python数据清洗-缺失值处理
本文主要内容:如何判断数据集中是否含有缺失值(如果数据集合存在不明含义的字符也可以作为缺失值处理),处理缺失值的常见方法介绍;

##导入数据分析需要的包
import numpy as np
import pandas as pd
##自定义数据分析数据集合
name=["小宝","小红","小小","大大","一一","一二","小兰","柯南","大小","小黑","小宝"]
sex=["女","女","女","男","男","男","女","男","女","女","女"]
age=[17,18,19,11,17,18,19,10,np.nan,10,17]
score=[86,86,98,98,91,92,104,94,93,92,86]
data=pd.DataFrame({"name":name,"sex":sex,"age":age,"score":score})
data.head()
检验数据集中是否含有缺失值
##判断数据是否有缺失值
data.isnull().sum()
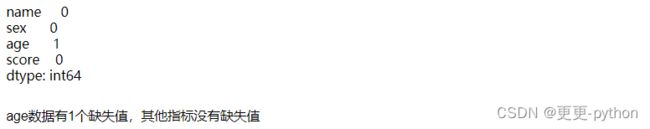
##查看缺失值的所在行
data[data['age'].isnull()]
(1)删除法处理缺失值
删除存在缺失值的所在的行
###缺失值删除法
data.dropna()
(2)均值填充法
用该变量没有缺失的数据均值作为填充值
###均值填充
data['age'].fillna(data['age'].mean())
(3)中位数填充法
用该变量没有缺失的数据中位数作为填充值
###中位数填充
data['age'].fillna(data['age'].median())
(4)向前填充法
用缺失值所在行的前一行对应的值作为填充值
###向前填充
data.fillna( method='ffill')
(4)向后填充法
用缺失值所在行的后一行对应的值作为填充值
###向后填充
data.fillna( method='bfill')
因为年龄分布不集中不均匀,且数据量小,不可采用删除法,最终我们选择中位数填充法
data['age'].fillna(data['age'].median(),inplace=True)
data
最后一步:复核数据集中是否还存在缺失值
产生缺失值的原因有很多:可能是在传输过程中产生数据确实,用户没有填写信息,信息被其他字符取代,如果某一变量缺失值占比大于80%,通常该变量数据不具有准确性,在处理的时候要先分析确实的原因是什么,再进行处理。