深入了解目标检测技术--从基本概念到算法入门

前言:Hello大家好,我是Dream。 众所周知,目标检测是计算机视觉领域中的重要任务之一,其目的是识别图像或视频中包含的物体实例并将其定位。实现目标检测可以帮助人们在自动驾驶、机器人导航、安防监控等领域中更好地理解和应用图像信息。接下来Dream将带大家一起介绍目标检测的基本概念和常见方法,并详细讲解如何使用深度学习技术实现目标检测。
一、目标检测概述
目标检测的主要任务是在图像或视频中找到感兴趣的物体,并确定其位置和类别。目标检测主要分为两个步骤:目标位置定位和目标类别预测。目标位置定位指的是在图像或视频中找到每个物体所在的位置,通常使用边框标注(BBox)的方式表示。目标类别预测则是识别每个物体属于哪一类别,如汽车、行人、信号灯等。
目标检测可以应用于各种领域,如自动驾驶、智能交通、机器人导航、医学图像分析、安防监控等。例如,在自动驾驶领域,车辆需要通过对前方的障碍物进行检测和定位,从而避免碰撞和危险。在安防监控领域,摄像头需要对监控的场景进行目标检测,从而警报和报警,确保安全。
二、目标检测方法
目标检测是一种复杂的图像处理任务,涉及到多个方面的知识和技术。在不同的情境下,可以采用不同的检测方法和算法,目前主要有以下两种方法。
1.传统目标检测方法
传统目标检测方法主要基于图像处理和计算机视觉技术,通过手工设计的特征提取和分类算法来实现检测。典型的方法包括SIFT,SURF,HOG等。这些方法可以有效地检测一些简单的物体,但对于复杂物体的检测效果较差。
2.基于深度学习的目标检测方法
近年来,基于深度学习的目标检测方法逐渐成为主流。这些方法能够自动地学习特征和分类器,并且在一定程度上解决了传统方法所存在的问题。
基于深度学习的目标检测方法可以分为两类:one-stage方法和two-stage方法。one-stage方法是直接在图像上进行目标检测,不需要先提取候选框,速度比较快。而two-stage方法则需要先生成一些候选框,然后对这些候选框进行分类和回归,依赖于候选框生成算法的准确性和速度。
2.1One-Stage方法
One-Stage方法主要包括三种算法:YOLO,SSD(单发多盒检测器)和RetinaNet。
YOLO算法采用全卷积结构,将物体检测看作是一个回归问题,直接将图像映射到边界框和置信度,减少了候选框的生成,从而提高了检测速度。
SSD算法采用了多个特征层来检测不同大小和比例的物体,每层都通过卷积操作产生固定的候选框,然后通过逐层融合和分类器回归等操作进行检测。
RetinaNet算法提出了一种新的损失函数Focal Loss来解决one-stage方法分类器过于“自信”的问题,即对于背景样本和易分类的正样本,减少其在训练中的贡献,加强难分类样本的训练。
2.2Two-Stage方法
Two-Stage方法主要包括RCNN(基于区域的卷积神经网络),Fast-RCNN,Faster-RCNN和Mask-RCNN。
RCNN算法首先生成大量候选框,然后通过卷积神经网络对候选框进行分类和回归。但是该算法需要较多时间来生成候选框,速度较慢。
Fast-RCNN算法对RCNN算法进行了改进,在生成候选框和计算特征向量上做了优化,速度有所提升。
Faster-RCNN算法增加了RPN(区域提案网络)模块,其作用是生成候选框的建议,从而使得整个检测过程更加快速和准确。
Mask-RCNN在Faster-RCNN的基础上进行了改进,不仅可以检测目标的位置和类别,还可以生成目标的分割掩模。
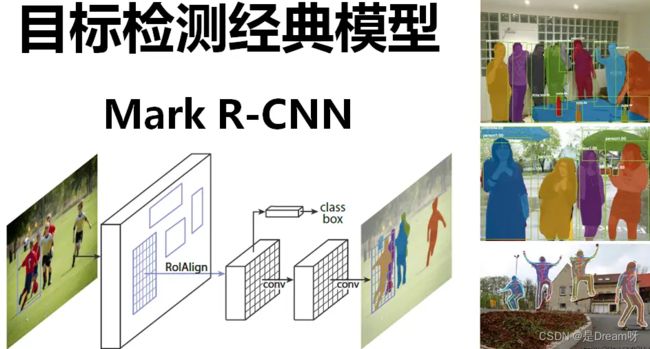
三、实现目标检测
目前,许多深度学习框架都提供了目标检测的实现方法,如TensorFlow Object Detection API、Detectron2等。本文以TensorFlow Object Detection API为例,介绍如何实现目标检测。
1.数据集准备
准备好的数据集应该包括两个重要的文件,一个是包含图像文件和相应标注的文件,另一个是用于训练模型和验证模型性能的文件。
图像文件和标注文件可以使用常见的标注工具生成,如LabelImg,VIA等。标注文件通常是XML或JSON格式,其中包含每个物体的类别和相对应的边界框坐标。训练和验证文件主要包括训练图像、验证图像、标签文件、训练配置文件等。
2.配置环境
配置环境需要先安装TensorFlow和Object Detection API。可使用Anaconda创建一个新的环境,然后在该环境下安装TensorFlow和Object Detection API。
conda create -n tfod python=3.8
conda activate tfod
pip install tensorflow==2.4.1
pip install tf-models-official
3.分割数据集
使用object_detection/dataset_tools/split.py工具,把数据集划分为训练集和验证集。
python split.py --csv_input=input.csv --output_dir=output --validation_set_frac=0.2
4.下载预训练模型
TensorFlow Object Detection API提供了一些预训练模型,可以在此基础上进行微调。模型可以在此处 下载。我们选取faster_rcnn_resnet101_coco预训练模型进行微调。
5.训练模型
准备好数据集并成功安装TensorFlow Object Detection API后,可以开始训练模型。利用object_detection/model_main_tf2.py文件进行训练。
python model_main_tf2.py --model_dir=models/faster_rcnn_resnet101 --pipeline_config_path=models/faster_rcnn_resnet101/pipeline.config
6.导出训练好的模型
训练完成后,需要将训练好的检测模型导出,以便进行预测和应用。使用object_detection/exporter_main_v2.py文件导出模型。
python exporter_main_v2.py --input_type=image_tensor --pipeline_config_path=models/faster_rcnn_resnet101/pipeline.config --trained_checkpoint_dir=models/faster_rcnn_resnet101/ --output_directory=models/faster_rcnn_resnet101_export/
7.测试模型
成功部署模型之后,可以对模型进行测试。在object_detection/test_images文件夹中有一些测试图像,可用于测试模型的性能。使用object_detection/test.py文件进行模型测试。
python test.py --model=models/faster_rcnn_resnet101_export --labels=models/label_map.pbtxt --image=object_detection/test_images/test1.jpg --output=output.jpg
测试效果图展示:
本期推荐:
ChatGPT时代:ChatGPT全能应用一本通
