IP笔记全部整合(参考)
高级网络工程师
- HCIA回顾
-
- 1、网络基础
- 2、动态路由协议
- 3、路由认证
- 4、路由控制(AD metric )
- 一、知识巩固
- 二、场景模拟
-
- 1、获取IP地址
-
- 1.1 DHCP --- 动态主机配置协议
-
- 1.1.1 DHCP客户端
- 1.1.2 DHCP服务器
- 1.1.3 DHCP客户端
- 1.1.4 DHCP服务器
- 2、打开浏览器
- 3、路由器进行路由
- 4、DNS服务器进行查找
- 5、TCP三次握手
- 6、HTTP请求
- 7、HTTP应答
- 三、OSPF基础
-
- 1、OSPF 特点
- 2、OSPF 区域
- 3、OSPF 消息数据包
- 4、OSPF 邻居状态机制
- 5、OSPF基本配置
- 四、OSPF网络类型
-
- 1、P2P
- 2、BMA
- 3、NBMA
- 4、P2MP
- 5、OSPF 认证
- 6、OSPF 路由控制
- 五、OSPF LSA详解
-
- 1、1类LSA:
- 2、2类LSA
- 3、3类LSA
- 4、5类LSA
- 5、4类LSA
- 6、7类LSA
- 7、FA
- 8、OSPF 中的计时器
- 六、OSPF总结
-
- 1、OSPF区域划分的要求
- 2、OSPF的基本配置
- 3、结构突变
- 4、条件匹配
- 5、DR/BDR选举
- 6、OSPF的数据包
- 七、OSPF不规则区域问题
-
- 1、使用VPN隧道
- 2、使用OSPF虚链路来解决不规则区域
- 八、特殊区域
-
- 1、第一大类特殊区域
- 2、第二大类特殊区域
- 3、特殊区域的标记位
- 4、OSPF的拓展配置
-
- 4.1 手工认证
- 4.2 缺省路由
- 4.3 沉默接口
- 4.4 加速收敛
- 4.5 路由过滤
- 4.6 路由控制
- 4.7 OSPF的附录E
- 九、广域网技术
-
- 1、HDLC
- 2、PPP
- 3、PAP
- 4、CHAP
- 5、GRE
- 6、运行路由协议
- 十、动态路由协议
-
- 1、OSPF
- 2、重发布
- 3、路由策略
-
- 3.1 抓流量
- 3.2 具体过程
- 4、BGP
- 十一、BGP边界网关协议
-
- 1、BGP的数据包
- 2、BGP的状态机
- 3、BGP的工作过程
- 4、BGP的路由黑洞问题
- 5、BGP的防环问题
- 6、BGP的基本配置
-
- 6.1 对等体关系建立
-
- 1)EBGP直连邻居建立
- 2)IBGP对等体之间环回接口建邻
- 3)EBGP对等体之间的非直连建邻
- 4)路由发布
- 十二、BGP的选路原则以及社会团属性
-
- 1、BGP的选路原则
- 2、BGP的路由过滤
- 3、BGP的社会团属性
- 十三、MPLS多协议标签交换
-
- 1、标签交换
- 2、静态LSP搭建
- 3、LDP协议
- 4、本地LDP会话建立的过程
- 十四、MPLS VPN的配置使用
- 十五、实际情况配置
- 十六、VLAN之间通信
-
- 1、生成树技术
- 2、配置BPDU
- 十七、完整通信分类
-
- 1、实现VLAN之间通信
- 2、使用路由器物理接口
- 3、使用路由器子接口
- 4、使用三层交换机的VLANIF接口
-
- 4.1 配置
- 4.2 VLANIF的转发流程
- 5、三层交换机参与下的三层通信流程
-
- 5.1 网络拓扑
- 5.2 连接逻辑图
- 5.3 通信过程
- 6、二层与三层接口对比
- 十八、STP
-
- 1、STP概述
- 2、二层环路带来的问题
-
- 2.1 广播风暴问题
- 2.2 MAC地址漂移问题
- 2.3 多帧复制
HCIA回顾
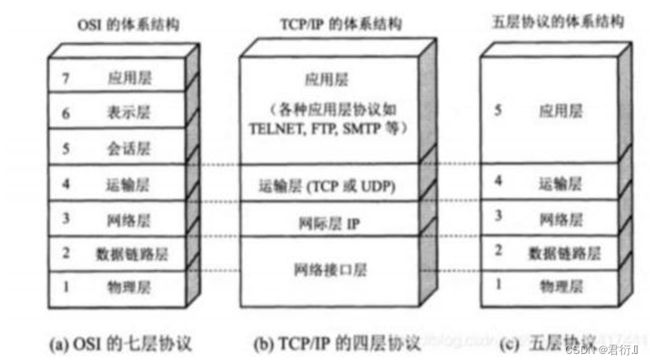
1、七层参考模型及IP讲解
2、TCP三次握手讲解
3、TCP四次挥手讲解及抓包分析
4、DHCP协议讲解及抓包分析
5、静态综合实验讲解
7、静态路由讲解
8、RIP路由信息协议讲解
9、动态路由协议讲解
10、抓包进行分析RIP以及OSPF的包
11、动态路由OSPF配置综合实验讲解
12、Vlan虚拟局域网技术讲解
13、ACL访问控制列表讲解
14、NAT技术讲解
15、网络综合实验讲解
1、网络基础
1、OSI模型 :七层参考模型及IP讲解
2、传输层: 区分不同的流量 ; 定义数据的传输方式
TCP:是一种面向连接的可靠的传输协议
UDP:是一种非面向连接的不可靠的传输协议
3、TCP :
序列号 32个二进制 ,发送数据的顺序
确认号 32个二进制 ,确认数据时使用的
4、TCP 三次握手 TCP三次握手讲解
5、TCP 四次挥手 TCP四次挥手讲解及抓包分析
6、UDP:没有ACK 号 没有序列号
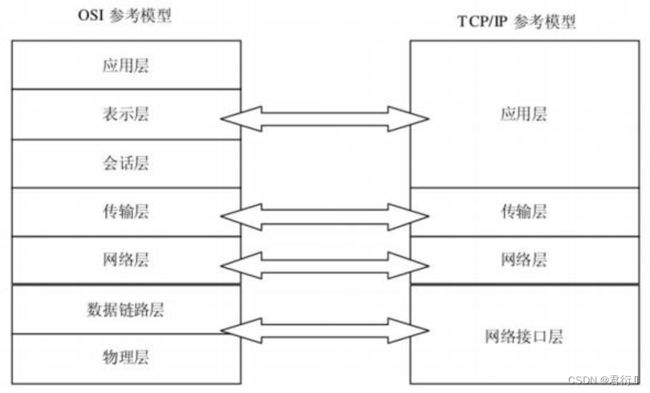
7、TCP/IP模型:
应用层(应用 表示 会话)
端到端层(传输层)
互联网层(网络层)
网络接口层(数据链路 物理层)
8、OSI与TCP/IP模型区别:
1.封装 OSI 模型数据封装必须具有完整的封装; TCP/IP支持跨层封装
2.使用 OSI 一般理论 ; TCP/IP 一般用于工业生产
3.协议 OSI支持多种网络层协议;TCP/IP仅仅支持IP协议栈(IPV4 IPV6)
9、ARP : 地址解析协议
正向ARP
反向ARP
逆向ARP
无故ARP—免费ARP
代理ARP-proxy ARP
10、路由: 按照路由条目,逻辑选址。
- 控制层面: 路由条目的加表;
AD metric(华为中priority cost) - 数据层面: 按照路由条目转发数据包;1.与操作 2.最长匹配 3.递归查找
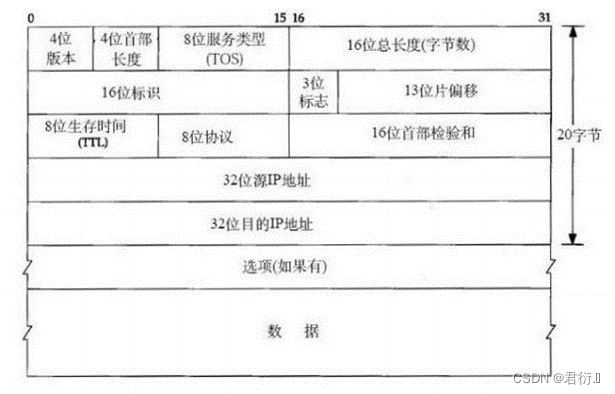
11、IPV4数据包结构:

12、静态路由:
- 1、出接口(一般建议在点对点的网络结构中使用)
- 2、下一跳地址(一般建议在非点对点(MA 多路访问网络结构中使用))
注意: 在思科中, 不同的网络类型中可以使用出接口或下一跳(以上的给出的只是建议);
在华为,若为MA网络结构,必须使用下一跳或出接口+下一跳
- 3.出接口+下一跳
- 4.浮动静态路由
13、思科做法:
- 1.定义SLA (定义发送数据包的类型以及频率,SLA的工作时间)
ip sla 1----#定义SLA的编号
icmp-echo 10.1.1.2 source-ip 10.1.1.1---#定义发送流量的类型
frequency 5---#定义频率
ip sla schedule 1 start-time now---#设置SLA的起始时间,没写终止代表发送3600s
- 2.定义
track跟踪

- 3.在静态路由中调用
track

14、测试:
华为浮动静态路由:
- 1.定义BFD会话
BFD----启动BFD功能
bfd 1 bind peer-ip 10.1.1.2 source-ip 10.1.1.1---#定义BFD会话信息
discriminator local 1----#定会一条会话的本地编号
discriminator remote 2
commit---#启动(提交)
- 2.在静态路由中通过
track调用BFD会话
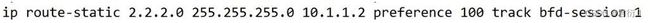
查看BFD会话:

- 3.永久静态路由 (思科与华为完全一致)
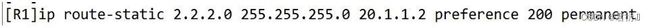
- 4.缺省路由
2、动态路由协议
1、动态路由协议: RIP OSPF EIGRP ISIS BGP
2、动态路由协议的分类:
- 1.按照使用范围进行分类:
IGP BGP AS— 自治系统 - 2.按照协议的算法特点进行分类:距离矢量型 ;链路状态型
- 3.按照是否携带网络掩码进行类:有类别路由协议 ;无类别路由协议
3、RIP : 路由信息协议
-
1.适用范围:
IGP -
2.协议算法特点:距离矢量型(DV),贝尔曼福特算法
-
3.是否携带网络掩码:RIPV1不携带 RIPV2携带
-
4.协议数据包的封装:基于UDP封装,使用端口号 520
-
5.RIP协议描述:路由器通过周期性发送消息数据包来传递路由信息(
request请求response 响应),周期时间30s ,支持路由认证,支持路由手工汇总。 -
6.RIP 携带路由信息的报文:
response基于UDP封装。一条RIP更新报文最多包含25条路由信息,若启用路由认证,则最多传递24条路由信息。 -
7.RIP的防环机制
-
- 异步更新机制
-
- 水平分割机制
-
- 毒性逆转水平分割机制
-
8.RIP计时器机制:思科(update 更新 30s invalid 无效180s holddown 抑制180s flush 刷新240s);华为(更新 30s 无效 180s 垃圾回收 120s )
-
9.RIP支持触发更新,并且默认开启。(华为中默认开启了触发更新 ,思科中默认关闭)
-
10.修改接口的RIP协议版本:

-
11.RIP 协议部署:
-
- 1.RIP 协议支持多进程 ; 进程号只具有本地意义
-
- 2.手工汇总
-
- (1)目的:
-
-
- 1.减少路由条目数量,减小路由表大小,加快查表速度
-
-
-
- 2.增加网络稳定性
-
-
- (2)位置: 在路由传播的出方向接口实施,建议在明细路由所在路由器的出接口
-
- (3)cost计算: 汇总路由cost使用所有明细路由中cost最小的(思科华为一致)
-
- (4)存在条件: 至少存在一条明细路由
-
- (5)特性:
-
- 在思科中,仅仅支持
VLSM,不支持CIDR
- 在思科中,仅仅支持
-
- 在华为中,支持
VLSM和CIDR
- 在华为中,支持
-
- 在IGP中,发送了汇总会自动抑制明细路由的发送
不自动产生指向NULL0 的防环路由
- 在IGP中,发送了汇总会自动抑制明细路由的发送
VLSM—可变长子网掩码技术
CIDR—无类别域间路由技术,又称为super net 超网
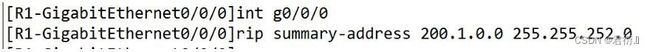
- 12.查看:
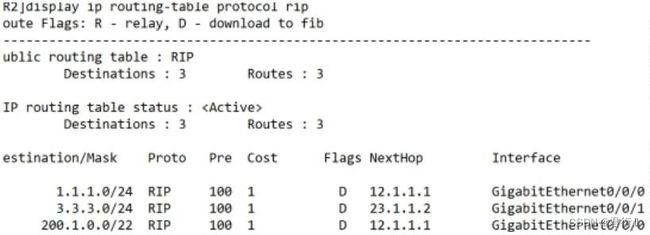
3、路由认证
- 1、启用明文认证:

- 2、启用MD5认证: 需要部署 key - id

4、路由控制(AD metric )
-
1、修改优先级(AD值):

-
2、查看:

-
3、修改
cost(metric值):接口使用分为in out,in代表接口增加度量值为多少,out代表增加度量值到多少;in out都可以配合ACL或前缀列表控制针对部分;路由修改度量值。(metric值调整只能增加不能减少)

-
4、查看ACL :

-
5、**过滤路由:**过滤列表,类似于
cisco中的分发列表(过滤列表)自身不具备过滤功能,需要调用ACL或前缀列表;可以在import或export方向上实施。 -
- 1.设置
ACL

- 1.设置
-
- 2.使用
filter-policy
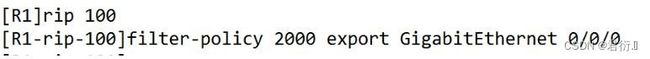
- 2.使用
-
6、被动接口(静默接口)
针对组播或广播的路由信息只收不发
设置接口为静默接口:
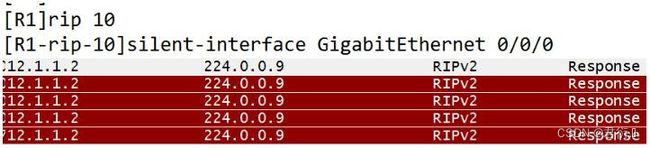
-
7、单播邻居: 发送RIP消息数据包使用单播方式发送,单播邻居技术并不影响组播的发送。
单播邻居+被动接口=单播被动 -
8、单播邻居:

-
9、被动接口:
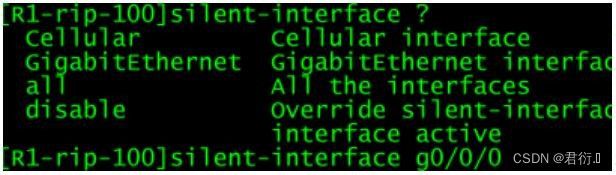
-
10、单播被动测试:
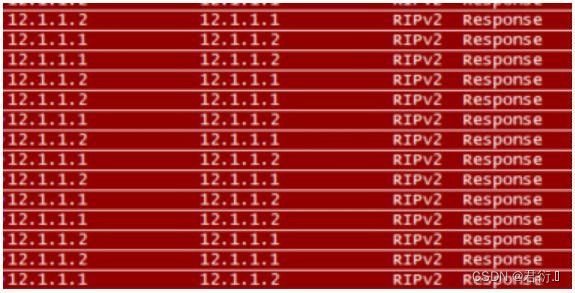
-
11、更新源检测
适用于所有的IGP协议
关闭更新源检测:

-
12、缺省路由:
默认路由 -
- 1.
default-route
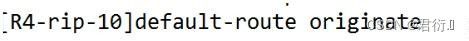
- 1.
-
- 2.汇总产生缺省

- 2.汇总产生缺省
一、知识巩固
抽象语言——电信号
抽象语言——编码
编码——二进制
二进制——电信号
处理电信号
OSI/RM——开放式系统互联参考模型——1979——ISO——国际标准化组织
1、核心思想——分层
- 应用层——提供各种应用程序, 抽象语言转换成编码, 人机交互的接口
- 表示层——编码转换成二进制
- 会话层——维持网络应用和网络服务器之间会话连接
- 传输层——实现端到端的传输——应用到应用*之间的传输——端口号——0-65535——0一般不作为传输层的端口号使用,所以,我们真实的端口号的取值范围为
1-65535。
1 - 1023知名端口号——SPORT, DPORT(来源端口以及目的端口) - 网络层——通过IP地址, 实现主机之间的逻辑寻址。 ——SIP, DIP
2、获取DIP的方法:
DIP是指动态IP,也称为动态IP地址。简单来说,动态IP是由互联网服务提供商(ISP)动态分配给用户使用的IP地址。每当用户重新连接到网络时,ISP就会分配一个新的IP地址,这个过程是自动完成的,无需用户手动干预。相对应的,静态IP是一个固定的IP地址,通常需要用户手动设置或花费更多的费用向ISP申请。
- 1, 直接知道服务器的IP地址
- 2, 通过域名访问服务器
- 3, 通过应用程序访问
- 4, 通过广播获取
3、数据链路层——将二进制转换成电信号。通过MAC地址进行物理寻址——在以太网协议中
MAC——48位二进制构成——1, 全球唯一; 2, 格式统一——SMAC, DMAC
4、获取目标MAC地址的方法:
(1)ARP——地址解析协议——通过一种地址获取另一种地址
(2)正向ARP——通过IP地址获取MAC地址
(3)工作过程——首先, 主机以广播的形式发送ARP请求报文。基于已知的IP地址获取 MAC地址。所有收到广播帧的设备都会先将数据包中的源IP地址和源MAC地址的对应关系记录在本地的ARP缓存表中。之后, 再看请求的IP地址。
- 如果请求的IP地址是本地的IP地址,则将
回复ARP应答报文。 - 如果请求的IP地址不是本地的IP地址,则将直接丢弃该数据包。
之后,再次发送信息时,将优先查看本地的ARP缓存表,
- 如果存在记录,则将按照记录转发;
- 如果没有记录,则再发送ARP请求。
(4)反向ARP——通过MAC地址获取IP地址
(5)免费ARP——利用的是正向ARP的工作原理, 只不过请求的IP地址是自己的。
1, 自我介绍; 2, 检测地址冲突
物理层 — 处理或传输电信号
5、TCP/IP模型——TCP/IP协议簇
TCP/IP标准模型 — 四层模型
TCP/IP对等模型 — 五层模型
6、封装和解封装
- 应用层
- 传输层——端口号——TCP, UDP
- 网络层——IP地址——IP协议
- 数据链路层——MAC地址——以太网协议
- 物理层
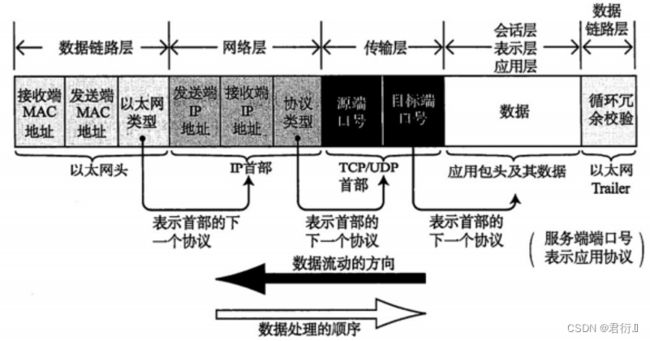
7、PDU——协议数据单元
- 应用层——报文
- 传输层——段
- 网络层——包
- 数据链路层——帧
- 物理层——比特流
TCP/IP模型中可以支持跨层封装, OSI中不行
8、跨层封装
- 跨层封装出现的情况较少——一般出现在直连的设备之间。
- 跨四层封装——一般出现在直连路由设备之间,比如,OSPF协议就是跨四层封装协议。——
89
- 跨三, 四层封装——直连交换机之间——stp

10、SOF——帧首定界符
SOF通常指代Start of Frame,指的是数据传输中的起始帧。
在串口通信等程序中,传输的数据需要有一个明确的起始标志,这个标志就是SOF。
SOF一般会作为串口通信协议的一部分,用于设定数据包的起始位置,通常由一个唯一字符、数字或其他标识符组成,不同协议中的SOF字符可能有所不同。
SOF的作用:
在接收端标志数据包的开始,使得接收端可以准确地解析数据。
SOF通常会在数据包中的开头作为起始标志,和结束帧的标志(EOF,End of Frame)一起构成了一个数据包的完整性,在数据传输的过程中起到了很重要的作用。
需要注意的是,SOF不是一种通用的协议,而是由具体的通信协议来定义的。在实际应用中,需要根据具体的分析来设定SOF的值,以确保数据的准确传输。
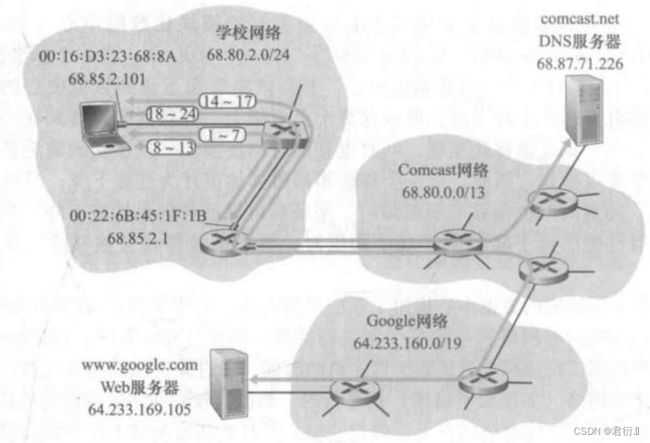
1,获取IP地址——1,手工获取; 2,通过DHCP自动获取
11、DHCP——动态主机配置协议
- DHCP客户端——广播包——DHCP-Discover
传输层——UDP——SPORT: 68 DPORT: 67
网络层——IP——SIP: 0.0.0.0 DIP: 255.255.255.255
数据链路层——以太网——SMAC: 自己的MAC地址 DMAC:全F
12、交换机的转发原理——交换机收到数据帧之后,首先先记录源MAC地址和进入接口的对应关系到MAC地址表中。之后看数据帧中的目标MAC地址,因为目标MAC 地址是全F,则将进行泛洪 — 除了数据进入的接口外,所有接口都将转发数据。
13、交换机泛洪的情况 ——1,广播帧; 2,组播帧;3,未知单播帧
二、场景模拟
1、获取IP地址
1,手工获取;2,通过DHCP自动获取
1.1 DHCP — 动态主机配置协议
1.1.1 DHCP客户端
DHCP客户端 — 广播包 — DHCP-Discover
传输层 — UDP — SPORT:68 DPORT:67
网络层 — IP — SIP:0.0.0.0 DIP:255.255.255.255
数据链路层 — 以太网 — SMAC:自己的MAC地址 DMAC:全F
交换机的转发原理 — 交换机收到数据帧之后,首先先记录源MAC地址和进入接口的对应关系到MAC地址表中。之后看数据帧中的目标MAC地址,因为目标MAC地址是全F,则将进行泛洪 — 除了数据进入的接口外,所有接口都将转发数据。
交换机泛洪的情况 — 1,广播帧;2,组播帧;3,未知单播帧
路由器收到广播包之后 — 路由器收到数据帧之后先看二层封装,(因为其目标MAC地址为广播地址,则路由器讲解二层封装)。则将根据数据帧中的类型字段将解封装后的数据包交给对应的IP模块进行处理。(因为三层头部中目标IP地址为受限广播地址),则路由器将解三层封装。(因为三层协议头部中协议字段为17),则路由器将把解封装后的数据段交给UDP模块进行处理。UDP根据目标端口号为67,则将解封装后的DHCP-DISCOVER报文交给对应的DHCP服务进行处理。
1.1.2 DHCP服务器
DHCP服务器 — DHCP客户端 ---- DHCP-OFFER(里面将携带一个可用的IP地址) — 单播/广播
传输层 — UDP — SPORT:67 DPORT:68
网络层 — IP — SIP:自己的IP DIP:255.255.255.255
数据链路层 — 以太网 — SMAC:自己的MAC地址 DMAC:全F ---- 注意,
华为设备以单播的形式来发送DHCP-offer包
1.1.3 DHCP客户端
DHCP客户端 — DHCP服务器 — DHCP - request (如果存在多个DHCP-OFFER包,则设备将选择第一个到达的OFFER包) — 广播
- 1,告诉请求IP地址的服务器,需要请求他的IP地址;
- 2,告诉没有选择的IP地址的服务器,自己已经有IP地址了,可以将他们的IP地址释放。
1.1.4 DHCP服务器
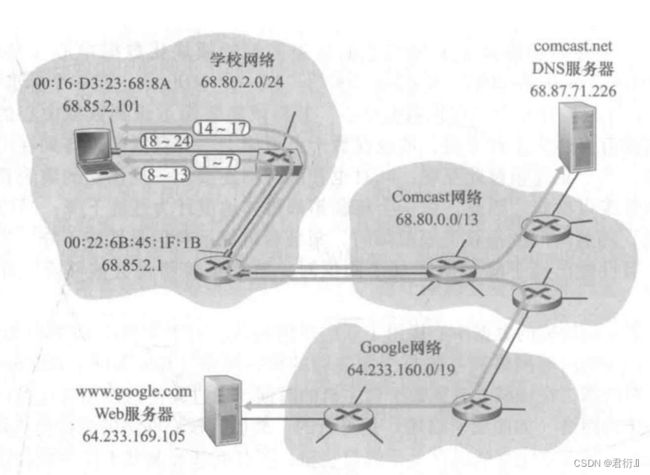
DHCP服务器 — DHCP客户端 — DHCP - ACK — 单播/广播
设备在通过DHCP协议获取一个IP地址的同时,还会获取到网关信息(68.85.2.1)以及DNS服务器的信息(68.87.71.226)
2、打开浏览器
在浏览器中的地址栏上输入需要访问的服务器的URL(资源定位符)
1、DNS — 域名解析协议
DNS协议存在两种查询方式 ---- 1,递归查询;2,迭代查询
设备将从输入的URL中提取到域名信息,根据域名信息通过DNS协议获取web服务器的IP地址
2、设备将发送DNS请求报文(本地设备会发送递归查询请求到本地DNS服务器)
传输层 — UDP — SPORT:随机值 DPORT:53
网络层 — IP — SIP:68.85.2.101 DIP:68.87.71.226
数据链路层 — 以太网 — SMAC:自己的MAC DMAC:???
3、ARP — 地址解析协议
- 工作过程
-
- 1、首先,主机以广播的形式发送ARP请求报文。
-
- 2、基于已知的IP地址获取MAC地址。所有收到广播帧的设备都会先将数据包中的源IP地址和源MAC地址的对应关系记录在本地的ARP缓存表中。
-
- 3、之后,再看请求的IP地址。
-
-
- 如果请求的IP地址是本地的IP地址,则将回复ARP应答报文。
-
-
-
- 如果请求的IP地址不是本地的IP地址,则将直接丢弃该数据包。
-
-
- 4、之后,再次发送信息时,将优先查看本地的ARP缓存表,
-
-
- 如果存在记录,则将按照记录转发;
-
-
-
- 如果没有记录,则再发送ARP请求。
-
传输层 — UDP — SPORT:随机值 DPORT:53
网络层 — IP — SIP:68.85.2.101 DIP:68.87.71.226
数据链路层 — 以太网 — SMAC:自己的MAC DMAC:网关的MAC地址
3、路由器进行路由
网关路由器收到DNS请求报文之后,将先查看数据帧的二层封装,确认该数据帧是给自己的,则将解二层封装看三层,根据目标IP地址查看本地的路由表。
- 直连路由 — 直连路由是默认生成的,生成条件 1,接口双UP;2,接口需要配置IP地址
- 静态路由 — 网络管理员手工添加的路由条目
- 动态路由 — 所有路由器运行相同的路由协议,之后,路由器之间沟通,交流最终计算
出到达未知网段的路由条目。
4、DNS服务器进行查找
本地的DNS服务器收到DNS请求信息,则将先查看本地缓存是否有记录,
- 有则直接返回DNS应答;
- 如果没有,则向DNS根服务器发送迭代查询(TCP 53)。最终将结果返回给设备。
5、TCP三次握手
本地设备将基于web服务器的IP地址,发起TCP三次握手,建立TCP会话。
(主要因为HTTP协议传输层使用的是TCP协议)— 建立本地到服务器之间双向的会话
6、HTTP请求
本地设备将基于TCP会话通道发送HTTP请求报文 — GET
传输层 — TCP — SPORT:随机值 DPORT:80
网络层 — IP — SIP:自己的IP DIP:baidu的IP
数据链路层 — 以太网 — SMAC:自己的MAC DMAC:网关的MAC
7、HTTP应答
baidu服务器收到HTTP请求报文,则服务器将解封装,
最终回复HTTP应答报文。
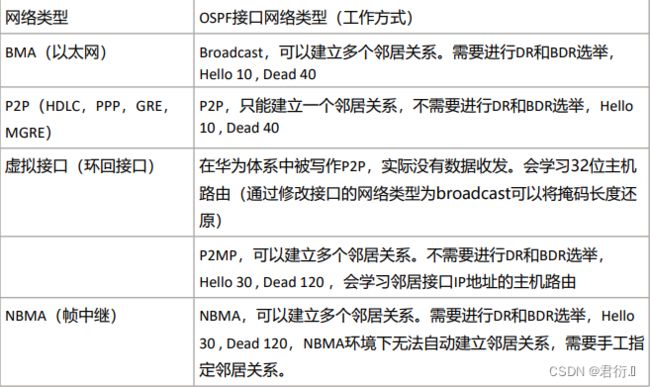
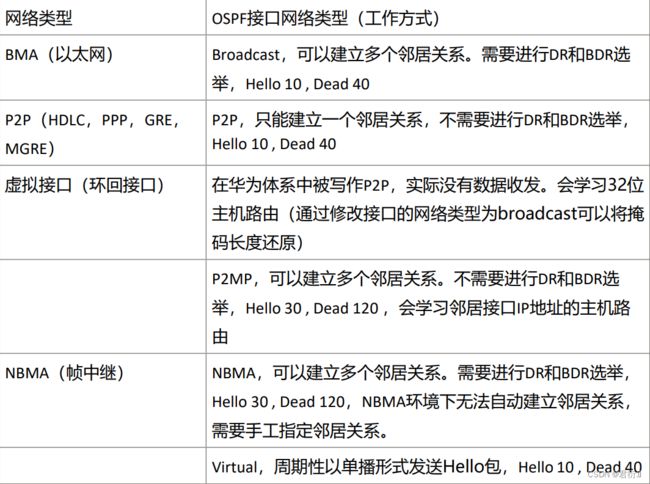
1、网络类型 — 根据数据链路层运行的协议进行划分的
P2P— 点到点MA— 多点接入网络BMA— 支持广播的多点接入网络NBMA— 非广播型多点接入网络
2、数据链路层运行的协议
2.1 以太网协议 — 需要在数据帧中封装MAC地址进行寻址。
2.2 原因 — 利用以太网协议组建的网络中可以包含两个或两个以上的接口,每个以太网接口之间都可以通过交互以太网帧的方式进行二层通讯。 — BMA
如果一个网络中只能有两台设备,则这样的网络不需要MAC地址进行区分标识,也可以正常通信,这样的网络,我们称为P2P网络。
- T1 – 1.544Mbps
- E1 – 2.048Mbps
以太网做到了一个技术 — 频分技术 — 所谓频分,就是一根铜丝上可以同时发送不同频段的电波而互不干扰,实现数据的并行发送。
- 1,HDLC
- 2,PPP
3、HDLC — 高级数据链路控制协议
- 标准的HDLC:ISO组织基于SDLC协议改进得到的
- 非标的HDLC:各大厂商在标准的HDLC基础上再进行改进而成
(思科设备组建串线网络默认使用的协议是HDLC协议,华为设备组建串线网络默认使用的协议是PPP协议。)
[r1]display interface Serial4/0/0 --- #查看接口的二层特征
[r1-Serial4/0/0]link-protocol hdlc --- #修改接口协议类型
4、PPP — 点到点协议
- 1,兼容性强 — 拥有统一的版本,并且串线种类比较多,只要支持全双工的工作模式,则可以支持PPP协议。
- 2,可移植性强 — PPPoE
- 3,PPP协议支持认证和授权
PPP和TCP协议类似,在正式传输数据之前,也需要经历建立会话的过程。
- 1,链路建立阶段 — LCP(链路控制协议)建立
- 2,认证阶段 — 可选项
- 3,网络层协议协商阶段 — NCP(网络控制协议)协商 — IPCP协议
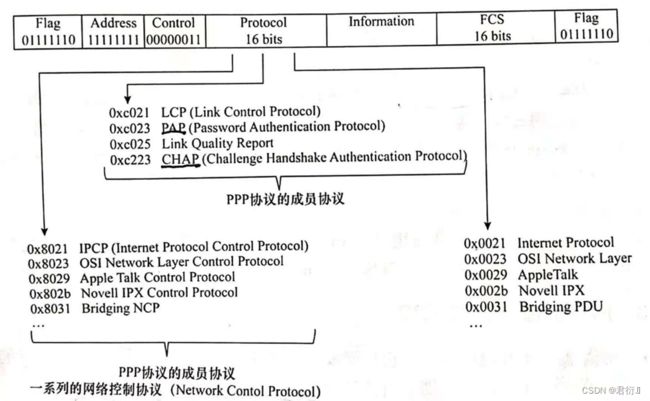
PPP协议包含若干个附属协议
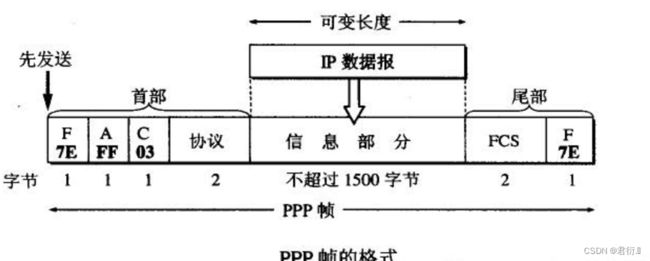
- F — FLAG — 01111110
- A — Address — 111111111
- C — Coltrol — 00000011
- 1,链路建立阶段 —
LCP(链路控制协议)建立
所谓链路建立,其实就是参数协商的过程
MRU— PPP帧中数据部分允许携带的最大长度(字节) — 默认1500字节

- 2,认证阶段
三、OSPF基础
OSPF : 开放式最短路径优先协议
- 1、使用范围: IGP
- 2、协议算法特点: 链路状态型路由协议,SPF算法
- 3、协议是否传递网络掩码: 传递网络掩码
- 4、协议封装: 基于IP协议封装,协议号为 89
1、OSPF 特点
- 1.OSPF 是一种典型的链路状态型路由协议
-
- 传递信息称作LSA ,**
LSA 链路状态通告,包含路由信息和拓扑信息。
- 传递信息称作LSA ,**
-
- 路由LSA:描述本路由器上接口的
路由信息
- 路由LSA:描述本路由器上接口的
-
- 拓扑LSA:描述路由器之间的
连接状态
- 拓扑LSA:描述路由器之间的
- 3.更新方式:触发更新
+30分钟的链路状态刷新 - 4.更新地址:组播和单播更新,
组播地址:224.0.0.5(ALL SPF router)224.0.0.6(ALL DR router) - 5.支持路由认证
- 6.支持手工汇总
- 7.支持区域划分
- 8.OSPF 比较消耗设备资源
2、OSPF 区域
1、区域划分的意义:
- 1.减少LSA的数量
- 2.减少LSA的传播范围
区域的划分是基于接口的(链路的)
2、区域的标记: 使用了32个二进制
- 1.十进制
- 2.类似于IP地址 A.B.C.D
3、区域的分类:
- 骨干区域: 区域标记为0或0.0.0.0
- 非骨干区域:区域标记不等于0或0.0.0.0
4、区域设计原则: 向日葵型网络结构
- 1.OSPF网络中必须存在并唯一的骨干区域(单区域除外)
- 2.若存在非骨干区域,非骨干区域必须与骨干区域直接相连
5、OSPF中路由器的角色:
- 骨干路由器
- 非骨干路由器
- ABR:区域边界路由器, 能够产生3类LSA的路由器
- ASBR:自治系统边界路由器, 能够产生5类或7类LSA的路由器
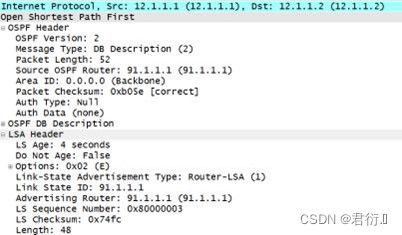
3、OSPF 消息数据包
Hello DBD LSR LSU LSACK
hello :周期性发送,周期时间10s或30s
(根据不同的网络类型默认 10s或30s)
目的: 建立并维持OSPF 邻居关系
(邻居关系建立之后充当保活包功能)
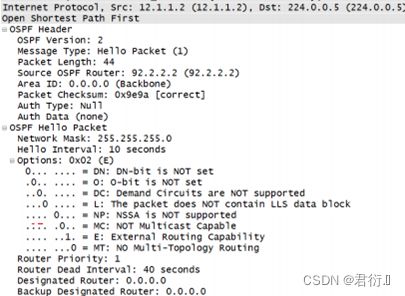
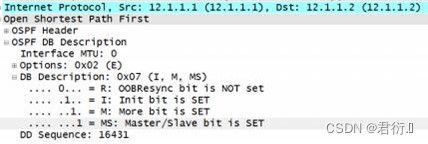
DBD: 数据库描述数据包;
- 1.主从选举DBD: 比较双方的
router-id,router-id大的一方为主 (master),小的一方为从(slave); 主用于控制LSA的交互
- 2.携带LSA头部信息的DBD
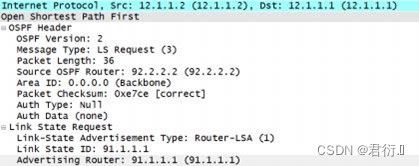
LSR : 链路状态请求,按照DBD中报文的未知LSA头部进行请求。
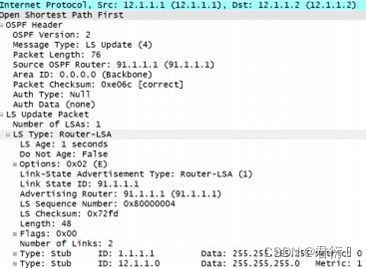
LSU:链路状态更新,携带LSA信息。
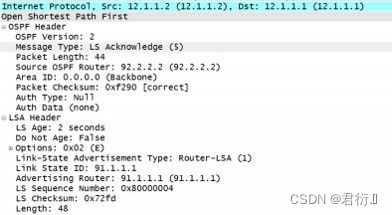
LSACK: 链路状态确认
4、OSPF 邻居状态机制
Down 、 init 、 attempt (尝试 过渡) 、 two-way 、 exstart 、 exchange 、loading 、full
Init —初始化状态,一旦开始发送hello报文, 进入初始化状态。
Two-way—双向通信状态(邻居状态),接收到包含自己router-id 的对方hello报文
1、邻居关系建立条件:
- 1.
router-id必须不同 - 2.
area ID相同 - 3.认证:
-
- 认证类型 (不认证=0 明文认证=1 MD5=2)
-
- 认证数据
- 4.
hello时间,dead时间必须一致 - 5.特殊区域标识一致
-
- (E(外部路由位) =1;N(NSSA外部路由 位)=0 P=0)
- 6.
MA网络中,网络掩码必须一致 - 7.必须同时使用单播或组播更新
- 8.更新源检测(双方的IP地址必须在同一网段)
邻居状态下(two-way): MA的网络中会选举DR (指定路由器) BDR (备份指定路由器)
2、DR选举:
- 1.==比较优先级 ==
(范围: 0-255,默认优先级为1 ,越大越优) - 2.比较各自的
router-id,越大越优
注意:
- 1.DR抢占是关闭的
- 2.DR是一个接口概念
- 3.优先级范围0-255,数字为0代表不参与选举
- 4.先选举BDR ,再升级为DR
3、主从选举:发生在exstart状态, 通过双方的router-id进行比较,router-id大的一方为主。 发送的主从选举DBD ,DBD中包含了MTU值(默认思科直接启用, 华为中默认不包含MTU,可以使用命令激活传递MTU值的功能,若双方的MTU值不值则卡在exstart 状态)。
4、Exstart—预启动状态
一旦开始发送主从DBD,则进入预启动状态。
5、Exchange —预交换,
- 主从选举完成,则发送携带LSA头部信息的DBD,
- 进入预交换状态,会发送LSR数据包。(但是没有LSU)
6、Loading —加载状态
一旦发送LSU数据包,进入了加载状态, 进行 大量LSA的学习。
7、Full —邻接状态。双方LSA同步(双方LSA全部学习)
5、OSPF基本配置
启用OSPF并指定router-id

1、Router-id:路由器标识符,用于标识本路由器在OSPF网络中的唯一性
2、OSPF router-id 选举规则:
- 1.手工指定最优先
- 2.选举所有逻辑中IP地址最大的
- 3.选举所有物理接口IP地址最大的
3、华为中:
- 若以上三点都不满足,则可以创建router-id 为0.0.0.0;
- 在使用逻辑或物理接口IP地址时,接口可以是关闭状态;
- 若一台路由器启用了多个 OSPF进程,不同进程可以使用相同的router-id (不推荐);
4、思科中:
- 若以上三点都不满足, 则无法启用OSPF;
- 在使用逻辑或物理接口时,接口必须双 up,该接口可以不通告进入OSPF中
- 同一路由器上多个 OSPF进程必须router-id必须不同;
全局模式下可以选择针对所有的OSPF进程修改router-id ;(若同时在接口部署时,接口优先生效)
![]()
5、查看:

- 1、Network通告:

- 2、必须先创建OSPF 进程并开启需用使用的区域ID,再进入接口启用:

- 3、激活DBD中携带MTU值功能:

- 4、修改接口MTU值: (同时修改3层和2层的MTU值)

- 5、查看二层接口信息:
![]()
- 6、查看三层信息:

6、OSPF三张表:
- 1.OSPF 邻居表
查看OSPF邻居表
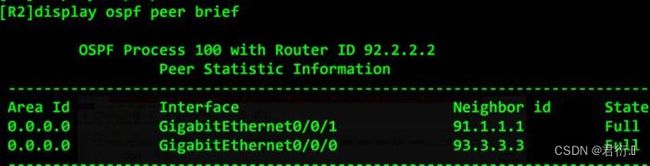
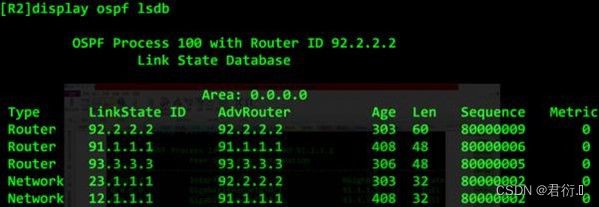
- 2.LSDB表(链路状态数据库)
查看LSBD的摘要信息:
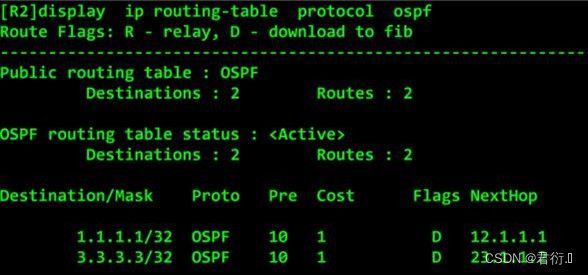
- 3.OSPF 路由表:
7、LSA中存在3个参数用于LSA的新旧比较:3600s的LSA 都是最新的
- 1.序列号
- 2.校验和
(若以上都相同, LSA age 之差小于15分钟,越小越优,若大于15分钟,则无法比较 认为都是最新的。)
四、OSPF网络类型
loopback
- 1.
P2P - 2.
BMA—广播多路访问网络 - 3.
NBMA—非广播型多路访问网络 - 4.
P2MP - 5.
V-link
注意: loopback接口默认OSPF网络类型为P2P,但是生成路由的网络掩码默认为32位 还原真实网络掩码思科中修改类型为P2P,华为中修改为BMA类型,并且cost为 0(cost不会因为参考带宽或者接口带宽变化而变化)
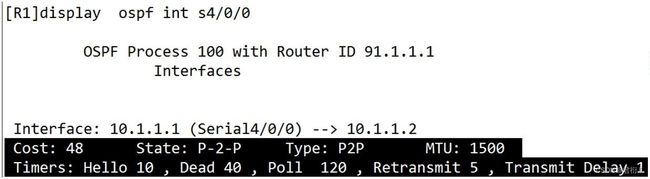
1、P2P
1.1 物理接口: HDLC(高级数据链路控制协议) PPP (点对点协议) GRE MGRE FR 点对点子接口
1.2 hello时间: 10s
1.3 是否选丼DR: 不选丼
1.4 是否自动建立邻居: 自动建立
1.5 特性:
2、BMA
2.1 物理接口:以太网
2.2 hello时间:10 s
2.3 是否选丼DR:选丼
2.4 是否自动建立邻居:是
2.5 特性: 产生的1类LSA不完整,需要2类LSA补充
3、NBMA
3.1 物理接口:FR-帧中继(物理接口、多点子接口) ATM-异步传输网络 (Cisco中的MGRE)
3.2 hello时间: 30s
3.3 是否选丼DR: 选丼DR
3.4 是否自动建立邻居: 否(建立邻居需要手工指定peer ,思科中单边指定就可以,华为需要双方同时指定)
3.5 网络部署类型: 1.full-mesh 2.part-mesh 3.hub-spoke
==在hub-spoke网络中,若默认网络类型为NBMA : ==
-
- 1.手工指定peer
-
- 2.控制DR位置,不得出现BDR
-
- 3.spoke之间互指映射(PVC)
4、P2MP
4.1 物理接口: 无
4.2 hello时间: 30s
4.3 是否选丼DR: 不选丼
4.4 是否自动建立邻居: 自动
4.5 特点: 将物理接口IP地址以32位主机路由的形式传递进入OSPF
5、OSPF 认证
链路认证、区域认证、虚链路认证
- 1.链路认证

- 2.区域认证

查看 :
6、OSPF 路由控制
1、默认: 1 3 类LSA
AD值为10 , 5类 7类 LSA AD值为150
2、修改AD值:
- 1.OSPF 进程直接修改AD值,仅仅针对 1 3 类LSA。
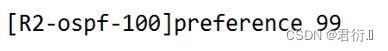
- 2.修改5 7类LSA AD值

查看:

3.修改metric (cost)
- 1、修改参考带宽:

查看:
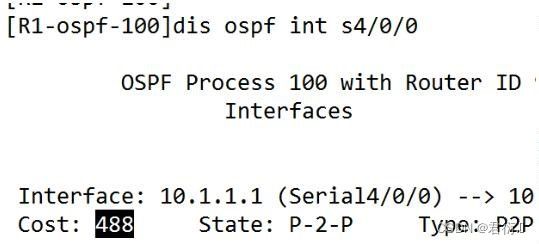
- 2、修改接口cost值

查看:

五、OSPF LSA详解
OSPFV2----LSA 1 2 3 4 5 7
描述一条LSA:
- 1.LSA 类型
- 2.link-ID 链路标识符
- 3.ADV router 产生路由器
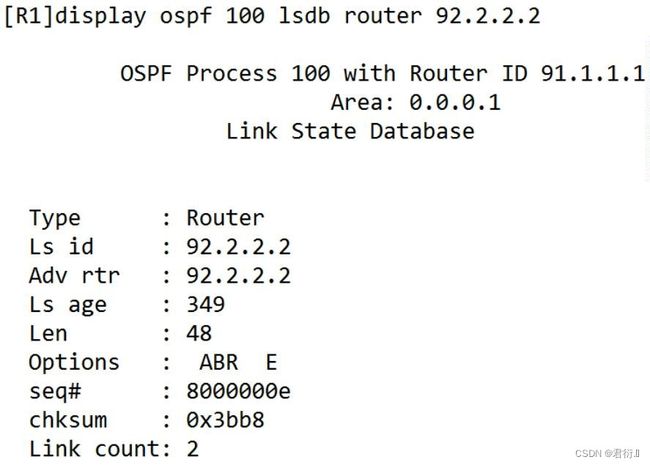
1、1类LSA:
router -LSA
1.1 功能: 本路由器针对某个区域产生的路由信息和拓扑信息
**1.2 传播范围:**本区域内传输
1.3 Link ID : 产生者的router-id
1.4 ADV router: 产生者的router-id
1.5 特性: 在单个区域中分别产生一条1类LSA,若存在MA网络,1类LSA不完整,需要配合二类LSA生成路由信息以及拓扑信息。
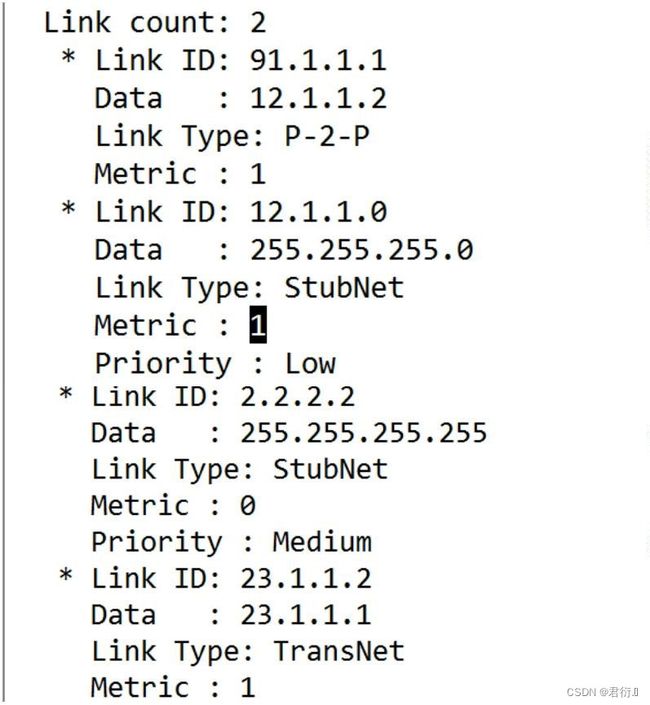
1.6 1类LSA 内容类型:
- 1.
stubnet(末节网络) —路由信息 - 2.
transnet(传输网络 仅限于MA网络)—拓扑信息 - 3.
point-to-point—拓扑信息 - 4.
virtual link(虚链路)—拓扑信息
1.7 查看1类LSA :
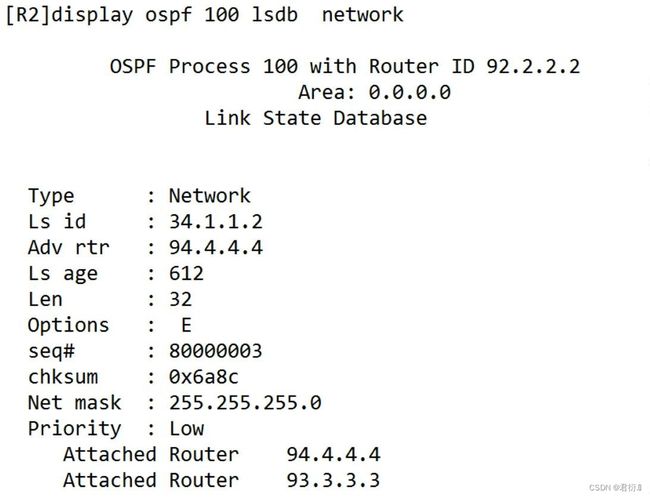
2、2类LSA
network LSA ,网络LSA
2.1 功能: 用于在MA网络中,描述本网络路由器的数量以及本MA网络的网络掩码
2.2 传播范围: 只能在本区域之内传输,终止于ABR
2.3 Link ID:DR接口的IP地址
2.4 ADV router:DR所在路由器的router-ID
2.5 特性: 只会出现在MA网络,用于补充1类LSA(1.MA网络的掩码 2.MA网络路由器的数量)
3、3类LSA
summary LSA 汇总LSA
3.1 功能: 用于在区域之间传递路由信息
3.2 link-id : 传递路由的网络号
3.3 ADV router:默认为所在区域ABR的router-id
3.4 特性: 在穿越不同区域时,由其他的ABR重新产生(ADV router 是变化的)
3.5 查看:
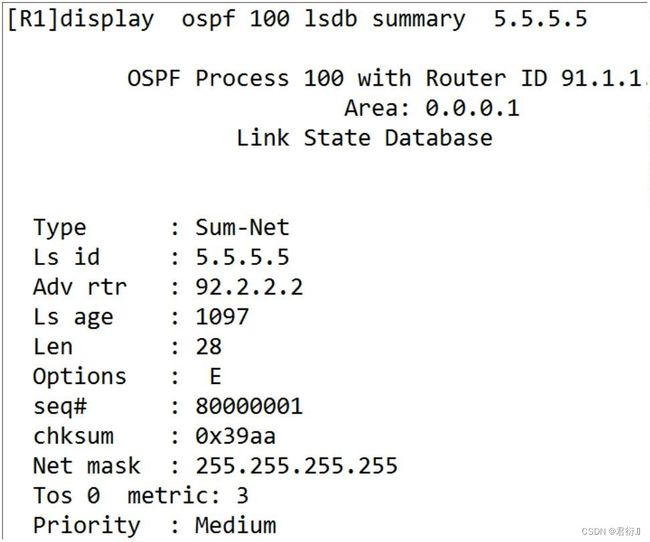
4、5类LSA
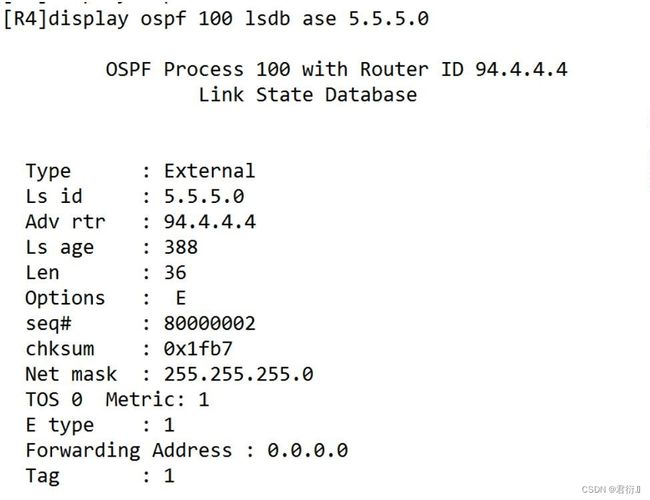
外部LSA
4.1 功能: 用于在整个OSPF中传递外部路由(原本不属于OSPF域)
4.2 5类LSA有两种类型: 类型1 类型2
(区别:Link id :传递外部路由的网络号)
4.3 ADV router :产生该LSA的 router-id
(产生本LSA的ASBR的router-id )
4.4 传播范围:在整个OSPF域中传输
4.5 特点:
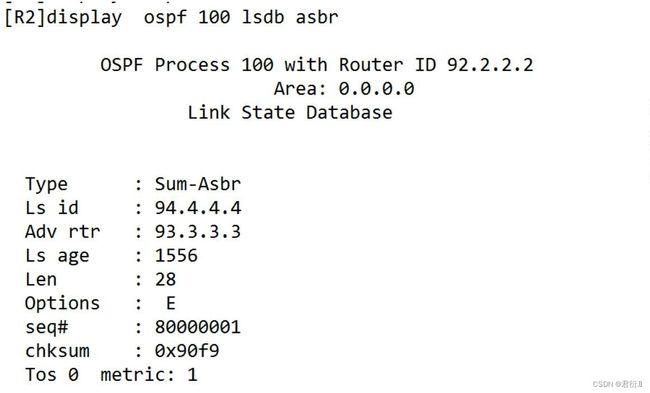
5、4类LSA
summary ASBR LS
5.1 功能: 除了ASBR所在区域外,用于通告ASBR位置
5.2 Link id: ASBR的router-id
5.3 ADV router: 默认ASBR所在区域的ABR的 router-id
5. 4 特点:在穿越不同区域时,由新的ABR重新产生。(与3类LSA一致)
6、7类LSA
NSSA LSA
6.1 功能: 在NSSA区域中,传递外部路由。
6.2 Link id : 传递路由网络号
6.3 ADV router:产生该LSA的 router-id
6.4 特性: 默认为类型2 ,度量值为1 。 携带了FA地址(转发地址)
7、FA
FA: 转发地址,当5类或7类LSA中携带了FA地址,则计算路径开销值时计算的是当前路由器到达FA地址的开销值之和+种子度量值。(若FA地址不可达,则路由不能加表)
FA 地址:
- 1.默认7类LSA 产生FA地址,5类LSA不产生的
(7转5 的5类LSA 携带FA地址 ) - 2.7类LSA 产生规则:
默认产生的FA地址为产生7类LSA 的ASBR 最大的环回接口地址;若连接其他协议的接口也运行了OSPF协议,网络类型为BMA,则产生的7类LSA中FA地址为连接其他接口对应的下一跳地址;若网络类型为P2P,则FA地址依然为环回接口中IP地址最大的 - 3.5类LSA FA地址规则:
**默认不产生,**若连接其他协议的接口运行了OSPF 协议并且网络类型为BMA,则FA地址为重发布之前路由的下一跳地址,若网络类型为P2P,则不会产生FA地址。
LSA中存在3个参数用于LSA的新旧比较: 3600s的LSA 都是最优的
- 1.序列号
- 2.校验和
- 3.LSA老化时间
(若以上都相同,LSA age 之差小于15分钟,越小越优,若大于15分钟,则无法比较认为都是最新的。)
Ls age : 1073
seq#: 80000006
chksum : 0x9dca
组步调计时器:默认5分钟。
8、OSPF 中的计时器
1.hello时间,默认为10s或30s。dead时间,默认为40s或120s;
修改hello时间,dead时间变化,修改dead时间,hello时间不变,hello时间或dead时间不同,都会影响邻居关系建立。
Waiting time:** 等待DR 或BDR的选举时间,永远保持与dead时间一致。**
修改hello时间:
ospf timer hello 5
修改dead 时间:
ospf timer dead 20
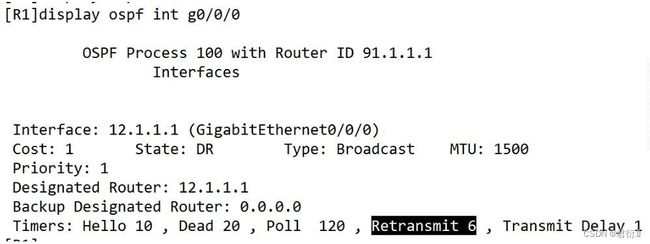
2.OSPF 默认重传时间5s
修改重传时间:

查看:
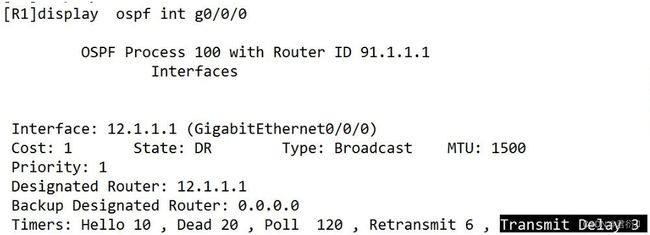
3.transmit delay 传输延时默认为1s
修改传输延时:

查看:
六、OSPF总结
OSPF — 无类别的路由协议
1、OSPF区域划分的要求
- 1,区域之间必须存在ABR设备
- 2,必须按照星型拓扑来划分 — 中间区域被称为骨干区域,骨干区域的区域ID(由32位二进制构成,可以使用点分十进制表示,也可以直接使用十进制表示)定义为0.
2、OSPF的基本配置
- 1,启动OSPF进程
[r1]ospf 1 router-id 1.1.1.1
- 2,创建区域
[r1-ospf-1]area 0
[r1-ospf-1-area-0.0.0.0]
- 3,宣告
宣告的目的 — 1,激活接口;2,发布路由
[r1-ospf-1-area-0.0.0.0]network 1.1.1.1 0.0.0.0 --- 反掩码 --- #由连续的0和连续的1组成,0代表不可变,1代表可变
[r1]display ospf peer --- #查看邻居表
[r1]display ospf peer brief --- #查看邻居关系简表
[r1]display ospf lsdb --- #查看链路状态数据库
[r1]display ospf lsdb router 2.2.2.2 --- #查看具体LSA信息
COST = 参考带宽/真实带宽 — 华为设备默认的参考带宽为100Mbps — [r1-ospf-1]
bandwidth-reference 1000 — 注意: 如果一台设备的参考带宽修改了,则所有设备的参考带宽必须改成相同的。
开销值计算,如果出现小数,如果是小于1的小数,则直接按照1来看;如果是大于1的小数,则直接取整数部分。
3、结构突变
- 1,突然新增一个网段 — 触发更新,直接发送LSU包,需要ACK确认
- 2,突然断开一个网段 — 触发更新,直接发送LSU包,需要ACK确认
- 3,无法沟通 ---- 死亡时间
4、条件匹配
- 指定路由器 — DR — 和MA网络中其他设备建立邻接关系。
- 备份指定路由 — BDR — 和MA网络中其他设备建立邻接关系。
一个MA网络当中,在DR和BDR都存在的情况下,至少需要4台设备才能见到邻居关系,因为只有DRother之间会保持邻居关系DR和BDR实际上是接口的概念。
条件匹配 — 在MA网络中,若所有设备均为邻接关系,将出现大量的重复更新,故需要进行DR/BDR的选举,所有DRother之间仅维持邻居关系即可。
5、DR/BDR选举
DR/BDR的选举规则:
- 1,先比优先级,优先级大的为DR,次大的为BDR
优先级的初始默认值为1。
[r1-GigabitEthernet0/0/0]ospf dr-priority ?
INTEGER<0-255> Router priority value
注意: 如果将一个接口的优先级改为0,则代表该接口放弃DR/BDR的选举。
- 2,优先级相同时,则比较RID,RID大的路由器对应的接口为DR,次大的为BDR。
DR/BDR的选举 — 非抢占模式的选举 — 一旦选举成功,则将不能被抢占 — 选举时间 — 和死亡时间相同。
<r2>reset ospf 1 process --- #重启OSPF进程的命令
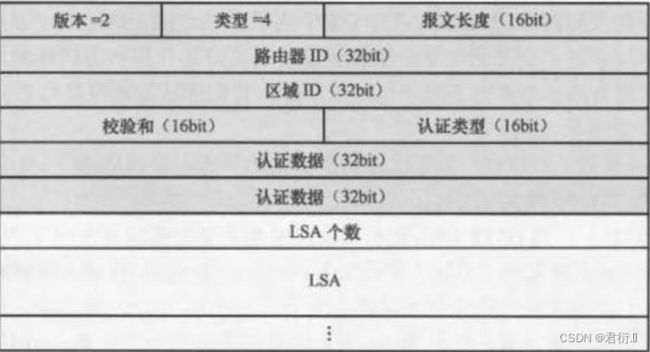
6、OSPF的数据包
OSPF跨四层封装,IP头部使用89作为协议号标识OSPF。
HELLO包,DBD包,LSR包,LSU包,LSACK包
6.1 OSPF头部

版本 — OSPF版本 — 2
类型 — OSPF数据包的类型
HELLO --- 1
DBD --- 2
LSR --- 3
LSU --- 4
LSACK --- 5
长度 — 指的是整个OSPF报文的长度,单位 — 字节
路由器ID — 发送这个数据包的路由器的RID
区域ID — 数据包发出的接口所在的区域的区域ID
校验和 — 确保数据完整性
认证类型,认证数据 — 完成OSPF认证工作的
认证类型 — null — 空认证 — 0
simple — 明文认证 — 1
MD5 — 比对摘要值认证 — 2
HELLO — 周期性发现,建立,保活邻居关系。DR/BDR选举。
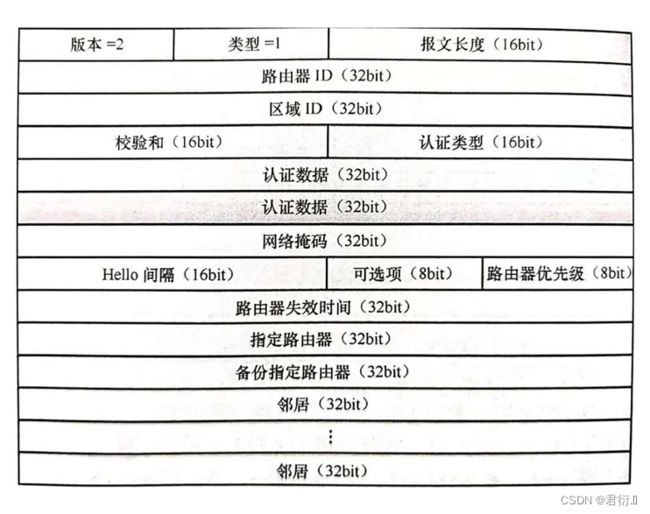
网络掩码 — 发出该数据包接口所配置的IP地址掩码信息。 — 华为体系中这个参数邻居双方所携带的值不一致将无法正常建立邻居关系。 — 这个限制条件仅针对MA网络,P2P网络不受限制。
hello时间,死亡时间 — 如果邻居双方这两时间参数不同,则将限制邻居关系的建立。
可选项 — 8位 — 每一位代表路由器遵从某个OSPF特性 — OSPF特殊区域的标记在其中,如果邻居双方特殊区域的标记不一致,则将限制邻居关系的建立。
路由器的优先级 — 发出hello包接口所配置的DR/BDR选举的优先级
DR/BDR — 网络中DR和BDR所对应接口的IP地址。在没有选出DR和BDR之前,将使用0.0.0.0进行填充。
Hello包中限制邻居关系建立的因素:
- 1,网络掩码
- 2,hello时间
- 3,dead time
- 4,OSPF特殊区域的标记
- 5,认证
DBD包 — 数据库描述报文
- 1,使用未携带数据的DBD包进行主从关系选举;
- 2,使用携带数据的DBD包进行目录共享;
DBD包还存在第三种形态,即仅完成确认的确认包状态。
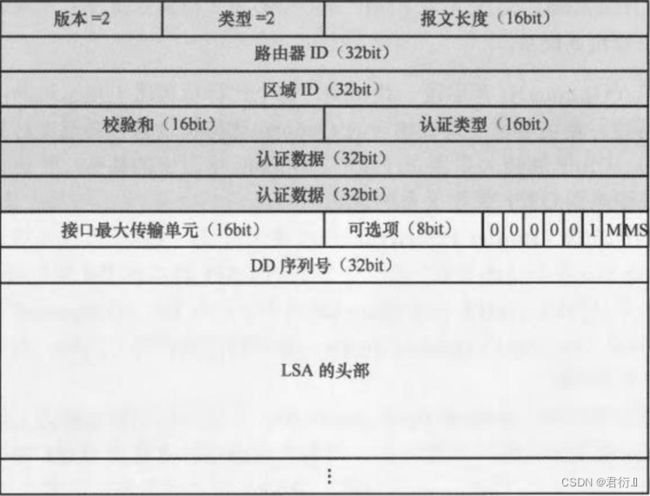
MTU — 设备默认没有开启接口MTU值的检测,所以将携带0。
[r1-Serial4/0/0]ospf mtu-enable — 如果邻居双方都开启了MTU值的检测,但是,双方携带的MTU值不同,则邻居状态将停留在Exstart状态。
I — init — 如果这个标记位置1,则这个DBD包是进行主从关系选举的数据包。
M — MORE — 该位置1,则代表后面还有更多的DBD包。
MS — Master — 该位置1,则代表发送该数据包的路由器为主。 — 在主从关系选举出来之前,双方都将认为自己是主,所以,都会将字节的MS置1;当主从关系选举结束后,将只有主会置1,从置0。
DBD序列号 — 在DBD报文交互中,会逐次加1,用于确保DBD包传输的有序性及可靠性。
LSR — 链路状态请求报文 — 基于DBD包请求未知的LSA信息。
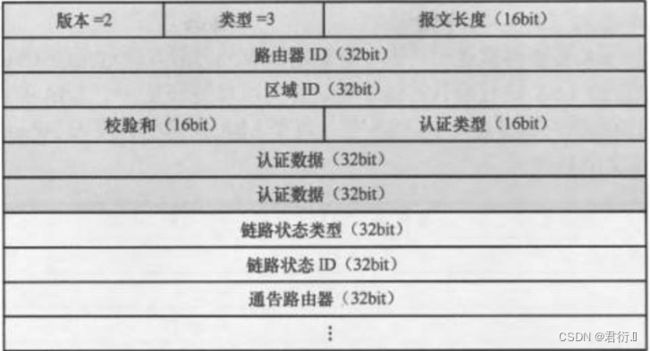
链路状态类型,链路状态ID,通告路由器 — LSA三元组 — 这三个参数可以唯一的标识出来一条LSA信息。
LSU包 — 链路状态更新报文 — 真正携带LSA信息的数据包
LSACK — 链路状态确认报文 — 确认包
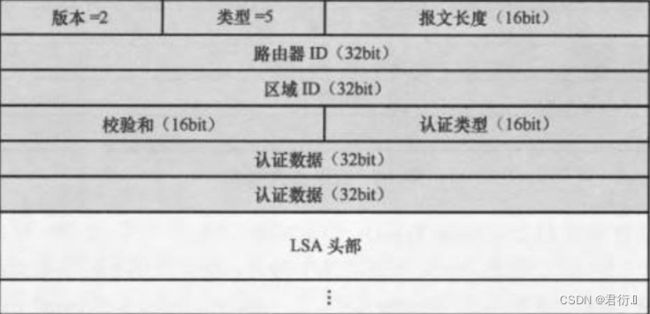
OSPF的接口网络类型:
P2P
MA
BMA
NBMA
OSPF接口网络类型 — 指的是OSPF接口在不同的网络类型默认下的不同工作方式。
[r2]display ospf interface GigabitEthernet 0/0/0 — 查看OSPF接口工作方式
在华为体系中,将环回接口在OSPF中的开销值定义为0,不会受到外界变化的影响。(修改参考带宽不会影响该值。)
[r2-LoopBack0]ospf network-type broadcast — 修改OSPF接口网络类型
华为体系将tunnel接口的传输速率定义为64K,实际上虚拟接口不存在传输速率。这样设定的目的是为了让隧道接口的开销值变的很大,导致在存在其他路径时,尽可能的避免走隧道接口,因为隧道接口需要进行复杂的封装和解封装过程,导致效率降低。
全连的MGRE环境 — MESH — 所有节点即使中心,也是分支。
[r1-ospf-1]peer 12.0.0.2 — 指定单播邻居 — 一定需要双向指定。
Attempt — 尝试 — 过度状态,只有在需要手工指定邻居关系的状态下出现,在指定对方后等待对方指定时将处于该状态,一旦对方指定,则将进行后续状态。
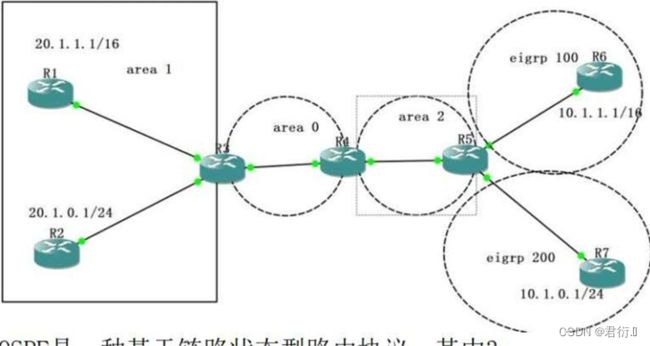
七、OSPF不规则区域问题
OSPF的不规则区域
区域划分的要求:
- 1,必须存在
ABR设备 - 2,区域划分必须按照
星型拓扑结构划分
1,远离骨干的非骨干区域
2,不连续骨干
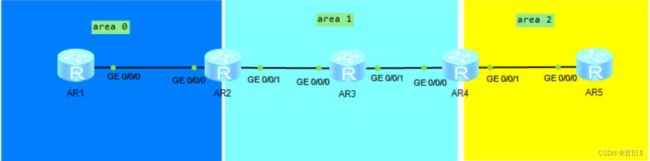
1、使用VPN隧道
思路: 在AR4和AR2之间构建一条隧道,之后,将这个隧道宣告到区域0中,相当于将AR4非法的ABR合法话,则AR4将正常传递区域2和区域0,1之间的路由信息。
在这个环境中,在没有隧道之前,AR4可以通过AR2转发的路由信息学习到达区域0的路由,而存在隧道之后,AR4可以直接通过隧道学习到区域0的拓扑信息。而AR4会优先选择自己通过拓扑信息学来的路由信息,就算是开销值巨大。
使用VPN隧道解决不规则区域的问题:
- 1,可能造成选路不佳;
- 2,可能造成重复更新;
- 3,因为虚拟链路的存在,AR2和AR4之间也需要建邻。导致他们之间维护的周期性数据将穿越中间区域区域1,导致中间区域的资源消耗。
2、使用OSPF虚链路来解决不规则区域
[r4-ospf-1-area-0.0.0.1]vlink-peer 2.2.2.2 — 虚链路的配置方法,后面跟需要创建虚链路设备的RID。
注意: 虚链路的建立是双向的。 — 虚链路永远属于骨干区域。
[r2-ospf-1-area-0.0.0.1]display ospf vlink — 查看虚链路详细信息
使用虚链路解决不规则区域的问题:
- 1,因为虚链路的存在,AR2和AR4之间也需要建邻。导致他们之间维护的周期性数据将穿越中间区域区域1,导致中间区域的资源消耗。
- 2,虚链路只能穿越1个区域
- 3,多进程双向重发布
不同的路由协议运行的机理各不相同,包括对路由的理解也不同,所以,不同的路由协议之间存在信息隔离。
重发布就是在运行不同协议的边界设备(ASBR — 自治系统边界路由器,协议边界路由器)上,将一种协议按照另一种协议的规则发布出去。 — ASBR设备要求必须存在重发布行为才行。
[r4-ospf-1]import-route ospf 2 — 将进程2的路由信息重发布到进程1中
O_ASE — 标志域外路由信息 — 因为域外的路由信息不可控性较强,所以,信任程度较低,我们将其优先级设置为150。
LSA — 链路状态通告 — OSPF协议在不同网络环境下产生的用于携带和传递不同的信息。
LSDB — 链路状态数据库
SPF — 最短路径优先算法
Type — LSA的类型,OSPFV2协议中,需要掌握的LSA类型一共有6种
LinkState ID — 链路状态标识符 — 主要用于标记一条LSA信息,可以理解为是LSA信息的名字。
AdvRouter — 通告路由器 — 通告LSA信息的设备的RID。
以上三个参数被称为LSA的三元组 — 这三个参数可以唯一的标识出来一条LSA信息。
LSA头部内容
Type : Router
Ls id : 4.4.4.4
Adv rtr : 4.4.4.4
LS AGE — LSA的老化时间 — 当LSA被始发路由器产生时置为0,之后,该LSA在网络中传
递,老化时间也将累加。 — 1800S — 为了防止老化时间无限制增长,我们设置了最大老化
时间 — MAXAGE – 3600S。如果一条LSA信息的老化时间达到3600S,则将判定其失效,将该LSA信息从本地的LSDB中删除。
SEQ — 序列号 — 32位二进制构成,用8位16进制表示 — 一台路由器每发送同一条LSA信息都会携带一个序列号,并且序列号逐次加1,用来标识LSA的新旧关系。
- 直线型序列空间 — 从最小到最大,逐次加1,其有点时新旧关系容易比较,而缺点是序列号空间有限,当序列号空间饱和后,将无法比较新旧关系。
- 循环型序列空间 — 序列号将循环使用,其问题在于一旦序列号差值过大,新旧关系将难以比较。
- 棒棒糖型序列空间 —
OSPF采用的就是这种序列空间,但是,为了避免循环部分出现循环型序列空间的问题,所以,OSPF的序列号将不进入循环部分,其取值范围为0X80000001 - 0X7FFFFFFE。
当一条LSA的序列号达到最大值时,则发出设备将会把该LSA的老化时间同时置为3600S(最大老化时间),之后,接受的设备将根据序列号判定为最新的LSA,刷新掉本地已有的同一条LSA信息,之后,由于其老化时间达到最大老化时间,则将该LSA信息从本地的LSDB中删除。同时,发出设备会再发送一遍该LSA信息,将其中序列号置为0X80000001,之后,接受设备将该LSA判定为最新的LSA信息进行接收。
Chksum — 校验和 — 确保数据完整性。校验和也将参与LSA的新旧比较,当两条LSA信息,三元组相同,且序列号相同时,则我们将通过校验和来进行新旧判定,校验和大的被认定为新。

TYPE-1 :网络中,所有设备都需要发送且只发送一条1类LSA。1类LSA的LS ID就是通告者的RID。
LINK— 用来描述接口的连接情况。一个接口可以使用一条或者多条LINK进行描述。

TYPE-2 LSA — 在MA网络中,仅靠1类LSA无法将所有信息描述完整,所以,需要使用二类LSA进行补充。二类LSA一个MA网络中只需要发送1条。
八、特殊区域
1、第一大类特殊区域
- 1,不能是骨干区域;
- 2,不能存在虚链路;
- 3,不能存在ASBR设备
满足以上条件的区域,我们称为末梢区域(STUB) — 如果将一个区域配置成为末梢区域,则其效果是这个区域将拒绝学习4类和5类LSA。并且,同时将自动生成一条指向骨干区域的三类缺省。
[r1-ospf-1]a 1
[r1-ospf-1-area-0.0.0.1]stub
注意: 一旦将一个区域配置成特殊区域,则区域内所有设备都必须做同样的配置,否则将影响邻居关系的建立。
完全末梢区域 — totally stub — 在普通的末梢区域的基础上,进一步拒绝三类LSA,仅保留三类缺省。
[r2-ospf-1-area-0.0.0.1]stub no-summary
注意: 这个命令只需要在ABR设备上执行即可
2、第二大类特殊区域
- 1,不能是骨干区域;
- 2,不能存在虚链路;
- 3,必须存在ASBR设备
满足以上条件的区域,我们称为非完全末梢区域(NSSA) — 如果将一个区域配置成为NSSA区域,则其效果是这个区域将拒绝学习4类和5类LSA。并且,同时将自动生成一条指向骨干区域的7类缺省。
因为NSSA区域拒绝学习5类LSA,但是,因为有ASBR设备的存在,他又必须将域外路由信息导入到OSPF网络当中,所以,他将使用7类LSA来携带域外路由信息。
注意,7类LSA只会在NSSA区域出现,在离开NSSA区域时,将由边界的ABR设备重现转换成5类LSA发布出去,则这个ABR设备完成了7转5的动作,其身份相当于是一个ASBR设备。
NSSA区域拒绝学习的主要是其他方向来的4类和5类LSA
[r5-ospf-1]a 2
[r5-ospf-1-area-0.0.0.2]nssa
注意: 一旦将一个区域配置成特殊区域,则区域内所有设备都必须做同样的配置,否则将影响邻居关系的建立。
| 类型 | LS ID | 通告路由器 | 传播范围 | 携带信息 |
|---|---|---|---|---|
| Type-1 LSARouter | 通告者的RID | 区域内所有运行OSPF协议的路由器的RID | 单区域 | 本地接口直连拓扑信息 |
| Type-2 LSANetwork | DR接口的IP地址 | 单个MA网络中的DR所在的路由器的RID | 单区域 | 单个MA网络的补充信息 |
| Type-3 LSASum-Net(summary) | 域间路由的目标网络号 | ABR,在通过下一个ABR时,将修改为新的ABR | ABR相邻的单区域 | 域间路由信息 |
| Type-5 LSAExternal(ase ) | 域外路由信息的目标网络号 | ASBR | 整个OSPF区域 | 域外路由信息 |
| Type-4 LSASum-Asbr(asbr) | ASBR的RID | ABR(ASBR所在区域的ABR设备),在通过下一个ABR时,将修改为新的ABR | 除了ASBR所在区域外的单区域 | ASBR的位置信息 |
| Type-7 LSANSSA | 域外路由信息的目标网络号 | ASBR(如果离开NSSA区域,则将转换成5类LSA) | 单个NSSA区域 | 域外路由信息 |
3、特殊区域的标记位
- E位:一般置1,代表支持5类LSA。要是做成特殊区域,则将拒绝学习5类LSA,则E位置0
- N位:一般置0,只有在NSSA区域中置1,代表支持7类LSA。
- P位 — P位置1,则代表该LSA支持7转5。
Forwarding Address — 转发地址
应对选路不佳的情况,如果存在选路不佳的情况,则通告者将会把最佳的下一跳放入转发地址当中,接收者看到转发地址中存在数据,则将不按照算法来计算下一跳,而直接使用转发地址作为下一跳。在5类LSA中,默认情况下,在不存在选路不佳时,将使用0.0.0.0进行填充。
而在7类LSA中,一般会使用通告者(ASBR)设备的环回接口地址作为转发地址。如果存在多个环回接口,则将使用最先宣告的地址作为转发地址;如果没有环回接口,则将使用物理接口的地址作为转发地址。
7类LSA生成路由信息的标记位, O_NSSA ,优先级为150。
完全的非完全末梢区域 — totally NSSA — 在普通的NSSA区域的基础上,进一步拒绝三类LSA,自动生成一条指向骨干区域的三类缺省。
[r4-ospf-1-area-0.0.0.2]nssa no-summary
#注意,这个命令只需要在ABR设备上执行即可
注意: 在配置完完全的NSSA区域后,因为之间普通的NSSA区域生成了一条7类缺省,完全的NSSA区域又生成了一条三类缺省,因为三类优于7类,所以,将选择三类缺省。
注意: 手工配置的缺省方向需要和自动生成的缺省方向一置,否则可能产生环路。
4、OSPF的拓展配置
4.1 手工认证
OSPF邻居双方,发送的所有的数据报中包含认证信息,两边口令相同,则代表认证成功;不同,则认证失败,将影响邻居关系建立。
- 1、接口认证
[r1-GigabitEthernet0/0/0]ospf authentication-mode md5 1 cipher 123456
- 2、区域认证 — 本质还是接口认证,相当于,将一台设备在某个区域内所有激活的接口配置接口认证。
[r4-ospf-1-area-0.0.0.0]authentication-mode md5 1 cipher 123456
- 3、虚链路认证 — 其本质也是接口认证
[r5-ospf-1-area-0.0.0.2]vlink-peer 4.4.4.4 md5 1 cipher 123456
4.2 缺省路由
3类缺省,5类缺省,7类缺省
3类— 只能自动生成,在配置 — 末梢区域,完全的末梢区域,完全的非完全末梢区域
特征 —OSP,优先级默认为10;5类— 通过手工配置的方法生成
[r3-ospf-1]default-route-advertise— 这个命令相当于是将设备本身通过其他协议学习到的缺省路由重发布到OSPF网络当中,所以,生成的是5类缺省。
特征 —O_ASE,优先级默认150;
[r3-ospf-1]default-route-advertise always— 如果本地没有其他协议学到的缺省信息,在可以使用这个命令强制下发一条5类缺省。7类— 可以自动生成 — 普通的NSSA区
可以手工配置 —[r5-ospf-1-area-0.0.0.2]nssa default-route-advertise— 手工下发7类缺省
特征 —O_NSSA,优先级默认150;
4.3 沉默接口
将某个接口配置成沉默接口,则该接口将只接受,不发送OSPF数据包。
[r5-ospf-1]silent-interface GigabitEthernet 0/0/2
4.4 加速收敛
减少计时器的时间、
1、修改HELLO时间
[r1-GigabitEthernet0/0/0]ospf timer hello 5
注意: HELLO时间一旦更改,死亡时间将自动按照四倍关系进行匹配。
2、修改死亡时间
[r2-GigabitEthernet0/0/0]ospf timer dead 20
注意: 死亡时间变更,hello时间不会变化
3、等待计时器 — 时间长短等同于死亡时间,DR和BDR选举时的计时器。这个计时器无法直接修改时间,死亡时间更改,则这个计时器时间同时更改。
Poll — 轮询时间 — `120`` — 与状态为DOWN邻居发送hello包的周期时间。 — NBMA
在NBMA环境下,如果单方面指定邻居关系,则将对方状态置为ATTEMP状态,如果对方一直不指定本地为邻居(中间等待时间为一个等待计时器的时间),则将对方的状态置为DOWN状态。之后,将按照轮询时间为周期发送hello包。
[r1-GigabitEthernet0/0/0]ospf timer poll ? #修改轮询时间
INTEGER<1-3600> Second(s)
Retransmit — 5S — 重传时间 — 发送信息需要进行确认,如果对方重传时间内都没有发送确认,则将重传。
[r2-GigabitEthernet0/0/0]ospf timer retransmit ?
INTEGER<1-3600> Second(s)
Transmit Delay — 1S ---- 传输延迟 — 是附加在LSA老化时间上的一个值,因为传输过程中,数据包中老化时间没有办法更改,所以,在封装数据包时,将在原有的老化时间基础上,额外增加传输延迟时间,用来补偿传输过程中的时间消耗。
[r2-GigabitEthernet0/0/0]ospf trans-delay 2
4.5 路由过滤
主要是针对3类,5类,7类LSA进行过滤。
[r2-ospf-1-area-0.0.0.1]abr-summary 192.168.0.0 255.255.252.0 not-advertise — 在ABR设备上针对3类LSA进行过滤
[r5-ospf-1]asbr-summary 10.0.0.0 255.255.255.0 not-advertise — 在ASBR设备上针对5类/7类LSA进行过滤
4.6 路由控制
1、优先级
[r5-ospf-1]preference 50 — 修改协议字段为OSPF的路由的默认优先级 ---- 只影响本设备
[r5-ospf-1]preference ase 100 — 修改协议字段为O_ASE/O_NSSA的默认优先级
2、开销值
COST = 参考带宽 / 真实带宽
- 1、通过修改参考带宽实现修改开销值
[r5-ospf-1]bandwidth-reference ?
INTEGER<1-2147483648> The reference bandwidth (Mbits/s)
注意: 参考带宽一旦修改,则所有设备的参考带宽必须改成一样的,必须要统一标准。这样的修改只能应对因参考带宽过小而造成的选路不佳,不能实现选路效果。 - 2、通过修改真实带宽实现修改开销值
[r3-GigabitEthernet0/0/0]undo negotiation auto— 关闭自动协商
[r3-GigabitEthernet0/0/0]speed 10— 修改接口真实带宽
Info: Please undo negotiation first.
注意: 修改真实带宽,可以达到控制开销值选路的效果,但是,因为传输速率只能改小,所以,不建议使用这种方法,会影响传输效率。 - 3,直接修改开销值
[r3-GigabitEthernet0/0/0]ospf cost 1000
注意: 1,2两种方法,均无法影响环回接口的开销值,但是,第三种方法,可以直接修改环回接口开销值。
OSPF的开销值计算方法为 — 目标网段到达本地设备路由流量流入的接口的累加值。
4.7 OSPF的附录E
附录E主要描述的就是在以下场景中,因为3类,5类,7类LSA导致出现的特殊问题的解决方案。
附录E提出的解决方案是掩码较短的信息正常进入,掩码较长的信息将使用目标网段的直接广播地址作为LS ID。
九、广域网技术
数据链路层面: 针对不同的物理链路定义不同的封装
- 局域网封装:
Ethernet 2 (TCP/IP) , IEEE802.3 (OSI) - 广域网封装:
PPP HDLC FR ATM
1、HDLC
HDLC : 高级数据链路控制协议,默认思科的串行链路封装为HDLC,分为工业标准的HDLC和思科私有的HDLC,两者不同通用,思科私有的HDLC中加入一些控制字符,识别上层协议,以及三层的传输方式。
定义接口封装为HDLC :
![]()
![]()
2、PPP
PPP:点对点封装协议,华为串行链路默认封装为PPP , PPP链路需要建立一条端到端的会话链路。
PPP会话建立分为:
- 1.LCP
- 2.PPP认证
- 3.NCP
LCP:链路控制协议,通过发送LCP数据进行物理链路和封装的确认
PPP认证:增加PPP会话的安全性, PAP CHAP
NCP:网络控制协议,通过发送NCP 针对上层协议进行封装, IPCP 协商,在NCP协商过程中,会自动将自己本端IP地址以路由方式发送给对方,当PPP会话建立之后,会产生到达对方接口IP地址的32位主机路由。
3、PAP
PAP : 密码认证协议,是一种一次性的简单的明文认证
主认证方:
![]()
接口调用:
被认证方: 提供账号密码

4、CHAP
CHAP :挑战握手认证协议, 通过三次握手的方式进行安全的MD5认证 ,在认证过程中需要发送挑战信息(类似 HMAC 密钥化哈希)。
![]()
接口启用chap认证:
被认证方:

在广域网技术中, PPP HDLC FR ATM PPPOE PPPOA
5、GRE
GRE : 通用路由封装,标准的三层隧道技术 ,是一种点对点的隧道技术
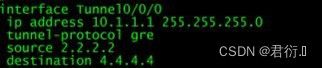
查看:
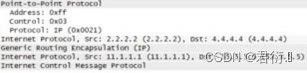
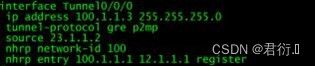
MGRE : 多点通用路由封装协议
NHRP :下一跳可达协议,所有的MGRE接口将自己的MGRE接口IP地址和对应隧道物理接口地址信息发送给NHS进行注册,NHS 上存在所有接入MGRE的接口映射关系。其他MGRE接口之间彼此通信时向NHS进行请求, 形成隧道的目标地址。
6、运行路由协议
hub端配置:

spoke端配置:
查看:
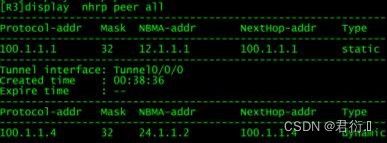
十、动态路由协议
1、OSPF
1、OSPF的选路原则
- 域内路由 — 1类,2类LSA
- 域间路由 — 3类LSA
- 域外路由 — 5类,7类LSA — 类型1,类型2
1.1 域内路由
如果都是通过1类和2类LSA学习到的域内路由信息,则将直接比较开销值;
开销值小的,优先选择,
如果开销值相同,则将负载均衡。
1.2 域间路由
如果都是通过3类LSA学习到的域间路由信息,则将直接比较开销值,
开销值小的,优先选择;
如果开销值相同,则将负载均衡。
1.3 域外路由
- 类型1:如果采用类型1,则所有域内设备到达域外网段的开销值都等于种子度量值加本地到达通告者的开销值。
- 类型2:OSPF默认采用类型2,如果开销值的类型为类型2,则所有域内设备到达域外网段的开销值都等于种子度量值。
2、5类LSA类型2比较:
优先比较种子度量值,种子度量值小的优先选择;
- 如果种子度量值相同,则比较沿途累加的开销值,沿途累加开销值小的优先选择;
- 如果两种开销值都相同,则将负载均衡。
类型1永远优于类型2。
3、5类LSA类型1比较:
直接比较总度量(种子度量值加沿途累加值),
- 总度量小的优先选择,
- 如果相同,则负载均衡。
域内和域间: 域内优于域间,不比较开销值
域间和域外: 域间优于域外,不比较开销值
4、OSPF的防环机制
- 域间防环
1,区域水平分割 — 路由信息从哪个区域学到的就不再发回哪个区域
2,星型拓扑的区域划分本身就是一种防环机制 - 域内防环
SPF—最短路径优先算法
拓扑信息 — 有向图 — 最短路径树
2、重发布
1、作用:
在一个网络中,若运行多种路由协议或者相同协议的不同进程,协议间不能直接沟通计算,进程间也是独立转发和计算的,所以,需要使用重发布来实现路由的共享。
2、条件:
- 1,必须存在
ASBR设备。 —所谓ASBR设备指的是同时运行两种协议或者两个进程的设备。 - 2,必须关注种子度量值 — 一个起始度量。A协议和B协议的度量标准计算逻辑不通,无法直接使用 所以,在将A协议导入到B协议时,ASBR将不携带A协议的度量值到B协议,而是在共享到B协议时,将由ASBR设备定义一个初始值。
3、规则:
- 1,将A协议发布到B协议时,在ASBR上的B协议进程中配置。
- 2,将A协议导入到B协议中,是将ASBR设备上通过A协议学习到的以及ASBR上宣告在A协议中的所有直连路由,全部共享到B协议中。
点
- 单点 — 两个协议或两个进程之间存在1个ASBR
- 双点 — 两个协议或两个进程之间存在2个ASBR
- 多点 — 两个协议或两个进程之间存在多个ASBR
向
- 单向 — 仅将A协议的路由共享到B协议中
- 双向 — A/B协议的路由均共享
4、RIP协议
A - B:将一种动态协议发布到另一种动态协议中
[r2-rip-1]import-route ospf 1
结论:
RIP协议导入的初始种子度量值为0;
[r2-rip-1]default-cost 2 ---- 全局修改,之后所有重发布到RIP进程中的路由其初始的种子度量值都将修改
[r2-ospf-1]default cost ? — OSPF中全局修改种子度量值的方法
INTEGER<0-16777214> Cost value
[r2-rip-1]import-route ospf 1 cost 3 — 仅针对本次导入进行种子度量值的修改
[r2-rip-1]
5、静态 - B:将静态路由发布到动态路由中
[r2-rip-1]import-route static
结论:
- 1,导入静态路由时,无法导入缺省路由
- 2,RIP协议导入的初始种子度量值为0;
6、直连 - B:将直连路由发布到动态路由中
[r2-rip-1]import-route direct
- 1,RIP协议导入的初始种子度量值为0;
- 2,若ASBR设备进行A-B的重发布,同时进行了直连到B的重发布,两种重发布又包含相同的路由信息时,则优先选择直连重发布的路由。
7、双点重发布
默认RIP和OSPF协议,若进行多点双向重发布,由于两者的优先级不同,故第一台ASBR设备重发布动作结束后,将影响其他ASBR设备的路由表;使得路由可能被回传回源协议,发生路由回馈 — A协议的路由重发布到B协议中,之后又被B协议重发布回A协议。
华为设备为了消除路由回馈现象,将OSPF协议域外导入的信息的优先级默认设置为150,这个值大于所有华为体系内定义的IGP协议的默认优先级,所以,将不会导致路由回馈的产生。
由于重发布技术的种子度量值问题,将必然导致选路不佳,只能依赖路由策略来人为干涉选路。
- 控制层面流量 — 路由协议传递路由信息产生的流量
- 数据层面流量 — 设备访问目标地址时,产生的数据流量
3、路由策略
路由策略 — 在控制层流量流动的过程中,截取流量,之后修改流量再转发或者不转发,最终达到影响路由器路由表生成,起到干涉选路的效果。
3.1 抓流量
-
1、
ACL— 因为ACL列表本身主要抓取数据层面流量, 其通配符设计导致数据流量可以精确匹配, 但是,在抓取控制层面流量时,无法准确的匹配掩码信息,导致无法精确抓取控制层流量。 -
2、前缀列表 —
ip-prefix
[r1]ip ip-prefix aa permit 192.168.1.0 24
#前缀列表主要靠自定义名称来进行区分
[r1]display ip ip-prefix aa
#查看名称为aa列表的规则
#前缀列表中的规则默认是以10为步调自动添加序列号的,便于插入规则。
[r1]ip ip-prefix aa index 15 permit 192.168.2.0 24
#添加序号插入规则
#前缀列表的匹配规则
#从上而下,逐一匹配,一旦匹配上则将按照该规则执行,不再向下匹配。末尾隐含拒绝所有的规则。
[r1]undo ip ip-prefix aa index 12
#删除规则的方法
[r1]ip ip-prefix aa permit 192.168.1.0 24 less-equal 28
#抓取掩码长度为24到28的网段信息
[r1]ip ip-prefix aa permit 192.168.1.0 24 greater-equal 28
#如果前后矛盾,则将按照后面的执行,而前面的将变成前24位固定
[r1]ip ip-prefix aa permit 192.168.1.0 24 greater-equal 28 less-equal 30
#匹配掩码长度为28到30的网段,前24位固定
[r1]ip ip-prefix aa permit 192.168.1.0 24 greater-equal 28 less-equal 28
#匹配掩码长度为28的网段,前24位固定
[r1]ip ip-prefix aa permit 0.0.0.0 0 greater-equal 32 less-equal 32
#匹配所有主机路由
[r1]ip ip-prefix aa permit 0.0.0.0 0 less-equal 32
#允许所有
[r1]ip ip-prefix aa permit 0.0.0.0 0
#抓取缺省路由
3.2 具体过程
1、RIP的merticin和merticout — 偏移列表
只能针对距离矢量型协议进行控制
注意: 在RIP中对开销值进行修改时只能将开销值改大,而不能改小。
- 1、抓取流量
[r4]acl 2000
[r4-acl-basic-2000]
[r4-acl-basic-2000]rule permit source 23.0.0.0 0
#使用ACL列表抓取
[r1]ip ip-prefix aa permit 23.0.0.0 24
#用前缀列表抓取
- 2、在接口上调用偏移列表
[r4-GigabitEthernet0/0/1]rip metricout 2000 2
#使用的出方向的列表,后面的设定值修改的是RIP数据包中携带开销值
#计算时默认的增加量。(默认增加量为1,该命令将增加量修改为2。)
[r1-GigabitEthernet0/0/1]rip metricin ip-prefix aa 2
#使用的入方向的列表,其效果是在本地路由表中的开销值的基础上
#再增加后面的设定值
2、过滤列表 — filter-policy
注意: 过滤列表也是分方向的,而且,可以应用在OSPF和RIP当中
- 1、抓流量
[r2]acl 2000
[r2-acl-basic-2000]
[r2-acl-basic-2000]rule deny s 34.0.0.0 0
#注意,过滤列表本身没有过滤能力,所以,需要在抓取流量时使用拒绝动作。
[r2-acl-basic-2000]rule permit source any
#注意,在抓流量时,末尾一定要放通剩余流量,
#否则将会把所有流量全部过滤掉。
[r1]ip ip-prefix cc deny 34.0.0.0 24
#使用前缀列表抓取流量
[r1]ip ip-prefix cc permit 0.0.0.0 0 less-equal 32
#后面添加放通所有的规则
- 2、在进程中调用过滤策略
[r2-rip-1]filter-policy 2000 export GigabitEthernet 0/0/0
#出方向的调用
#出方向影响他人
[r1-rip-1]filter-policy ip-prefix cc import GigabitEthernet 0/0/0
#入方向调用
#入方向影响自身,注意,需要选择接口,
#否则所有接口学到的路由信息都将过滤
注意: 过滤列表可以在OSPF中使用,但是,因为OSPF中传递的是拓扑信息,所以,无法进行出方向的过滤,只能进行入方向的调用,并且,调用的效果是仅过滤抓取的路由信息不加表。
- 3,
Route-policy— 路由策略 -
- 1,抓流量
[r2]acl 2000
[r2-acl-basic-2000]rule permit source 1.1.1.0 0
[r2]acl 2001
[r2-acl-basic-2001]rule permit source 2.2.2.0 0
[r2]ip ip-prefix aa permit 3.3.3.0 24
[r2]ip ip-prefix bb permit 4.4.4.0 24
-
- 2,做路由策略
[r2]route-policy aa deny node 10
Info: New Sequence of this List.
[r2-route-policy]if-match acl 2000
[r2]route-policy aa permit node 20
[r2-route-policy]if-match acl 2001
[r2-route-policy]apply cost-type type-1
[r2]route-policy aa permit node 30
Info: New Sequence of this List.
[r2-route-policy]if-match ip-prefix aa
[r2-route-policy]apply cost 2
[r2]route-policy aa permit node 40
Info: New Sequence of this List.
[r2-route-policy]if-match ip-prefix bb
[r2-route-policy]apply cost 10
[r2-route-policy]apply tag ?
INTEGER<0-4294967295> Tag value
[r2-route-policy]apply tag 666
[r2]route-policy aa permit node 50
Info: New Sequence of this List.
[r2-route-policy
注意:
- 如果没有
if-match,则代表匹配所有; - 如果没有
APPLY,则只执行大动作
路由策略的匹配规则 — 从上而下,逐一匹配,一旦匹配上则将按照该规则执行,不再向下匹配。末尾隐含拒绝所有的规则。
- 3,在重发布中调用
[r2-ospf-1]import-route rip route-policy aa
3、Route-policy的配置指南
- 1,即便要拒绝一个流量,在抓取流量的时候,也必须使用允许,之后由路由策略来拒绝。
- 2,在一条规则中,
-
- 若没有进行流量匹配,则代表匹配所有;
-
- 若没有apply,则仅对匹配到的流量执行大动作,
- 因此,大动作为允许的空表为允许所有。
4、BGP
BGP — 边界网关协议
AS — 自治系统 — 由单一机构或者组织所管理的一些列IP网络及其设备所构成的集合原因:
- 1,范围大,需要划分;
- 2,自治管理
AS号 — 由16位二进制构成 — 0 - 65535,其中0和65535保留,1 - 65534;其中64512 - 65534被称为私有AS号 — 目前也存在扩展版的AS号 — 32位二进制构成
目前市场上针对IPV4环境使用的BGP协议版本为BGPV4,目前市场上也已经存在BGPV4+(MP - BGP — 可以支持多种地址族)协议。
AS之间不使用重发布获取路由信息的原因:
- 1,选路不佳;
- 2,ASBR设备的归属问题
BGP共享AS之间的路由信息的方式应该是直接传递路由信息而不是共享拓扑信息,因为拓扑信息一方面更新量更大,其次将暴露本AS的拓扑情况,所以,传递路由信息更加合理。
BGP被称为 — 无类别的路径矢量型协议
无类别 — 传递的路由信息携带子网掩码
| 路径矢量 | 距离矢量 |
|---|---|
| 一个AS为一跳 | 一个路由器为一跳 |
| 不是算法概念,仅将IGP协议算好的路由信息传递出去,仅完成搬运工作。 | 是一个算法的概念,用来计算到达未知网段的路由信息 |
IGP — 选路佳,收敛快,占用资源小
EGP协议的关注点:
- 1,可控性 — AS之间需要传递大量的路由信息,所谓可控,就是可以方便的干涉选路,更容易做策略。
BGP为了保证可控性,直接舍弃了开销值。取而代之的是BGP定义了很多路径属性。
注意: BGP协议存在触发更新,但是,不存在周期更新, 因为BGP需要更新的路由信息量太大,周期更新太浪费资源。
- 2,可靠性 — BGP协议为了保证可靠性,传输层直接选择使用TCP协议,使用179号端口。
在IGP当中,没有使用TCP协议,主要是因为TCP协议传输效率较低,占用资源较大,只能实现单播,不能自动发线邻居关系。而在BGP中,为了保证可靠性,选择使用TCP。
在BGP中,是可以实现非直连建邻,BGP的非直连建邻是承载在IGP之上的。
- AS内部 —
IBGP对等体关系— 如果建立对等体的路由器位于相同的AS中,则建立的是IBGP对等体关系 - AS外部 —
EBGP对等体关系— 如果建立对等体的路由器位于不同的AS中,则建立的是EBGP对等体关系
注意: 为了保证EBGP对等体关系之间使用直连建邻,我们将他们之间传递的数据报中TTL值设置为1,若EBGP对等体之间需要非直连建邻,则需要修改TTL值。IBGP对等体之间,一般使用非直连建邻,所以TTL值设置为255。
- 3,
AS-BY-AS— 将一个AS看作是一个单位。 — bgp不支持负载均衡,如果到达同一个目标网络存在多条路由信息时,则将只选择其中一条。
十一、BGP边界网关协议
1、BGP的数据包
在BGP中,因为使用TCP协议,需要建立点到点的连接,所以,无法通过组播或者广播来自动发现邻居,只能手工指定邻居关系。
- Open报文 — 主要完成BGP对等体关系的建立,协商参数。
- AS号 — 在创建邻居关系时,需要指定对等体设备所在的AS号,之后,将该参数通过OPEN报文携带,对端收到后,将该参数和本地所在AS号进行比对,一致,则可以正常建立对等体关系,不一致则对等体关系建立失败。
- 认证 — BGP也可以做认证,则认证口令将成为邻居关系建立的核查条件。
Router ID— 用于区分和标定不同的路由设备。 OPEN报文中将携带本地的RID,之后对等体将核查该参数,需要确保RID不冲突,则需要保证和本地的RID不一致,一致则无法建立邻居关系。
BGP中的RID其生成方法和OSPF中的相同,可以手工配置,也可以自动生成。
(自动生成规则 — 先在本地环回接口的IP地址中取最大的最为RID,如果本地没有环回接口,则在所有物理接口的IP地址中取最大的作为RID。)
在指定邻居关系时,指定的IP地址作为后续的更新源IP,如果对等体发送的数据报中的源IP地址和给定的地址不同,则也将影响邻居关系的建立。
Holdtime — 保活时间 — 周期保活的失效判定时间 — 默认180S — 如果在保活时间内,没有收到Keeplive报文或者Update报文,则判定对方失效,将中断BGP会话连接。 — 双方在发送OPEN报文中都需要携带保活时间,这个时间可以不同,但执行时必须相同,所以,如果双方的保活时间不同,则按照时间较短的执行。
包括设备是否支持路由刷新功能,也需要在OPEN报文中进行协商。
Keeplive报文— 仅完成周期保活即可,周期发送时间为保活时间的1/3。默认为60S — 除了保活之外,keeplive报文在收到对方发送的open报文时,将临时充当确认包的作用。 — BGP协议所有数据包传输的可靠性由TCP协议来保障,而此时的确认,指的是确认对方OPEN报文中的参数,如果认可对方所携带的参数,则将发送keeplive报文进行确认。Update报文— 真正携带路由信息的数据报。主要携带目标网络号及掩码信息和路径属性 — 在UPDATE报文中,存在一个撤销路由条目的参数,可以将失效的路由信息放置其中,则对端将会删除失效的路由信息,而不需要带毒传输。Notification报文— BGP协议设计的一个告警机制 — 在BGP协议运行的全过程中,如果发生错误导致对等体关系断开,则设备将在断开之前,发送该报文来报告错误原因。Route-refresh报文— 用于改变路由策略后请求对等体重新发送路由信息。改报文使用存在前置要求,即对等体双方路由设备必须都支持路由刷新功能。
2、BGP的状态机
BGP的状态机仅描述的是BGP对等体建立过程中的状态变化,而不包含数据收发过程。因为BGP中建立邻居关系和收发数据可以分开完成。

IDLE — 空闲状态 — 所有设备启动BGP进城后将首先进入空闲状态。
当手工指定邻居关系后,将会进入到一个检查环节,需要检查手工指定的IP地址在本地路由表中是否可达,只有可达,才可以正常建立TCP的会话,如果不可达,则邻居关系建立失败,停留在IDLE状态。
如果检查成功,则将进入到Connect状态 — 连接状态 — 建立TCP会话连接的状态。
(注意,对等体关系指定是双向的,双方都将发起TCP会话连接请求,最终将会建立两个双向的TCP会话通道,只需要保留一个即可。所以,在之后发送的open报文中,将比较其中的RID参数,RID大的设备发起的TCP会话连接将被保留,RID小的发起的连接将被关闭。)
如果TCP会话连接失败,则将进入到Active状态 — 尝试重新建立TCP会连接(多次失败后,将超时,回退到空闲状态,如果成功,则进入到opensent状态。)
如果TCP会话连接成功,则将直接进入到opensent状态 — 发送open报文来协商参数,建立对等体关系。 同时,也将收到对方发来的open报文,则将查看其中的参数,如果参数没问题,则将发送keeplive报文进行确认。则将进入到openconfirm状态。 — 等待对方发送keeplive报文,确认本地参数。
如果,收到对方发送的keeplive报文, 则代表双方open报文中的参数协商完成,则邻居关系建立成功,将进入到最终状态 — Established状态。

3、BGP的工作过程
- 1,基于
IGP实现IP可达 - 2,指定邻居关系,邻居之间单播传输,通过三次握手,建立TCP会话通道。BGP之后所有的通信都将基于TCP会话通道来传输。包括提供传输的可靠性
- 3,使用
OPEN报文和Keeplive报文进行邻居关系的建立。OPEN报文用来携带建邻使用的参数,keeplive报文用于参数的确认。最终完成对等体关系的建立。生成邻居表。 - 4,使用
update报文来共享路由信息。信息中将携带目标网络号,掩码及路径属性;之后,将发送以及收集到的路由信息记录在一张表中 — BGP表。 - 5,之后,将BGP表中最优的路由信息(通过路由属性选择的结果)加载到路由表中。
- 6,收敛完成后,将使用
keeplive报文进行周期保活,默认的保活时间为180S,发送周期为60S。 - 7,如果出现错误,将使用notification报文进行告警。
- 8,若出现结构突变,则将使用update报进行触发更新。
4、BGP的路由黑洞问题

由于BGP协议可以非直连建邻,所以导致BGP协议可能出现跨越未运行BGP协议的设备,导致BGP路由传递后,控制层面显示可达,但是,数据层面,流量流经未运行BGP协议的设备时,无法通过,形成路由黑洞。
解决方案:
- 1,让未运行BGP协议的设备运行BGP协议 — 问题,所有设备都需要运行BGP则都将承载大量的路由信息,造成设备成本增加。
- 2,在IGP协议中,重发布BGP协议的路由信息
- 3,MPLS
为了避免路由黑洞的情况,BGP提出了同步机制 — 即当一台路由器从自己的IBGP对等体处学到一条BGP路由时,他将不能将该路由通告给自己的EBGP对等体关系。除非,他从自己IGP协议中也学习到这条路由信息。 — 华为设备默认关闭同步机制。
5、BGP的防环问题
BGP使用的防环手段 — 水平分割机制
- EBGP的水平分割 — 针对EBGP对等体之间可能出现的环路问题所提供的解决方案
AS_PATH— 专门记录AS路径信息的一个属性。
所谓EBGP的水平分割,主要用于防止EBGP环境下的环路问题 — BGP协议在路由条目中将经过的AS号进行记录,生成一个属性 —AS_PATH(记载所有经过的AS的AS号),之后,在接收到的路由条目中的AS_PATH属性中,如果存在本地的AS号,则将拒绝学习该路由信息,防止路由回传,形成环路。 —AS_PATH属性也可以用于选路,其可以反应经过AS的数量。
IBGP的水平分割 — 针对IBGP对等体之间可能出现的环路问题所提供的解决方案
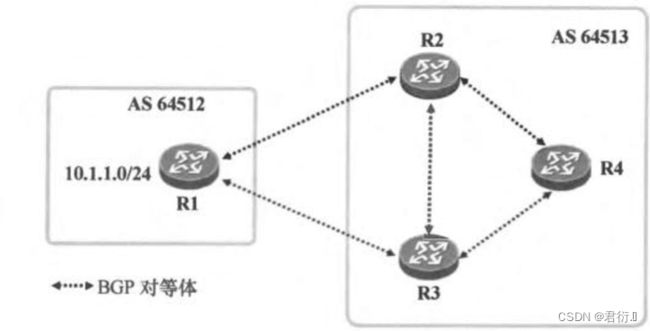
注意: 因为BGP的AS-BY-AS的特性,要求其将一个AS看作是一个整体,所以,在默认情况下,AS内部传递的路由信息的路径属性是不会发生变化的。
所以,IBGP水平分割的做法是 — 要求当路由器从一个IBGP对等体出学习到某条BGP路由时,他将不再把这条路由信息通告给其他的IBGP对等体。
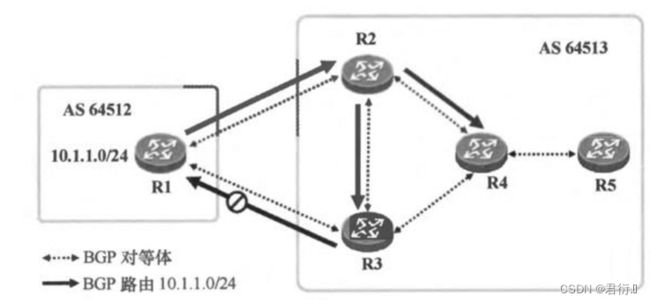
因为IBGP水平分割的限制,导致在IBGP对等体内部,BGP的路由信息只能传递一次,这样将会造成通信障碍。
==可以通过建立全联的IBGP对等体关系来解决通信障碍。 ==- 1,资源占用将变大;
- 2,将降低网络的可拓展性。
1,路由反射器;
2,联邦 — 专门用来解决IBGP水平分割机制造成的通信障碍。
6、BGP的基本配置
6.1 对等体关系建立
1)EBGP直连邻居建立
- 1,启动BGP进程
[R1]bgp 1#AS号
#因为BGP设备只能存在在一个AS中,
#所以,BGP一台设备上只能启动一个进程
[R1-bgp]
- 2,配置
RID
[R1-bgp]router-id 1.1.1.1
- 3,手动指定邻居关系
[R1-bgp]peer 12.0.0.2 as-number 2
#注意,手工指定一定是双向的
[R1]display bgp peer
#查看BGP邻居表
2)IBGP对等体之间环回接口建邻
由于IBGP对等体之间处于同一个AS中,正常一个AS内部将存在大量的备份路径,若使用物理接口建立邻居关系,将浪费备份资源,所以建议使用环回接口来建立IBGP对等体关系。
[r2-bgp]peer 3.3.3.3 as-number 2
[r2-bgp]peer 3.3.3.3 connect-interface
LoopBack 0 — 给3.3.3.3发消息使用环回接口的IP地址。 — 使用环回接口建立对等体关系一定需要执行这个命令,否则邻居关系将建立失败。
3)EBGP对等体之间的非直连建邻
前提条件: 建邻的IP之间必须可达,可以使用静态路由来保证。
[r4-bgp]peer 5.5.5.5 ebgp-max-hop 2
#修改EBGP对等体之间发送数据报中的TTL值
[r5-bgp]peer 4.4.4.4 ebgp-max-hop
#直接将ttl值修改为255
4)路由发布
对于BGP而言,只要是路由表中存在的路由信息,都可以发布
1)通过network命令发布路由
[R1-bgp]network 1.1.1.0 24
#后面跟目标网络号及掩码信息
[R1]display bgp routing-table
#查看BGP表
NextHop
- 谁发送的路由信息,则下一跳就写谁;
- 如果是自己始发的,则下一跳写0.0.0.0
状态码
*-- 代表可用。 — 所有设备收到路由条目后,首先会根据下一跳属性中的参数来查询本地路由表,查看该地址的可达性。如果,本地路由表中可达,则代表该路由信息可用;如果不可达,则该路由信息将不可用。 ---- 如果该路由条目不可用,则将不会参与路由信息的优选。
>–代表优选。 ---- 当收到多条到达相同网段的路由信息时,并且都可用,则将依据属性在其中选择最优的进行加表及传递。
1.1.1.0/24 EBGP 255 0 D 12.0.0.1 GigabitEthernet0/0/0 — 下一跳字段将直接使用下一跳属性中的地址,我们将BGP的路由信息的优先级设置为255。
i-- 状态码为I,代表该路由信息是通过IBGP对等体学到的。
[r2-bgp]peer 3.3.3.3 next-hop-local --- 将下一跳属性修改为自身
2)重发布
[r2-bgp]import-route ospf 1
Ogn — 起源码
一共存在三种
- — I — 代表这条路由信息起源于AS内部使用network通告出来的。
- — e — 代表来自于EGP协议。
- — ? — 除了以上两种方式,其他方式获取的路由信息都是?
3)通过汇总发布
在BGP中我们将这样的操作成为路由聚合
十二、BGP的选路原则以及社会团属性
1、BGP的选路原则
BGP选路的前提条件 — BGP首先需要进行可用的校验,只有可用的路由才会参与BGP的选举。
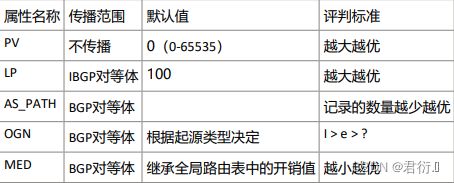

1,优选PV属性值最大的路由
PV属性是在本设备上选路优先级最高的一个属性。属性值越大越优。 ---- 这个属性不能传播。
PV属性是华为设备的私有属性。
[r4-bgp]peer 3.3.3.3 preferred-value ? --- 修改R3发来的路由的PV值
INTEGER<0-65535> Preference value
[r4-bgp]peer 3.3.3.3 preferred-value 100
AS-path 1, origin igp, MED 0, localpref 100, pref-val 0, valid, internal, pre 2
55, IGP cost 1, not preferred for PreVal
负载分担 — 即让不同的流量走不同的线路,分担单一线路的压力。
使用路由策略干涉选路:
- 1,抓取流量
[r4]ip ip-prefix PV permit 10.0.0.0 24
- 2,使用路由策略修改PV值
[r4]route-policy PV permit node 10
Info: New Sequence of this List.
[r4-route-policy]if-match ip-prefix PV
[r4-route-policy]apply preferred-value 100
[r4-route-policy]q
[r4]route-policy PV permit node 20
#创建空表放通剩余所有流量
Info: New Sequence of this List.
[r4-route-policy]q
[r4]
- 3,在BGP进程中调用策略
[r4-bgp]peer 3.3.3.3 route-policy PV import #注意,因为这个属性不能传递,所以,只能使用入方向。
2,优选LP属性值最大的路由。
LP — 本地优先级 — 默认值100,越大越优 — 这个属性是在IBGP内部选路时最常用的属性。 — 这个属性可以在IBGP对等体之间进行传递,但是,不能传递给自己的EBGP对等体。
[r3-bgp]default local-preference 200
#3发布路由条目所携带的默认LP值改为200
AS-path 1, origin igp, MED 0, localpref 100, pref-val 0, valid, internal, pre 2
55, IGP cost 1, not preferred for Local_Pref
- 1,抓取流量
[r3]ip ip-prefix LP permit 10.0.0.0 24
- 2,做路由策略
[r3]route-policy LP permit node 10
Info: New Sequence of this List.
[r3-route-policy]if-match ip-prefix LP
[r3-route-policy]apply local-preference ?
INTEGER<0-4294967295> Specify a local preference value
[r3-route-policy]apply local-preference 300
[r3-route-policy]q
[r3]route-policy LP permit node 20
Info: New Sequence of this List.
[r3-route-policy]q
- 3,在BGP中调用
[r3-bgp]peer 4.4.4.4 route-policy LP export
3,手工聚合 > 自动聚合 > network > import > 从对等体处学来的
AS-path Nil, origin igp, MED 0, localpref 100, pref-val 0, valid, internal, pre
255, IGP cost 1, not preferred for route type
4,优选AS_PATH属性最短的路由
AS_PATH属性在进行选路时,最基本的原则是记录的数量越少越优,但有两点需要额外
注意:
- 1,在聚合路由时,**如果激活AS_SET关键字,将不同的AS明细路由的AS号使用大括号括起来,**在进行防环是,所有AS都不能回传,当进行选路时,不管大括号中存在多少个AS,都将按照1个AS来看。
- 2,联邦时,联邦内部将使用
AS_PATH属性防环,我们用小括号括起来。这种情况下,我们计算AS_PATH长度时,将不考虑小括号里的内容。
注意: AS_PATH属性虽然可以在所有的BGP对等体之间进行传递,但是,只有在EBGP对等体之间传递时才会修改,所以,在进行策略干涉选路时,也需要在EBGP对等体之间来完成。
在R1上进行出方向的修改:
- 1,抓取流量
[r1]ip ip-prefix AS permit 10.0.0.0 24
- 2,做路由策略
[r1]route-policy AS permit node 10
Info: New Sequence of this List.
[r1-route-policy]if-match ip-prefix AS
[r1-route-policy]apply as-path 11 22 33 ?
INTEGER<1-4294967295> AS number in asplain format (number<1-4294967295>)
STRING<3-11>
AS number in asdot format
(number<1-65535>.number<0-65535>)
additive
Append to original As Number
#只在原先AS_PATH属性基础上
#添加额外的AS号
#因为AS_PATH属性主要用于防环,所以,建议使用添加的方法。
overwrite Overwrite original As Number
#覆盖原先的AS_PATH
[r1-route-policy]apply as-path 11 22 33 additive
[r1-route-policy]q
[r1]route-policy AS permit node 20
Info: New Sequence of this List.
[r2-route-policy]q
- 3,在BGP进程中调用
[r1-bgp]peer 12.0.0.2 route-policy AS export
Total Number of Routes: 2
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 1.1.1.0/24 12.0.0.1 0 0 1i
*> 10.0.0.0/24 12.0.0.1 0 0 1 11 22 33
i
在R2的入方向修改
Total Number of Routes: 2
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 1.1.1.0/24 12.0.0.1 0 0 1i
*> 10.0.0.0/24 12.0.0.1 0 0 11 22 33 1
i
AS-path 11 22 33 1, origin igp, MED 0, localpref 100, pref-val 0, valid, intern
al, pre 255, IGP cost 1, not preferred for AS-Path
[r2-route-policy]apply as-path 1 1 1 additive
注意: 因为AS_PATH属性在进行选路时,
只关注长短,不关注内容,所以,建议增加使用过的AS号,这样不会影响防环效果。
5,OGN属性的优选规则
Ogn — 起源码
一共存在三种
- — I — 代表这条路由信息起源于AS内部使用network通告出来的。
- — e — 代表来自于EGP协议。
- — ? — 除了以上两种方式,其他方式获取的路由信息都是?
AS-path 1, origin incomplete, MED 0, pref-val 0, valid, external, pre 255, notpreferred for Origin
在R1的出方向修改
- 1,抓取流量
[r1]ip ip-prefix OGN permit 10.0.0.0 24
- 2,做路由策略
[r1]route-policy OGN permit node 19
Info: New Sequence of this List.
[r1-route-policy]if-match ip-prefix OGN
[r1-route-policy]apply origin ?
egp Remote EGP
igp Local IGP
incomplete Unknown heritage
[r1-route-policy]apply origin incomplete
[r1-route-policy]q
[r1]route-policy OGN permit node 20
Info: New Sequence of this List.
[r1-route-policy]q
- 3,在BGP中进行调用
[r1-bgp]peer 12.0.0.2 route-policy OGN export
6,优选MED值最小的路由
MED — 多出口鉴别属性
MED值的初始默认值并不是0,而是继承了全局路由表中该路由信息的开销值。
因为MED值反应的是AS边界设备到达内部网段的开销情况,所以,如果存在多个出口,则可以通过这个属性判断走那个出口到达目标网段开销更小。
BGP协议在进行宣告时,是宣告本地路由表中的任意路由,不关注这些路由条目的产生方式,默认将携带这些路由的开销值,到BGP的路由条目中的MED属性中。 若将本地宣告的BGP路由传递给本地的EBGP对等体时,将携带这些MED值,便于其他AS选择出口进入本地AS;如果通过IBGP对等体学来的路由信息中包含MED属性,则将该路由信息再通告给其他的EBGP对等体时,将不会携带MED属性,因为这些度量并不是本地产生的
总结: 若存在多对EBGP对等体关系时,建议所有设备都将AS内部的路由进行通告,避免选路不佳的情况产生。
注意: MED属性是为了方便判断一个AS的多个出口到达目标网段的开销,所以,在接受
多条路由时,将查看AS_PATH最左边的AS号,相同,则比较MED属性,不同则不比较,将直接比较第七条规则。
在R2上做出方向的策略影响R1的选路
- 1,抓取流量
[r2]ip ip-prefix MED permit 99.0.0.0 24
- 2,做路由策略
[r2]route-policy MED permit node 10
Info: New Sequence of this List.
[r2-route-policy]if-match ip-prefix MED
[r2-route-policy]apply cost 10
[r2-route-policy]q
[[r2]route-policy MED permit node 20
Info: New Sequence of this List.
[r2-route-policy]q
- 3,在BGP进程中调用
[r2-bgp]peer 12.0.0.1 route-policy MED export
7,优先选择来自EBGP对等体的路由。
AS-path 3, origin igp, MED 0, localpref 100, pref-val 0, valid, internal, pre 2
55, IGP cost 1, not preferred for peer type
8,优选到NEXT-HOP的IGP度量最小的路由
这条规则比较的就是到达下一跳地址本地路由表中的开销值。
AS-path 1, origin igp, MED 0, localpref 100, pref-val 0, valid, internal, pre 2
55, IGP cost 11, not preferred for IGP cost
2、BGP的路由过滤
1,通过路由策略进行过滤
- 1,抓取流量
[r1]ip ip-prefix aa permit 192.168.1.0 24
- 2,配置路由策略
[r1]route-policy aa deny node 10
Info: New Sequence of this List.
[r1-route-policy]if-match ip-prefix aa
[r1-route-policy]q
[r1]route-policy aa permit node 20
Info: New Sequence of this List.
[r1-route-policy]q
- 3,在BGP进程调用
[r1-bgp]peer 12.0.0.2 route-policy aa export
2,通过前缀列表来过滤路由
- 1,抓取流量并过滤
[r2]ip ip-prefix aa deny 192.168.2.0 24
[r2]ip ip-prefix aa permit 0.0.0.0 0 less-equal 32 #注意,需要放通所有剩余流量
- 2,在BGP进程中进行调用
[r2-bgp]peer 12.0.0.1 ip-prefix aa import
- 3,通过过滤策略来进行过滤
-
- 1,抓流量
[r3]ip ip-prefix aa deny 192.168.2.0 24
[r3]ip ip-prefix aa permit 0.0.0.0 0 less-equal 32
-
- 2,在BGP进程中调用
[r3-bgp]filter-policy ip-prefix aa import
#直接在进程中调用过滤策略
#也可以在peer中调用,
#注意,在peer中调用时,只能使用ACL列表抓取流量。
[r3-acl-basic-2000]rule deny source 192.168.3.0 0
[r3-acl-basic-2000]rule permit source any
[r3-bgp]peer 13.0.0.1 filter-policy 2000 import
3、BGP的社会团属性
所谓社团属性,相当于是一个路由标记,我们可以给需要通告的路由信息打上不同的社团属性,之后,我们可以根据不同的社团属性抓取流量,执行不同的策略。 — 社团属性本质由32位二进制构成— 1,直接使用十进制表示;2,AS:NN — AS号:自定义值(各占16位) — 一条路由信息,可以存在多个社团属性。
BGP中也定义了几个公认的BGP社团属性。
- 1,
0X00000000— 全0的社团属性 — “internet” — 相当于是最大的一个集合,所有BGP路由默认都属于该集合中。 - 2,
0XFFFFFF02— “no - Advertise” — 一旦一条路由信息打上该社团属性,则他将不会通告给自己的BGP对等体。 - 3,
0XFFFFFF01— “No - Export” — 一旦一条路由信息打上该社团属性,则他将不会通告给自己的EBGP对等体关系。(但是可以通告给自己的联邦EBGP对等体) - 4,
0XFFFFFF03— “No - Export - subconfed” — 一旦一条路由信息打上该社团属性,则他将不会通告给自己的EBGP对等体关系。(则也不可以通告给自己的联邦EBGP对等体)
配置路由策略
[r1]route-policy com permit node 10
Info: New Sequence of this List.
[r1-route-policy]apply community ?
INTEGER<0-4294967295> Specify community number
STRING<3-11> Specify aa<0-65535>:nn<0-65535>
internet Internet(well-known community attributes)
no-advertise Do not advertise to any peer (well-known community attributes)
no-export Do not export to external peers(well-known community attributes)
no-export-subconfed Do not send outside a sub-confederation(well-known community attributes)
none No community attribute
[r1-route-policy]apply community no-advertise
[r1-route-policy]q
[r1-bgp]peer 12.0.0.2 route-policy com export
注意: 华为体系中,默认关闭了社团属性的传递,需要手工配置打开
[r1-bgp]peer 12.0.0.2 advertise-community
Community:no-advertise
Community:<1:11>
- 1,配置策略
[r1]route-policy com1 permit node 10
Info: New Sequence of this List.
[r1-route-policy]apply community 1:11
[r1]route-policy com2 permit node 10
Info: New Sequence of this List.
[r1-route-policy]apply community 1:22
2,在发布路由时调用
[r1-bgp]network 172.16.1.0 24 route-policy com1
[r1-bgp]network 172.16.2.0 24 route-policy com1
[r1-bgp]network 172.16.3.0 24 route-policy com2
[r1-bgp]network 172.16.4.0 24 route-policy com2
社团属性过滤器 — community - filter
- 1,通过过滤器抓流量
[r2]ip community-filter 1 permit 1:11
[r2]ip community-filter 2 permit 1:22
- 2,配置路由策略
[r2]route-policy aa deny node 10
Info: New Sequence of this List.
[[r2-route-policy]if-match community-filter 1
[r2-route-policy]q
[r2]route-policy aa permit node 20
Info: New Sequence of this List.
[r2-route-policy]if-match community-filter 2
[r2-route-policy]apply community no-export additive
#添加多个社团属性需要后面增加additive命令
[r2-route-policy]q
[[r2]route-policy aa permit node 30
Info: New Sequence of this List.
[r2-route-policy]q
- 3,调用
[r2-bgp]peer 12.0.0.1 route-policy aa import
[r2-bgp]
十三、MPLS多协议标签交换
MPLS — 多协议标签交换
包交换 — 所谓包交换,数据组成数据包,在各个网络节点中不断传递,最终到达目标。(可以简单的理解为是三层转发的过程)
其实,我们对于包交换的转发方式并不是很满意,主要是因为他的转发效率太低:
- 1,完成过程需要查两张表 — 路由表,ARP缓存表
- 2,路由表的匹配原则 — 最长匹配原则
- 3,递归查找 — 在一定情况下,设备需要递归查找出接口或者下一跳。
- 4,IPV4头部是可变长头部 — 则处理头部信息时必须依靠软件来处理。相较而言,交换机的二层转发可以基于硬件来实现(通过使用支持二元运算的硬件芯片。如:CAM),这样,即使MAC地址表中的条目数量很多,也可以在短时间内完成匹配动作,效率要远高于路由表的软件查找。
1、标签交换
在二层和三层封装之间,添加一个和路由条目存在映射关系的标签,之后,维护一张记录对应关系和转发接口表。携带标签的数据来到设备上,将先看到标签,之后,基于维护的表进行转发,而不看三层的IP数据。因为标签本身短小而且定长,所以其转发效率应该高于包交换。
但是标签交换需要给数据包中先打上标签,之后到达目标之前,还需要弹出标签,因为标签只是在传输过程中提高转发效率的手段。因为有这些动作的存在,所以,标签交换转发效率的提升相较于包交换并不明显。
因为标签交换的转发效率提升并不是很明显,所以,我们在数据转发上又继续研发改进包交换。包交换至今,存在3次大的变更。
- 1,进程交换 —
process switching— 最早的包交换,就是每个数据包到设备上需要先根据IP地址查询路由表,之后,在查看ARP缓存表实现转发。 - 2,快速包交换 —
Fast switching— 基于流的包交换 — 一次路由,多次交换 — 一股数据流来到设备上,只需要针对数据流中的第一个数据包进行路由查询过程,之后,将数据包的特征(一般使用五元组来标识数据流)及转发方式记录在缓存中,之后,数据流中的其他数据包来到设备上,将直接比对缓存中的特征,比对上则直接按照转发方式进行转发,而不需要所有数据包都进行路由过程,可以大大的提高转发效率。 - 3,思科的特快交换 —
Cisco Express Forwading— 简称CEF,其思路就是将路由表和ARP缓存表中的内容进行预读取,之后都记录在CEF表中。并且该表支持硬件转发。
虽然CEF是思科的私有技术,但是,各大厂商也根据其思路设计出了属于自己的特快交换技术。华为在进行数据转发时,使用的就是FIB(转发信息数据库),该表就是可以支持硬件处理的转发表。
MPLS — 和包交换共同发展的一个标签交换技术。因为标签交换中的标签需要很路由信息相关,MPLS作为多协议标签交换技术,可以识别并兼容多种三层协议(IPV4,IPV6…),其兼容性较强。
MPLS主要应用于三大领域
- 1,用于解决BGP的路由黑洞问题。
- 2,
MPLS VPN - 3,
MPLS TE— 流量工程 — 简单理解为控制流量转发的路径。
所有路由器激活MPLS之后,将按照MPLS的规则实现标签交换,这些运行了标签交换的设备所组成的MPLS网络,我们称为MPLS域。
所有运行了MPLS的路由器,都可以称为LSR(标签交换路由器)
因为所有匹配到同一条路由的所有数据报文,他们最终走的路由都是一样的,所以,我们只需要给他们分配同一个标签即可。在MPLS中,我们把这些具有相同特征的数据报文称为FEC — 等价转发类。一个FEC只需要分配一个标签即可。
标签分配后,设备需要将路由信息和标签的映射关系记录在一张表中 — LIB(标签信息表),之后,结合FIB表,生成LFIB(标签转发表) — 这张表中记录的时标签编号,和对应出接口和下一跳信息。
MPLS和包交换一样,其过程也可以分为控制层面和数据层面
包交换
-
控制层面 — 路由协议的数据流方向,目的时为了获取未知网段的路由信息,生成路由表。
-
数据层面 — 设备基于已经完善的路由表(FIB表),来转发具体的数据信息,其方向和控制层面相反
MPLS
- 控制层面 — 基于FEC分配标签,并获取其他LSR对同一个FEC分配的标签,记录生成LIB表,之后再结合FIB表生成LFIB表。(这个过程可以通过手工静态实现,也可以通过动态协议来实现 — LDP协议:标签分发协议)
- 数据层面 — 设备基于LFIB表,根据标签进行转发。
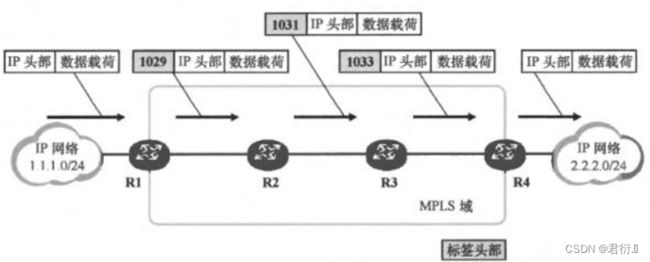
入站LSR — ingress — MPLS域的一个边界,之前数据包中不存在标签,数据来到设备上之后,需要压入标签,完成压入动作的设备,我们称为入站LSR。
中转LSR — transit — 在标签交换过程中完成标签置换动作的LSR
出站LSR — egress — 弹出标签,之后基于三层IP头部进行包交换的LSR设备。
我们标签交换数据流量走过的路径 — R1 - R2 - R3 - R4,这条路径我们称为LSP — 标签交换路径。特别注意,LSP是分方向的,如果想要实现1.0网段和2.0网段的互通,除了要有R1-R2-R3-R4这条LSP外,还需要构建一条R4-R3-R2-R1的LSP。
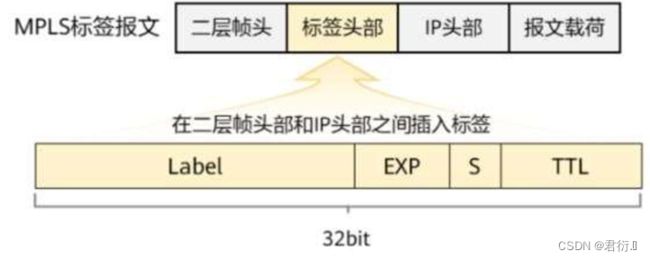
Label — 标签号 — 前20位(0 - 2的20次方 — 这个标签的取值范围可以理解为标签空间。每台设备的标签空间都是独立的。),是标签转发的主要标识依据。
- 0 - 15 — 特殊标签值 — 不能直接分配,每一个都存在特殊含义。
- 16 - 1023 ---- 一般用于静态LSP的搭建
- 1024 - 2的20次方 — LDP等一些动态协议分配标签的取值范围
EXP — 主要做策略用,占3位 — 可以理解为是优先级,数值越大,优先级越高,越高则可以优先转发数据。
S — 栈底位 — 仅占1位 — 标签不止可以打一个,可以打两个或多个。这些标签头部的有序集合我们称为标签栈。
- 如果存在多个标签,且该标签是最后一个标签,则栈底位置1,不是则置0
- 如果只有一个标签,则栈底位置1。
TTL — 生存时间 — 和三层IP头部中的TTL值作用一样,每经过一台设备转发需要减1,因为在标签交换过程中,不看IP头部,所以,TTL的计数作用就放在标签中了。在进入MPLS域时,由入站LSR将IP头部中的TTL值复制压入到标签中,之后,离开MPLS域时,再弹出标签时,将标签中的TTL值再复制回IP头部。
2、静态LSP搭建
1,创建路由条件* — 静态搭建LSP不需要所有设备都具备路由信息,因为所有路径都需要人工手工说明。只有边界设备(入站LSR和出站LSR)需要具备路由,因为他们将成为核查条件。
[r1]ip route-static 4.4.4.0 24 12.0.0.2
2,配置MPLS
- 1,配置LSR-ID
MPLS要求每台LSR设备都拥有唯一的身份标识,我们使用LSRID来标识,这个参数由32位二进制构成,按照IP地址格式配置,但是,只能手工配置,不能自动生成。(注意:一般情况下,我们习惯使用设备的环回接口的IP地址作为LSR - ID)
[r1]mpls lsr-id 1.1.1.1
- 2,激活MPLS
全局激活
[r1]mpls
Info: Mpls starting, please wait... OK!
[r1-mpls]
接口激活 — 所有参与MPLS转发的接口都需要激活
[r1-GigabitEthernet0/0/0]mpls
- 3,搭建静态LSP
入站LSR
[r1]static-lsp ingress 1to4 destination 4.4.4.0 24 nexthop 12.0.0.2 out-label 16
destination 4.4.4.0 24 nexthop 12.0.0.2 — 这个需要和本地路由表中的内容对应上,否则静态LSP将搭建失败
out-label — 出站标签 — 即R1将这个数据包转发后压入的标签,R2收到数据包后,需要根据这个标签判断到底是到达那个网段的数据包。
中转LSR
[r2]static-lsp transit 1to4 incoming-interface GigabitEthernet 0/0/0 in-label 16 nexthop
23.0.0.2 out-label 17
incoming-interface — 数据进入的接口
in-label — 入站标签 — 这个标签必须和R1上配置的出站标签相同
出站LSR
[r4]static-lsp egress 1to4 incoming-interface GigabitEthernet 0/0/0 in-label 18
4.4.4.0/24 12.0.0.2 GSU t[902] GE0/0/0 0x1 — 注意: 在入站LSR上,需要根据FIB表中标识判断其需要走标签交换,标识就是tunnel ID为非0值。
[r1]display mpls static-lsp #查看静态LSP

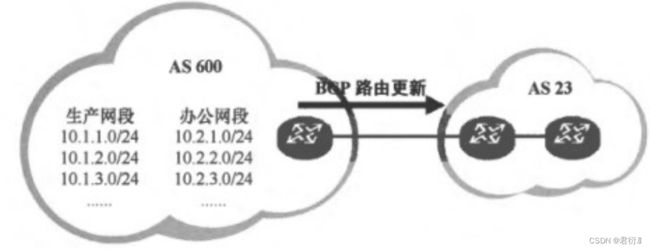
3、LDP协议
标签分发协议
LDP协议主要需要完成的任务:
- 1,分配标签;
- 2,传递标签
因为LDP协议需要完成以上两个任务,所以,我们需要先保证MPLS域中运行IGP协议来获取路由信息。 —IGP协议是LDP协议的基础。
- 1,**LDP激活后需要先在本设备上为FEC分配标签。 ** — 如果该设备是这个FEC的出站LSR时,LDP才会主动为这个FEC分配标签。例如,R4是4.0网段的出站LSR,则R4会主动为4.0网段分配一个标签。但是R1,R2,R3均不是出站LSR,则都不会主动分配标签。但是,构建LSP时也都需要有4.0网段的标签。所以,当R4将自己的标签信息传递到R3时,R3收到后,将进行检查环节 — 看本地路由表中是否存在到达4.0网段的路由信息,且路由表中的下一跳是否和通告者相同,如果检查成功,则R3也会为4.0网段分配一个标签,依次类推。 ---- 这种标签分配方式我们称为有序模式。 — 华为设备默认选择的是有序模式。
除了有序模式以外,还存在一种标签分配方式 — 独立模式。独立模式就是设备可以自主的分配标签而不需要等待其他设备的通告。
- 2,传递标签
传递标签的前提条件是设备之间必须先是LDP对等体关系才行,而对等体关系建立的前提条件是需要先建立LDP会话。
LDP会话存在两种类型 -
- 1,本地会话 — 直连设备之间建立的LDP会话
-
- 2,远程会话 — 并不一定是直连设备,可以通过手工指定的方式去创建远程的LDP会话。(LDP会话可以实现非直连建邻。)
LDP会话在建立本地会话时,不需要指定邻居关系,也可以建立。 — 因为LDP协议会先以组播(224.0.0.2 — 所有路由器都会监听的本地链路组播地址)的形式发送hello包发现邻居关系。 — hello包将使用UDP协议进行封装,源目端口均为646号端口。
4、本地LDP会话建立的过程
- 1,在激活了LDP之哦胡,LSR的接口首先会周期性的发送
Hello(默认5S为周期,保活时间默认为3倍周期,15S)包来发现LDP对等体关系。
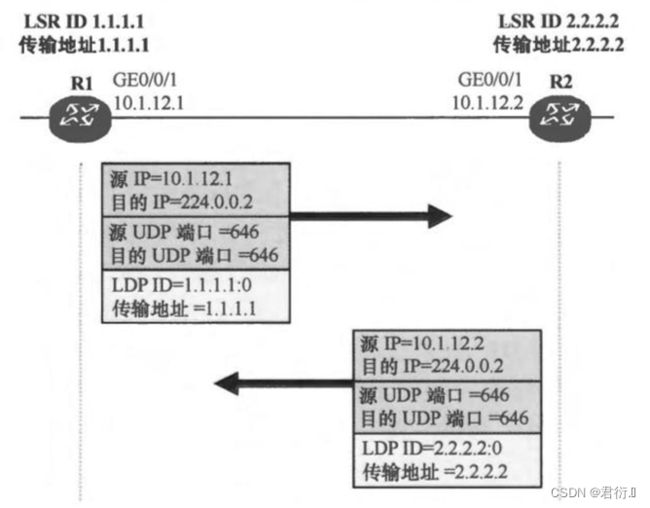
hello包在发现邻居的过程中,会携带一些参数,主要有两个参数,一个是传输地址,一个是LDP ID
-
- 传输地址:
这个传输地址是后续需要进行TCP会话建立使用的地址。 这个传输地址默认使用配置的LSR-ID,所以,我们配置设备LSR-ID时要求必须使用环回接口的IP地址,并且保证该地址可达,因为后面需要使用这个地址建立TCP会话。
- 传输地址:
-
LDP ID:
如果设备激活了LDP协议,则需要具有一个LDP ID。 ---- 由48位二进制构成。 —32:16 — 前面32位二进制使用的就是LSR-ID。后16位一般写0。
-
2,双方交互完hello包之后,则获取到对方的传输地址,之后将基于这个传输地址,建立TCP会话。
在建立TCP会话之前,也需要进入检查环节 — 检查传输地址的可达性。
因为双方都收到了对方的传输地址,则都将发起TCP会话的建立,这样将造成资源浪费,因为一方发起则建立的时一个双向的通道。所以,LDP在发起TCP会话之前,会先比较传输地址,谁的传输地址大,谁就是主动方,则可以主动发起TCP会话请
求。
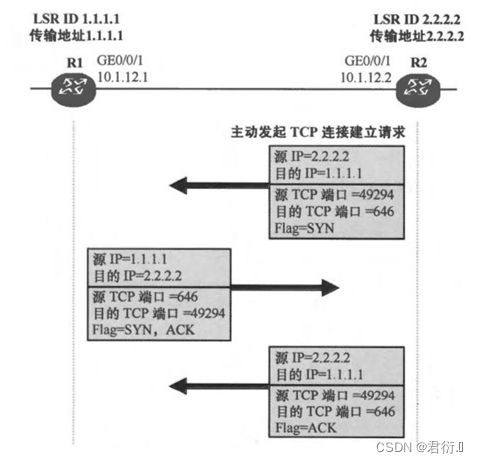
3,完成TCP会话建立之后,将开始建立LDP会话。传输地址大的一方,优先发送初始化的报文,里面将包含需要协商建立LDP会话的参数。对端收到后,如果认可,可以将自己的初始化报文发送,并且同时发送一个Keeplive报文,进行确认。如果双方都确认完成,则LDP会话建立完成。
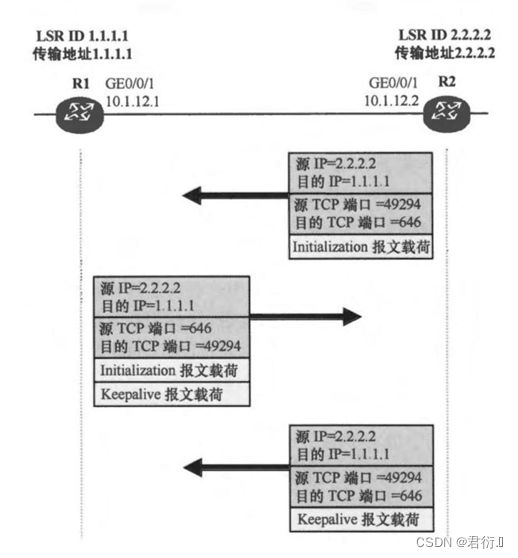
LDP协议也会周期性的发送keeplive来保活会话。 ---- 周期时间为15S,失效判断时间为3倍周期时间,默认45S。
十四、MPLS VPN的配置使用

上下游关系 — 在标签交换中,我们将以数据流动的方向为准,区分上下游关系,数据发出设备处于上游,而接受设备处于下游。 — 控层流量流动的方向是和数据层流动方向相反,即从下游传递到上游。 — 上游需要获取下游的标签,而下游不需要获取上游的标签。
标签传递方式也分为两种 — 1,DU模式(下游自主模式);2,DoD模式(下游按需模式)
DoD模式 — 就是下游在给上游传递标签之前,需要先获取上游发送的数据包,之后,才可以传递标签信息。
DU模式 — 在分配完标签之后,设备将自主的传递标签,因为设备本身无法分辨上下游关系,所以,这个标签将传递给自己的上游和下游。
标签的保存方式 — 保守模式 — 只保留下游传递的标签
自由模式 — 所有标签均保存
华为设备默认选择DU + 保守模式
在数据传输过程中,入站LSR和出站LSR都将查看两张表(FIB和LFIB),这样将导致传输效率下降。
入站LSR的优化 — 将LFIB表中的出站标签记录在FIB表中出站LSR的优化 — PHP — 次末跳弹出机制 — 需要用到一个特殊标签值 – 3(隐式空标签),当一条条目中的出站标签为3时,则他将把标签弹出 — 出站LSR在分配标签时,分配3号标签,之后传递给次末跳。之后,数据转发时,标签将在次末跳上弹出,在出站LSR上只需要查看FIB进行路由转发即可。 — 华为设备默认开启PHP机制。
1,配置LSR-ID
[r1]mpls lsr-id 1.1.1.1
2,激活MPLS和LDP
全局激活
[r1]mpls — 激活MPLS
Info: Mpls starting, please wait… OK!
[r1-mpls]
[r1]mpls ldp — 激活LDP
[r1-mpls-ldp]
接口激活 — 所有参与MPLS转发的接口都需要激活
[r1-GigabitEthernet0/0/0]mpls — 激活MPLS
[r1-GigabitEthernet0/0/0]mpls ldp — 激活LDP
[r1]display mpls ldp peer — 查看LDP对等体
[r1]display mpls ldp session — 查看LDP会话
[r1]display mpls lsp — 查看LFIB表
[r1]display fib verbose — 查看FIB表细节信息
[r4-mpls]lsp-trigger all — 给所有的路由条目都分配标签 — 默认情况下,华为设备只给主机路由分配标签,因为如果所有路由都分配标签,则都需要走标签交换,将导致转发效率降低。所以,仅针对部分路由分配。
利用MPLS解决BGP的路由黑洞问题
[r2]route recursive-lookup tunnel
MPLS VPN
VPN — 虚拟专用网
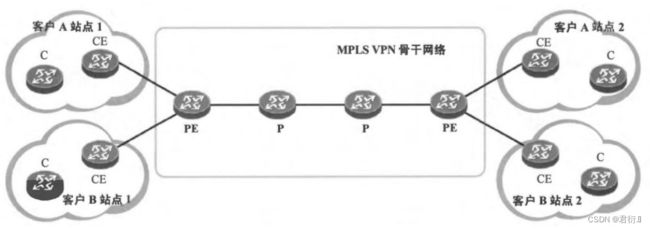
站点 — 可以理解为同属于一个企业或机构,位于不同地理位置的IP网络。
MPLS VPN并不是单一的一种VPN技术,而是由多种技术结合的综合解决方案。
PE — 服务提供商边界设备 — 一方面需要接入到VPN骨干网络中,另一方面需要为不同的客户提供VPN接入服务,和CE(客户边界设备)设备相连
P — 服务提供商设备 — 在MPLS VPN骨干网中的设备,并不连接CE,只是提供路由快速的转发。
C — 客户设备 — 在MPLS VPN中不扮演实质性的角色
控制层面 — 站点1的CE设备通过IGP协议学习本站点内的路由信息,之后,传递给PE设备(可以使用静态或者动态来进行传递),之后,PE设备通过骨干网络传递给远端的PE设备(使用BGP来传递),远端PE在将路由信息传递给站点2的CE设备(动态静态方法均可),之后,站点2的CE设备再通过IGP协议将路由信息发送到本站点内部。
数据层面 — 站点2的想访问站点1的网段,数据先到达站点2的CE设备,之后,传递给PE设备。PE设备再传递到远端的PE设备,之后,再传递到站点1的CE设备,再由CE设备发送到目标网段。
控制层面
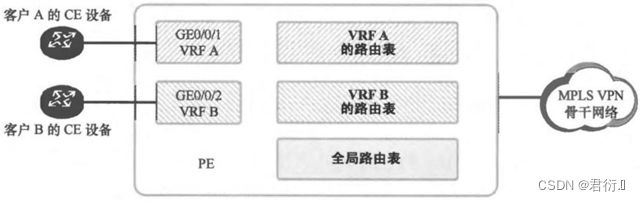
VRF — 虚拟路由转发 — VPN Instance(VPN实例) — 相当于将一台真实的设备逻辑上划分成多台虚拟的路由器。每个VRF各自拥有独立的路由表,FIB表,动态路由协议进程及接口等。
RD值 — 路由区分码 — 由64位二进制构成的 — AS:NN — AS号:自定义值

IPV4路由信息 — 32位二进制构成
加了RD值之后 — 96位二进制构成 ---- VPNV4路由信息
因为普通的BGPV4版本只是针对IPV4环境,传递的是IPV4路由,这里需要传递VPNV4路由,所以,需要应用到MP-BGP协议(多协议BGP协议),可以支持多种地址族。
RT值 — 路由目标值 — 也被称为VPN target — 32位二进制构成
出站RT:PE设备为不同的VRF配置不同出站RT值,发出时由社团属性携带。
入站RT:远端PE设备为不同VRF空间配置的不同的入站RT,根据社团属性中的值进行对比,将其放入到对应的VRF空间中。
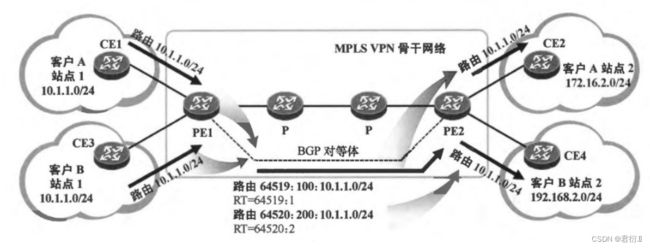
数据层面
在数据层流量穿过骨干网络时,需要打上双重标签。一个靠近二层的标签,我们称为公网标签;一个靠近三层的标签,我们称为私网标签。公网标签由LDP协议分配,其作用是保证数据流量可以顺利的通过MPLS骨干网络,而私网标签,由MP-BGP协议分配(在传递路由信息时分配,之后通过社团属性携带传递到对端),其作用是用来区分不同的VRF空间。数据到达远端PE后,先弹出公网标签,之后露出私网标签,可以根据私网标签和VRF的映射关系,将数据发放到对应的VRF空间中。
VRF空间的创建
[r2]ip -instance a ---- VRF空间在命名时大小写敏感
[r2--instance-a]
[r2--instance-a]route-distinguisher 100:1 — 配置RD值
[r2--instance-a-af-ipv4]
[r2--instance-a-af-ipv4]-target 100:1 export-extcommunity — 配置出站RT
EVT Assignment result:
Info: VPN-Target assignment is successful.
[r2--instance-a-af-ipv4]-target 100:2 import-extcommunity — 配置入站RT
IVT Assignment result:
Info: VPN-Target assignment is successful.
将接口划入到VRF空间中
[r2-GigabitEthernet0/0/0]ip binding -instance a
Info: All IPv4 related configurations on this interface are removed!
Info: All IPv6 related configurations on this interface are removed!
[r2]display ip routing-table -instance a — 查看VRF空间的路由表
[r2]ping --instance a 192.168.2.1
通过静态路由在CE和PE上配置
[r2]ip route-static -instance a 192.168.1.0 24 192.168.2.1
MP-BGP
[r2-bgp]ipv4-family v4
[r2-bgp-af-v4]peer 4.4.4.4 enable — 因为PE设备之间需要传递VPNV4路由,所以,在普通的BGPV4邻居关系建立的基础上,需要在VPNV4地址族中激活邻居关系
[r2-bgp]ipv4-family -instance a ---- 在VRF空间中发布路由信息
[r2-bgp-a]
[r2-bgp-a]import-route direct
[r2-bgp-a]import-route static
[r2]display bgp v4 -instance a routing-table — 查看VRF空间的BGP表
CE和PE设备之间动态路由传递
[r2]rip 1 -instance a — 在VRF空间中启动RIP进程
[r2-rip-1]
[r4]ospf 2 -instance b router-id 4.4.4.4 — 在VRF空间中启动OSPF进程
[r4-ospf-2]
十五、实际情况配置
网络的三层架构 — 园区网搭建的建议方案
园区 — 工厂,政府机关,商场,写字楼,校园,公园等,这些公共场所为了实现数据的互通而搭建的网络称为园区网。
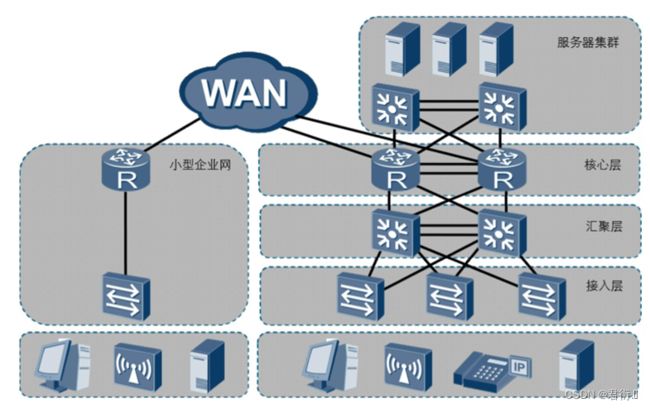
接入层 — 有接入层交换机(一般就是二层交换机)组成,为终端设备提供接入网络条件。
WLAN — 无线局域网 — 从广义上来讲,指以无线电波,激光,红外线等代替有线局域网中的部分或全部传输介质所以构成的网络。
“无线是有线的最后一公里”
AP – 无线接入点
无线网络的缺陷
1,传输速率本身较低并且信号强弱波动较大
2,无线信号本身穿透性较差
2.4G,5G
3,接入人数较多时,会出现明显的卡顿
CSMA/CD — 载波侦听多路访问/冲突检测 — 将设备通过AP接入到无线网络中,也相当于接入到一个冲突域中,所以需要去进行冲突避免。但是,因为无线网络本身信号强度的动态范围非常大,往往接收到的信号强度远小于发出时的信号,导致冲突检测不易进行;并且再某些场景下,无线当中的冲突是检测不到的,所以,无法使用CD冲突检测技术,只能使用CA冲突避免技术。
CSMA/CA — 载波侦听多路访问/冲突避免
1,即使侦听到没有信号,也不会立即发送信息,而是先给自己施加一个随机的计时器,尽可能的再发送之前避免冲突。
2,CSMA/CA技术,采用了停等式流控。即每发送一个数据包,都需要对方回复ACK进行确认。
汇聚层 — 汇聚接入层收集到的流量,一般使用三层交换机来组成。
三层交换机和二层交换机最显著的区别是三层交换机即拥有像二层交换机一样的二层接口(不需要配置IP地址,也不需要MAC地址)同时也拥有像路由器一样的三层接口(需要配置IP地址,同时拥有MAC地址)。可以理解为是交换机和路由器的集成设备。既可以完成交换机的二层转发,也可以完成路由器的三层转发。其内部既有MAC地址表也存在IP路由表。
三层架构的核心 — 冗余(备份)
1,线路冗余
2,设备冗余
3,网关冗余
4,UPS冗余 — UPS — 不间断电源 — 99.9999%的可用性
核心层 — 作用是完成私网和公网之间数据的快速转发。
VLAN
LAN — 局域网 — 地理覆盖范围较小的网络
VLAN — 虚拟局域网 — 交换机和路由器协同工作,将原来的一个广播域逻辑上切分成为多个。
第一步:创建VLAN
display vlan
VID — VLAN ID — 用来区分和标识不同VLAN — IEEE组织在802.1Q标准定义VLAN ----由12位二进制构成 — 0 - 4095 — 其中0和4095保留 — 真正的取值范围 — 1 - 4094所有设备默认存在VLAN 1,并且,所有接口默认属于VLAN 1
[Huawei]vlan 2 — 创建VLAN
[Huawei]vlan batch 4 to 100 — 批量创建VLAN
第二步:将接口划入VLAN
VID配置映射到交换机的接口,实现VLAN的划分 — 物理VLAN/一层VLAN
VID配置映射到数据帧中的MAC地址,实现VLAN的划分 — 二层VLAN
数据帧中的类型字段映射VID进行VLAN的划分 — 三层VLAN

通过IP地址划分VLAN ,通过策略来划分VLAN
802.1Q帧 — 在以太网Ⅱ型帧的基础上,在源MAC地址和类型字段之间,添加了4个字节的TAG(包含12位的VID)。也可以将这种打了标签的帧称为tagged帧,正常没有打标签的帧可以称为untagged帧。
因为我们的电脑是无法识别tagged帧,只有交换机(支持802.1Q的设备)才能识别。根据这个特性,我们把交换机和电脑之间的链路称为Access链路,交换机侧的接口称为Access接口,这些链路中只能通过untagged帧,并且这些帧只能属于某一种特定VLAN;交换机和交换机之间的链路称为trunk链路(trunk干道),交换机侧的接口称为trunk接口,这些链路中可以通过tagged帧,并且,这些帧可以属于多个vlan。
第三步:配置trunk干道
第二步配置
[sw1-GigabitEthernet0/0/1]port link-type access
[sw1-GigabitEthernet0/0/1]port default vlan 2
[sw1]port-group group-member GigabitEthernet 0/0/3 GigabitEthernet 0/0/4
[sw1-port-group] — 创建接口组
第三步配置
[sw1-GigabitEthernet0/0/5]port link-type trunk
[sw1-GigabitEthernet0/0/5]port trunk allow-pass vlan 2 to 3
[sw2-GigabitEthernet0/0/3]port trunk allow-pass vlan all
hybrid — 混杂接口
[sw1]display port vlan active
华为交换机设备所有接口默认情况下都是hybrid 类型,混杂接口。
PVID — 接口所对应的VID值,可以理解为接口所属VLAN。华为设备,默认情况下,所有接口的PVID值为1。
华为设备VLAN技术中规定,所有通过接口进入到交换机的数据,都必须打上接口对应PVID的标签。也就是说,交换机内部的所有数据都是带标签的数据。
VLAN List — 接口允许通过的VLAN列表 — ACCESS接口因为只允许通过接口所属的VLAN的流量,所以,其允许列表只能通过一个VLAN且和PVID相同。Trunk干道允许通过多个VLAN,默认放通VLAN 1的流量,之后,可以通过port trunk allow-pass vlan XX去放通其他VLAN的流量。
U/T标记
— U — Untagged — 代表后面允许列表中的VLAN数据在通过时不携带标签发出。
— T — Tagged — 代表后面允许列表中的VLAN数据在通过时携带标签发出。
Trunk干道在发出流量时,为了区分不同VLAN的流量,需要带上标签,只有该TRUNK接口PVID对应的VLAN的流量需要剥离标签。
ACCESS接口
1,当ACCESS接口从链路上接收到一个untagged帧时。 ---- 交换机接收到这个帧后,需要先添加vid为PVID的tag。然后,看允许列表,如果允许列表存在该VID(ACCESS接口必然存在),则转发。
2,当一个tagged帧从交换机的其他端口到达一个ACCESS接口后。 — 则交换机会先检查该数据帧标签中VID值在不在自己的允许列表中。如果在,则剥离标签后转发,如果不在,则丢弃。
3,如果ACCESS接口从链路上接受到一个tagged帧。交换机不需要再打标签,而是查看他的VID是否再自己的允许列表中,如果在,则可以转发;如果不在,则丢弃。
Trunk接口
1,当trunk接口从链路上收到一个untagged帧 — 交换机会先在数据帧中打上和PVID相同VID的标签。之后查看允许列表,如果允许列表中存在该VID,则转发;如果不存在,则直接丢弃。
2,当一个tagged帧从交换机的其他端口到达一个Trunk接口后。如果这个tag中的VID不在trunk接口的允许列表中,则直接丢弃;如果在,则进行转发。如果VID和TRUNK接口的PVID相同,则先剥离标签,之后转发;如果不同,则带标签转发
3.如果Trunk接口从链路上接受到一个tagged帧。交换机不需要再打标签,而是查看他的VID是否再自己的允许列表中,如果在,则可以转发;如果不在,则丢弃。
ACCESS接口的修改权限 — 可以修改PVID,可以修改允许列表,但是只能放通一个VLAN的流量,并且这个VLAN必须和PVID相同。出口的封装方式不能修改,这能是不带标签发出
TRUNK接口的修改权限 — 可以修改PVID,可以修改允许列表,可以放通多个VLAN的流量。出口的封装方式不能修改,和PVID相同的VLAN的流量出去时需要剥离标签,其余的出去需要携带标签。
[sw1-GigabitEthernet0/0/5]port trunk pvid vlan 2 — 修改trunk接口的PVID
hybrid — 混杂接口 — 接口的修改权限 — 可以修改PVID,可以修改允许列表,可以放通多个VLAN的流量。可以定义出口的封装方式。
[SW1-GigabitEthernet0/0/1]port link-type hybrid
[SW1-GigabitEthernet0/0/1]port hybrid pvid vlan 2
[SW1-GigabitEthernet0/0/1]port hybrid untagged vlan 2 3 4
十六、VLAN之间通信
vlan----一个网段 一个广播域
路由器可以实现异种网络的链接
路由器一般情况下路由性能比三层交换机要强(cpu,内存)路由器能实现nat,一般交换机没有NAT功能
SVI switch vlan interface 技术从根本上改变了园区网的组网架构
层次化模块化
SVI技术强化了交换机作为园区网组网的核心地位,进而也出现了三层交换机的快速转发技术(三层交换机不光在园区内取代了路由器而且转发速度更快)。
一次路由多次交换
1、生成树技术
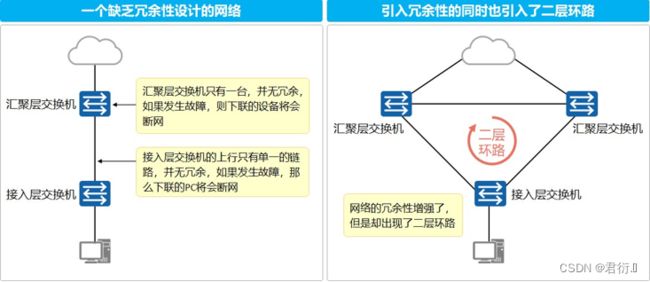
环路导致的现象:形成广播风暴
- 交换机接口的带宽资源被迅速消耗殆尽
- 交换机的转发资源也被快速消耗殆尽
- 交换机的mac地址表出现漂移,mac地址反复修改接口
解决环路是交换机必不可少的技术
生成树之BPDU bridge protocol data unit
BPDU主要分为两大类
- 配置BPDU
- TCN BPDU
其中,配置BPDU是STP进行拓扑计算的关键;TCN BPDU只在网络拓扑发生变更时才会被触发。
2、配置BPDU
配置BPDU的报文格式

十七、完整通信分类
1、实现VLAN之间通信
传统交换二层组网中,默认所有网络都处于同一个广播域,这带了诸多问题。VLAN(Virtual Local Area Network,虚拟局域网)技术的提出,满足了二层组网隔离广播域需求,使得属于不同VLAN的网络无法互访,但不同VLAN之间又存在着相互访问的需求。
- 实际网络部署中一般会将不同IP地址段划分到不同的VLAN。
- 同VLAN且同网段的PC之间可直接进行通信,无需借助三层转发设备,该通信方式被称为二层通信。
- VLAN之间需要通过三层通信实现互访,三层通信需借助三层设备。

2、使用路由器物理接口

- 路由器三层接口作为网关,转发本网段前往其它网段的流量。
- 路由器三层接口无法处理携带VLAN Tag的数据帧,因此交换机上联路由器的接口需配置为 Access。
- 路由器的一个物理接口作为一个VLAN的网关,因此存在一个VLAN就需要占用一个路由器物理接口。
- 路由器作为三层转发设备其接口数量较少,方案的可扩展性太差。
3、使用路由器子接口
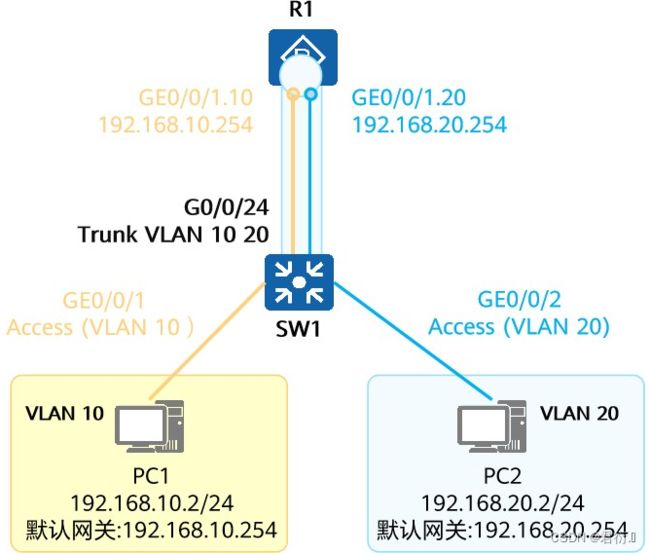
- 子接口(Sub-Interface)是基于路由器以太网接口所创建的逻辑接口,以物理接口ID+子接口ID进行标识,子接口同物理接口一样可进行三层转发。
- 子接口不同于物理接口,可以终结携带VLAN Tag的数据帧。由于三层子接口不支持VLAN报文,当它收到VLAN报文时,会将VLAN报文当成是非法报文而丢弃。因此,需要在子接口上将VLAN Tag剥掉,也就是需要VLAN终结(VLAN Termination)。
- 基于一个物理接口创建多个子接口,将该物理接口对接到交换机的Trunk接口,即可实现使用一个物理接口为多个VLAN提供三层转发服务。
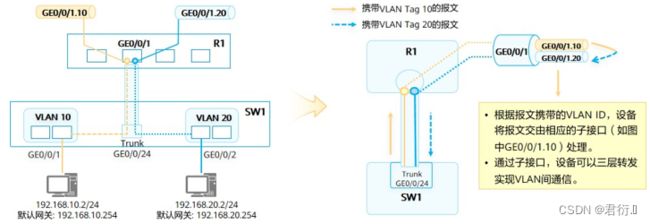
交换机连接路由器的接口类型配置为Trunk,根据报文的VLAN Tag不同,路由器将收到的报文交由对应的子接口处理。
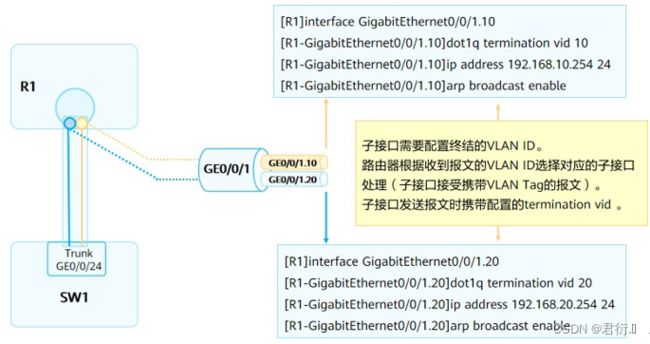
- interface interface-type interface-number.sub-interface number命令用来创建子接口。sub- interface number代表物理接口内的逻辑接口通道。一般情况下,为了方便记忆,子接口ID与所要终结的VLAN ID相同。
- dot1q termination vid命令用来配置子接口Dot1q终结的单层VLAN ID。缺省情况,子接口没有配置dot1q终结的单层VLAN ID。arp broadcast enable命令用来使能终结子接口的ARP广播功能。缺省情况下,终结子接口没有使能ARP广播功能。终结子接口不能转发广播报文,在收到广播报文后它们直接把该报文丢弃。为了允许终结子接口能转发广播报文,可以通过在子接口上执行此命令。
4、使用三层交换机的VLANIF接口
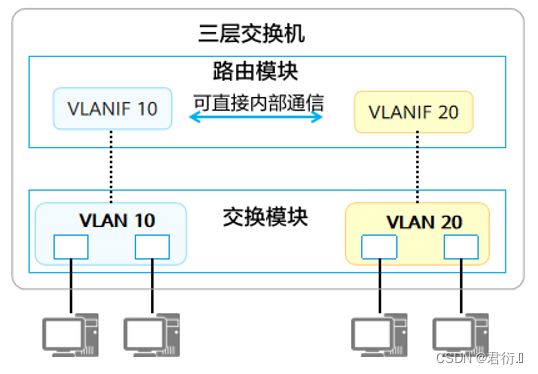
在子接口技术的启发下我们研究出了三层交换机技术,该技术彻底摆脱了物理接口。
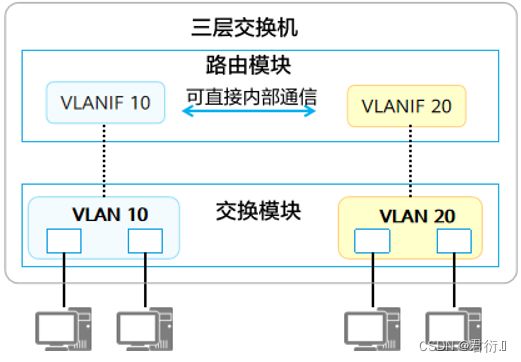
- 二层交换机(Layer 2 Switch)指的是只具备二层交换功能的交换机。
- 三层交换机(Layer 3 Switch)除了具备二层交换机的功能,还支持通过三层接口(如VLANIF接口)实现路由转发功能。
- VLANIF接口是一种三层的逻辑接口,支持VLAN Tag的剥离和添加,因此可以通过VLANIF接口实现 VLAN之间的通信。
- VLANIF接口编号与所对应的VLAN ID相同,如VLAN 10对应VLANIF 10。
4.1 配置
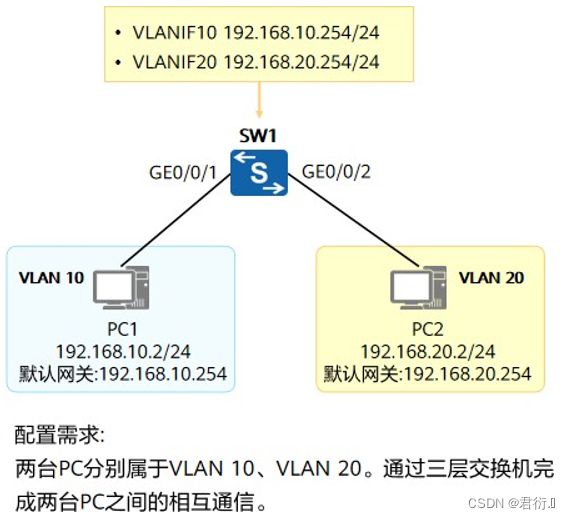
[SW1]vlan batch 10 20
[SW1] interface GigabitEthernet 0/0/1
[SW1-GigabitEthernet0/0/1] port link-type access [SW1-GigabitEthernet0/0/1] port default vlan 10 [SW1] interface GigabitEthernet 0/0/2
[SW1-GigabitEthernet0/0/2] port link-type access
[SW1-GigabitEthernet0/0/2] port default vlan 20
[SW1]interface Vlanif 10
[SW1-Vlanif10]ip address 192.168.10.254 24
[SW1]interface Vlanif 20
[SW1-Vlanif20]ip address 192.168.20.254 24
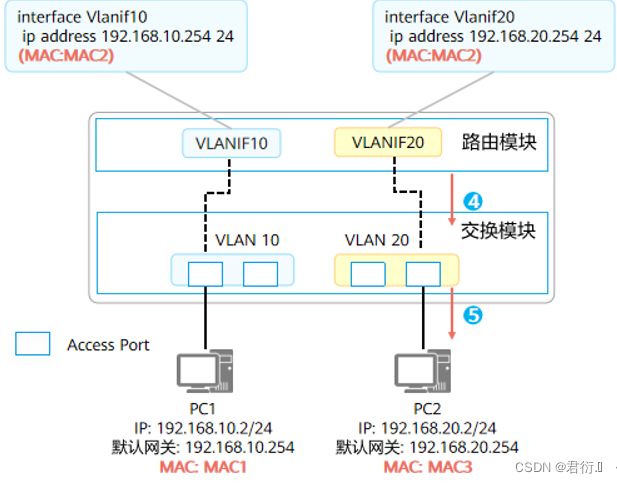
4.2 VLANIF的转发流程
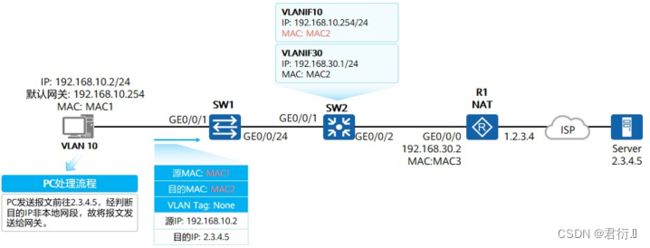
- 假设PC、三层交换机上都已存在相应的ARP或MAC表项。
- PC1与PC2之间通信过程如下:
- PC1通过本地IP地址、本地掩码、对端IP地址进行计算,发现目的设备PC2与自身不在同一个网 段,判断该通信为三层通信,将去往PC2的流量发给网关。PC1发送的数据帧:源MAC = MAC1,目的MAC = MAC2。
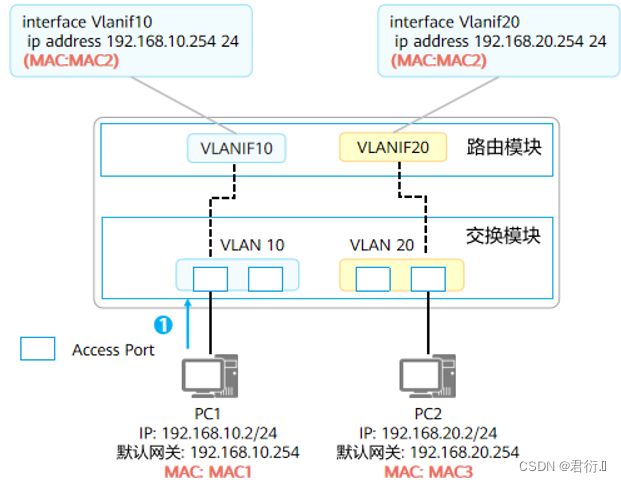
- 交换机收到PC1发送的去往PC2的报文,经解封装发现目的MAC为VLANIF10接口的MAC地址,所以将报文交给路由模块继续处理。
- 路由模块解析发现目的IP为192.168.20.2,非本地接口存在的IP地址,因此需要对该报文三层转发。查找路由表后,匹配中VLANIF20产生的直连路由。
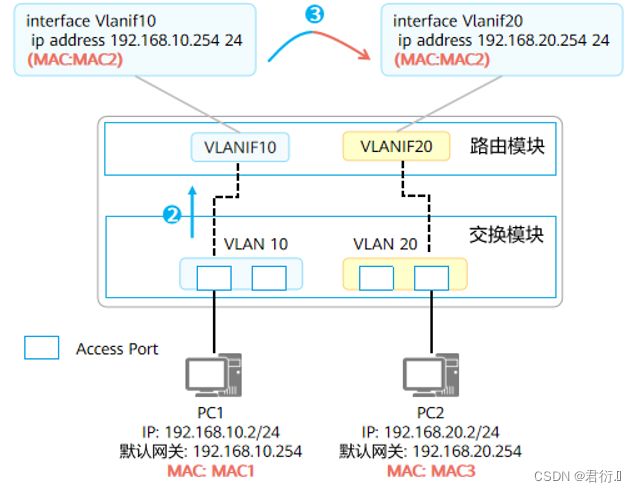
- 因为匹配的为直连路由,说明已经到达最后一跳,所以交换机在ARP表中查找192.168.20.2,获取192.168.20.2的MAC地址,交由交换模块重新封装为数据帧。
- 交换模块查找MAC地址表以明确报文出接口、是否需要携带VLAN Tag。最终交换模块发送的数据帧:源MAC = MAC2,目的MAC = MAC3,VLAN Tag = None。
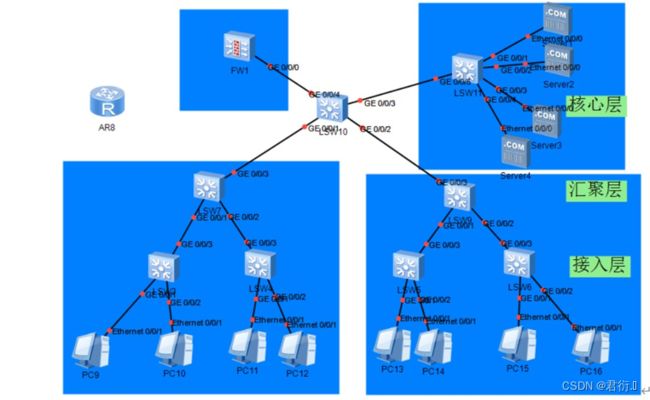
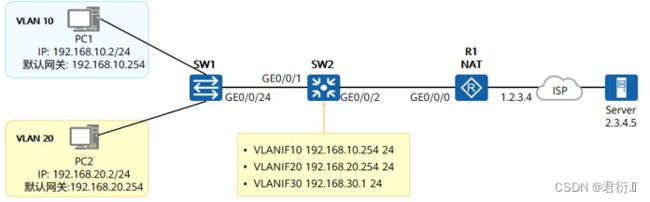
5、三层交换机参与下的三层通信流程
5.1 网络拓扑
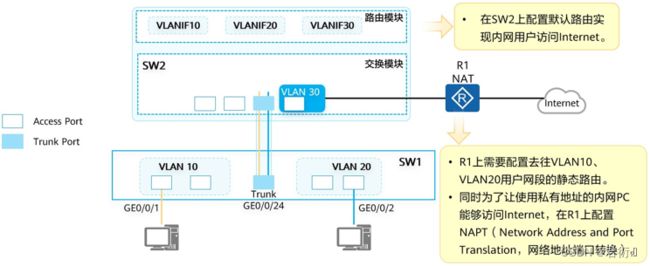
5.2 连接逻辑图
5.3 通信过程
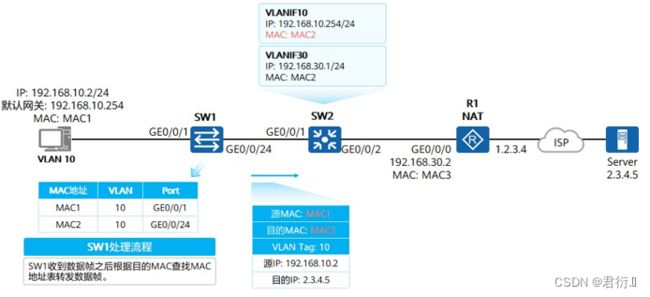
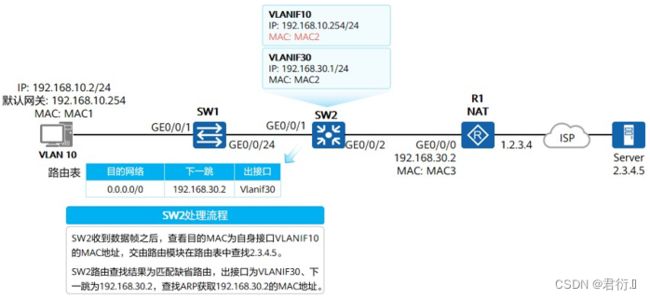
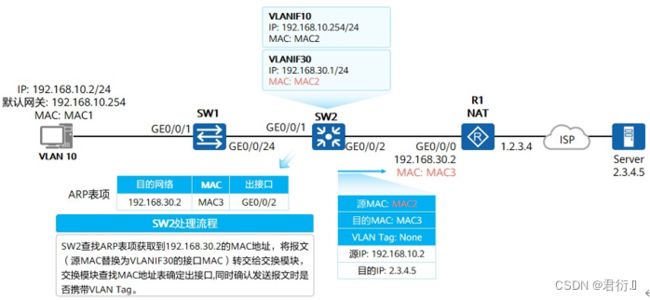
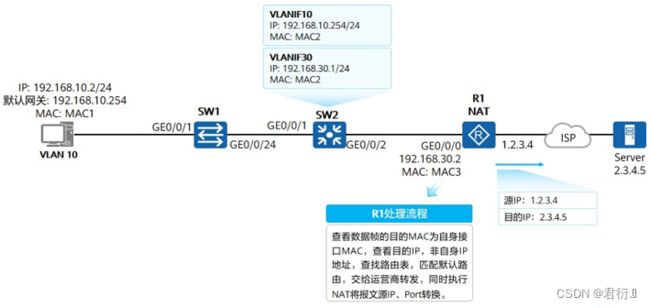
6、二层与三层接口对比
| 二层接口(Layer2 Interface) | 三层接口(Layer3 Interface) |
|---|---|
| 二层接口不能配置IP地址 | 三层接口可以配置IP地址 |
| 二层接口不具备MAC地址 | 三层接口具备MAC地址 |
| 当二层接口收到数据帧时,设备在其 MAC地址表中查询该帧的目的MAC地址,找到匹配的MAC地址表项后按照该表项的指示转发帧;如果没有找到匹配的MAC地址表项,则将帧进行泛洪。 | 三层接口收到数据帧后,如果数据帧的目的MAC地址与设备的本地MAC地址相同,则将数据帧解除封装,然后在路由表中查询数据包的目的IP地址,找到匹配的路由表项后按照该表项的指示转发包;如果没有找到匹配的表项,则将包丢弃。 |
| 典型的二层接口如二层交换机(只具备二层交换能力的交换机)的物理接口;大部分三层交换机(同时具备二层及三层交换能力的交换机)的物理接口缺省为二层接口。 | 典型的三层接口如路由器的三层接口。某些三层交换机的物理接口可以切换成三层模式。此外除了物理三层接口,还存在逻辑三层接口,例如交换机的 VLANIF,或者网络设备上的逻辑子接口,如 GE0/0/1.10。 |
| 二层接口并不隔离广播域,当二层接口收到广播帧时,会将数据帧进行泛洪。 | 三层接口隔离广播域,当三层接口收到广播帧时,缺省不会进行泛洪,而是直接终结。 |
十八、STP
1、STP概述
以太网交换网络中为了进行链路备份,提高网络可靠性,通常会使用冗余链路。但是使用冗余链路会在交换网络上产生环路,引发广播风暴以及MAC地址表不稳定等故障现象,从而导致用户通信质量较差,甚至通信中断。为解决交换网络中的环路问题,提出了生成树协议STP(Spanning Tree Protocol)。
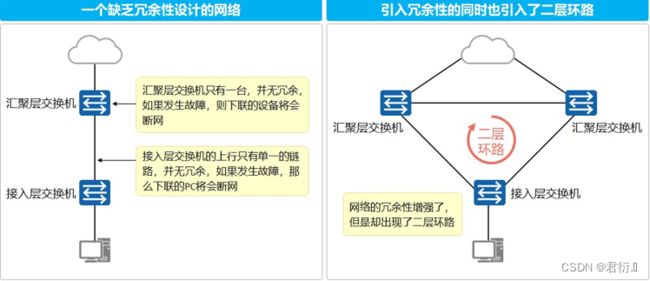
- 随着局域网规模的不断扩大,越来越多的交换机被用来实现主机之间的互连。如图,接入层交换机单链路上联,则存在单链路故障,也就是如果这根上联链路发生故障,交换机下联用户就断网了。另一个问题的单点故障,也就是交换机如果宕机,交换机下联用户也就断网了。
- 为了解决此类问题,交换机在互连时一般都会使用冗余链路来实现备份。冗余链路虽然增强了网络的可靠性,但是也会产生环路,而环路会带来一系列的问题,继而导致通信质量下降和通信业务中断等问题。
2、二层环路带来的问题
2.1 广播风暴问题
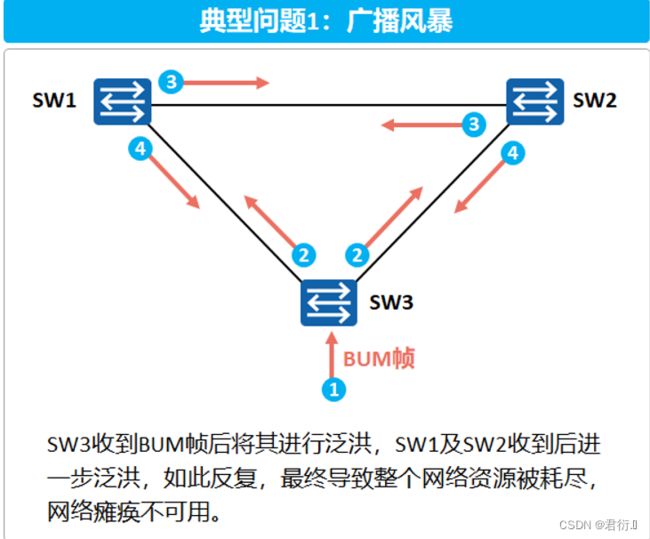
- 根据交换机的转发原则,如果交换机从一个端口上接收到的是一个广播帧,或者是一个目的MAC地址未知的单播帧,则会将这个帧向除源端口之外的所有其他端口转发。如果交换网络中有环路,则这个帧会被无限转发,此时便会形成广播风暴,网络中也会充斥着重复的数据帧。
- 本例中,SW3收到了一个广播帧将其进行泛洪,SW1和SW2也会将此帧转发到除了接收此帧的其他所有端口,结果此帧又会被再次转发给SW3,这种循环会一直持续,于是便产生了广播风暴。交换机性能会因此急速下降,并会导致业务中断。
2.2 MAC地址漂移问题
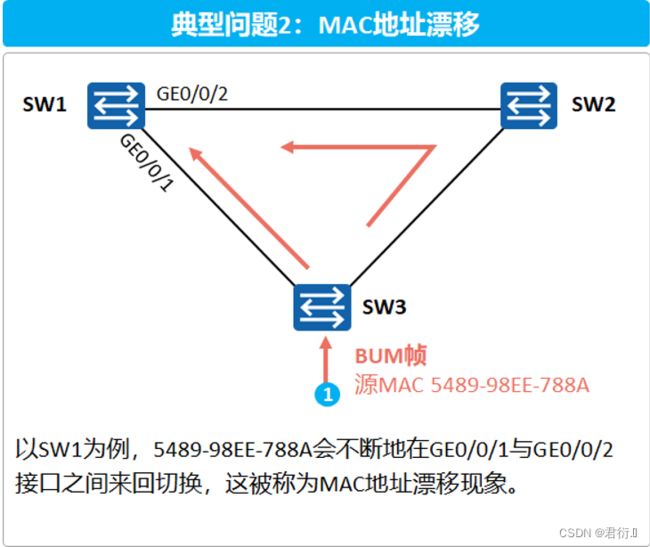
- 交换机是根据所接收到的数据帧的源地址和接收端口生成MAC地址表项的。
- 本例中,SW3收到一个广播帧泛洪,SW1从GE0/0/1接口接收到广播帧后学习且泛洪,形成MAC地址5489-98EE-788A与GE0/0/1的映射;SW2收到广播帧后学习且泛洪,SW1再次从GE0/0/2收到源 MAC地址为5489-98EE-788A的广播帧并进行学习,5489-98EE-788A会不断地在GE0/0/1与 GE0/0/2接口之间来回切换,这被称为MAC地址漂移现象。
2.3 多帧复制
— 这个好理解,同一个数据帧被重复收到多次,被称为多帧复制。
为了保证备份链路的存在,并且不会出现二层环路,所以,我们设计了STP协议。
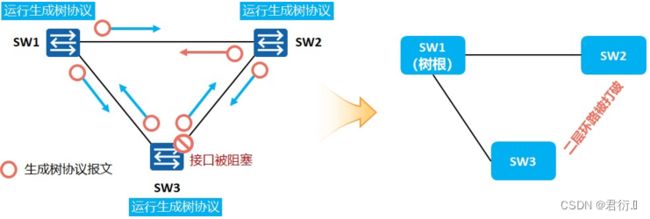
- STP通过构造一棵树来消除交换网络中的环路。
- 运行STP算法,判断网络中存在环路的地方并阻断冗余链路,将环路网络修剪成无环路的树型网络,从而避免了数据帧在环路网络中的增生和无穷循环。

- 交换机上运行的生成树协议会持续监控网络的拓扑结构,当网络拓扑结构发生变化时,生成树能感知到这些变化,并且自动做出调整。
(如图,交换机上运行STP协议,会通过报文监控网络的拓扑结构,正常情况下是将SW3上的一个接口进行阻塞(Block),从而打破环路,当监控到SW1与SW3之间出现链路故障,则恢复阻塞端口进入转发状态。) - 因此,生成树既能解决二层环路问题,也能为网络的冗余性提供一种方案。
生成树协议原理:在二层交换网络中,逻辑的阻塞部分的接口,实现从根交换机到所有节点唯一的路径且为最佳路径,生成一个没有环路的拓扑。当最佳路径出现故障时,个别被阻塞的接口将打 开,形成备份链路。