如何实时统计最近 15 秒的商品销售额|Flink-Learning 实战营
为进一步帮助开发者学习使用 Flink,Apache Flink 中文社区近期发起 Flink-Learning 实战营项目。本次实战营通过真实有趣的实战场景帮助开发者实操体验 Flink,课程包括实时数据接入、实时数据分析、实时数据应用的场景实。并结合小松鼠助教模式,全方位帮助入营开发者轻松玩转 Flink,点击下方图片扫码即刻入营。
Tips:点击「阅读原文」即刻入营~

本期内容详细介绍 Flink 实战营第一期实战。
想要了解如何使用 Flink 实时统计最近 15 秒的商品销售额吗?本实验将以阿里云实时计算 Flink 版为基础,使用 Flink 自带的 MySQL Connector 连接 RDS 云数据库实例,并以实时商品销售数据统计的例子,引导开发者上手 Connector 的数据捕获、数据写入等功能。
完成本次实验后,您将掌握的知识有:
使用 Flink 实时计算平台创建并提交作业的方法;
编写基于 Flink Table API SQL 语句的能力;
使用 MySQL Connector 对数据库进行读写的方法。
Flink MySQL Connector 简介
MySQL Connector 可以将本地或远程的 MySQL 数据库连接到 Flink 中,并方便地使用 Flink Table API 与之交互、捕获数据变更、并将处理结果写回数据库。本实验主要介绍如何在阿里云实时计算平台上使用 Flink MySQL 连接器的相关功能,并使用 Table API 编写一个简单的例子,尝试 MySQL 作为源表、维表、汇表的不同功能。
步骤一:创建资源
开始实验之前,您需要开通阿里云实时计算 Flink 版,创建实验资源。
步骤二:创建数据库表
在这个例子中,我们将创建三张数据表,分别作为源表、维表、汇表,演示 MySQL Connector 的不同功能。
1. 进入云数据库 RDS 后台,并登录刚刚创建资源的后台页面。
2. 点击左侧边栏的 + 加号按钮,创建一个测试用数据库,然后在右侧命令区输入以下建表指令并执行:
-- Source Table;
CREATE TABLE `source_table` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`good_id` int DEFAULT NULL,
`amount` int DEFAULT NULL,
`record_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
);
-- Dimension Table;
CREATE TABLE `dimension_table` (
`good_id` int unsigned NOT NULL,
`good_name` varchar(256) DEFAULT NULL,
`good_price` int DEFAULT NULL,
PRIMARY KEY (`good_id`)
);
-- Sink Table;
CREATE TABLE `sink_table` (
`record_timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`good_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`sell_amount` int DEFAULT NULL,
PRIMARY KEY (`record_timestamp`)
);步骤三:创建 Flink 作业
1. 进入实时计算 Flink 平台,点击左侧边栏中的「应用」—「作业开发」菜单,并点击顶部工具栏的「新建」按钮新建一个作业。作业名字任意,类型选择「流作业 / SQL」,其余设置保持默认。如下所示:
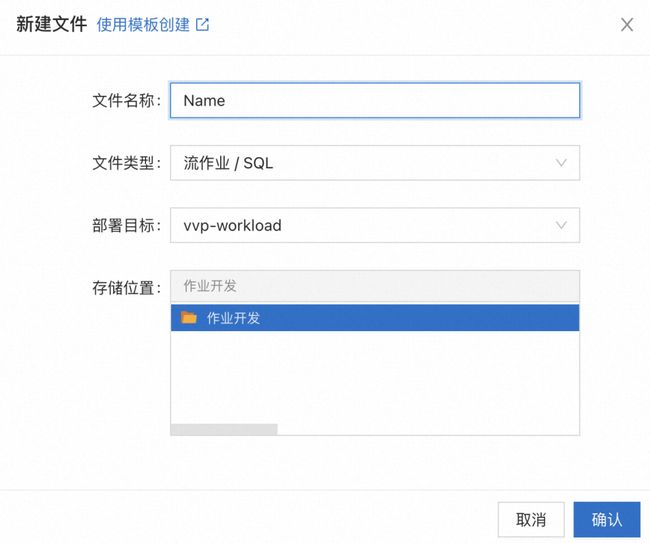
2. 成功创建作业后,右侧编辑窗格应该显示新作业的内容:

3. 接下来,我们在右侧编辑窗格中输入以下语句来创建一张临时表,并使用 MySQL CDC 连接器实时捕获 source_table的变化:
CREATE TEMPORARY TABLE source_table (
id INT NOT NULL PRIMARY KEY NOT ENFORCED,
record_time TIMESTAMP_LTZ(3),
good_id INT,
amount INT,
WATERMARK FOR record_time AS record_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'source_table'
);需要将 hostname参数替换为早些时候创建资源的域名、将 username和 password参数替换为数据库登录用户名及密码、将 database-name参数替换为之前在 RDS 后台中创建的数据库名称。
其中,'connector' = 'mysql-cdc'指定了使用 MySQL CDC 连接器来捕获变化数据。您需要使用准备步骤中申请的 RDS MySQL URL、用户名、密码,以及之前创建的数据库名替换对应部分。
任何时候您都可以点击顶部工具栏中的「验证」按钮,来确认作业 Flink SQL 语句中是否存在语法错误。
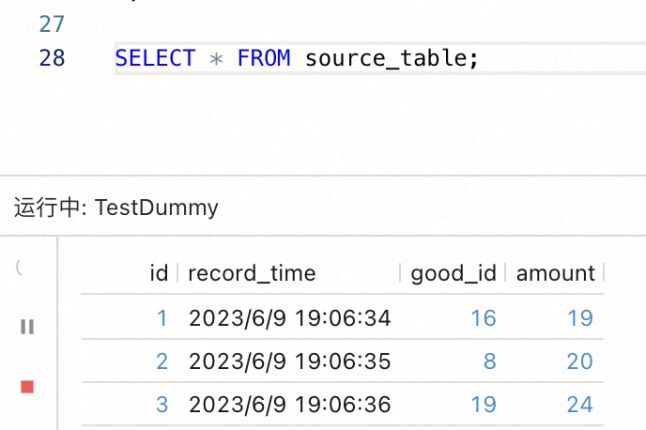
4. 为了测试是否成功地捕获了源表数据,紧接着在下面写一行 SELECT * FROM source_table;语句,并点击工具栏中的「执行」按钮。接着,向 source_table表中插入一些数据。如果控制台中打印了相应的数据行,则说明捕获成功,如下图所示:
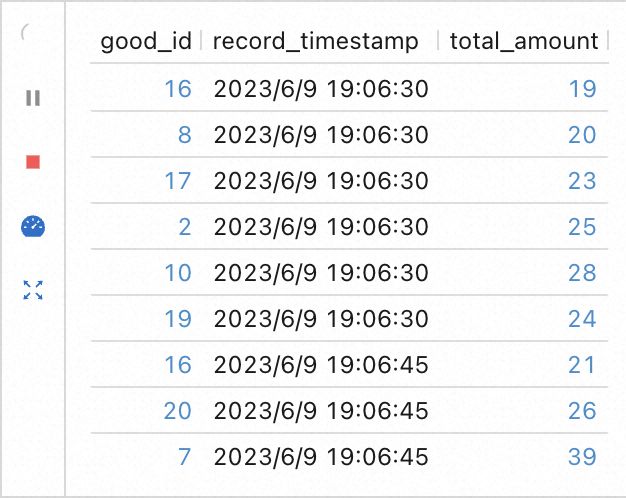
5. 接下来,我们希望对原始数据按照时间窗口进行分组计算。我们使用 TUMBLE相关窗口函数结合 GROUP BY,将长度 15 秒内的订单数据按照商品 ID 进行归类,并使用 SUM计算其销售总额。我们在 Flink 作业编辑窗格中输入如下代码:
SELECT
good_id,
tumble_start(
record_time, interval '15' seconds
) AS record_timestamp,
sum(amount) AS total_amount
FROM
source_table
GROUP BY
tumble (
record_time, interval '15' seconds
),
good_id;为了测试这一效果,需要向数据库中插入多条数据。你可以在 RDS 中执行附件中的「示例数据.sql」来插入数据,或者使用「示例数据生成.py」脚本实时地插入数据。
在保证源表中有数据的情况下,再次执行 Flink 作业,观察控制台的输出结果:
6. 在这个业务场景中,购买商品信息使用 good_id记录,而商品 ID 到可读商品名字的映射表、每件商品的价格等信息则存储在另一张维度表(Dimension Table)中。我们同样可以使用 Flink SQL 连接维度表,只需在 Flink 作业中编写下面的语句:
CREATE TEMPORARY TABLE dimension_table (
good_id INT NOT NULL PRIMARY KEY NOT ENFORCED,
good_name VARCHAR(256),
good_price INT
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'dimension_table'
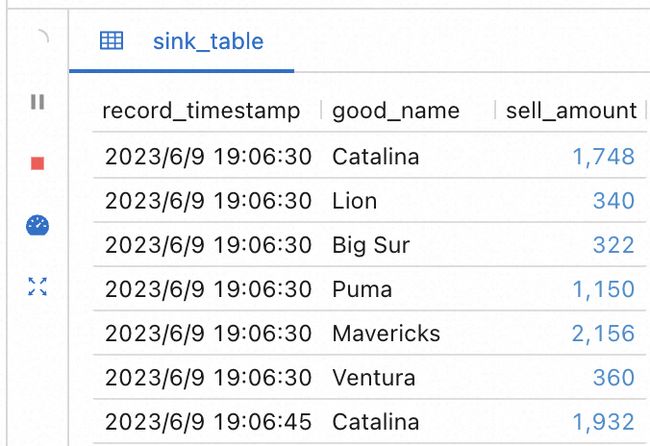
);这里,我们希望根据上一步中统计出的「每 15 秒商品销售量」信息,计算出每件商品的销售额。由于商品名称及商品价格数据存储在另一张维度表 dimension_table中,我们需要将结果视图和 dimension_table进行 JOIN 操作,并将「商品销售量」、「商品价格」相乘计算出「商品销售额」,并提取结果中的商品可读名称信息作为结果表。
需要确保 dimension_table中存在对应商品 ID 的条目。你可以在 RDS 中执行附件中的「示例数据.sql」来插入数据。
作业代码如下:
SELECT
record_timestamp,
good_name,
total_amount * good_price AS revenue
FROM
(
SELECT
good_id,
tumble_start(
record_time, interval '15' seconds
) AS record_timestamp,
sum(amount) AS total_amount
FROM
source_table
GROUP BY
tumble (
record_time, interval '15' seconds
),
good_id
) AS tumbled_table
LEFT JOIN dimension_table ON tumbled_table.good_id = dimension_table.good_id;其中第 7 到 20 行和上一步骤的 SQL 语句一致。
执行上面的语句,并观察控制台中的统计数据:
7. 最后,我们将这些实时的统计数据写回数据库,Flink SQL 也可以简单地实现这一点。首先我们需要创建一张用于连接汇表的 Flink 临时表,如下所示:
CREATE TEMPORARY TABLE sink_table (
record_timestamp TIMESTAMP(3) NOT NULL PRIMARY KEY NOT ENFORCED,
good_name VARCHAR(128),
sell_amount INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://******************.mysql.rds.aliyuncs.com:3306/***********',
'table-name' = 'sink_table',
'username' = '***********',
'password' = '***********',
'scan.auto-commit' = 'true'
);然后,只需要将上面的 SELECT 语句的输出结果 INSERT 到该表就可以了:
INSERT INTO sink_table
SELECT
record_timestamp,
-- ... 和上面的语句一样现在,点击控制台上的「上线」按钮,即可将我们编写的 Flink SQL 作业部署上线执行。您可以使用数据库客户端等软件观察汇表中是否写入了正确的数据。
阿里云实时计算控制台在使用「执行」功能调试时,不会写入任何数据到下游中。因此为了测试使用 SQL Connector 写入汇表,您必须使用「上线」功能。
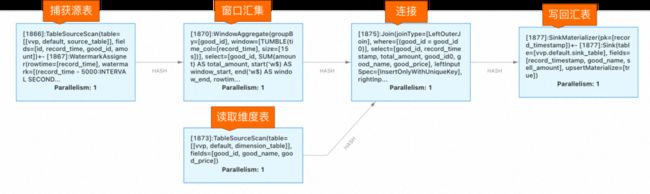
您也可以进入 Flink UI 控制台观察流数据处理图。在这个简单的示例中,首先进行的是源表数据的捕获与窗口聚合;接着和维度表进行 JOIN 操作得到运算结果;最后将处理数据存入汇表。
想要了解更多商品销售额实时统计的实验信息吗?快来尝试一下吧!
往期精选





▼ 活动推荐▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,即刻入营
点击「阅读原文」,即刻入营