Flink流批一体计算(3):FLink作业调度
架构
所有的分布式计算引擎都需要有集群的资源管理器,例如:可以把MapReduce、Spark程序运行在YARN集群中、或者是Mesos中。Flink也是一个分布式计算引擎,要运行Flink程序,也需要一个资源管理器。而学习每一种分布式计算引擎,首先需要搞清楚的就是:我们开发的分布式应用程序是如何在集群中执行的,这其中一定会涉及到与资源管理器的交互。其实,可以把资源管理看成是一个cluster的抽象。
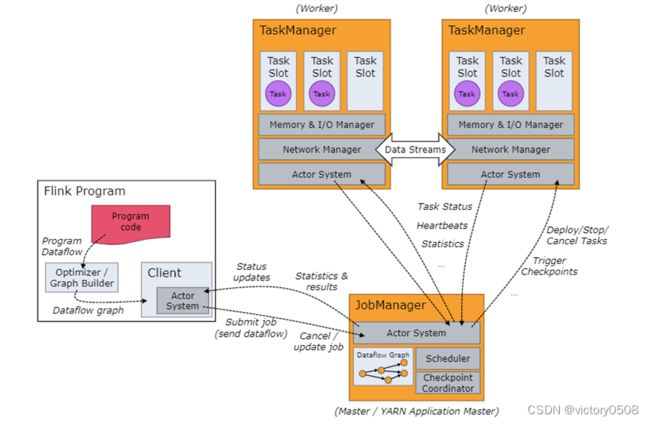
我们来看一下Flink集群会涉及到的重要角色。
- client
client将编写的代码转换为程序的Dataflow,并对Dataflow进行优化,生成Dataflow Graph,再将job提交给JobManager。我们编写的Flink代码,其实主要是用来描述Flink程序在集群中应该如何执行,Flink集群当然也不是像运行编写的单机程序一样,顺序往下执行。它只会接受一个一个的Job,然后运行Job中一个个的任务。
- Job Manager
Job Manager其实是Flink集群的作业管理器,它负责调度、管理集群的计算资源。
- Task Manager
一个集群往往由很多的Task Manager组成,Task Manager负责管理、运行具体的任务。Task Manager与Task Manager之间也是能够互相通信的。
| 组件 |
用途 |
实现 |
| Flink Client |
将批处理或流式应用程序编译成数据流图,然后提交给JobManager。 |
|
| JobManager |
Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些Taskmanager执行。 JobManager的作业提交模式有三种 Application Mode Per-Job Mode Session Mode |
|
| TaskManager |
Flink系统的业务执行节点,执行具体的用户任务、Flink作业。 |
调度
Flink通过Task Slots来定义执行资源。每个TaskManager有一到多个task slot,每个task slot 可以运行一条由多个并行task组成的流水线。 这样一条pipeline由多个连续的task组成。

每个slot能够使用的资源是固定的,例如:如果一个TaskManager上配置了3个slot,那每个slot能够使用的内存为TaskManager管理的内存的1/3。slot与slot之间并不存在内存资源上的竞争。Flink运行用户调整TaskManager的slot数量,如果slot数量为1,那表示每个任务都是在独立的JVM中执行。而如果大于1,表示多个任务运行在一个JVM中。
每个slot运行可以运行一个任务。一个JOB中如果Operator和并行度比较多,就会包含很多任务,而Flink集群中的默认配置,任务是可以共享Slot的。也就是说,一个Slot中可以运行多个任务。
client将Flink代码解析为JobGraph,并且会将一些子任务打包到一个任务中,每个任务运行在一个线程中。每一个任务都是运行在TaskManager中的Slot中。针对流式处理,Flink都会将一个完整的pipeline放在一个Slot中。
这样一个程序运行在一个有两个TaskManager、每个TaskManager有3个slot的Flink集群中。Flink并不是基于每个Operator执行实例来调度的,而是优先会将一个完整的Pipeline,调度到一个slot中。我们看到,针对此处的并行度设置,有三个slot中,都调度了完整的pipeline。
这种方式,可以提高程序运行的吞吐量。如果每一个operator并行度都以独立的线程执行,那么当线程数量较多时,线程需要不停地切换、缓存,这是会有一定开销的。
JobManager数据结构
在作业执行期间,JobManager会持续跟踪各个task,决定何时调度下一个或一组task,处理已完成的task或执行失败的情况。
JobManager 接收 JobGraph,JobGraph 是数据流的表现形式,包括算子(JobVertex)和中间结果(IntermediateDataSet)。每个算子都有诸如并行度和执行代码等属性。
我们编写的代码会转换为JobGraph。其实它也是有向无环图。既然是图结构,那就一定会有Vertex(顶点)以及Edge(边)。Flink中的JobGraph顶点就是JobVertex,它其实就是Flink中的Operator,而JobGraph的边就是IntermediateDataSet,Operator处理后的中间结果。
每个JobVertex都有自己的属性。例如:并行度、以及Operator要执行的代码。而且,为了确保每个JobVertex中的代码能够正确的在JVM中运行,每个JobGraph还得包含一组库(一堆的jar包)
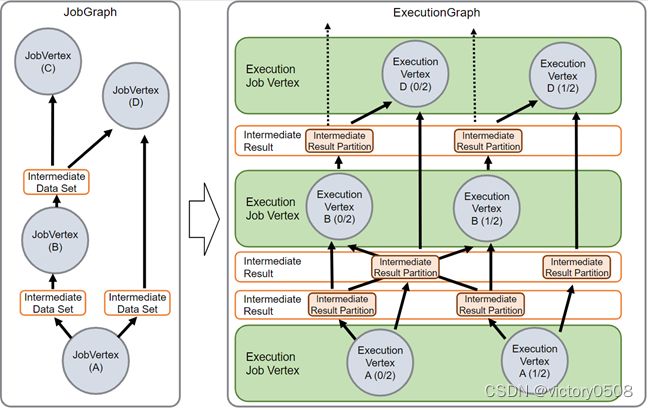
而要真正在集群中运行Flink程序,需要将JobGraph转换为ExecutionGraph。其实,可以把ExecutionGraph理解为JobGraph的并行版本,或者是JobGraph的并行放大。
ExecutionGraph中的顶点为ExecutionVertex。如果某个JobVertex的并行度为50,那么在ExecutionGraph中将会有50个ExecutionVertex(顶点)。每个ExecutionVertex包含了每个任务的执行状态。ExecutionGraph中的边就是IntermediatePartition。因为每个并行度顶点对应的中间结果数据其实就是一个个的分区。
作业状态
每个ExecutionGraph都有一个与之相关的作业状态信息,用来描述当前的作业执行状态。
- 一次完整的执行
Flink作业刚开始会处于一个created状态,然后开始调度运行时,切换到running状态。在作业运行完后切换到finished状态。

- 作业运行出现故障
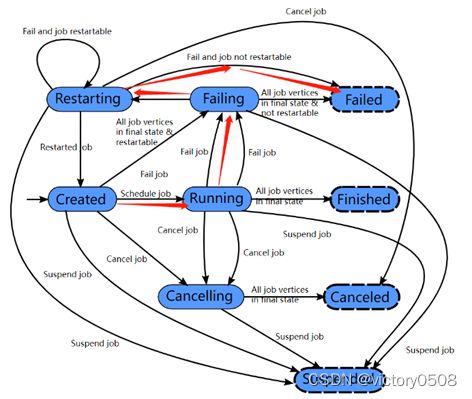
如果期间出现故障,作业首先切换到failing状态以便取消所有正在运行的task。如果所有job节点都到达最终状态并且job无法重启, 那么job 进入failed状态。
- 作业重启
如果作业运行期间出现故障,且作业可以重新启动,则作业会进入重启restarting状态,当作业彻底重启之后会进入到created状态。

- 用户手动取消作业
如果用户手动取消作业,它会进入到cancelling状态,并取消所有正在运行的 task。当所有正在运行的task进入到最终状态的时候,作业转换为cancelled状态。

- 作业挂起
Finished、canceled和failed会导致全局的终结状态,并且触发作业的清理。跟这些状态不同,suspended状态只是一个局部的终结。局部的终结意味着作业的执行已经被对应的JobManager 终结,但是集群中另外的JobManager 依然可以从高可用存储里获取作业信息并重启。因此一个处于suspended状态的作业不会被彻底清理掉。
Finished、Canceled、Failed状态都是全局终端状态,这些状态会触发作业的清理工作。而挂起suspended状态是一种本地终端状态。它意味着,如果作业已经在一个JobManager上是终止的,但如果是HA集群,另一个JobManager依然可以从HA存储中检索到Job,并重新启动。所以Suspended状态是不会进行Job的完全清理的。

- 任务的状态
在整个ExecutionGraph执行期间,每个并行task都会经历多个阶段,从created状态到finished或failed。下图展示了各种状态以及他们之间的转换关系。由于一个 task可能会被执行多次(比如在异常恢复时),ExecutionVertex的执行是由Execution来跟踪的,每个ExecutionVertex 会记录当前的执行,以及之前的执行。
