【Hive实战】Hive元数据存储库数据增多的分析
Hive元数据存储库数据增多的分析
文章目录
- Hive元数据存储库数据增多的分析
-
- 问题
- 新增Hive相关的DDL操作
-
- 创建Hive库
-
- 库授权到用户
- 创建Hive表 内部表
-
- 非分区表
- 表授权到用户
- 一级分区表
- 二级分区表
- 分桶表
- 分桶排序表
- 查询指令
- 核心表分析
-
- 表关系图表
-
- 以库表为主
- 以hive表为主
- 以分区表为主
- 以文件存储表为主
- 数据增长分析
-
- 治理构想
- 治理操作方案
- 工具化 常态化疑问
问题
元数据存储库的情况,多个单表数据超过2千万。
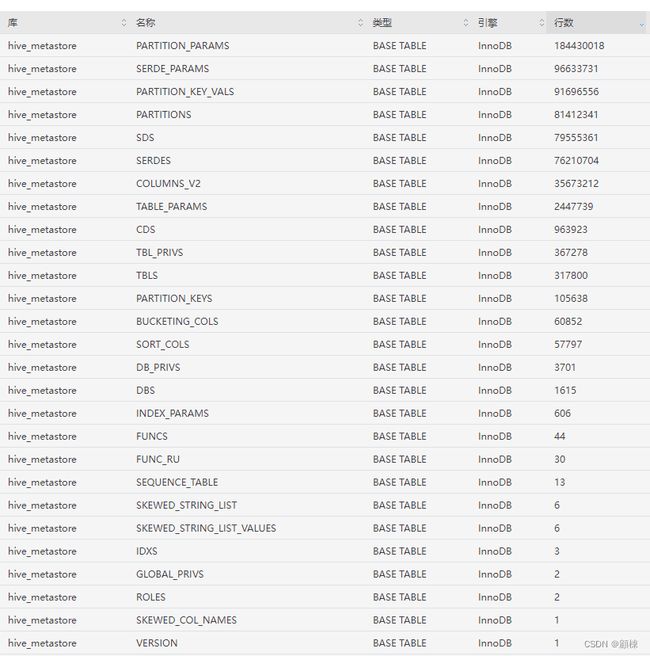
对超过2千万数据量的表需要进行分析,分析的角度:
- hive的哪些操作会引起这些表的数据的变化?
- 了解这些表的数据代表什么?
- 表数据之间的关系?
新增Hive相关的DDL操作
创建Hive库
create DATABASE if not EXISTS test20230425001 COMMENT '测试的库' WITH DBPROPERTIES ('createUser'='顾栋','date'='20230425');
DROP DATABASE IF EXISTS test20230425001;
库授权到用户
INSERT | SELECT | UPDATE | DELETE | Create | ALL
grant select on database test20230425001 to user hdfs;
REVOKE select on database test20230425001 from user hdfs;
创建Hive表 内部表
非分区表
CREATE TABLE `test20230425001.t_test_001`(
`cluster_name` string COMMENT 'hbase集群名称',
`namespace` string COMMENT '命名空间',
`table_name` string COMMENT '表名',
`system_os` string COMMENT 'Hbase表的归属系统')
COMMENT 'hbase表与归属系统表'
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
Drop Table `test20230418001.t_test_001`;
表授权到用户
INSERT | SELECT | UPDATE | DELETE | ALL
grant select on table test20230425001.t_test_001 to user hdfs;
REVOKE select on table test20230425001.t_test_001 from user hdfs;
一级分区表
CREATE TABLE `test20230425001.t_test_002`(`ldc` string COMMENT '机房',`cluster_name` string COMMENT '集群名称',`cluster_id` bigint COMMENT '集群id')
COMMENT 'ES的索引申请情况的信息表'
PARTITIONED BY (`date_time` string COMMENT '分区字段')
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230417');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230418');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230419');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230420');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230417');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230418');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230419');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230420');
Drop Table `test20230425001.t_test_002`;
二级分区表
CREATE TABLE `test20230425001.t_test_003`(
`ldc` string COMMENT '机房',
`cluster_name` string COMMENT '集群名称',
`cluster_id` bigint COMMENT '集群id')
COMMENT 'ES的索引申请情况的信息表'
PARTITIONED BY (
`month` string COMMENT '1级分区字段',
`day` string COMMENT '2级分区字段')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='17');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='18');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='19');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='20');
ALTER TABLE `test20230425001.t_test_003` DROP IF EXISTS PARTITION (month='202304',day='17');
ALTER TABLE `test20230425001.t_test_003` DROP IF EXISTS PARTITION (month='202304',day='18');
ALTER TABLE `test20230425001.t_test_003` DROP IF EXISTS PARTITION (month='202304',day='19');
ALTER TABLE `test20230425001.t_test_003` DROP IF EXISTS PARTITION (month='202304',day='20');
Drop Table `test20230425001.t_test_003`;
分桶表
CREATE TABLE `test20230425001.user_info_bucketed`(`user_id` bigint, `firstname` string, `lastnames` string)
COMMENT '分桶表'
PARTITIONED BY(ds string)
CLUSTERED BY(user_id) INTO 256 BUCKETS;
ALTER TABLE `test20230425001.user_info_bucketed` ADD IF NOT EXISTS PARTITION (ds='20230417');
ALTER TABLE `test20230425001.user_info_bucketed` ADD IF NOT EXISTS PARTITION (ds='20230418');
ALTER TABLE `test20230425001.user_info_bucketed` ADD IF NOT EXISTS PARTITION (ds='20230419');
ALTER TABLE `test20230425001.user_info_bucketed` ADD IF NOT EXISTS PARTITION (ds='20230420');
ALTER TABLE `test20230425001.user_info_bucketed` DROP IF NOT EXISTS PARTITION (ds='20230417');
ALTER TABLE `test20230425001.user_info_bucketed` DROP IF NOT EXISTS PARTITION (ds='20230418');
ALTER TABLE `test20230425001.user_info_bucketed` DROP IF NOT EXISTS PARTITION (ds='20230419');
ALTER TABLE `test20230425001.user_info_bucketed` DROP IF NOT EXISTS PARTITION (ds='20230420');
Drop Table `test20230425001.user_info_bucketed`;
分桶排序表
CREATE TABLE `test20230425001.user_info_bucketed_sorted`(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230417',country='bj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230417',country='nj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230417',country='dj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230417',country='xj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230418',country='bj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230418',country='nj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230418',country='dj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` ADD IF NOT EXISTS PARTITION (dt='20230418',country='xj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230417',country='bj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230417',country='nj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230417',country='dj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230417',country='xj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230418',country='bj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230418',country='nj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230418',country='dj');
ALTER TABLE `test20230425001.user_info_bucketed_sorted` DROP IF NOT EXISTS PARTITION (dt='20230418',country='xj');
Drop Table `test20230425001.user_info_bucketed_sorted`;
查询指令
--查询hive库
show databases;
-- 可用符号 *(通配) |(或)
show databases like '';
-- 查询库中的表 可用符号 *(通配) |(或)
show tables;
show tables in [database_name];
show tables in [database_name] [''];
-- 查询分区 show partitions test20230425001.t_test_002;
SHOW PARTITIONS [db_name.]table_name [PARTITION(partition_spec)];
-- 查询表的扩展信息
SHOW TBLPROPERTIES `test20230425001.t_test_002`;
show table extended like `t_test_002`;
-- 查询用户拥有的所有授权信息
show grant user user_name on all;
-- 查询用户拥有的对应表的授权信息
show grant user user_name on table db_name.table_name;
-- 查询表的所有授权信息
show grant on table db_name.table_name;
核心表分析
通过执行上述DDL时,观察hive元数据存储库的变化,总结出以下关系:
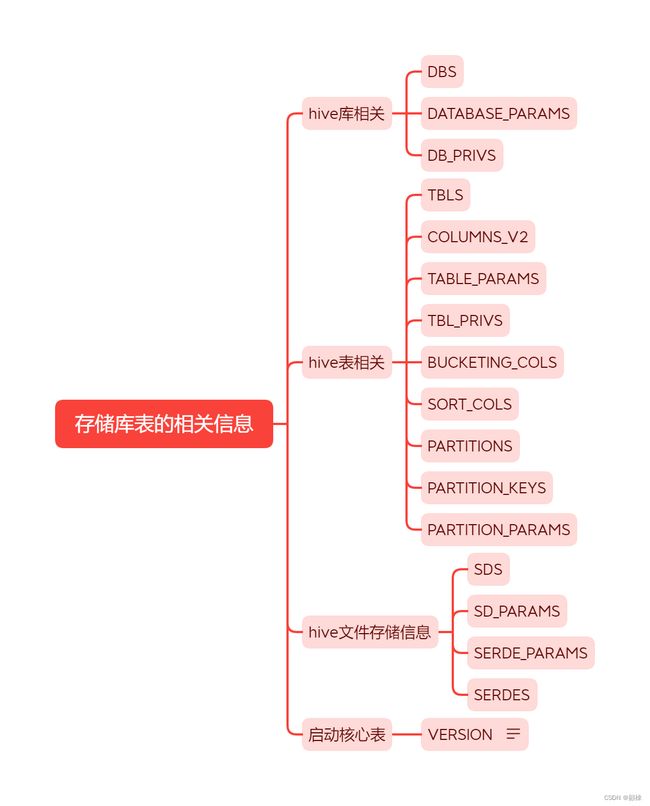
逐个表开始分析字段作用与关系
DBS
存储Hive中所有数据库的基本信息
| 字段 | 注释 |
|---|---|
| DB_ID | 数据库的编号,默认的数据库编号为1,如果创建其他数据库的时候,这个字段会自增,主键 |
| DESC | 对数据库的备注 |
| DB_LOCATION_URI | 数据库的存放位置,default库是存放在hdfs://ip:9000/user/hive/warehouse,如果是其他数据库,就在后面添加目录,默认位置可以通过参数hive.metastore.warehouse.dir来设置 |
| NAME | 数据库的名称 |
| OWNER_NAME | 数据库拥有主体的名称 |
| OWNER_TYPE | 数据库拥有主体的类型,USER:代表OWNER_NAME存放的是用户名;ROLE:代表OWNER_NAME存放的是角色名 |
DATABASE_PARAMS
存储数据库的相关参数信息
| 字段 | 注释 |
|---|---|
| DB_ID | 数据库编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数值 |
DB_PRIVS
新建的库时,无需对本用户进行授权(无默认新增记录)
| 字段 | 注释 |
|---|---|
| DB_GRANT_ID | 数据库授权编号 |
| CREATE_TIME | 授权时间 |
| DB_ID | 被授权的数据库ID |
| GRANT_OPTION | 授权操作 |
| GRANTOR | 授权账户 |
| GRANTOR_TYPE | 授权类型 |
| PRINCIPAL_NAME | 被授权主体名称 |
| PRINCIPAL_TYPE | 被授权主体类型 |
| DB_PRIV | 数据库权限 |
TBLS
存储Hive表,视图,索引表的基本信息
| 字段 | 注释 |
|---|---|
| TBL_ID | 在hive中创建表的时候自动生成的一个id,用来表示,主键 |
| CREATE_TIME | 创建的数据表的时间,使用的是时间戳 |
| DB_ID | 数据库编号,表所属的数据库 |
| LAST_ACCESS_TIME | 最后一次访问的时间戳 |
| OWNER | 数据表的所有者 |
| RETENTION | 保留时间 |
| SD_ID | 标记物理存储信息的id |
| TBL_NAME | 数据表的名称 |
| TBL_TYPE | 数据表的类型,MANAGED_TABLE, EXTERNAL_TABLE, VIRTUAL_VIEW, INDEX_TABLE |
| VIEW_EXPANDED_TEXT | 展开视图文本,非视图为null |
| VIEW_ORIGINAL_TEXT | 原始视图文本,非视图为null |
TBL_PRIVS
存储表/视图的授权信息
| 字段 | 注释 |
|---|---|
| TBL_GRANT_ID | 表授权编号 |
| CREATE_TIME | 授权时间 |
| GRANT_OPTION | 授权操作 |
| GRANTOR | 授权者 |
| GRANTOR_TYPE | 授权类型 USER ROLE GROUP |
| PRINCIPAL_NAME | 被授权主体名称 |
| PRINCIPAL_TYPE | 被授权主体类型 USER ROLE GROUP |
| TBL_PRIV | 表权限类别 |
| TBL_ID | 表的编号 |
TABLE_PARAMS
存储表/视图的属性信息
| 字段 | 注释 |
|---|---|
| TBL_ID | 数据的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
COLUMNS_V2
所有Hive表中的字段都存于此表。用于描述列的信息
| 字段 | 注释 |
|---|---|
| CD_ID | 字段的ID(实际中发现应该是表的ID) |
| COMMENT | 字段注释说明 |
| COLUMN_NAME | 列的名称 |
| TYPE_NAME | 列的类型 |
BUCKETING_COLS
桶表字段
| 字段 | 注释 |
|---|---|
| SD_ID | 表的编号 |
| BUCKET_COL_NAME | 作为分桶的列名称 |
| INTEGER_IDX | 列的索引 |
SORT_COLS
记录要进行排序的列
| 字段 | 注释 |
|---|---|
| SD_ID | 数据表物理信息描述的编号 |
| COLUMN_NAME | 用来列的名称 |
| ORDER | 排序方式 |
PARTITIONS
存储表分区的基本信息
| 字段 | 注释 |
|---|---|
| PART_ID | 分区的编号 |
| CREATE_TIME | 创建分区的时间 |
| LAST_ACCESS_TIME | 最近一次访问时间 |
| PART_NAME | 分区的名字 |
| SD_ID | 存储描述的id |
| TBL_ID | 数据表的id |
PARTITION_KEYS
存储分区的字段信息
| 字段 | 注释 |
|---|---|
| TBL_ID | 数据表的编号 |
| PKEY_COMMENT | 分区字段的描述 |
| PKEY_NAME | 分区字段的名称 |
| PKEY_TYPE | 分区字段的类型 |
PARTITION_KEY_VALUES
存储分区字段值
| 字段 | 注释 |
|---|---|
| PART_ID | 分区表的编号 |
| PART_KEY_VALUE | 分区字段的值 |
| INTEGER_IDX | 分区字段的顺序 |
PARTITION_PARAMS
存储分区字段值
| 字段 | 注释 |
|---|---|
| PART_ID | 分区的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
Hive文件存储信息相关的元数据表
SDS
文件存储的基本信息
| 字段 | 注释 |
|---|---|
| SD_ID | 主键 |
| CD_ID | 数据表ID |
| INPUT_FORMAT | 数据输入格式 |
| IS_COMPRESSED | 是否对数据进行了压缩 |
| IS_STOREDASSUBDIRECTORIES | 是否进行存储在子目录 |
| LOCATION | 数据存放位置 |
| NUM_BUCKETS | 分桶的数量 |
| OUTPUT_FORMAT | 数据的输出格式 |
| SERDE_ID | 序列和反序列的信息id |
SD_PARAMS
文件存储的扩展属性的信息
| 字段 | 注释 |
|---|---|
| SD_ID | 主键,记录序列化的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
SERDE_PARAMS
存储序列化的一些属性、格式信息,比如:行、列分隔符
| 字段 | 注释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
SERDES
记录序列化和反序列化信息
| 字段 | 注释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| NAME | 序列化和反序列化名称 |
| SLIB | 使用的是哪种序列化方式 |
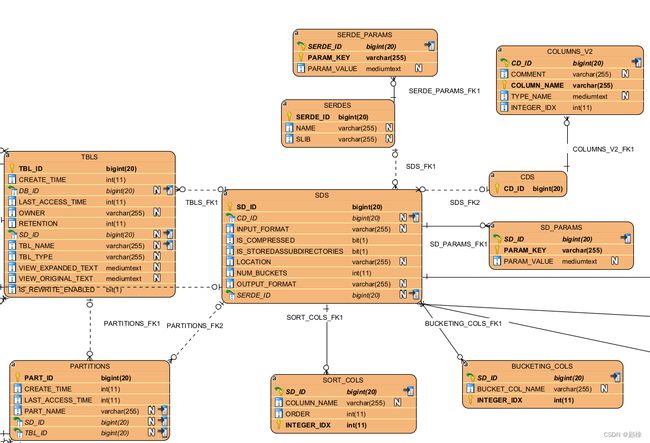
表关系图表
(工具visual_paradigm)
以库表为主
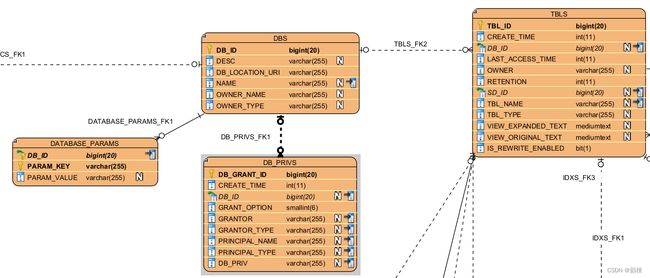
以hive表为主

以分区表为主
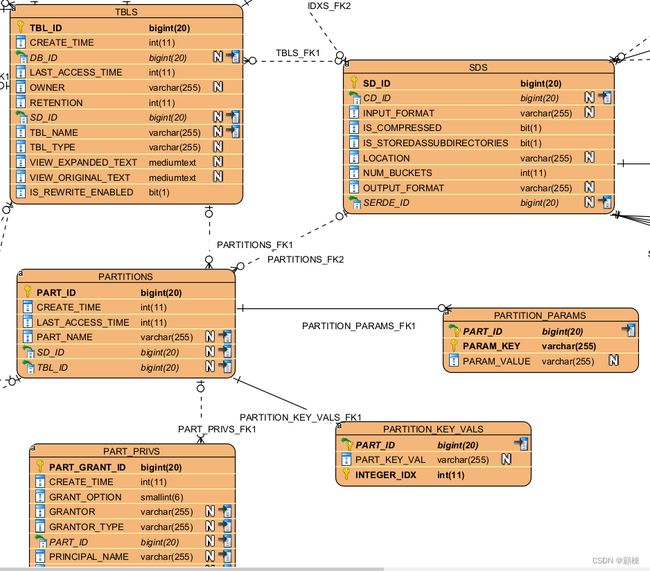
以文件存储表为主
数据增长分析
将元数据存储库中的相关表数据抽取到hive表中,进行数据分析。
-
分析hive数据库的情况
-
分析hive表的字段数量情况
SELECT COUNT(*) FROM ( SELECT cd_id ,COUNT(1) AS cts FROM hive_meta_columns_v2 WHERE day = '20230505' GROUP BY cd_id ) WHERE cts <= 100;hive表字段数量分布情况 单表字段数区间 (0,100] [101,500] [501,1000] [1001,2000] [2000,+∞] 数量 834125 46313 543 205 112 占比 94.65% 5.26% 0.06% 0.02% 0.01% -
分析hive表的属性参数情况
SELECT COUNT(*) FROM ( SELECT c.TBL_ID ,COUNT(*) AS parCount FROM ( SELECT a.TBL_ID ,b.PARAM_KEY FROM hive_meta_tbls a LEFT JOIN hive_meta_table_params b ON a.TBL_ID = b.TBL_ID WHERE a.day = '20230505' AND b.day = '20230505' ) c GROUP BY c.TBL_ID ) d WHERE d.parCount > 100;hive表的属性数量分布情况 单表属性数区间 (0,10] [11,20] [21,30] [31,40] [41,50] [51,100] [100,+∞] 数量 315839 9910 73 13 23 21 7 占比 96.917% 3.041% 0.022% 0.004% 0.007% 0.006% 0.002% -
分析hive表的分区情况
SELECT COUNT(*) FROM ( SELECT a.TBL_ID ,COUNT(*) AS PART_SUM FROM hive_meta_tbls a LEFT JOIN hive_meta_partitions b ON a.TBL_ID = b.TBL_ID WHERE a.day = '20230505' AND b.day = '20230505' GROUP BY a.TBL_ID ) WHERE PART_SUM > 0 AND PART_SUM <= 180;表有多少个分区,以下区间是按一级分区天粒度进行设定的。二级分区为2倍,分区级别不超过2级。
hive分区数量分布情况 单表分区数时长 半年(6个月) 1年 2年 3年 5年 10年 20年 30年 存疑 单表分区数区间 [1,180] [181,365] [366,730] [731,1095] [1096,1825] [1826,3650] [3651,7300] [7301,10950] [10950,+∞] 数量 29023 5989 12380 12547 18180 5299 385 143 679 占比 34.30% 7.08% 14.63% 14.83% 21.48% 6.26% 0.45% 0.17% 0.80% 分区的属性参数情况
SELECT COUNT(*) FROM ( SELECT a.PART_ID ,COUNT(*) AS PART_PAR_SUM FROM hive_meta_partitions a LEFT JOIN hive_meta_partition_params b ON a.PART_ID = b.PART_ID WHERE a.day = '20230505' AND b.day = '20230505' GROUP BY a.PART_ID ) c WHERE PART_PAR_SUM > 0 AND PART_PAR_SUM <= 10;hive分区的属性数量分布情况 单表属性数区间 (0,10] [11,20] 数量 80830453 2627 占比 99.997% 0.003% 分区层级的情况
SELECT COUNT(hmp.PART_ID) AS PART_SUM ,hmp.TBL_ID FROM hive_meta_partitions hmp WHERE hmp.day = '20230505' GROUP BY hmp.TBL_ID -
分析hive表存储与序列化的情况
序列化表中存在记录不指向存储信息表
1283503行
SELECT * FROM hive_meta_serdes a WHERE serde_id not IN ( SELECT serde_id FROM hive_meta_sds b WHERE b.day = '20230505') WHERE a.day = '20230505'存储表中存在记录既不指向表又不指向表分区 量小忽略
SELECT COUNT(1) FROM ( SELECT * FROM hive_meta_sds a WHERE sd_id NOT IN ( SELECT sd_id FROM hive_meta_tbls b WHERE b.day = '20230505' ) AND a.day = '20230505' ) d WHERE d.sd_id NOT IN ( SELECT sd_id FROM hive_meta_partitions c WHERE c.day = '20230505');文件存储的序列化属性信息
SELECT count(1) FROM ( SELECT a.SERDE_ID ,COUNT(*) AS SERDE_ID_par_count FROM hive_meta_serdes a LEFT JOIN hive_meta_serde_params b ON a.SERDE_ID = b.SERDE_ID WHERE b.day = '20230505' AND b.day = '20230505' GROUP BY a.SERDE_ID ) c WHERE SERDE_ID_par_count = 4文件存储的序列化属性信息 序列化属性个数 1 2 3 4 5 数量 65712703 10825167 5016671 868419 1 占比 79.726% 13.134% 6.086% 1.054% 0.000% -
内部表分析
内部表的分区中的文件存储信息不存在
199行 量小忽略
SELECT * FROM ( SELECT p.* FROM hive_meta_partitions p WHERE p.TBL_ID IN ( SELECT t.TBL_ID FROM hive_meta_tbls t WHERE t.TBL_TYPE = 'MANAGED_TABLE' AND t.day = '20230505') AND p.day = '20230505' ) a WHERE a.SD_ID not IN ( SELECT s.SD_ID FROM hive_meta_sds s WHERE s.day = '20230505');内部表的文件存储信息不存在
109行
SELECT * FROM hive_meta_tbls t WHERE t.TBL_TYPE = 'MANAGED_TABLE' AND t.day = '20230505' AND t.SD_ID not IN ( SELECT SD_ID FROM hive_meta_sds s WHERE s.day = '20230505'); -
其他
-- 查询数据库的数量 select * from hive_meta_dbs where day='20230424'order by db_id desc -- 查询表的字段情况 select * from hive_meta_columns_v2 where day='20230424' order by cd_id desc -- 分析出表字段数量的占比 SELECT * FROM ( SELECT cd_id ,COUNT(1) AS cts FROM hive_meta_columns_v2 WHERE day = '20230424' GROUP BY cd_id ) ORDER BY cts desc -- 分析表属性参数 SELECT * FROM ( SELECT c.TBL_ID ,COUNT(*) AS parCount FROM ( SELECT a.TBL_ID ,b.PARAM_KEY FROM hive_meta_tbls a LEFT JOIN hive_meta_table_params b ON a.TBL_ID = b.TBL_ID WHERE a.day = '20230424' AND b.day = '20230424' ) c GROUP BY c.TBL_ID ) d order by d.parCount desc -- sd_id在tbls表中的关系-一张表拥有一个sd_id SELECT * FROM ( SELECT sd_id ,COUNT(*) AS sd_id_count FROM hive_meta_tbls WHERE day = '20230424' GROUP BY sd_id ) ORDER BY sd_id_count desc -- 分析表的分区情况 -- 一张表有多少个分区 SELECT * FROM ( SELECT a.TBL_ID ,COUNT(*) AS PART_SUM FROM hive_meta_tbls a LEFT JOIN hive_meta_partitions b ON a.TBL_ID = b.TBL_ID WHERE a.day = '20230423'and b.day = '20230423' GROUP BY a.TBL_ID ) ORDER BY PART_SUM DESC --分区的属性参数情况 SELECT a.PART_ID ,COUNT(*) AS PART_PAR_SUM FROM partitions a LEFT JOIN partition_params b ON a.PART_ID = b.PART_ID GROUP BY a.PART_ID --sd_id在partitions表中的关系-一个表分区拥有一个sd_id SELECT * FROM ( SELECT sd_id ,COUNT(*) AS sd_id_count FROM hive_meta_partitions WHERE day = '20230424' GROUP BY sd_id ) ORDER BY sd_id_count desc -- 一个存储的序列化情况 SELECT * FROM ( SELECT serde_id ,COUNT(*) AS serde_id_count FROM hive_meta_serdes WHERE day = '20230424' GROUP BY serde_id ) ORDER BY serde_id_count desc -- 文件存储的序列化属性信息 SELECT * FROM ( SELECT a.SERDE_ID ,COUNT(*) AS SERDE_ID_par_count FROM serdes a LEFT JOIN sede_params b ON a.SERDE_ID = b.SERDE_ID GROUP BY a.SERDE_ID ) c ORDER BY SERDE_ID_par_count desc;
分析结果:
-
表的常见属性
- transient_lastDdlTime
- totalSize
- rawDataSize
- numRows
- numFiles
- last_modified_time
- last_modified_by
- comment
- spark sql系:字段个数越多,属性也就越多,多个字段(个数不定,与长度有关)一个属性
- flink系: 字段个数为主要因素,属性也就越多,一个字段两个属性
-
表的一级分区情况
- 拥有分区数在1800~11000之间的一级分区表,黄牌
- 拥有分区数超过11000的一级分区表,拥有超过20000的二级分区表,拥有2级分区以上的表,红牌
-
表分区的常见属性
- totalSize
- rawDataSize
- numRows
- numFiles
- last_modified_time
- last_modified_by
- transient_lastDdlTime
- comment
- serialization.format
- spark sql系:字段个数越多,属性也就越多,多个字段(个数不定,与长度有关)一个属性
治理构想
-
建立相关元数据库,提供治理的数据依据
-
表的字段数、分区数量、分区层次性的合理性探讨
- 常规hive表的字段在100以内
- 按一级分区,天粒度,保存周期跨度上限30年的条件,统计表分区数量分布情况
- 为了价格数据存储压力和数据的指数级增长,分区的层级控制在2层。
-
垃圾数据的识别与处理
按照表之间的关系,查询出关系不对应的数据,根据数据量进行处理
- 序列化表中存在记录不指向存储信息表
- 表的文件存储信息不存在
- 表的分区中的文件存储信息不存在
治理操作方案
除了上述主动发现的场景外,当出现如下几种情况,需要对分区表进行治理
- 任务失败,日志包含
"FAILED: SemanticException Number of partitions scanned (=xxxx) on table xxx exceeds limit (=xxx). This is controlled by hive.limit.query.max.table.partition."。 - 执行查询很慢,检查发现任务中使用到的分区表分区个数超过10000或者分区表分区层级超过2级。
首先,需要检查报错的Hql语句是否对涉及的分区表加上分区过滤,没有加上的请加上分区过滤。若已加上的,请缩小分区过滤区间。其次,需要确认该分区表是否为自己账号名下的分区表,若是,则对该分区表进行治理,反之,则通知上游任务的负责人进行分区表治理 。
删除分区
ALTER TABLE table_name DROP IF EXISTS PARTITION(part_name=xx);
分区拆分
若分区数据被当前任务或者下游任务使用或者删除部分分区数据后分区表分区数量仍过多,仍需要将分区表进行拆分,将老表的分区数据导入到新表中。
//建立新的分区表
create table table_new like table_old;
//将老的分区表的部分分区数据导入到新的分区表中,确保导入的分区数不超过限定的数量
insert into table table table_new(part1) select * from table_old
where <partition_filter>;
分区表重建
若分区数据被当前任务或者下游任务使用,需要重新设计新分区表,要求新分区表分区层级小于2级,然后将老表数据按照新分区表分区结构导入到新分区表中,最后删除老分区表 。
//创建新分区表
create table table_new (c1 string ,...) partitioned by ...;
//将老分区表数据导入到新分区表
insert into table table table_new(part1=xx) select * from table_old
where <partition_filter>;
insert into table table table_new(part1=xxxx) select * from table_old
where <partition_filter>;
//删除老分区表(逐条删除分区,最后删除表)
ALTER TABLE table_name DROP IF EXISTS PARTITION(part_name=xx);
ALTER TABLE table_name DROP IF EXISTS PARTITION(part_name=xxx);
drop table table_old;
工具化 常态化疑问
- 如何提供分区列表?
- 如何工具化处理,减少人工手动变更操作?
- 如何批量处理?