KMP算法
概述
KMP是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同时发现的。其中第一位就是《计算机程序设计艺术》的作者!
KMP算法要解决的问题就是在字符串(也叫主串)中的模式(pattern)定位问题。说简单点就是我们平时常说的关键字搜索。模式串就是关键字(接下来称它为子串),如果它在一个主串中出现,就返回它的具体位置,否则返回-1(常用手段)。
首先,对于这个问题有一个很单纯的想法:从左到右一个个匹配,如果这个过程中有某个字符不匹配,就跳回去,将子串向右移动一位。
这种方法也叫朴素的模式匹配:
简单来说就是:从主串s 和子串t 的第一个字符开始,将两字符串的字符一一比对,如果出现某个字符不匹配,主串回溯到第二个字符,子串回溯到第一个字符再进行一一比对。如果出现某个字符不匹配,主串回溯到第三个字符,子串回溯到第一个字符再进行一一比对……一直到子串字符全部匹配成功。
下面我们通过图片展示这个过程:
竖直线表示相等,闪电线表示不等
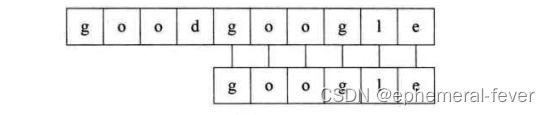
第一个过程:子串“goo”部分与主串相等,“g”不等,结束比对,进行回溯。
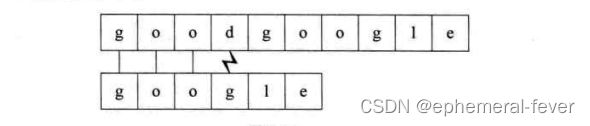
第二个过程:开始时就不匹配,直接回溯
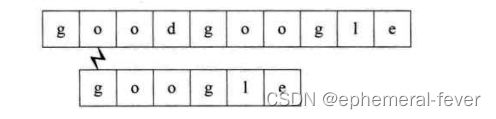
第三个过程:开始时即不匹配,直接回溯
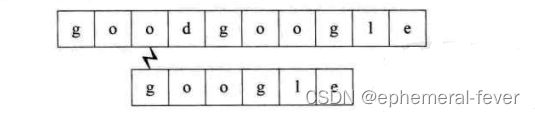
第四个过程:开始时即不匹配,直接回溯
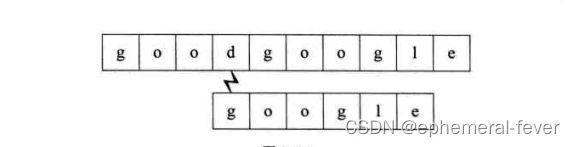
第五个过程:匹配成功
这种算法在最好情况下时间复杂度为O(n)。即子串的n个字符正好等于主串的前n个字符,而最坏的情况下时间复杂度为O(m*n)。相比而言这种算法空间复杂度为O(1),即不消耗空间而消耗时间。
思想引入
然而,上面的朴素模式匹配显然太慢了,那么有没有更快的方法呢?这就是KMP算法了。
我们先回顾一下上面的过程,看看为什么这么慢,注意上面第一个过程,如下图:
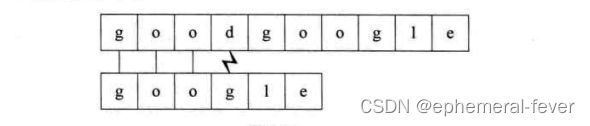
d和g不匹配之后朴素的方法是:将主串的指针指向第二个字母o,子串右移一位,然后比较从头比较。然而这是完全没有必要的,因为主串匹配失败的位置前面除了第一个g之外再也没有g了,我们为什么能知道主串前面只有一个g?因为我们已经知道前面三个字符都是匹配的!(这很重要)。移动过去肯定也是不匹配的!所以,我们完全可以让子串的g和主串刚刚不匹配的地方(也就是d)对齐,这样就能节约很多不必要的比较过程。
KMP算法的思想就如同我们上边所看到的一样:利用已经部分匹配这个有效信息,让模式串尽量地移动到有效的位置。
图解KMP算法
预备知识
先了解一个概念:一个字符串最长相等前缀和后缀。

举个例子:
字符串 abcdab
前缀的集合:{a,ab,abc,abcd,abcda}
后缀的集合:{b,ab,dab,cdab,bcdab}
那么最长相等前后缀不就是ab嘛。
做个小练习吧:
字符串abcabfabcab中最长相等前后缀是什么呢?
对就是abcab
好了我们现在会求一个字符串的前缀,后缀以及最长相等前后缀了。这个概念很重要。接下来就是正菜了。
图解
现在我们先看一个图:第一个长条代表主串,记为s,第二个长条代表子串,记为t。红色部分代表两串中已匹配的部分,绿色和蓝色部分分别代表主串和子串中不匹配的字符。
再具体一些:这个图代表主串"abcabeabcabcmn"和子串"abcabcmn"。

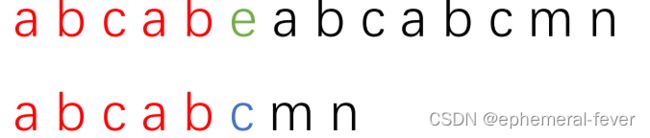
现在发现了不匹配的地方,根据KMP的思想我们要将子串向后移动,现在解决要移动多少的问题。
之前提到的最长相等前后缀的概念有用处了。因为红色部分也会有最长相等前后缀。如下图:

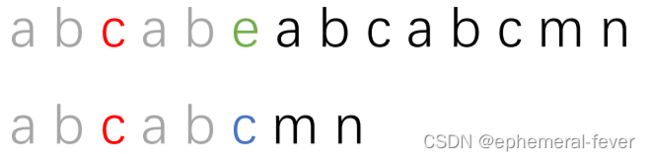
灰色部分就是红色部分字符串的最长相等前后缀,我们子串移动的结果就是让子串的红色部分最长相等前缀和主串红色部分最长相等后缀对齐。


这一步弄懂了,KMP算法的精髓就差不多掌握了。接下来的流程就是一个循环过程了。事实上,每一个字符前的字符串都有最长相等前后缀,而且最长相等前后缀的长度是我们移位的关键,所以我们单独用一个next数组存储子串的最长相等前后缀的长度。而且next数组的数值只与子串本身有关。
所以next[i]=j,含义是:下标为i 的字符前的字符串最长相等前后缀的长度为j。
我们可以算出,子串t= "abcabcmn"的next数组为next[0]=-1(前面没有字符串的单独处理);next[1]=0;next[2]=0;next[3]=0;next[4]=1;next[5]=2;next[6]=3;next[7]=0;
| a | b | c | a | b | c | m | n |
|---|---|---|---|---|---|---|---|
| next[0] | next[1] | next[2] | next[3] | next[4] | next[5] | next[6] | next[7] |
| -1 | 0 | 0 | 0 | 1 | 2 | 3 | 0 |
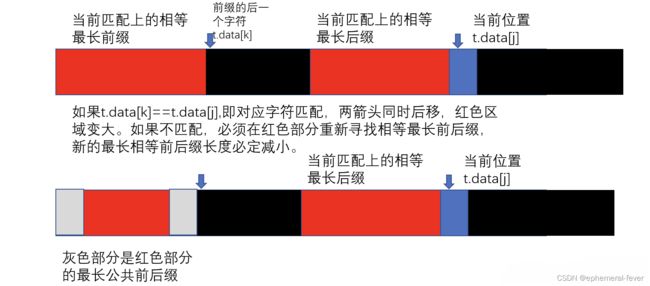
本例中的蓝色c处出现了不匹配(是s[5]!=t[5]),
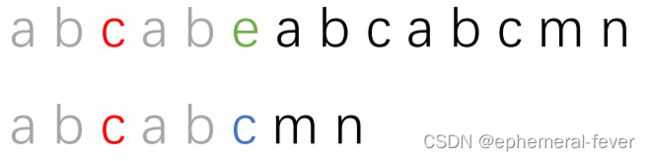
我们把子串移动,也就是让s[5]与t[5]前面字符串的最长相等前缀后一个字符再比较,而该字符的位置就是t[?],很明显这里的?是2,就是不匹配的字符前的字符串 最长相等前后缀的长度。
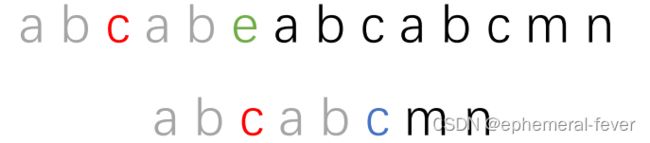
也是不匹配的字符处的next数组next[5]应该保存的值,也是子串回溯后应该对应的字符的下标。 所以?=next[5]=2。接下来就是比对是s[5]和t[next[5]]的字符。这里也是最奇妙的地方,也是为什么KMP算法的代码可以那么简洁优雅的关键。
我们可以总结一下,next数组作用有两个:
一是之前提到的:
next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度。
二是:
表示该处字符不匹配时应该回溯到的字符的下标
next有这两个作用的源头是:之前提到的字符串的最长相等前后缀
想一想是不是觉得这个算法好厉害,从而不得不由衷佩服KMP算法的创始人。
时间复杂度
现在我们分析一下KMP算法的时间复杂度:
KMP算法中多了一个求数组的过程,多消耗了一点点空间。我们设主串s长度为n,子串t的长度为m。求next数组的时间复杂度为O(m),因后面匹配中主串不回溯,比较次数可记为n,所以KMP算法的总时间复杂度为O(m+n),空间复杂度记为O(m)。相比于朴素的模式匹配时间复杂度O(m*n),KMP算法提速是非常大的,这一点点空间消耗换得极高的时间提速是非常有意义的,这种思想也是很重要的。
下面还有更厉害的,我们一起来分析具体的代码。
代码实现
getNext
下面我们一起来欣赏计算机如何求得next数组的
void getNext(string t, int next[]) //由模式串t求出next
{
//next[i]的值表示:
//(1)下标为i的字符前的字符串最长相等前后缀的长度
//(2)该处字符不匹配时应该回溯到的字符的下标
int j = 0, k = -1; //j指向子串后缀的后一个位置,用于扩展新的字符;k指向子串前缀的后一个位置
next[0] = -1; //第一个字符前没有字符,给-1
while (j < t.length())
{
if (k == -1 || t[j] == t[k])
{
j++;
k++;
next[j] = k;
}
else
{
//当新扩展进来的一个字符和前面不匹配时,需要在前缀和后缀的串上再求最长公共前后缀,
//再将前缀的前缀的后一个位置和j位置的字符比较,
//这个前缀的前缀的后一个位置就是next[k]
k = next[k]; //k回退到next[k],即前缀的前缀的后一个位置
}
}
}
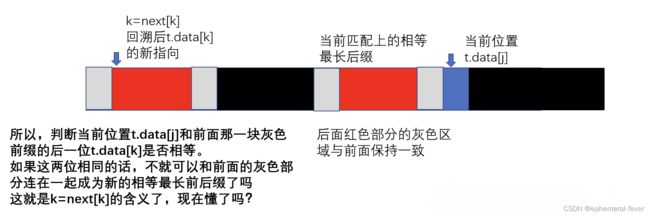
解释next数组构造过程中的回溯问题
大家来看下面的图,下面的长条代表子串,红色部分代表当前匹配上的最长相等前后缀,蓝色部分代表t[j]。
int KMPIndex(string s, string t)
{
int len = t.length(); //不这么做下面所有出现t.length()的地方都会有问题,即if(j>=t.length())会出现判定-1>=t.length()为真的情况
int *next = new int[len];
getNext(t, next); //获取子串t的next数组
int i = 0, j = 0; //i是主串s的指针,j是子串t的指针
while (i < s.length() && j < len)
{
if (j == -1 || s[i] == t[j])
{
i++;
j++;
}
else
j = next[j]; //i不变,j回退
// cout<<"i:"<= len)
return i - len; //返回匹配模式字符串的下标
else
return -1; //返回不匹配标志
}
改进
为什么KMP算法这么强大了还需要改进呢?
大家来看一个例子:
主串s=“aaaaabaaaaac”
子串t=“aaaaac”
这个例子中当‘b’与‘c’不匹配时应该‘b’与’c’前一位的‘a’比,这显然是不匹配的。‘c’前的’a’回溯后的字符依然是‘a’。
我们知道没有必要再将‘b’与‘a’比对了,因为回溯后的字符和原字符是相同的,原字符不匹配,回溯后的字符自然不可能匹配。但是KMP算法中依然会将‘b’与回溯到的‘a’进行比对。这就是我们可以改进的地方了。我们改进后的next数组命名为:nextval数组。KMP算法的改进可以简述为: 如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。 这应该是最浅显的解释了。如字符串"ababaaab"的next数组以及nextval数组分别为:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 子串 | a | b | a | b | a | a | a | b |
| next | -1 | 0 | 0 | 1 | 2 | 3 | 1 | 1 |
| nextval | -1 | 0 | -1 | 0 | -1 | 3 | 1 | 0 |
改进后的代码:
void getNextval(string t, int nextval[])
{
int j = 0, k = -1;
nextval[0] = -1;
while (j < t.length())
{
if (k == -1 || t[j] == t[k])
{
j++;
k++;
if (t[j] != t[k])
//这里的t[k]是t[j]处字符不匹配而会回溯到的字符
//为什么?因为没有这处if判断的话,此处代码是next[j]=k;
//next[j]不就是t[j]不匹配时应该回溯到的字符位置嘛
nextval[j] = k;
else
nextval[j] = nextval[k];
}
else
k = nextval[k];
}
}
KMPIndex函数没有变,只是换个数组名字,这里就不放了。