百度交流会大玩心跳!现场实时调教大模型,炸出背后更强底座文心千帆
鱼羊 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
大模型评价标准,现在到了被摆上台面讨论的时刻。
过去两个月,“百模大战”吸足了外界眼球,大模型越发越多,但到底什么样的大模型才是好大模型,却也越来越众说纷纭、备受关注。
就在这样的时间节点,国内最早内测生成式AI大模型的百度,一波新的技术动作,迅速在线下引发热烈反响:
5月9日的百度智能云的文心大模型技术交流活动现场,文心一言先是化身“文心问数”,秀了一把分分钟数据可视化的能力。
但下一分钟,“出bug”的一幕就给逮住了:在面对画折线图的需求时,文心一言压根没懂,来了一句“换个问题试试”。

这是上演直播事故了?台上的程序员小哥,却十分淡定,随即调出了一个新界面——文心千帆大模型平台。
结果下一步操作,直接让现场观众纷纷举起手机录像:现!场!微!调!大!模!型!
只见他当场新建了一个微调数据集。
导入的是这样一份数量在100条左右的标注数据。
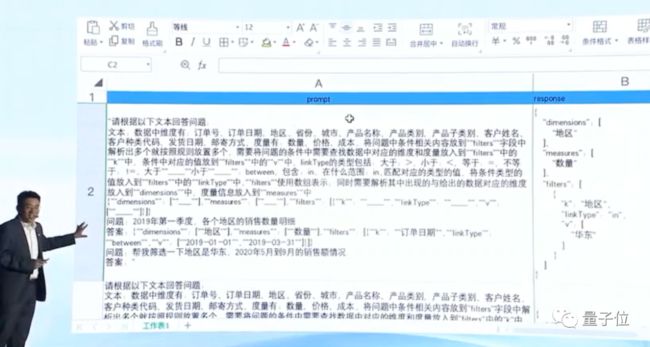
一通可视化操作下来,不过10几分钟之后,当文心一言再次被要求:
华北地区2019年3月的销售额,用折线图表示。
它就已经完全不糊涂,能快速给出正确的结果了。

不错,“现场调教”,恰恰是这一次技术交流活动中,文心一言最受关注的升级重头戏。
因为这就意味着,在百度围绕文心一言搭建起的工具链中,仅需少量数据,最快几分钟,大模型就能完成一次“定制化”,这也是国内第一个现场演示如何微调行业专属大模型的全过程。
更重要的是,通过已在内测中的文心千帆大模型平台,这样的训练调优经验和技术,已经可以向第三方输出了。
于是,回到一开始那个问题上,什么样的大模型才是好大模型?大模型背后正在被改写规则的云计算,又该用何种新标准去评价?
至少现在,讨论的范围中,是时候考虑加进新的样本范例了。
文心千帆是什么?
先来研究研究,这个“文心千帆大模型平台”,与文心一言具体是个什么关系?
简单来说,在文心千帆大模型平台上,企业用户可以直接用上文心一言的大模型服务,不过与此同时,也可以基于这个平台,训练、调优任何第三方大模型,打造属于自己的大模型。
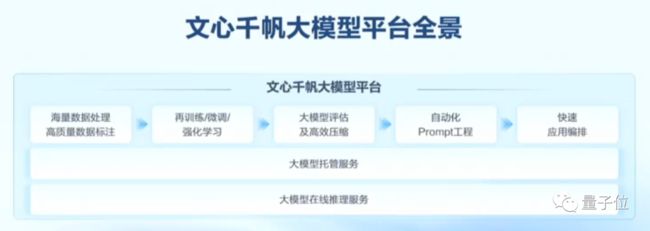
作为全球首个一站式企业级大模型平台,文心千帆所能提供的,实际上不仅是大模型本身,更是开发大模型的一整套工具链和环境。
还是结合具体案例来看看,文心千帆具体能用来做什么。
首先,是公有云服务。主要包括三个组成部分:
1、推理,就是直接调用大模型的推理能力。
以百度员工“内用”的智能办公软件如流为例,其中就接入了一个可以直接向文心一言提问的AI小助手。
平时无论是程序员还是产品经理,手头上的项目都有不少,遇到问题时往往需要私戳对应的负责人,光是等待时间就接近5分钟。
现在有了AI助手,如流不仅能直接模拟同事身份,帮助回答一些专业问题,还能从项目文件中提取关键信息来答疑解惑。
而且,平均应答时间只需5秒钟,比同事快了60倍。
这样看,哪天身边的同事被AI替代了,可能百度员工都不知道(手动狗头)

2、微调,通过少量高质量的精标业务数据,高效训练出特定行业大模型。前文提到的文心一言现场微调,就是基于这一服务实现的。
3、托管,即把训好的模型,发布到百度智能云上,由百度智能云来对模型进行运营维护。企业同样只需考虑如何用好模型,而无需顾虑复杂的部署和管理问题。
百度集团副总裁侯震宇谈到,尽管当前,从头训练大模型的成本仍然高昂,但使用、微调大模型的成本已经在过去几个月中,有显著降低。
比如,现在调用文心一言的成本,已经降低到模型刚发布时(3月16日)的10%。
也就是说,通过文心千帆的公有云服务,用户可以直接服用百度智能云过去积累下的开发、应用大模型的经验,更低成本、低门槛地用上大模型。
公有云服务之外,文心千帆也支持私有化部署。同样包括三个方面:
软件授权,即在企业本地环境中,提供文心一言的大模型服务。
软硬一体,提供整套大模型服务及对应的硬件基础设施。
租赁服务。提供机器和平台租赁,以满足客户的低频需求。
以金山办公为例,他们认为,当前市面上的文档产品,无论是传统的还是流式的,都是基于人们的创作,用自己的笔一行一行把想要的东西表达出来。
这就需要重新思考,AI时代,创作的过程该是什么样子?

金山办公选择的策略是,“要跟中国优秀的大模型提供方站在一起,做好大模型应用方的角色,用更好的办公软件,为客户提供更多的价值”,于是在综合考虑安全合规、模型深度、迭代速度、推理性能等多个方面的优势后,金山办公pick了文心千帆。
据透露,在意图理解、PPT大纲生成、范文书写、生成待办列表、文生图等多模态生成的场景上,双方的联合开发已经取得了进展,但在细节方面仍然会自己进一步调试。
说不定不久后,我们就能在WPS Office上和基于文心千帆大模型平台打造的AI小助手对话了。

相比于公有云服务,私有化部署能满足更严格的数据监管需求。
总结一下就是,文心千帆能通过图形化的界面,提供AI算力,数据管理、模型训练、评估优化、服务部署等大模型生产开发全流程的工具链。除了开发,文心千帆还为客户提供了非常好的大模型训练推理服务。
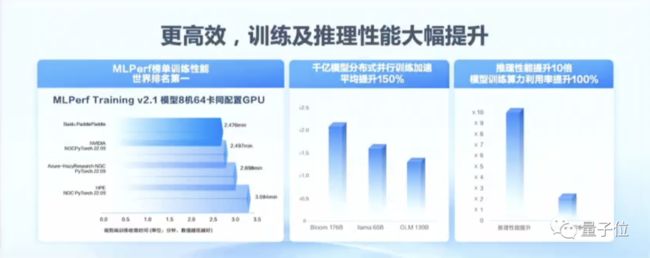
有意思的一点是,百度智能云AI与大数据平台总经理忻舟提到,“快且收敛,是大模型应用训练中一个非常重要的指标,只快不收敛,大模型的训练是没有用的。”
基于文心千帆大模型平台+百度AI大底座的能力,像Bloom、LLaMA、GLM等千亿级第三方开源模型,分布式并行训练的性能提升平均也都能达到150%。
新时代需要新的评价标准
事实上,如果进一步探寻大模型技术进展背后,来自产业端的需求变化,就会发现文心千帆所折射出的,其实是云计算规则被大模型改变之后,百度智能云自身面对新评价标准,给出的思考总结。
用侯震宇的话说,就是“从科幻向务实的转变”:
在被划时代技术所震惊的最初,大家都期待着大模型有“解决一切”的表现。但当技术的优势和局限在实践中不断被验证,“效果”和“成本”这两个评价大模型的关键词,也逐渐清晰起来。
这一方面,使得上云使用大模型,成为绝大多数企业的首选:人人都想用大模型,还有不少人想打造自己的大模型,但同时,从头打造大模型依然是一件高投入、高技术含量的事情。
另一方面,面对市场上越来越多的竞争者,企业如何选择、评估大模型及背后的云计算服务,已成为新的需要被探讨的问题。

而从文心千帆的应对之道中,可以看出来自产业的三重新评估标准已经初现雏形——
大模型本身的能力
炼大模型的基础设施能力
全栈技术的积累程度
新在何处?
大模型本身的能力不必过多解释,一组数据足以说明:侯震宇透露,在文心一言开始企业内测以后,在与百度智能云接洽大模型业务的客户中,新客户的比例已经超过了老客户的比例,“有大量的机构,原先不太愿意用,现在愿意跟我们聊,也愿意去用”——大模型本身,已经成为最主要的吸引力来源。

据介绍,截止目前,已有超过300家生态伙伴参与文心一言内测,在400多个企业内部场景取得测试成效。
值得关注的还有两方面的变化:
其一,是评估大模型是否“高效好用”,显然算力已经不再是其中的唯一标准。
受限于自身大计算、大参数、高成本等特性,大模型此前在落地上一直存在瓶颈。
这也决定了企业在选择大模型时,即使输出效果足够好,也必然还会考虑易用性、安全性、高效性、开放性、扩展性和全面性等诸多方面的因素。
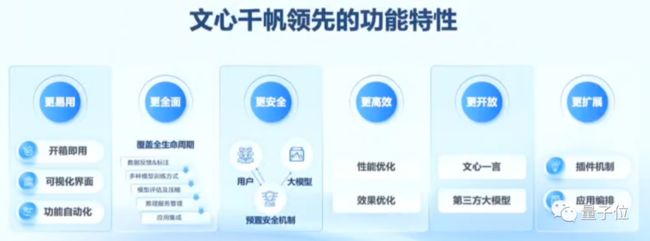
如果拆解企业打造大模型的方式,会发现硬件算力只影响这些因素中的一小部分。
协同算力、框架、模型、应用这四层架构打造AI大模型,才能从根本上决定其端到端的输出效果,是“最佳调优”模式。
打个比方,对于大模型而言,想要极致优化推理速度和使用成本,算力、框架、模型、应用就像是四个齿轮,各自转速之外,很大程度上还要看它们之间的“配合能力”。
此前,国内外云厂商或多或少都已经在软硬件技术协同方面进行布局,国外如亚马逊、国内阿里都已经在芯片层、模型层上发展了自研技术,微软则也已经在框架层和应用技术上有所准备。
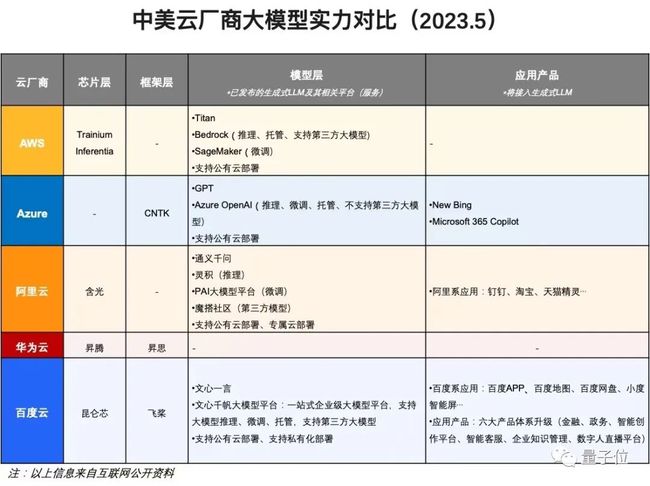
而目前在四层架构上均有自研技术布局的,就是百度一家。
这一布局成果,如今已经在成本降低上有直观的体现:
此前3月份启动内测时,如今不到2个月,百度大模型文心一言已完成4次技术版本升级,其推理成本更是已经降为原来的十分之一。
其二,是评估“生产”大模型的能力时,本质上考验的是企业炼大模型的基础设施能力。
算法、算力和数据,对于大模型而言缺一不可。值得一提的是,由于大模型的训练和推理都需要大量算力支撑,因此云厂商能把多少算力划分入AI算力的范畴,比单纯的硬件数量更值得关注。
更重要的是,三者的综合运用,大模型高效、稳定的训练和有效的收敛,离不开扎实的工程基座。
其中涉及的工程问题实际上非常复杂,包括千卡通信、集群调度、大规模分布式文件系统等等。
比如,文心千帆大模型平台,其实就是把模型开发、训练、调优、运营等复杂过程封装成能更高效调用的工具,来输出百度打造大模型的工程经验。
“大家可能会觉得堆积算力、写好代码、然后进行模型训练,把它跑起来就行了。实际上在训练过程中会遇到各种各样的挑战,很少有人能够使得一个大模型训练过程能够在连续一两天内不出问题。”百度智能云云计算产品解决方案和运营部总经理宋飞介绍。
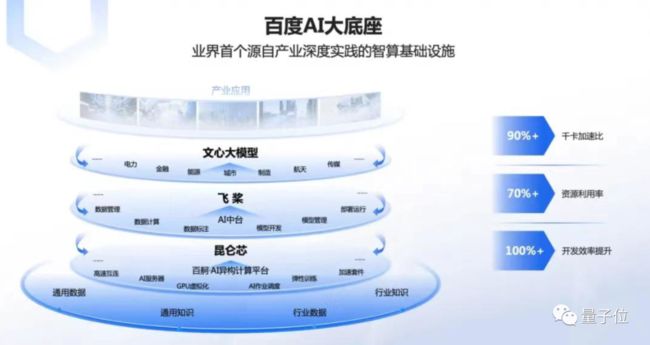
而百度AI大底座,更是通过芯片、框架、模型、应用四层架构之间的高效协同,在基础设施层面上,实现千卡加速比90%、资源利用率70%,开发效率提升100%。这是AI大底座为大模型的开发和应用带来的价值。
每一个时代的技术,有每一个时代评价标准。
而新标准的越辩越明,也往往意味着旧有格局的打破,和换道竞争机会的到来。
智能手机之于非智能手机如此,电动车之于燃油车亦如此。
而现在,催生了大模型,又被大模型打破规则的云计算,站在技术浪潮的最前沿,或许也同样走到了变化的前夕。
正如李彦宏所说,大模型应用时代是一个全新的时代。
对于云计算来说,第一批参考案例已经到来,更多新时代的新变化,还会远吗?
— 完 —
点这里关注我,记得标星哦~