Linux文件基础IO的理解1
目录
一.Linux中文件的特性
二.C语言部分库文件相关函数
2.1在C语言的文件底层原理中:
2.打开与关闭函数
fopen:打开文件函数
2.1参数理解:
fclose:关闭文件函数
实验案例:
w方式:
r方式的案例:
a方式案例:
三.Linux系统调用的文件函数讲解:
3.1.3缓冲文件系统和非缓冲文件系统
3.2 open函数:
3.3Write函数 :
案例1:
解决方法 :在open函数的第二参数位置处加上O_TRUNC宏
案例2:追加写入
3.4 read函数
一.Linux中文件的特性
先来回顾一下Linux中文件的特性吧:
1.文件=文件内容+属性
2.修改文件共有三种可能: a.修改文件内容 b.修改文件属性 c.修改文件内容+属性
3.文件是存储在磁盘(硬件)中的,但是只有操作系统可以管理软硬件资源,所以文件只能由操作系统去打开。
4.指定一个重点,文件的路径+文件名代表了一个文件的唯一性标识。
5.空文件被生成后,它也有大小,虽然没有内容,而且显示出来也是0字节,但是它拥有属性那就不是真正的为0字节大小。
6.一个文件如果没有被打开,就不能被访问,相应的,想要访问某个文件,就需要先打开。
打开方式:步骤1:用户进程 ——>OS操作系统。 注:文件存放在磁盘,用户想要访问就不饿能绕过OS操作系统去访问——只能使用OS提供的系统接口。
7.打开文件就是将文件的属性或者内容加载到内存中。
所以文件的本质:用户进程+被打开文件的关系。
二.C语言部分库文件相关函数
2.1在C语言的文件底层原理中:
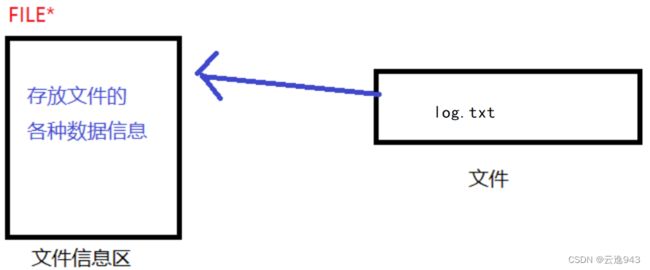
当我们打开文件时,文件就会在内存空间中产生一个文件信息区,里面就是上图形成的结构体FILE,文件信息区与文件紧密的绑在一起,文件信息区的类型是FILE*。
每当我们打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的属性数据,使用者不用关心细节。一般是通过一个FILE*类型的文件指针变量来维护
2.打开与关闭函数
fopen:打开文件函数

2.1参数理解:

解释一下fopen的第二参数——文件使用方式:
例如:在当前路径下有一个A.c源文件。想要对一个文本文件作操作。
1. 在A.c文件中对log.txt文件设置 “w”方式时,读取不到文本文件的内容,只能向文本文件中写内容,写的原理是:系统都会先清空文件上次的所有内容,然后都会在文件的开头处进行内容输入。(注:在编译链接.c文件后执行时,不会有任何结果显示!)注:该文本文件若不存在会自动创建。
2. 在A.C文件中对log.txt文件使用 "w+"方式时,也是可读可写。但是写的时候如果文件存在,其内容会被清空,从头开始写。注:该文本文件若不存在会自动创建。
3. 在A.c文件中对log.txt文件进行设置 "r"方式时,该.c文件中只能使用fgets / fscanf等函数从文件中读取数据到缓冲区,让后搭配使用puts / printf等输出函数在屏幕中打印出来。注:前提是该文本文件必须存在,否则会出错。
4. 在A.c文件中对log.txt文件设置 "r+"方式时,我们依旧可以使用上面的函数从文件中读取内容,而且也可以写内容给文本文件。(注:前提是该文本文件必须存在,否则会出错。)
5. 在A.c文件中对log.txt文件设置 “a”方式时,也是只能去向文件写入内容无法读取,但是a方式写的内容不会覆盖上次写过的内容,会在上次写过的内容结尾进行内容的追加。
fclose:关闭文件函数

fclose函数的参数就是fopen函数的返回值。
注:在代码中一旦使用fopen打开文件函数时,就必须得搭配fclose,否则若文件过大,用完不关会造成内存泄漏,崩溃掉系统!
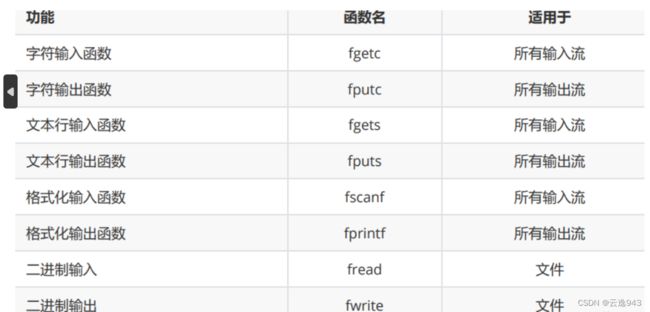
复习一下C语言的文件读写操作接口:
实验案例:
w方式:
#include
#include
#include
#define FILE NAME "log.txt"
int main(){
FILE* fpr=fopen(FILE NAME,"w+"); //文件指针
if(fpr!=NULL){
perror("open file");
exit(-1);
}
//写
int cnt=5;
while(cnt){
fputs("hello world\n",fp);
cnt--;
}
//关闭文件
fclose(fpr);
fpr=NULL;
return 0;
} 在本程序代码中,使用w+方式对文本文件进行内容的写入。
运行结果:
r方式的案例:
#include
#include
#define FILE NAME "log.txt"
int main(){
FILE* fpr=fopen(FILE NAME,"r"); //文件指针
int cnt=10;
char buffer[1024]; //创建缓冲区数组
//利用fgets函数读取文件内容到缓冲区
while(fgets(buffer,sizeof buffer,fp)!=NULL){
printf("%s\n",buffer); //打印缓冲区的内容
}
//关闭文件
fclose(fpr);
fpr=NULL;
return 0;
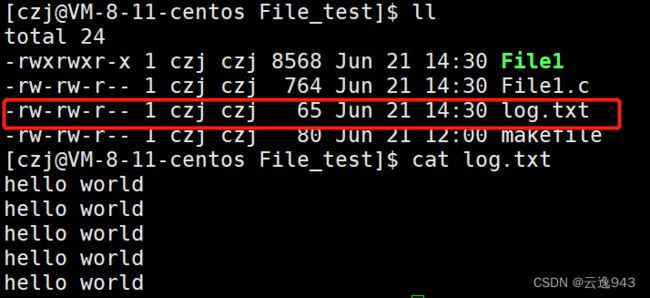
} 在该程序中使用r方式读取文件内容(上个案例写入的5行"hello world\n")到缓冲区,进而将内容打印到屏幕中。
运行结果:
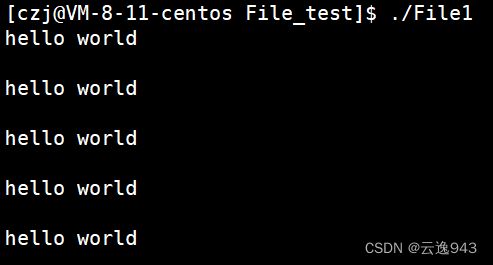
解析:从上图结果中可知:执行File1时,发现打印出来的多行hello world中都隔有空行,这是为什么?
原因在于fgets函数读到字符串末尾会自动换行,每行"hello world"结尾处都默认有一个'\n'换行符,fgets读到后转向下一行,然后继续往后读,又读到了这个字符串结尾默认有的一个字符 '\0'(fgets遇到'\0'会自动换行),所以每读取一行hello world就会多空出一行,便出现了上图的问题。
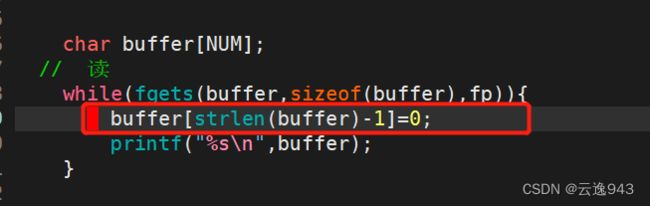
解决方法:每次循环读取之前,我们需要将缓冲区的最后一个有效字符'\n'变成0(0就相当于'\0'字符串结束符)。那么fgets在读取内容时就不会再读取'\n字符了,如下:
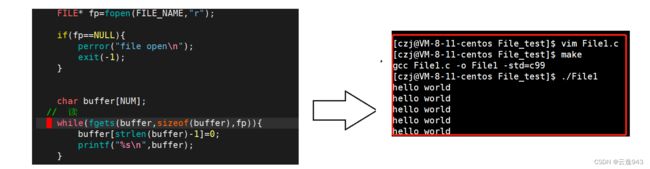
运行结果:
a方式案例:
#include
#include
int main(){
FILE* fp=fopen(FILE NAME,"a"); //追加
if(fp==NULL){
perror("file open\n");
exit(-1);
}
//写
int cnt=5;
int i=l;
while(cnt){
fprintf(fp,%s;%d\n","夜来风雨声,花落知多少”,i++);
cnt--;
}
fclose(fp);
fp=NULL;
return 0;
} 运行结果:
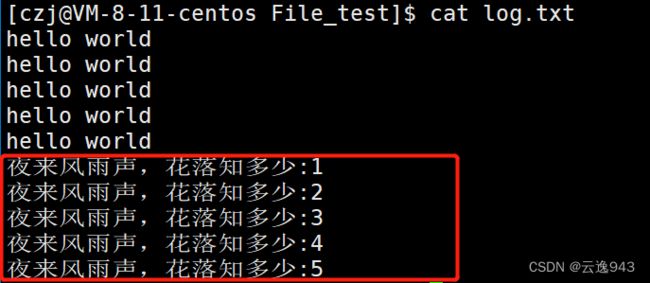
以上这些C语言的库函数全都是基于系统调用函数为底层进行封装的,例如fopen函数是以open函数封装产生的,fclose函数是以close函数封装产生的。
三.Linux系统调用的文件函数讲解:

3.缓冲文件系统和非缓冲文件系统
(a)缓冲文件系统
缓冲文件系统的特点是: 在内存开辟一个“缓冲区”,为程序中的每一个文件使用,当执行读文件的操作时,从磁盘文件将数据先读入内存“缓冲区”装满后再从内存“缓冲区”依此读入接收的变量。执行写文件的操作时,先将数据写入内存“缓冲区”,待内存“缓冲区”装满后再写入文件。由此可以看出,内存 “绣冲区”的大小,影响着实际操作外存的次数,内存“绣冲区”越大,则操作外存的次数就少,执行速度就快、效率高。一般来说,文件“缓冲区”的大小随机器 而定。fopen, fclose, fread, fwrite, fgetc, fgets, fputc, fputs, freopen, fseek, ftell, rewind(b)非缓冲文件系统
非缓冲文件系统是借助文件结构体指针来对文件进行管理,通过文件指针来对文件进行访问,既可以读写字符、字符串、格式化数据,也可以读写二进制数 据。非缓冲文件系统依赖于提作系统,通过操作系统的功能对文件进行读写,是系统级的输入输出。它不设文件结构体指针,只能读写二进制文件,但效率高、速度 快,由于ANSI标准不再包括非缓冲文件系统,因此建议大家最好不要选择它。本书只作简单介绍。open,close, read,write getc,putc,puts......
3.2 open函数:
![]()
参数1:pathname:要打开的文件
若pathname以路径的方式给出,则当需要创建该文件时,就在pathname路径下创建。 若pathname以文件名的方式给出,当需要创建该文件时,会默认在当前路径下进行创建。
参数2:flags
O RDONLY: 只读方式打开
O_WRONLY: 只写方式打开
O_RDWR: 以读写方式打开
O_EXCL: 创建已存在的文件会报错
O_TRUNC: 清空文件
O APPEND: 追加
flags是标志位,而这些打开方式都是用宏和32位比特位建成,所以上面的这些全都是选项,flags参数可以选择其中一个选项,也可以同时选用多个进行使用。
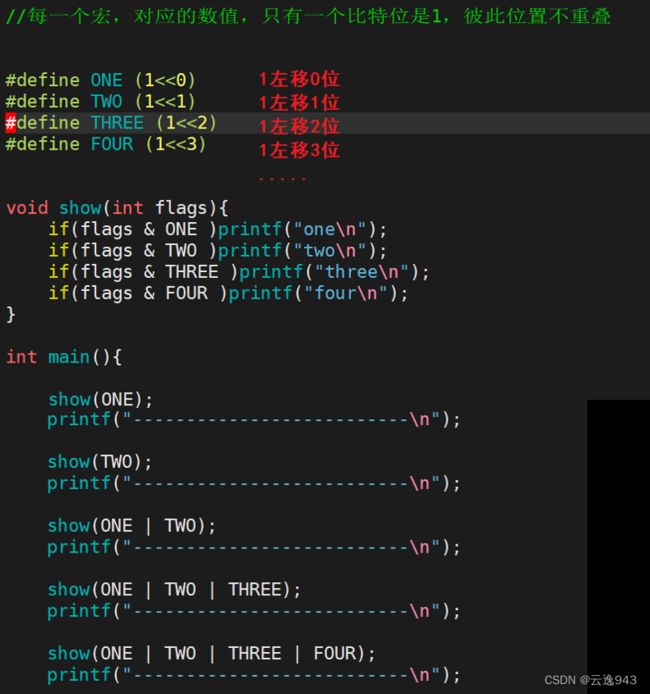
O_RDONLY,O_WRONLY.....也都是这么设置的。
运行结果:
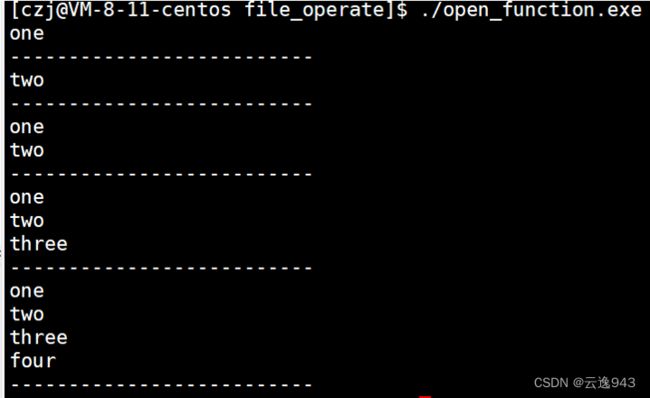
参数3:mode_t mode :表示文件的读写执行权限,可以自行设置,例如0666或者0664......
头文件:
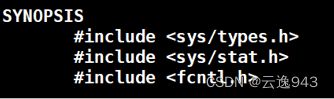
返回值:
open失败返回-1,open调用成功就会成为int类型的文件描述符。这个文件描述符知识点在后面的学习过程中相当重要哟!!!
#include
#include
#include
#include
#include
#include
#include
#define FILE_NAME "123.txt"
int main(){
int fd=open(FILE_NAME,O_WRONLY,0664);
if(fd==-1){
perror("open file");
exit(-1);
}
//写
//......
close(fd);
return 0;
}
运行结果:
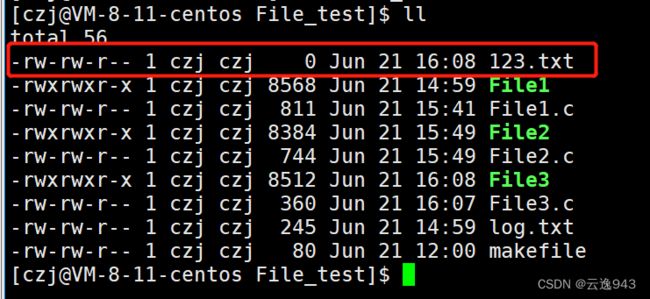
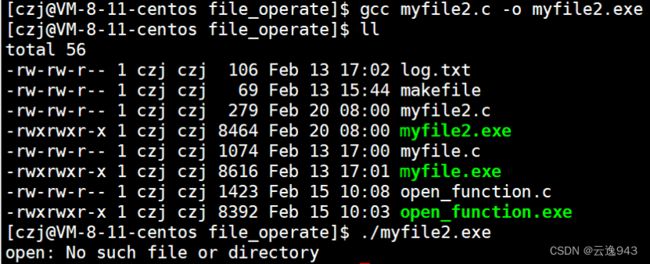 解析:通过上图结果可知,123.txt文件并没有被创建出来,这是为什么? open函数中的三个参数都写上了,都符合相应的条件,为什么会报错?
解析:通过上图结果可知,123.txt文件并没有被创建出来,这是为什么? open函数中的三个参数都写上了,都符合相应的条件,为什么会报错?
![]()
我在上面展示使用fopen函数的时候,log.txt一开始不存在,但C语言的编译器会自动为其创建,是在open函数的基础上给做了封装优化,让我们用的更加趁手。但是open函数本身并没有这个自动创建的特性,需要在参数2中自行添加:

再次编译链接,结果如下:
3.3Write函数 :
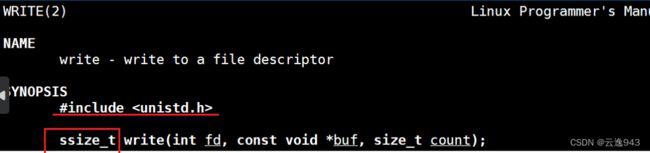
write函数也是系统调用接口,也是用来将程序写入的内容传到文件中去。
write也有三个参数:
int fd :文件接口(open的返回值)
const void* buf:表示任何类型的内容都可以传入(字符串、图片.....),相当于一个缓冲数组。
size_t count:表示传入内容的字节大小。
案例1:
#include
#include
#include
#include
#include
#include
#include
#include
#define FILE_NAME "123.txt"
int main(){
int fd=open(FILE_NAME,O_WRONLY| O_CREAT ,0664);
if(fd==-1){
perror("open file");
exit(-1);
}
//写
int cnt=5;
int i=1;
char buffer[1024];
while(cnt){
sprintf(buffer,"%s:%d\n","hello world",i++);
cnt--;
write(fd,buffer,strlen(buffer));
}
close(fd);
return 0;
} 运行结果:
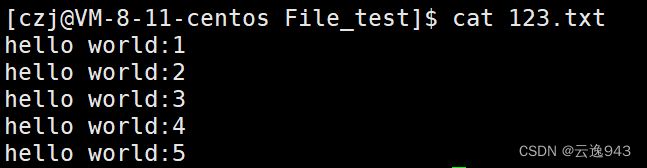
屏幕显示出来的结果正确无误。
之后,我对代码想重新写入新的数据时:
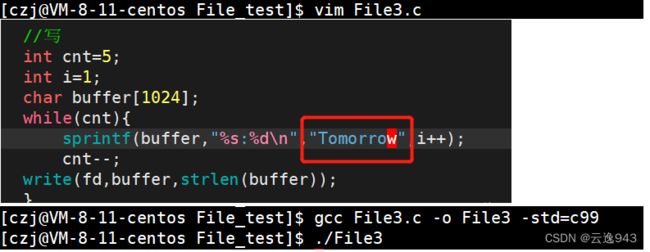
写入新内容Tomorrow时,会覆盖旧数据。
运行结果:
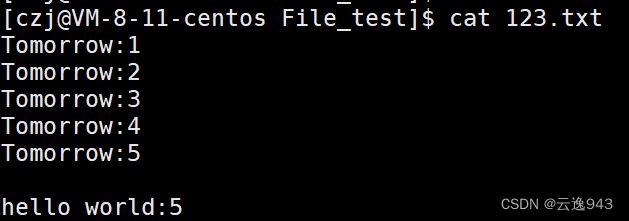
从屏幕中显示出来的结果可知,最后两行出现了问题,原本我想要的只是5行Tomorrow,但是最后两行莫名其妙的多出来一行空行和之前的旧内容,表明代码在写入的过程中出现了问题,没有清理掉以前的数据内容。
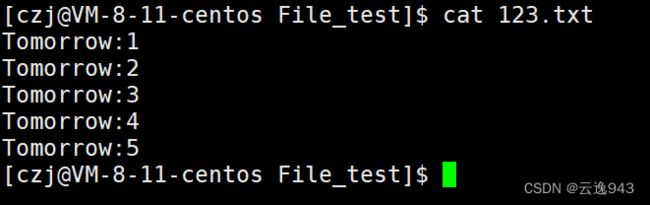
解决方法 :在open函数的第二参数位置处加上O_TRUNC宏

该宏的功能是使得当前程序在写入文件之前会先清空该文件的旧内容,这样就不会出现文件旧内容残留的情况了。C语言库函数fopen的优化,就是通过封装open函数的这多种属性形成的。
再次汇编链接该程序,结果如下:
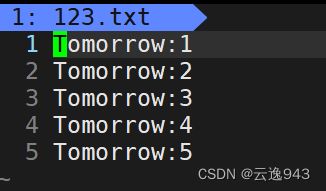
vim编译器中查看该文本文件,也没有出现乱码现象:
案例2:追加写入
#include
#include
#include
#include
#include
#include
#include
#include
#define FILE_NAME "123.txt"
int main(){
int fd=open(FILE_NAME,O_WRONLY| O_CREAT | O_APPEND ,0664); //追加
if(fd==-1){
perror("open file");
exit(-1);
}
//写
int cnt=5;
int i=1;
char buffer[1024];
while(cnt){
sprintf(buffer,"%s:%d\n","春江花月夜",i++);
cnt--;
write(fd,buffer,strlen(buffer));
}
close(fd);
return 0;
} fopen函数的 "a方式",是通过open函数的O_APPEND属性封装而成。
既然使用追加O_APPEND,就没必要使用O_TRUNC清空内容了。
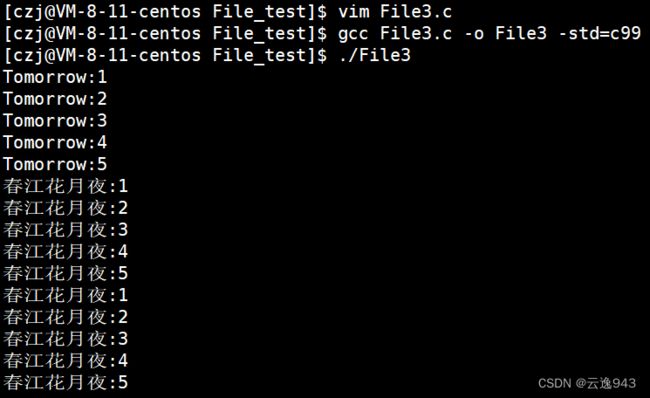
运行结果如下:
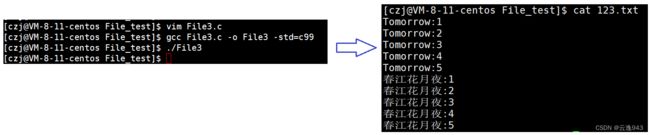
再执行一次该程序,继续追加:
3.4 read函数
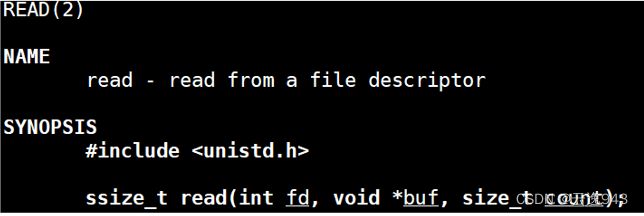
read函数与write函数参数个数和形式相同,唯一不同在于write是通过写入程序缓冲区进而写进文件中;read是通过读取文件内容到程序缓冲区进而使用printf函数打印到屏幕中。
案例1:该案例将围绕上面的write案例进行对123.txt文件的读取。
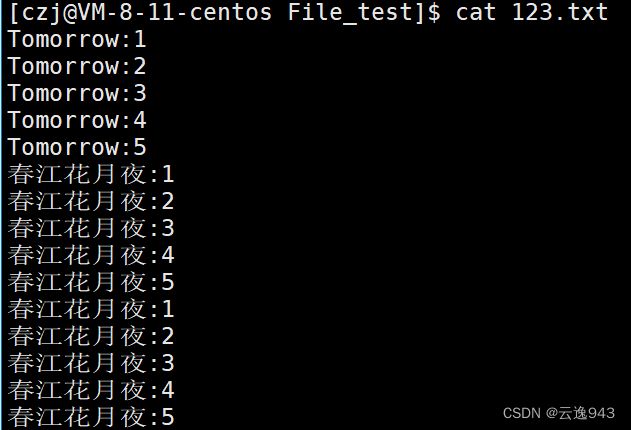
代码如下:
#include
#include
#include
#include
#include
#include
#include
#include
#define FILE_NAME "123.txt"
int main(){
int fd=open(FILE_NAME,O_RDONLY);
if(fd==-1){
perror("open file");
exit(-1);
}
//读取
char RedStr[1024];
ssize_t r1=read(fd,RedStr,(sizeof(RedStr)-1));
puts(RedStr);
//将最后一个有效字符加上'\0'结尾
if(r1>0){
RedStr[r1]=0;
}
close(fd);
return 0;
}
结果如下: