AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
- 2014 R-CNN
- 2015 Fast R-CNN、Faster R-CNN
- 2016 YOLO、SSD
- 2017 Mask R-CNN、YOLOv2
- 2018 YOLOv3
随着2019 CenterNet的发布,特别是2020发布的DETR(End-to-End Object Detection with Transformers)之后,自此CV迎来了生成式下的多模态时代(本文介绍其中有下划线的部分,其他部分下一篇介绍)
| 1月 | 3月 | 4月 | 5月 | 6月 | 8月 | 10月 | 11月 | |
| 2020 | DETR | DDPM | DDIM VisionTransformer |
|||||
| 2021 | CLIP DALL·E |
SwinTransformer | MAE SwinTransformerV2 |
|||||
| 2022 | BLIP | DALL·E 2 | StableDiffusion BEiT-3 Midjourney V3 |
|||||
| 2023 | BLIP2 | VisualChatGPT GPT4 Midjourney V5 |
SAM(Segment Anything Model) |
但看这些模型接二连三的横空出世,都不用说最后爆火的GPT4,便可知不少CV同学被卷的不行
说到GPT4,便不得不提ChatGPT,实在是太火了,改变了很多行业,使得国内外绝大部分公司的产品、服务都值得用LLM全部升级一遍(比如微软的365 Copilot、阿里所有产品、金山WPS等等)
而GPT4相比GPT3.5或GPT3最本质的改进就是增加了多模态的能力,使得ChatGPT很快就能支持图片的输入形式,从而达到图生文和文生图的效果,而AI绘画随着去年stable diffusion和Midjourney的推出,使得文生图火爆异常,各种游戏的角色设计、网上店铺的商品/页面设计都用上了AI绘画这样的工具,更有不少朋友利用AI绘画取得了不少的创收,省时省力还能赚钱,真香
但面对这么香的技术,其背后的一系列原理到底是什么呢,本文特从头开始,不只是简单的讲一下扩散模型的原理,而是在反复研读相关论文之后,准备把20年起相关的CV多模态模型全部梳理一遍,从VE、VAE、DDPM到ViT/Swin transformer、CLIP/BLIP,再到stable diffusion/Midjourney、GPT4,当然,实际写的时候,会分成两篇甚至多篇文章,比如
- 第一篇,即本文《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer》
- 第二篇,即下篇《AIGC下的CV多模态原理解析:从CLIP/BLIP到stable diffusion/Midjourney、GPT4》
就当2020年之后的CV视觉发展史了,且过程中会尽可能写透彻每一个模型的原理,举两个例子
- 网上介绍VAE的文章都太数学化(更怕那种表面正确其实关键的公式是错的误导人),如果更边推导边分析背后的理论意义(怎么来的 出发点是什么 为什么要这么做 这么做的意义是什么),则会更好理解,这就跟变介绍原理边coding实现 会更好理解、理解更深 一个道理
- 如果完全展开DDPM推导的所有细节,假定需要100步的话,本文正在朝展开80步而努力,截止5月份之前,绝大部分的中文资料只展开了60步(正在因为只展开了60%,让很多初学者卡到中途),所以你害怕的不是公式,你只是怕公式的展开不够细致,毕竟对每一个人而言,公式展开越细致 越不怕
(如果本文有任何一个公式展开的不够细致、不够一目了然,请随时指出,一定及时二次展开)
第一部分 编码器VE与变分自编码器VAE
1.1 AE:编码器(数据 压缩为低维表示
压缩为低维表示 )-解码器(低维表示恢复为原始数据
)-解码器(低维表示恢复为原始数据 )架构
)架构
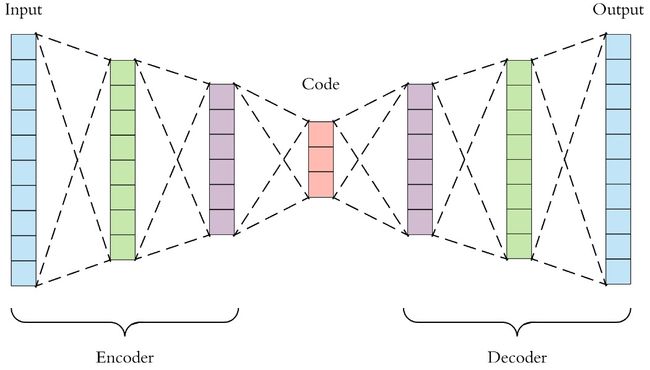
自编码器(Autoencoder,简称AE)是一种无监督学习的神经网络,用于学习输入数据的压缩表示。具体而言,可以将其分为两个部分:编码器和解码器
-
编码器:编码器是一个神经网络,负责将输入数据
(如图像、文本等)压缩为一个低维表示,且表示为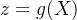
-
解码器:解码器是另一个神经网络,负责将编码器生成的低维表示恢复为原始数据
,且表示为
从而最终完成这么一个过程:![]() ,而其训练目标即是最小化输入数据与解码器重建数据之间的差异,所以自编码器常用的一个损失函数为
,而其训练目标即是最小化输入数据与解码器重建数据之间的差异,所以自编码器常用的一个损失函数为![]()
这个自编码的意义在于
- 模型训练结束后,我们就可以认为编码囊括了输入数据的大部分信息,也因此我们可以直接利用表达原始数据,从而达到数据降维的目的
- 解码器只需要输入某些低维向量,就能够输出高维的图片数据,那我们能否把解码器模型直接当做生成模型,在低维空间中随机生成某些向量,再喂给解码器
 来生成图片呢?
来生成图片呢?
对于第二点,理论上可以这么做,但问题在于
- 绝大多数随机生成的
 只会生成一些没有意义的噪声,之所以如此,原因在于没有显性的对的分布
只会生成一些没有意义的噪声,之所以如此,原因在于没有显性的对的分布 进行建模,我们并不知道哪些能够生成有用的图片
进行建模,我们并不知道哪些能够生成有用的图片 - 而且我们用来训练的数据是有限的,
 可能只会对极有限的有响应。而整个低维空间又是一个比较大的空间,如果只在这个空间上随机采样的话,我们自然不能指望总能恰好采样到能够生成有用的图片的
可能只会对极有限的有响应。而整个低维空间又是一个比较大的空间,如果只在这个空间上随机采样的话,我们自然不能指望总能恰好采样到能够生成有用的图片的
有问题自然便得探索对应的解决方案,而VAE(自变分编码器,Variational Autoencoders)则是在AE的基础上,显性的对的分布![]() 进行建模(比如符合某种常见的概率分布),使得自编码器成为一个合格的生成模型
进行建模(比如符合某种常见的概率分布),使得自编码器成为一个合格的生成模型
1.2 Variational AutoEncoder (VAE)
1.2.1 VAE:标数据的分布和目标分布尽量接近
VAE和GAN一样,都是从隐变量![]() 生成目标数据,具体而言,先用某种分布随机生成一组隐变量
生成目标数据,具体而言,先用某种分布随机生成一组隐变量![]() (假设隐变量服从正态分布),然后这个
(假设隐变量服从正态分布),然后这个![]() 隐变量经过一个生成器生成一组数据
隐变量经过一个生成器生成一组数据![]() ,具体如下图所示(本1.2节的部分图来自苏建林):
,具体如下图所示(本1.2节的部分图来自苏建林):

而VAE和GAN都希望这组生成数据的分布和目标分布尽量接近,看似美好,但有两个问题
- 一方面,“尽量接近”并没有一个确定的关于 和 的相似度的评判标准,比如KL散度便不行,原因在于KL散度是针对两个已知的概率分布求相似度的,而 和 的概率分布目前都是未知(只有一批采样数据 没有分布表达式)
- 二方面,经过采样出来的每一个
 ,不一定对应着每一个原来的
,不一定对应着每一个原来的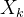 ,故最后没法直接最小化
,故最后没法直接最小化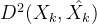
实际是怎么做的呢,事实上,与自动编码器由编码器与解码器两部分构成相似,VAE利用两个神经网络建立两个概率密度分布模型:

- 一个用于原始输入数据
 的变分推断,生成隐变量
的变分推断,生成隐变量 的变分概率分布
的变分概率分布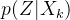 ,称为推断网络
,称为推断网络
而VAE的核心就是,我们不仅假设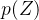 是正态分布,而且假设每个 也是正态分布。什么意思呢?即针对每个采样点获得一个专属于它和 的一个正态分布
是正态分布,而且假设每个 也是正态分布。什么意思呢?即针对每个采样点获得一个专属于它和 的一个正态分布
换言之,有 个 sample,就有个正态分布 ,毕竟没有任何两个采样点是完全一致的,而后面要训练一个生成器
个 sample,就有个正态分布 ,毕竟没有任何两个采样点是完全一致的,而后面要训练一个生成器  ,希望能够把从分布 采样出来的一个 还原为 ,而如果从 中采样一个 ,没法知道这个 对应于真实的 呢?现在 专属于,我们有理由说从这个分布采样出来的 可以还原到对应的 中去
,希望能够把从分布 采样出来的一个 还原为 ,而如果从 中采样一个 ,没法知道这个 对应于真实的 呢?现在 专属于,我们有理由说从这个分布采样出来的 可以还原到对应的 中去
而如何确定这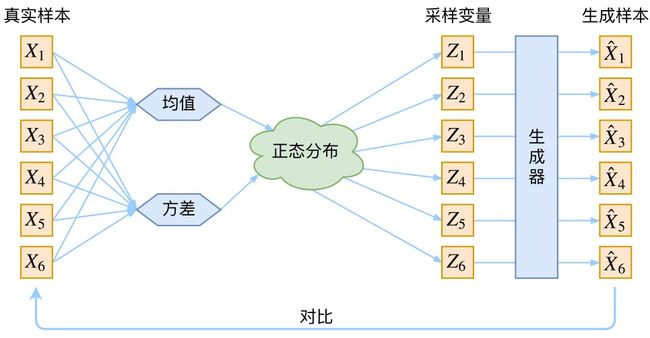 个正态分布呢,众所周知,确定一个正太分布只需确定其均值
个正态分布呢,众所周知,确定一个正太分布只需确定其均值 和方差
和方差 即可,故可通过已知的 和 假设的 去确定均值和方差
即可,故可通过已知的 和 假设的 去确定均值和方差
具体可以构建两个神经网络 ,
,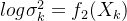 去计算。值得一提的是,选择拟合
去计算。值得一提的是,选择拟合 而不是直接拟合
而不是直接拟合 ,是因为总是非负的,需要加激活函数处理,而拟合不需要加激活函数,因为它可正可负
,是因为总是非负的,需要加激活函数处理,而拟合不需要加激活函数,因为它可正可负 - 另一个根据生成的隐变量的变分概率分布,还原生成原始数据的近似概率分布
 ,称为生成网络
,称为生成网络
因为已经学到了这 个正态分布,那可以直接从专属分布中采样一个出来,然后经过一个生成器得到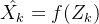 ,那接下来只需要最小化方差 就行
,那接下来只需要最小化方差 就行 
仔细理解的时候有没有发现一个问题?为什么在文章最开头,我们强调了没法直接比较 与 的分布,而在这里,我们认为可以直接比较这俩?注意,这里的 是专属于或针对于![]() 的隐变量,那么和
的隐变量,那么和 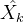 本身就有对应关系,因此右边的蓝色方框内的“生成器”,是一一对应的生成。
本身就有对应关系,因此右边的蓝色方框内的“生成器”,是一一对应的生成。
另外,大家可以看到,均值和方差的计算本质上都是encoder。也就是说,VAE其实利用了两个encoder去分别学习均值和方差
1.2.2 VAE的Variational到底是个啥
这里还有一个非常重要的问题:由于我们通过最小化![]() 来训练右边的生成器,最终模型会逐渐使得
来训练右边的生成器,最终模型会逐渐使得 ![]() 和趋于一致。但是注意,因为 是重新随机采样过的,而不是直接通过均值和方差encoder学出来的,这个生成器的输入
和趋于一致。但是注意,因为 是重新随机采样过的,而不是直接通过均值和方差encoder学出来的,这个生成器的输入 ![]() 是有噪声的
是有噪声的
- 仔细思考一下,这个噪声的大小其实就用方差来度量。为了使得分布的学习尽量接近,我们希望噪声越小越好,所以我们会尽量使得方差趋于 0
- 但是方差不能为 0,因为我们还想要给模型一些训练难度。如果方差为 0,模型永远只需要学习高斯分布的均值,这样就丢失了随机性,VAE就变成AE了……这就是为什么VAE要在AE前面加一个Variational:我们希望方差能够持续存在,从而带来噪声!
- 那如何解决这个问题呢?其实保证有方差就行,但是VAE给出了一个优雅的答案:不仅需要保证有方差,还要让所有
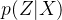 趋于标准正态分布
趋于标准正态分布 ,根据定义可知
,根据定义可知
这个式子的关键意义在于告诉我吗:如果所有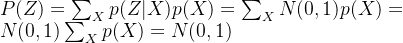 都趋于,那么我们可以保证也趋于,从而实现先验的假设,这样就形成了一个闭环!那怎么让所有趋于呢?还是老套路:加loss
都趋于,那么我们可以保证也趋于,从而实现先验的假设,这样就形成了一个闭环!那怎么让所有趋于呢?还是老套路:加loss
到此为止,我们可以把VAE进一步画成:
现在我们来回顾一下VAE到底做了啥。VAE在AE的基础上

- 一方面,对均值的encoder添加高斯噪声(正态分布的随机采样),使得decoder(即生成器)有噪声鲁棒性
- 二方面,为了防止噪声消失,将所有趋近于标准正态分布,将encoder的均值尽量降为 0,而将方差尽量保持住
这样一来,当decoder训练的不好的时候,整个体系就可以降低噪声;当decoder逐渐拟合的时候,就会增加噪声
第二部分 扩散模型DDPM:先前向加噪后反向去噪从而建立噪声估计模型
在写本文之前,我反复看了网上很多阐述DDPM的文章,实话说,一开始看到那种一上来就一堆公式的,起初基本看不下去,虽然后来 慢慢的都看得下去了,但如果对于一个初次接触DDPM的初学者来说,一上来就一堆公式确实容易把人绕晕,但如果没有公式,则又没法透彻理解背后的算法步骤
两相权衡,本文将侧重算法每一步的剖析,而公式更多为解释算法原理而服务,说白了,侧重原理 其次公式,毕竟原理透彻了,公式也就自然而然的能写出来了
言归正传,2020年,UC Berkeley等人的Jonathan Ho等人通过论文《Denoising Diffusion Probabilistic Models》正式提出DDPM(全称即论文名称:Denoising Diffusion Probabilistic Models,简称DDPM)
扩散模型的灵感来自非平衡热力学,通过定义了一个扩散步骤的马尔可夫链,以缓慢地将「符合高斯分布的随机噪声」添加到数据中,然后反转扩散过程以从噪声中构建所需的数据样本

每一个噪声都是在前一时刻增加噪声而来的,从最开始的![]() 时刻开始,最终得到
时刻开始,最终得到![]() 时刻的纯噪声图像。不过问题来是为什么要加噪声?
时刻的纯噪声图像。不过问题来是为什么要加噪声?
- Diffusion的最终目标是去噪以生成图片,而为了推导出逆向的去噪方法,必须了解增加噪声的原理。同时,添加噪声的过程其实就是不断构建标签的过程。如果在前一时刻可以预测出来后一时刻的噪声,便能很方便地实现还原操作(就和人走路一样,不管你从哪来,哪怕走过万水千山,最后都可按原路返回至原出发点)
说白了 当你学会了怎么加噪(前向扩散),就一定能知道怎么去噪(逆向生成),毕竟知道怎么来 也必知道怎么回
- 且在噪声的添加过程中,每一步都要保持尽量相同的噪声扩散幅度。比如,在给上图加噪的过程中,前期的分布非常均匀,添加一些噪声便可以将原始分布改变,但到后期,需要添加更多的噪声,方可保证噪声扩散幅度相同(这就像往水中加糖,为了使糖的甜味增长相同,后期需要加更多的糖)
所以DDPM为了从随机噪声中直接生成图片,首先需要训练一个噪声估计模型,然后将输入的随机噪声还原成图片,相当于就两个关键,一个是训练过程,一个是推理过程
- 训练过程:随机生成噪声
 ,经过
,经过 步将噪声扩散到输入原始图片
步将噪声扩散到输入原始图片 中,破坏后的图片
中,破坏后的图片 ,学习破坏图片的预估噪声
,学习破坏图片的预估噪声 ,用L2 loss约束与原始输入噪声的距离
,用L2 loss约束与原始输入噪声的距离 - 推理过程:即输入噪声,经过预估噪声模型还原成图片
2.1 DDPM的两个过程:从前向过程到逆向过程
2.1.1 前向过程(加噪):通过高斯噪音随机加噪 ——给图片打马赛克
前向过程(forward process)也称为扩散过程(diffusion process),简单理解就是对原始图片![]() 通过逐步添加「方差为
通过逐步添加「方差为![]() 的高斯噪声」变成
的高斯噪声」变成![]() ,从而达到破坏图片的目的,如下图
,从而达到破坏图片的目的,如下图

在从 到
到![]() 的过程中,其对应的分布
的过程中,其对应的分布![]() 是一个正太分布,且其均值是
是一个正太分布,且其均值是![]() ,方差为
,方差为![]() ,则有
,则有
![]()
对于这个公式,解释下3点
-
正态分布的概率密度函数具有以下形式:
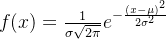
正态分布有两个参数:均值
 和方差。其中,是分布的均值,决定了分布的中心位置,
和方差。其中,是分布的均值,决定了分布的中心位置, 是标准差,决定了分布的宽度
是标准差,决定了分布的宽度 - 上面的方差之所以表示为
 ,原因在于我们一般处于多维情况下,而
,原因在于我们一般处于多维情况下,而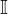 是单位矩阵,表明每个维度有相同的标准偏差
是单位矩阵,表明每个维度有相同的标准偏差
且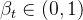 是事先给定的常量,代表从到
是事先给定的常量,代表从到 这一步的方差,且正因为设置的比较小,所以使得
这一步的方差,且正因为设置的比较小,所以使得 的均值在附近,换言之,相当于就是在的基础上加了一些噪声,而且是渐进式逐步增加/扩散的,当然 从加噪大小的角度上讲,前期加噪较弱,后期加噪加强,所以在DDPM的论文中,作者取
的均值在附近,换言之,相当于就是在的基础上加了一些噪声,而且是渐进式逐步增加/扩散的,当然 从加噪大小的角度上讲,前期加噪较弱,后期加噪加强,所以在DDPM的论文中,作者取 为从0.0001到0.02的线性递增序列
为从0.0001到0.02的线性递增序列 - 此外,值得一提的是,因为是马尔可夫链,所以其联合分布便是:
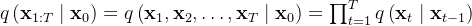
如下图所示
接下来,如果我们定义 ![]() , 且
, 且![]() 『被称为Noise schedule,通常是一些列很小的值』,以及
『被称为Noise schedule,通常是一些列很小的值』,以及 ![]() 是高斯噪声,便可以得到
是高斯噪声,便可以得到![]() 的采样值
的采样值
![]()
把上述公式迭代变换下,可以直接得出 ![]() 到
到 ![]() 的公式,如下:
的公式,如下:
![]()
其中 ![]() ,
,![]() 也是一个高斯噪声
也是一个高斯噪声
换言之,所以 ![]() 在
在 ![]() 条件下的分布就是均值为
条件下的分布就是均值为 ![]() , 方差为
, 方差为 ![]() 的正态分布
的正态分布
![]()
考虑到可能会有读者对这个
- 首先通过
可知,
,把这个代入到
- 考虑到「两个独立正态分布的随机变量之和是正态的,其均值是两个均值之和,其方差是两个方差之和(即标准差的平方是标准差的平方),比如两个方差不同的高斯分布
和
相加等于一个新的高斯分布
」,然后再通过重参数技巧可得
对此,本文参考文献中的这篇《Understanding Diffusion Models: A Unified Perspective》也解释了这几个步骤- 最后定义一个累积混合系数,
,即
,可得

2.1.2 逆向过程(去噪):求解真实后验分布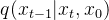 —— 复原被加噪的图片使之清晰化
—— 复原被加噪的图片使之清晰化
逆向过程就是通过估测噪声,多次迭代逐渐将被破坏的 ![]() 恢复成
恢复成 ![]() ,如下图
,如下图

更具体而言,正向扩散和逆扩散过程都是马尔可夫,唯一的区别就是正向扩散里每一个条件概率的高斯分布的均值和方差都是已经确定的(依赖于 ![]() 和
和 ![]() ),而逆扩散过程里面的均值和方差需要通过网络学出来,怎么个学法呢?
),而逆扩散过程里面的均值和方差需要通过网络学出来,怎么个学法呢?
- 有人可能要说,直接把上一节得到的
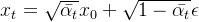 移个项不就行了(先把带的项移到等式左边,然后所有项各自除以
移个项不就行了(先把带的项移到等式左边,然后所有项各自除以 ,最后把等式右边的
,最后把等式右边的 提取到括号外边即可)?
提取到括号外边即可)?
但问题在于中的是个随机变量,意味着 也是个随机变量,其具体取值由 实际取值决定「相当于现在我们有一个具体的 ,它对应着 的某个取值,但是什么值我们并不知道」,所以我们只能以前向过程的 取值为标签,训练一个模型去估计它,即:
其中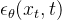 就是所谓的模型,用来近似真实的(即前向过程采样出来的);相应地,
就是所谓的模型,用来近似真实的(即前向过程采样出来的);相应地, 就是 的近似。或者,你也可以无视,直接把 视为模型
就是 的近似。或者,你也可以无视,直接把 视为模型
为了训练它,最直接的想法就是用 L2 损失 或者
或者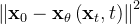

理论上没问题,但是实际效果很差,为什么呢?如果直接用
,那么中间的 都没用了,整个 DDPM 就退化成了 VAE 的结构
都没用了,整个 DDPM 就退化成了 VAE 的结构
但是 VAE 的生成模型和后验都是自己学习出来的,二者双向奔赴共同优化去寻找最优解;而 DDPM 的后验是人为指定的(即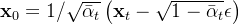 ),并且由于
),并且由于  ,
, 基本上就是一个标准正态分布,磨灭掉了几乎所有的输入信息,全靠生成模型这一边去恢复,难度未免也..
基本上就是一个标准正态分布,磨灭掉了几乎所有的输入信息,全靠生成模型这一边去恢复,难度未免也.. - 所以,实际应用中,我们是一点一点来的,比如先生成、然后
 ……由于每一步的变化都比较小,保留了上一步足够的信息,生成模型的负担就轻了很多
……由于每一步的变化都比较小,保留了上一步足够的信息,生成模型的负担就轻了很多
如果我们能够逆转前向过程并从真实分布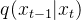 采样,就可以从高斯噪声
采样,就可以从高斯噪声  还原出原图分布
还原出原图分布  。因为我们可以证明如果前向满足高斯分布且 足够小,其逆向仍然是一个高斯分布
。因为我们可以证明如果前向满足高斯分布且 足够小,其逆向仍然是一个高斯分布 那样,我们便可以使用「参数为 θ 的U-Net+attention 结构
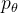 」去预测这样的一个逆向的分布(类似VAE):
」去预测这样的一个逆向的分布(类似VAE):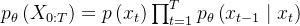
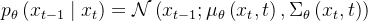
不过在DDPM的论文中,作者把条件概率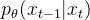 的方差直接取了,而不是上面说的需要网络去估计的
的方差直接取了,而不是上面说的需要网络去估计的  ,所以说实际上只有均值需要网络去估计
,所以说实际上只有均值需要网络去估计 -
然现在的问题是,我们无法直接去推断
所以,接下来的问题 自然而然 就转换成了我们希望求解
 ,因为我们知道前向过程
,因为我们知道前向过程 ,所以自然想到使用贝叶斯公式:
,所以自然想到使用贝叶斯公式: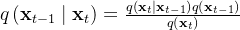
可惜
 和
和  是未知的,事情到这里似乎走入了僵局,但是我们敏锐地发现和
是未知的,事情到这里似乎走入了僵局,但是我们敏锐地发现和  是已知的,如果给上式加上 为条件,则立马柳暗花明,且如果知道
是已知的,如果给上式加上 为条件,则立马柳暗花明,且如果知道  就可以直接写出
就可以直接写出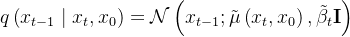
接下来,我们便好好推导下

解释下上面7.1~7.5这5个步骤的推导
7.1依据的是
- 7.2中,分母部分依据的是
分子部分依据的是- 7.3依据的是分子分母同时除以
- 至于7.3到7.4
依据的是
且由前向扩散过程的特性『别忘了2.1.2节中,有』,可知
- 最后,再解释下怎么从7.4到的7.5
先举一个最简单的例子,比如对于,稍加转化下即是
,则其均值为
,方差为
而这个则对应于7.5中的
则对应于7.5中的
从而有

好,接下来关键来了
根据![]() ,可知
,可知![]() ,代入上面
,代入上面![]() 的表达式 可得
的表达式 可得
![]()
大部分对这个的推导都是一步到位的,但本文为细致起见,故还是一步步来推导下
- 首先直接把
 和
和 代入进去,可得
代入进去,可得 - 接下来,我们可以进一步观察到 分子中的后半部分有
 这一项,怎么进一步化简呢『接下来非常关键(截止23年5月份之前,暂时没看到有其他中英文资料解释了这个细节)』?
这一项,怎么进一步化简呢『接下来非常关键(截止23年5月份之前,暂时没看到有其他中英文资料解释了这个细节)』?
好在之前有定义:,即,从而有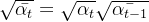
所以我们可以针对这一项
的分子分母同时除以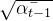 ,得到
,得到 -
之后的推导就比较简单了
以下分别对上面的三行公式做解释说明:
 接着把上阶段2得到的式子的分子拆成三项,且三项中最后两项的分子分母同时乘以
接着把上阶段2得到的式子的分子拆成三项,且三项中最后两项的分子分母同时乘以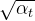 然后再把上一步骤中分子三项中的前两项通过提取出从而实现合并 前两项合并之后,再对前两项中第一项的分子分母同时乘以,然后对第三项的分子分母同时除以
然后再把上一步骤中分子三项中的前两项通过提取出从而实现合并 前两项合并之后,再对前两项中第一项的分子分母同时乘以,然后对第三项的分子分母同时除以 ,即可得
,即可得 ,原因很简单,因为:
,原因很简单,因为:
-
接下来,针对上面阶段3得到的式子的前两项再做合并,合并中用到了一个细节,即
 ,原因也同样很简单,根据上面阶段2出现的这个式子而来,再之后就更eazy 便不再赘述了
,原因也同样很简单,根据上面阶段2出现的这个式子而来,再之后就更eazy 便不再赘述了
从最终得到的结果可以看出,在给定
后验条件高斯分布的均值只和超参数
、
有关,即
方差只与超参数
有关,即
从而通过以上的方差和均值,我们就得到了
2.2 DDPM如何训练:通过噪声估计模型预测真实噪声——最小化估计噪声与真实噪声之间的差距
接下来介绍这个模型要怎么优化,即网络该怎么训练:去估计分布![]() 的条件概率
的条件概率![]() 的均值
的均值![]() 和方差
和方差![]()
与之前介绍的VAE相比,扩散模型的隐变量是和原始数据是同维度的,而且encoder(即扩散过程)是固定的

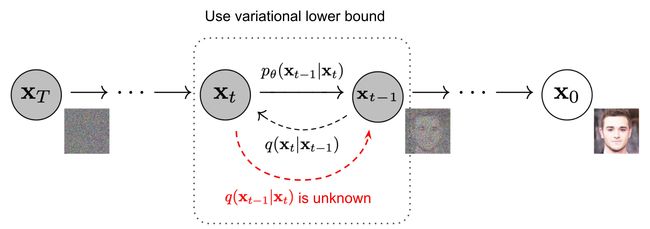
既然扩散模型是隐变量模型,那么我们可以基于变分推断来得到variational lower bound(VLB,又称ELBO)作为最大化优化目标,当然实际训练时一般对VLB取负,即我们要最小化目标分布的负对数似然:
考虑到本文的定位起见,逐一解释下上面推导的每一行
第一行:由 KL 散度的非负性质(KL 散度始终大于等于零),我们得到如下不等式:
第二行:将 KL 散度的定义代入上式可得
其中
表示期望,即对分布
中的所有可能值求期望
第三行:对上式进行简化,将
项移到期望内部
其中
表示对分布
第四行:
相互抵消可得
令
所以 ![]() 就是我们的上界,我们要最小化它,接着进行变形
就是我们的上界,我们要最小化它,接着进行变形

老规矩,上面整个推导总计九行,下面逐行解释下上面推导的每一行(纵使其他所有文章都不解释,本文也要给你解释的明明白白)
第一行,直接给出了
的定义,即计算概率分布
和
之间的对数比值的期望(注意,这是咱们的目标)
第二行,将条件概率
和联合概率
展开为一系列条件概率的乘积
考虑到,所以有
然后把上述结果分别分别代入
,即可得到第二行的结果
第三行,将乘积转换为求和,并将
项移到前面
第四行,调整求和的范围,使其从2开始,从而达到将
的项分离出来的目的
第五行,将
项的对数比值分解为两个对数比值的和,其中一个涉及
和
,另一个涉及
,相当于补了个
这里得着重解释下
把第四行的第二项的分子和分母都乘以,即得
这里面的关键是,即同时乘以
,则就变成了这个呢:
?好问题! 原因在于这两个式子是等价的,即(定义为等式1)
为何等价呢,或者说上面这个等式1是怎么来的?下面再细致解释下
对于上面等式1右边的第一项
表示的是给定
在这个等式中,分子表示
对于这个等式2右边项中的分子,可以表示为(定义为等式3):
由于在给定
现在,我们可以将上面这个等式4代入进等式2中,替换掉等式2右边项中的分子(定义为等式5)
等式5右边项的分子部分等于等式右边项的分母部分乘以等式的左边项,也就得到了我们想要的这个结论:
此外,针对这个第五行,还有另外一种推法『下面五个等式先后依据:马尔科夫假设倒推、条件概率定义、分母中联合概率定义、分子中联合概率定义、分子分母同时约掉
』
第六行,将第五行的中间项一分为二,即拆分为两个求和项
第七行,将第五行中间部分得到的两个求和项的第二个求和项的最后一项
分离出来,说白了,将第二个求和项的范围调整为从1到
,啥意思呢
首先,第五行中间部分的两个求和项可以表示为
接下来,关键的一步在于,上面中括号里的第二个求和项在求和过程中相邻两项会相互抵消。具体地,当
时的
会和当
时的
和
时的两项,即
,从而得到最终整个第7行所示的结果,如下
第八行,上一行第7行总共4项,把最后两个log项拆开成4个式子,抵消两个,还分别剩一个
、一个
,然后
合并,即可得到整个第八行的结果
第九行,将最后一项中的负号移到对数里面,并将整个表达式重写为一系列 KL 散度项的和,这些项分别为
、
和
最后得到的表达式表示了最初我们想求解的
对于上面公式最后第九行得到的结果
- 首先,
 是和优化无关的(由于前向过程 q 没有可学习参数,而 则是纯高斯噪声,因此 可以当做常量忽略),所以不用管,只用看右边的
是和优化无关的(由于前向过程 q 没有可学习参数,而 则是纯高斯噪声,因此 可以当做常量忽略),所以不用管,只用看右边的 - 然后, 是KL散度,则可以看做拉近估计分布
 和真实后验分布 这两个分布之间的距离:
和真实后验分布 这两个分布之间的距离:
对于真实后验分布 ,我们已经在上一节2.1.2节推导出其解析形式,这是一个高斯分布,其均值和方差为

对于估计分布,其是我们网络期望拟合的目标分布,也是一个高斯分布,均值用网络估计,方差被设置为了一个和  有关的常数
有关的常数
- 考虑到,如果有两个分布 p,q 都是高斯分布,则他们的KL散度为

然后因为这两个分布的方差全是常数,和优化无关『说白了,去掉相关的项,只留下 』,所以其实优化目标就是两个分布均值的二范数,从而可得
』,所以其实优化目标就是两个分布均值的二范数,从而可得
怎么来的?我再细致解释下,对于这个公式而言![L_{t} =\mathbb{E}_{q}\left[\left\|\tilde{\boldsymbol{\mu}}_{t}\left(\mathbf{x}_{t}, \mathbf{x}_{0}\right)-\boldsymbol{\mu}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}\right]](http://img.e-com-net.com/image/info8/ec31077a4f5641ed9e2042e425bf2fed.png)
这里的
 是在分布 下的期望,当我们
是在分布 下的期望,当我们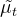 的表达式代入后,得到:
的表达式代入后,得到:![L_{t}=\mathbb{E}_{q}\left[\left\|\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \epsilon\right)-\boldsymbol{\mu}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}\right]](http://img.e-com-net.com/image/info8/05a1c9f908794651908f0ff81478eb60.png)
在这个式子中,
是一个服从标准正态分布的随机变量,而则取决于和。因此,这个期望实际上是在 和 的联合分布下的期望(在 和 的所有可能值上取平均),于是我们得到: 代表就是在 和 的联合分布下的期望, 依然是从标准正态分布中采样的噪声
代表就是在 和 的联合分布下的期望, 依然是从标准正态分布中采样的噪声 - 这个时候我们可以直接整个网络出来直接学习
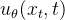 ,然后再去预测
,然后再去预测
因为是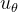 的输入,其它的量都是常数,所以其中的未知量其实只有,所以我们干脆把需要学习的定义成:
的输入,其它的量都是常数,所以其中的未知量其实只有,所以我们干脆把需要学习的定义成:
也就是说,不用网络预测 ,而是用网络先预测噪声,然后把预测出来的噪声带入到定义好的表达式中去计算出预测的均值即可
,而是用网络先预测噪声,然后把预测出来的噪声带入到定义好的表达式中去计算出预测的均值即可 - 所以,最终把这个公式,代入到步骤3得到的公式中,可得:

经过这样一番推导之后就是个 L2 loss,网络的输入是一张和噪声线性组合的图片,然后要估计出来这个噪声:
由上可知,DDPM的关键是训练 ![]() 模型,使其预测的
模型,使其预测的  与真实用于破坏的 相近,用L2距离刻画相近程度就好,因此我们的Loss就是如下公式『相当于训练时,网络输入为
与真实用于破坏的 相近,用L2距离刻画相近程度就好,因此我们的Loss就是如下公式『相当于训练时,网络输入为 ![]() (由
(由 ![]() 和噪声 线性组合而成) 和时刻 ,输出要尽可能的拟合输入的噪声 (通过L2 loss约束)』
和噪声 线性组合而成) 和时刻 ,输出要尽可能的拟合输入的噪声 (通过L2 loss约束)』

而整个训练过程可如下图描述
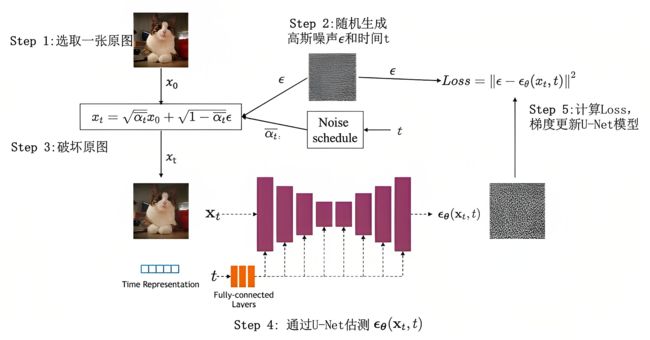
DDPM论文中对应的伪代码为

2.3 如何通过训练好的DDPM生成图片
通过上文2.1节的最后,我们得知
从最终得到的结果可以看出,在给定
后验条件高斯分布的均值只和超参数
方差只与超参数
从而通过以上的方差和均值,我们就得到了
通过2.2节的最后,我们估计到了噪声估测模型 ![]() ,接下来要生成模型就很简单了。从N(0,1)中随机生成一个噪声作为
,接下来要生成模型就很简单了。从N(0,1)中随机生成一个噪声作为![]() ,然后再用该模型逐步从估测噪声,并用去噪公式逐渐恢复到
,然后再用该模型逐步从估测噪声,并用去噪公式逐渐恢复到 ![]() 即可,见如下伪代码
即可,见如下伪代码

相当于推理时,我们从各项独立的高斯分布![]() 开始,一共 步,每一步其实都是用了一次reparameterization trick
开始,一共 步,每一步其实都是用了一次reparameterization trick
每一步具体来说,我们有了 ![]() , 想要得到 ,因为我们之前逆扩散过程建模有:
, 想要得到 ,因为我们之前逆扩散过程建模有:
![]()
![]()
所以由reparameterization trick我们有:

每一轮都这样迭代,最终就得到了生成的图片
第三部分 DETR:首次通过结合CNN+Transformer端对端解决object detection
注,本小节的内容主要参考科技猛兽此文的相关部分
一般目标检测的任务是预测一系列的Bounding Box的坐标以及Label,而大多数检测器的具体做法是
- 要么基于proposal,比如RCNN系列的工作,类似Faster R-CNN、Mask R-CNN
- 要么基于anchor,比如YOLO
把问题构建成为一个分类和回归问题来间接地完成这个任务,但最后都会生成很多个预测框(确定框的坐标及框内是什么物体),从而不可避免的出现很多冗余的框,而要去除这些冗余的框,则都需要做一个NMS(non-maximum suppersion,非极大值抑制)的后处理(使得最后调参不易、部署不易),所以如果要是有一个端对端的模型,不需要做NMS之类的后处理 也不需要太多先验知识则该有多好
而通过论文《End-to-End Object Detection with Transformers》提出的DETR则满足了大家这个期待,其取代了现在的模型需要手工设计的工作,效果不错且可扩展性强(在DETR上加个专用的分割头便可以做全景分割),其解决的方法是把检测问题看做是一个集合预测的问题(即set prediction problem,说白了,各种预测框本质就是一个集合),其基本流程如下图所示

- CNN抽特征且拉直
- 全局建模,给到transformer-encoder去进一步学习全局信息
通过借助Transformer中的的self-attention机制,可以显式地对一个序列中的所有elements两两之间的interactions进行建模或交互,如此就知道了图片中哪块是哪个物体,从而对于同一个物体只需出一个预测框即可 - 接着通过不带掩码机制的transformer-decoder生成很多预测框
注意是并行预测(即并行出框,而不是像原始transformer预测下一个token时一个一个往外蹦)
相当于一次性生成 个box prediction,其中 是一个事先设定的远远大于image中object个数的一个整数(比如100)
个box prediction,其中 是一个事先设定的远远大于image中object个数的一个整数(比如100) - 预测框和真实框做二分图匹配
最后通过bipartite matching loss的方法,基于预测的100个boxex和ground truth boxes的二分图做匹配,计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth
当然,这第4步更多是做模型训练的时候用,如果模型训练好了去做推理时,该第4步就不需要了,可以直接在预测的100个框中设定个阈值,比如置信度大于0.7的预测框保留下来,其他视为背景物体而 舍弃
3.1 DETR整体结构:backbone,encoder,decoder和FFN
3.1.1 DETR结构之前两部分:backbone与encoder
更细致的讲,DETR整体结构可以分为四个部分:backbone,encoder,decoder和FFN,如下图所示
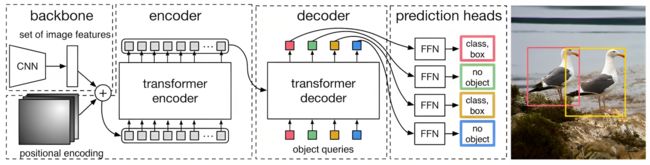
对于前两部分而言
一开始的backbone面对的是 ![]() 维的图像,首先把它转换为
维的图像,首先把它转换为![]() 维的feature map(一般来说,通道数
维的feature map(一般来说,通道数![]() 或256,
或256, ,
,![]() )
)
然后由于encoder的输入是![]() 维的feature map,故正式输入encoder之前还需要依次进行以下过程(图源:科技猛兽):
维的feature map,故正式输入encoder之前还需要依次进行以下过程(图源:科技猛兽):

- 通道数压缩(其实就是降维操作):用 1×1 convolution处理将通道数channels数量从
 压缩到
压缩到 ,即得到
,即得到 维的新feature map
维的新feature map - 转化为序列化数据:将空间的维度(高
 和宽
和宽 )压缩为一个维度
)压缩为一个维度 ,即把上一步得到的(
,即把上一步得到的( )维的feature map通过reshape成(
)维的feature map通过reshape成( )维的feature map
)维的feature map
这步相当于把编码矩阵的维度是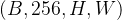 ,序列化成维度为
,序列化成维度为  维的张量
维的张量 - 位置编码:在上一步得到了维的feature map之后,再对 维的feature map做positional encoding,最后也做下reshape:高和宽压缩为一个维度,使得其与上面input embedding维度是一致的
3.1.2 详解DETR的位置编码
对于上节第三步的位置编码,再好好解释说明下
首先,通过此文《类ChatGPT逐行代码解读(1/2):从零实现Transformer、ChatGLM-6B》的1.1.2节可知,原始transformer中的Positional Encoding的表达式为:
![]()
![]()
其中, 就是这个 ![]() 维的feature map的第一维,
维的feature map的第一维,![]() 表示token在sequence中的位置,sequence的长度是
表示token在sequence中的位置,sequence的长度是![]() ,例如第一个token 的
,例如第一个token 的  ,第二个token的
,第二个token的![]()
 ,或者准确意义上是
,或者准确意义上是![]() 和
和![]() 表示了Positional Encoding的维度, 的取值范围是:
表示了Positional Encoding的维度, 的取值范围是:![]() ,所以当
,所以当 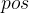 为1时,对应的Positional Encoding可以写成(注意到
为1时,对应的Positional Encoding可以写成(注意到![]() ):
):
其次,DETR与原版transformer中的位置编码有两点不同
- 第一点不同的是,原版Transformer只考虑
 方向的位置编码,但是DETR考虑了
方向的位置编码,但是DETR考虑了  方向的位置编码,因为图像特征是2-D特征。采用的依然是 sin cos 模式,但是需要考虑 两个方向。不是类似vision transoformer做法简单的将其拉伸为
方向的位置编码,因为图像特征是2-D特征。采用的依然是 sin cos 模式,但是需要考虑 两个方向。不是类似vision transoformer做法简单的将其拉伸为  ,然后从
,然后从 ![[1,HW]](http://img.e-com-net.com/image/info8/511fc886e9cb45e79af09ca0d379c391.png) 进行长度为256的位置编码,而是考虑了 方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特点
进行长度为256的位置编码,而是考虑了 方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特点
Positional Encoding的输出张量是: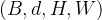 , ,其中 代表位置编码的长度,
, ,其中 代表位置编码的长度,  代表张量的位置。意思是说,这个特征图上的任意一个点
代表张量的位置。意思是说,这个特征图上的任意一个点  有个位置编码,这个编码的长度是256,其中,前128维代表
有个位置编码,这个编码的长度是256,其中,前128维代表 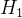 的位置编码,后128维代表
的位置编码,后128维代表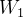 的位置编码
的位置编码
假设你想计算任意一个位置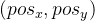 ,
,![pos_x \in[1,HW]](http://img.e-com-net.com/image/info8/541ba0f6f82b4773974f438c42f0d2af.png) ,
,![pos_y \in[1,HW]](http://img.e-com-net.com/image/info8/e9fbcdf67cdd467e8ae40825a62ba111.png) 的Positional Encoding 先把
的Positional Encoding 先把 代入上面4个公式中的
代入上面4个公式中的 式和
式和  式可以计算得到128维的向量,它代表 的位置编码 再把
式可以计算得到128维的向量,它代表 的位置编码 再把  代入上面4个公式中的
代入上面4个公式中的  式和 式可以计算得到128维的向量,它代表 的位置编码 把这2个128维的向量拼接起来,就得到了一个256维的向量,它代表的位置编码
式和 式可以计算得到128维的向量,它代表 的位置编码 把这2个128维的向量拼接起来,就得到了一个256维的向量,它代表的位置编码
从而计算所有位置的编码,就得到了 的张量,代表这个batch的位置编码
的张量,代表这个batch的位置编码 - 第二点不同的是,原版Transformer只在Encoder之前使用了Positional Encoding,而且是在输入上进行Positional Encoding,再把输入经过transformation matrix变为Query,Key和Value这几个张量
但是DETR在Encoder的每一个Multi-head Self-attention之前都使用了Positional Encoding,且只对Query和Key使用了Positional Encoding,即:只把维度为维的位置编码与维度为维的Query和Key相加,而不与Value相加
下图为DETR的Transformer的详细结构,读者可以对比下原版Transformer的结构 可以发现,除了Positional Encoding设置的不一样外,Encoder其他的结构是一致的。每个Encoder Layer包含一个multi-head self-attention 的module和一个前馈网络Feed Forward Network

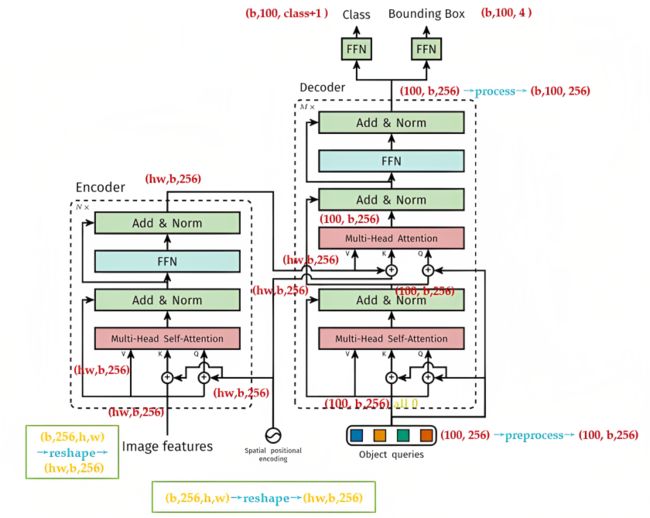
所以,了解了DETR的位置编码之后,你应该明白了其实input embedding和位置编码维度其实是一样的,从而也就可以直接相加,使得Encoder最终输出的是 维的编码矩阵Embedding,按照原版Transformer的做法,把这个东西给Decoder
维的编码矩阵Embedding,按照原版Transformer的做法,把这个东西给Decoder
3.1.3 DETR结构的后两部分:decoder和FFN
通过上节最后的对比图,可知DETR的Decoder和原版Transformer的decoder也是不太一样的
- 对于原版Transformer,其decoder的最后一个框(上节最后对比图的左图右上角所示):output probability,代表我们一次只产生一个单词的softmax,根据这个softmax得到这个单词的预测结果,即:predicts the output sequence one element at a time
- 不同的是,DETR的Transformer Decoder是一次性处理全部的object queries(上节最后对比图的右图右上角所示),即一次性输出全部的predictions(而不像原始的Transformer是auto-regressive的,从左到右一个词一个词地输出),即:decodes the N objects in parallel at each decoder layer
至于DETR的Decoder主要有两个输入:
- 第一个输入是Transformer Encoder输出的Embedding与 position encoding(在下图右侧第二个multi-head self-attention处)相加之后 给到
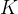
其中的Embedding就是上文提到的的编码矩阵 - 第二个输入是Object queries
所谓Object queries是一个维度为 维的张量,数值类型是nn.Embedding(意味着是可以学习的)。Object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出
维的张量,数值类型是nn.Embedding(意味着是可以学习的)。Object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出
关于上图右侧第1个multi-head self-attention的Q K V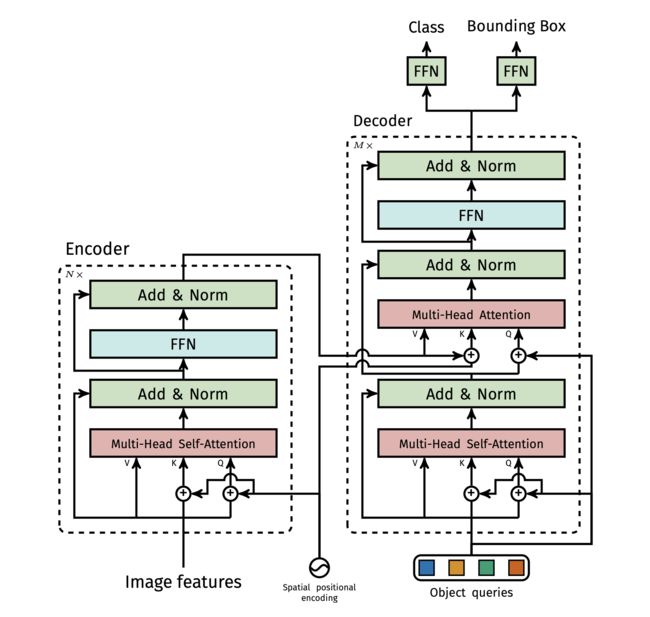
如上图所示,它的Q K是这么来的:Decoder原本的输入一开始初始化成维度为维的全部元素都为0的张量,然后和Object queries加在一起之后充当第1个multi-head self-attention的Query和Key,至于Value则是Decoder原本的输入,也就是全0的张量
关于上图右侧第2个multi-head self-attention的Q K V
它的Key和Value来自Encoder的输出张量,维度为 ,其中Key值还进行位置编码(正如上面第一个输入所述)
,其中Key值还进行位置编码(正如上面第一个输入所述)
至于其Query值一部分来自第1个Add and Norm的输出,维度为的张量,另一部分来自Object queries,充当可学习的位置编码
所以,第2个multi-head self-attention的Key和Value的维度为,而Query的维度为
每个Decoder的输出维度为![]() ,送入后面的前馈网络
,送入后面的前馈网络
到这里你会发现:Object queries充当的其实是位置编码的作用,只不过它是可以学习的位置编码,所以,我们对Encoder和Decoder的每个self-attention的Query和Key的位置编码做个归纳,如下图所示,Value没有位置编码

3.1.4 损失函数部分解读
得到了Decoder的输出以后,如前文所述,应该是输出维度为![]() 的张量。接下来要送入2个前馈网络FFN得到class和Bounding Box(如再度引用的下图所示),它们会得到
的张量。接下来要送入2个前馈网络FFN得到class和Bounding Box(如再度引用的下图所示),它们会得到 ![]() 个预测目标 包含类别和Bounding Box(当然这个100肯定是大于图中的目标总数的,如果不够100,则采用背景填充
个预测目标 包含类别和Bounding Box(当然这个100肯定是大于图中的目标总数的,如果不够100,则采用背景填充
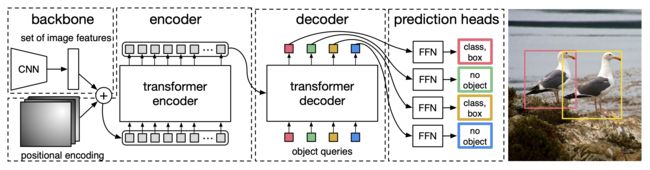
所以,DETR输出张量的维度为![]() ,和
,和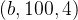 『对应COCO数据集来说:
『对应COCO数据集来说:![]() , 4 指的是每个预测目标归一化的
, 4 指的是每个预测目标归一化的 ,归一化就是除以图片宽高进行归一化』,对于这两个维度
,归一化就是除以图片宽高进行归一化』,对于这两个维度
- 前者代表分类分支,指100个预测框的类型
- 后者代表回归分支,指100个预测框的Bounding Box(仅仅计算有物体位置,背景集合忽略)
但是读者可能会有疑问:预测框和真值是怎么一一对应的?换句话说:你怎么知道第47个预测框对应图片里的狗,第88个预测框对应图片里的车?..
- 这就需要用到经典的双边匹配算法了,也就是常说的匈牙利算法,该算法广泛应用于最优分配问题
一幅图片,我们把第 个物体的真值表达为  ,其中,
,其中, 表示它的 class ,
表示它的 class ,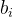 表示它的 Bounding Box
表示它的 Bounding Box
然后定义 为网络输出的 个预测值
为网络输出的 个预测值
对于第 个真值 ,
,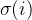 为匈牙利算法得到的与真值
为匈牙利算法得到的与真值 对应的预测值prediction的索引,举个例子,比如
对应的预测值prediction的索引,举个例子,比如 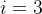 ,
, ,意思就是:与第3个真值对应的预测值是第18个
,意思就是:与第3个真值对应的预测值是第18个 - 那如何根据匈牙利算法找到与每个真值对应的预测值到底是哪个呢?
对于某一个真值
 ,假设已经找到这个真值对应的预测值
,假设已经找到这个真值对应的预测值 ,这里的
,这里的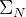 是所有可能的排列(代表从真值索引到预测值索引的所有的映射),然后用
是所有可能的排列(代表从真值索引到预测值索引的所有的映射),然后用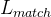 最小化和的距离
最小化和的距离 - 这个具体是:
意思是:假设当前从真值索引到预测值索引的所有映射为 ,对于图片中的每个真值 先找到对应的预测值,再看看分类网络的结果
,对于图片中的每个真值 先找到对应的预测值,再看看分类网络的结果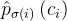 ,取反作为 的第1部分 再计算回归网络的结果
,取反作为 的第1部分 再计算回归网络的结果 与真值的 Bounding Box 的差异,即
与真值的 Bounding Box 的差异,即  ,作为的第2部分
,作为的第2部分
所以,可以使得最小的排列  就是我们要找的排列,即:对于图片中的每个真值来讲,
就是我们要找的排列,即:对于图片中的每个真值来讲,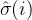 就是这个真值所对应的预测值的索引
就是这个真值所对应的预测值的索引
上述这个匈牙利算法的过程与Anchor或Proposal有异曲同工的地方,只是此时我们找的是一对一匹配 - 接下来就是使用上一步得到的排列,计算匈牙利损失
式中的 具体为:
具体为:
最常用的
 loss对于大小 Bounding Box 会有不同的标度,即使它们的相对误差是相似的。为了缓解这个问题,作者使用了 loss和广义IoU损耗
loss对于大小 Bounding Box 会有不同的标度,即使它们的相对误差是相似的。为了缓解这个问题,作者使用了 loss和广义IoU损耗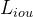 的线性组合,它是比例不变的
的线性组合,它是比例不变的
Hungarian意思就是匈牙利,也就是前面的,上述意思是需要计算 个 GTBounding Box 和个输预测出集合两两之间的广义距离,距离越近表示越可能是最优匹配关系,也就是两者最密切,广义距离的计算考虑了分类分支和回归分支
个 GTBounding Box 和个输预测出集合两两之间的广义距离,距离越近表示越可能是最优匹配关系,也就是两者最密切,广义距离的计算考虑了分类分支和回归分支
第四部分 从ViT到MAE
4.1 Vision Transformer:用标准的Transformer直接干CV任务
继DETR、DDPM之后,此篇论文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》提出的ViT彻底引燃了多模态的火热,更是直接挑战了此前CNN在视觉领域长达近10年的绝对统治地位
这个工作是怎么一步步出来的呢?自从Google在2017年发布的transformer在NLP领域大杀四方的时候,就一直不断有人想把如此强大且充满魔力的transformer用到CV领域中,但前路曲折啊
- 一开始面对的问题就是,当把transformer中对NLP的各个token之间两两互相做相似度计算的self-attention引入到图片各个像素点之间两两做self-attention时,你会发现计算复杂度瞬间爆炸(transformer 的计算复杂度是序列长度 n 的 平方
 )
)
原因很简单,一句话才多少个token(顶多几百而已),但一张图片呢?比如一张像素比较低的 分辨率的图片,就已经达到了 50176 个像素点,再考虑到RGB三个维度,直接就是15万起步,你品..
分辨率的图片,就已经达到了 50176 个像素点,再考虑到RGB三个维度,直接就是15万起步,你品.. - 兴高采烈之下理想遇挫,才发现没那么简单,咋办呢,那就降低序列长度呗。比如要么像CVPR Wang et al. 2018的工作把网络中间的特征图当做transformer的输入,毕竟ResNet 50 最后一个 stage, res4 的 feature map也就
 的大小,要么借鉴CNN的卷积机制用一个局部窗口去抓图片的特征,从而降低图片的复杂度,但这一系列工作虽然逻辑上通畅,但因为硬件上无法加速等,导致模型没法太大
的大小,要么借鉴CNN的卷积机制用一个局部窗口去抓图片的特征,从而降低图片的复杂度,但这一系列工作虽然逻辑上通畅,但因为硬件上无法加速等,导致模型没法太大 - 总之,之前的工作要么把CNN和self-attention结合起来,要么把self-attention取代CNN,但都没取得很好的扩展效果,看来得再次冲击transformer for CV (为何如此执着?还不是因为理想实在过于美丽,要不然人到中年 每每听到beyond的“原谅我这一生不羁放纵爱自由”便如此共鸣强烈),但还是得回头开头的老大难问题:如何处理图片的复杂度,于此,Vision Transformer(ViT)来了:不再一个一个像素点的处理,而是把整个图片切分成一个个图片块(比如分割为九宫格),这些图片块作为transformer的输入
下面,我们来仔细探究下ViT到底是怎么做的
4.1.1 ViT的架构:Embedding层 + Transformer Encoder + MLP Head
简单而言,Vision Transformer(ViT)的模型框架由三个模块组成:

- Embedding层(线性投射层Linear Projection of Flattened Patches)
以ViT_base_patch16为例,一张224 x 224的图片先分割成 16 x 16 的 patch ,很显然会因此而存在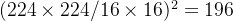 个 patch(这个patch数如果泛化到一般情况就是图片长宽除以patch的长宽,即
个 patch(这个patch数如果泛化到一般情况就是图片长宽除以patch的长宽,即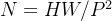 ),且图片的长宽由原来的224变成:224/16 = 14
),且图片的长宽由原来的224变成:224/16 = 14
你可能还没意识到这个操作的价值,这相当于把图片需要处理的像素单元从5万多直接降到了196个像素块,如果一个像素块当做一个token,那针对196个像素块/token去做self-attention不就轻松多了么(顺带提一句,其实在ViT之前,已经有人做了类似的工作,比如ICLR 2020的一篇paper便是针对CIFAR-10中16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 16*16 ...  的图片抽
的图片抽 的像素块)
的像素块)
而对于图片而言,还得考虑RGB channel这个因素,故每个 patch 的 维度便是 [16, 16, 3],但标准Transformer的输入是一个一维的token序列,所以需要把这个三维的维度通过线性映射linear projection成一维的维度,从而使得每个 patch 最终的输出维度是:
这样图片就由原来的 [224, 224, 3] 变成了 [14, 14, 768],相当于之前图片横竖都是224个像素点的,现在横竖只是14个像素点了,而每个像素点的维度(相当于每个token的序列长度)为768
之后经过 Flatten 就得到![[196, 768]](http://img.e-com-net.com/image/info8/f68d57e417764de9bff4baed5b7598b3.png) ,接着再经过一个维度为
,接着再经过一个维度为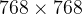 的Linear projection (本质上就是一个全连接层,用大写 表示,这个768的维度即embedding_dim可以变,简写为
的Linear projection (本质上就是一个全连接层,用大写 表示,这个768的维度即embedding_dim可以变,简写为 ,比如原始的transformer设置的维度为512),故最终的维度还是为
,比如原始的transformer设置的维度为512),故最终的维度还是为
至于在代码实现中,可通过一个卷积层来实现,卷积核大小为16,步长为16,输入维度是3,通过对整个图片进行卷积操作:[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768]
接下来,为了做最后的分类,故在所有tokens的前面加一个可以通过学习得到的 [class] token作为这些patchs的全局输出,相当于BERT中的分类字符CLS (这里的加是concat拼接),得益于self-attention机制,所有token两两之间都会做交互,故这个[class] token也会有与其他所有token交互的信息Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
且为了保持维度一致,[class] token的维度为 [1, 768] ,通过Concat操作,[196, 768] 与 [1, 768] 拼接得到 [197, 768]
由于self-attention本身没有考虑输入的位置信息,无法对序列建模。而图片切成的patches也是有顺序的,打乱之后就不是原来的图片了,故随后和transformer一样,就是对于这些 token 添加位置信息,也就是 position embedding,VIT的做法是在每个token前面加上位置向量position embedding(这里的加是直接向量相加即sum,不是concat),这里和 transformer 一致,都是可训练的参数,因为要加到所有 token 上,所以维度也是 [197, 768] - Transformer Encoder
维度为[197, 768]的embedded patches进来后,先做一次Layer Norm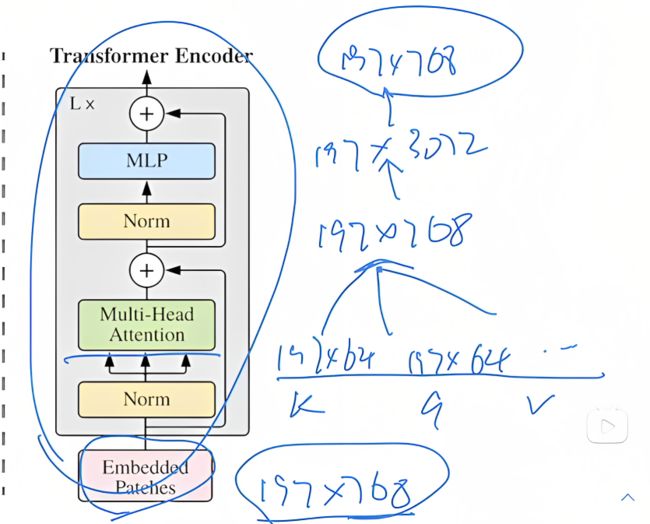
然后再做Multi-head Attention,通过乘以三个不同的Q K V矩阵得到三个不同的Q K V向量,且ViT_base_patch16设计的是12个头,故每个头的维度为:[197, 768/12] = [197, 64],最后把12个头拼接起来,会再次得到[197, 768]的维度
接着再做Norm
最后是MLP,维度上先放大4倍到[197, 3072],之后又缩小回去恢复到[197, 768]的维度 - MLP Head(最终用于分类的层结构)
MLP里面,是用tanh作为一个非线性的激活函数,去根据[class] token做分类的预测
再通过小绿豆根据ViT的源码画的这个图总结一下
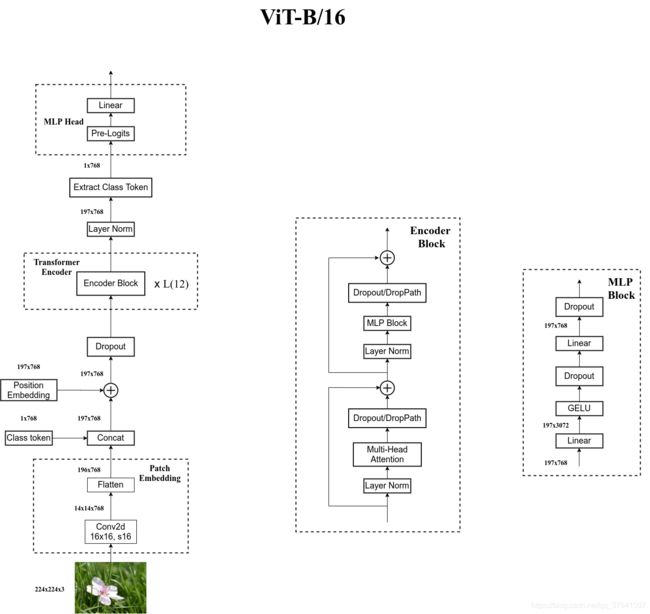
此外,上述这三个阶段的过程最终可以用如下4个公式表达
对于公式(1),
表示图片patch,总共
则表示patch embedding,
表示class embedding,因为需要用它做最后的输出/分类
对于公式(2),则表示多头注意力的结果(
先Norm再multi-head attention,得到的结果再与
对于公式(3),表示最终整个transformer decoder的输出(

4.1.2 ViT与CNN在先验知识上的对比
值得一提的是,由于ViT不像CNN那样对图像有比较多的先验知识,即没有用太多的归纳偏置
- 具体来说,CNN的局部性locality (以滑动窗口的形式一点一点在图片上进行卷积,故会假设图片上相邻的区域会有近似的特征),和平移等变性translation equivariance「无论先做平移还是先做卷积,最后的 结果都是一样的,类似
 ,毕竟卷积核就像一个模板一样,输入一致的情况下,不论图片移动到哪里,最后的输出都是一样的」贯穿整个CNN模型的始终
,毕竟卷积核就像一个模板一样,输入一致的情况下,不论图片移动到哪里,最后的输出都是一样的」贯穿整个CNN模型的始终 - 而对于ViT而言,也就在最后的MLP用到了局部且平移等变性,以及针对每个图片的patch加了位置编码,除这两点之外,ViT没有再专门针对CV问题做任何额外的处理,说白了,就是干:直接拿transformer干CV
所以在中小型的数据集上训练的结果不如CNN也是可以理解的。既如此,transformer的全局建模能力比较强,而CNN又不用那么多的训练数据,那是否可以把这个模型的优势给结合起来呢?比如做一个混合网络,前头是CNN,后头是transformer呢,答案是:也是可以的! 但这是不是就类似上文介绍过的DETR呢?读者可以继续深入思考下。
4.2 MAE

// 待更
第五部分 Swin Transformer
5.1 Swin Transformer:多尺度的ViT
swin transformer作为多尺度的ViT更加适合处理视觉问题,且证明transformer不但能在ViT所证明的分类任务上取得很好的效果,在检测、分割上也能取得很好的效果,而在结构上,swin transformer主要做了以下两点改进

- 获取图像多尺寸的特征
对于ViT而言,经过12层每一层的transformer都是16✖️16的patch块(相当于16倍下采样率),虽然通过transformer全局的自注意力操作可以达到全局的建模能力,但它对多尺寸特征的把握则相对弱些,而这个多尺寸的特征有多重要呢,比如对于目标检测而言,用的比较广的一个方法叫FPN,这个方法用的一个分层式的CNN,而每一个卷积层因为不同的感受野则会获取到不同尺寸的特征
而swin transformer就是为解决ViT只有单一尺寸的特征而来的 - 降低序列长度是图像处理中一个很关键的问题,虽然ViT把整张图片打成了16✖️16的patch,但但图像比较大的时候,计算的复杂度还是比较高
而Swin Transformer使用窗口Window的形式将16✖️16的特征图划分成了多个不相交的区域(比如16个4✖️4的,4个8✖️8的),并且只在每个小窗口(4✖️4或8✖️8)内进行多头注意力计算,大大减少计算量
之所以能这样操作的依据在于借鉴了CNN中locality先验知识(CNN是以滑动窗口的形式一点一点地在图片上进行卷积,原因在于图片上相邻的区域会有相邻的特征),即同一个物体的不同部位在一个小窗口的范围内是临近着的,从而在小窗口内算自注意力够用
且swin transformer使用patch merging,可以把相邻的四个小的patch合成一个大的patch(即patch merging),提高了感受野,这样就能获取多尺度的特征(类似CNN中的池化效果),这些特征通过FPN结构就可以做检测,通过UNet结构就可以做分割了
5.1.1 如何让4个互相独立不重叠的窗口彼此交互做自注意力操作:经过一系列shift操作
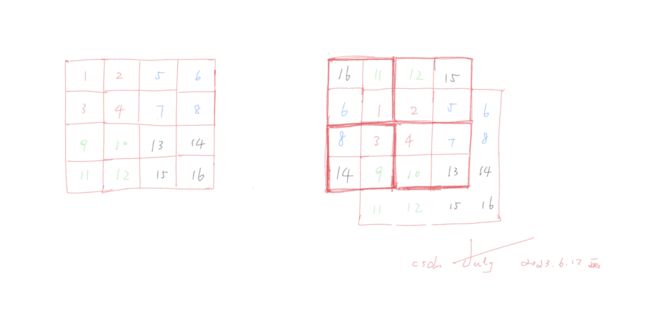
接下来,我们看下swin transformer中移动窗口的设计,图中灰色的小patch就是4✖️4的大小,然后最左侧的4个红色小窗口中均默认有7✖️7=49个小patch(当然,示意图中只展示了16个小patch),如果做接下来几个操作

- 把最左侧的整个大窗口layer 1向右下角整体移动两个小patch,并把移动之后的大窗口的最右侧的宽为2个小patch、高为6个小patch的部分平移到大窗口之外的左侧
- 且同时把移动之后的大窗口最底部宽为8个小patch、高为2个小patch部分的左侧部分(宽为6个小patch 高为2个小patch)整体平移到大窗口之外的最上方,最后遗留下来的右下角小patch移动到大窗口之外的最左上角

则成为图中右侧所示的大窗口layer 1+1,从而使得之前互相独立不重叠的4个小窗口在经过这一系列shift操作之后,彼此之间可以进行互动做自注意力的计算了
貌似还是有点抽象是不?没事,我画个图 就一目了然了,如下所示,在右侧加粗的4个新的小窗口内部,每个小窗口都有其他小窗口的信息了(每个小窗口都由之前的单一颜色的patch组成,变成了由4种不同的颜色patch组成,相当于具备了全局的注意力,够直观吧?!)
5.1.2 Swin Transformer模型总览图
以下是整个swin transformer模型的总览图

从左至右走一遍整个过程则是
- stage 1
patch partition
对于一张原始图片224✖️224✖️3,打成4✖️4的patch(则每个patch的维度是4✖️4✖️3 = 48,其中3是图片的RGB通道),从而会存在 个patch,相当于整个图片由[224,224,3]的维度变成了[56,56,48]的维度
个patch,相当于整个图片由[224,224,3]的维度变成了[56,56,48]的维度 - linear embedding
为了变成transformer能接受的值,[56,56,48]的维度变成[56,56,96],最前面的两个维度拉直之后,则维度变成了[3136,96],很明显在ViT里在这一步对应的维度是[196,768],故这个3136的维度太大了,咋办呢? - swin transformer block:基于7✖️7个小patch的小窗口计算自注意力
好在swin transformer引入了基于窗口的自注意力机制,而每个窗口默认只有七七四十九个patch,所以序列长度就只有49了,也就解决了计算复杂度的问题 - stage 2
patch mergeing(很像lower level任务中很常用的一个上采样方式:pixel shuffle)
patch mergeing的作用在于把临近的小patch合并成一个大patch,比如针对下图中维度为[H,W,C]的张量
由于下采样两倍,所以选点的时候,是每隔一个点选一个,最终整个大张量变成了4个小张量(每隔张量大小为[H/2,W/2])
之后把这4个张量的在C的维度上拼接起来,拼接之后的张量的维度则就变成了[H/2,W/2,4C]
接着,在C这个维度上通过一个1✖️1的卷积操作把张量的维度降了下来(这个1✖️1的卷积操作类似于linear的作用),最终变成了[H/2,W/2,2C]
所以对应到模型总览图上则是:[56,56,96]的维度变成了[28,28,192]的维度
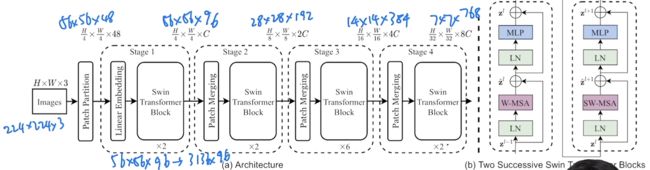
- stage 3
维度上从[28,28,192]变成[14,14,384] - stage 4
维度上从[14,14,384]变成[7,7,768]
整个前向传播过程走完了之后,可能有读者问,swin transformer如何做分类呢?它为了和CNN保持一致,没有像ViT在输入序列上加一个用于最后分类的CLS token,而是在得到最后的特征图之后,用了一个golbal average polling(即全局池化)的操作,直接把[7,7,768]中的7✖️1取平均并拉直成1,使得最终的维度变成[1,768]
//待更新..
参考文献与推荐阅读
- 变分自编码器(一):原来是这么一回事
- VAE原始论文
- 关于VAE的几篇文章:一文理解变分自编码器(VAE)、机器学习方法—优雅的模型(一):变分自编码器(VAE)、
- 苏剑林关于扩散模型的几篇文章:(一):DDPM = 拆楼 + 建楼、(二):DDPM = 自回归式VAE
- 怎么理解今年 CV 比较火的扩散模型(DDPM)?
-
知乎上关于扩散模型的几篇文章:全网最简单的扩散模型DDPM教程、Diffusion扩散模型大白话讲解、扩散生成模型: 唯美联姻物理概念与机器学习
- Understanding Diffusion Models: A Unified Perspective(写于2022年8月,此文写的非常细致,另,这是其PDF版本)
- 扩散模型是如何工作的:从0开始的数学原理
- What are Diffusion Models?,写于2021年7月
- Introduction to Diffusion Models for Machine Learning
- 关于扩散模型的几篇论文
CVPR 2022 Tutorial: Denoising Diffusion-based Generative Modeling: Foundations and Applications
Diffusion Models Beat GANs on Image Synthesis - 关于DDPM的几篇文章(如果相关文章与本文有冲突,建议以本文为准,因为有些文章有笔误或错误):DDPM概率扩散模型(原理+代码)、Denoising Diffusion Probabilistic Models (DDPM)、从VAE到DDPM、扩散模型原理解析
- Vision Transformer 超详细解读 (原理分析+代码解读) (一)
- DETR论文的解读之一
- End-to-End Object Detection with Transformers,DETR原始论文
- Vision Transformer 超详细解读 (原理分析+代码解读) (二)
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ViT原始论文,挑战CNN的在CV领域的统治地位 - ViT论文逐段精读,这是针对该视频解读的笔记之一(神洛华)、针对该视频解读的笔记之二(MT_Joy)
- Vision Transformer 论文 + 详解,Vision Transformer详解by 小绿豆
- Masked Autoencoders Are Scalable Vision Learners
MAE原始论文 - MAE 论文逐段精读,此文则为对该视频解读所做的笔记
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin transformer原始论文 - Swin Transformer论文精读,此文是针对该视频解读所做的笔记(神洛华)、Swin-Transformer网络结构详解(by小绿豆)
- 图解Swin Transformer、如何看待微软亚洲研究院的Swin Transformer?
创作、修改/完善记录
- 第一大阶段
4.28,因要发布AI绘画与CV多模态原理解析的博客,从VAE开始写起
反复理了一个下午,总算把VAE写清楚了,也看了很多同类文章,之前推导看不下去的 都能看得下去了 - 5.1,拆解DDPM的前向过程,其他同类文章对于一个公式 可能一步或两三步到位我而言,能拆10步则10步 阅读无障碍,不然 何必我来写
- 5.3,连续抠了两天DDPM的推导 总算有雏形了
- 5.4,今天又抠了一天的DDPM公式推导,增加了很多同类文章里没有的细节,很爽 这就是我提笔的价值和意义所在了
- 5.6,完善2.2节
从5.2日起,连抠了整整4天DDPM的前向逆向推导,总算快写清楚了整个推导过程
大家害怕的不是公式,只是怕公式的展开不够细致,毕竟对每一个人而言,公式展开越细致 越不怕
且解读 九行推导的每一行
九行推导的每一行
解读代码时 对每一行代码都加注释
拆解公式时 对每一行公式都做解释
已是一个固定的风格,这样人人都能理解 - 5.10,继续完善2.2节
理解DDPM不难,但里面的公式推导特别多,为了让每位朋友可以一目了然的理解每一个公式的推导
只要能拆开的一定拆开 要解释的一定解释 - 5.12,再次完善2.1.2节逆向过程(去噪)
为让整个推导看下来不费劲,修改部分描述以更流畅,使得最终尽可能就像看小说一样 - 5.14,开始更新3.1节DETR的部分
- 5.15,修改完善3.1节DETR结构之前两部分:backbone与encoder
- 5.16,开始更新3.1节DETR结构的后两部分:decoder和FFN,以及损失函数部分解读
- 第二大阶段
5.19,修改完善3.1节3.1节DETR结构的后两部分:decoder和FFN,以及损失函数部分解读
尽可能让行文清晰直观 一目了然 避免看着费劲/别扭 - 6.6,开始写ViT的部分
且为了尽可能让对ViT的介绍一目了然、清晰明确,做了反复多轮的修改
同时也创造了记录,只用一天便写清楚了ViT的介绍,算有史以来最快速度写清楚一个模型
但ViT这个工作真心6,Google这篇论文也写的真心好 每一句话 每一个配图都恰到好处(值得反复看好几遍),有类似感触的第一想到的是OpenAI那篇CLIP论文 - 6.9,开始写Swin Transformer的部分
- 6.12,继续写Swin Transformer的部分