TokenGT:Transformer是强大的图学习器
论文标题:Pure Transformers are Powerful Graph Learners
论文链接:https://arxiv.org/abs/2207.02505
论文来源:NIPS 2022
一、概述
由于Transformer的完全注意力架构接收、处理和关联任意结构的输入和输出的能力,消除了将特定于数据和任务的归纳偏差融入网络架构的需要,这使得其在NLP、CV等诸多领域成为了通用架构。与大规模训练相结合,它为构建一个通用模型开辟了新的篇章,该模型可以解决涉及多种数据模式甚至混合模式的广泛问题。
在图学习领域,受这些突破的启发,许多研究尝试将自注意力机制结合到之前以消息传递为主的图神经网络(GNN)架构中。然而,由于跨节点的全局自注意力不能反映图结构,这些方法引入了特定于图的架构修改。这些方法包括
①限制自注意力只关注节点的局部邻域;
②使用全局自注意力与消息传递GNN相结合;
③通过attention的偏置将边信息注入全局自注意力机制中。
尽管性能不错,但就通用性而言,这样的修改可能是一个限制约束,特别是考虑到未来与多任务和多模态通用注意力架构的集成。此外,由于其偏离纯粹的自注意力机制,这些方法可能会继承消息传递的问题,如过平滑,并且与有用的工程技术不兼容,例如为标准自注意力开发的linear attention。
在本文中我们采用标准的Transformer架构,将其直接应用在图上。我们将所有的节点和边看做独立的token,并且使用相应的token-wise embedding来增强(augment)他们,最后将这些token作为标准Transformer的输入。模型命名为Tokenized Graph Transformer (TokenGT),该模型与用在语言和视觉上的Transformer相同,每个节点或边都被视为一个token,类似于句子中的word或图像中的patch。本文也证明了这种简单的方法在理论和实践中都能成为强大的图学习器。在这篇博客中只介绍方法部分。
本文的一个关键理论结果是我们证明了通过适当的token-wise embedding,节点和边token上的自注意力可以近似图上的任何置换等变线性算子(permutation equivariant linear operator)。另外,我们还发现一种非常简单的embedding就可以实现这种精确的近似。这提供了一个坚实的理论保证,通过embedding和足够的注意力头,Transformer至少具备二阶不变图网络(2-IGN)一样的表达能力,这已经超过了所有的消息传递GNN的能力。这赋予了模型至少与二维Weisfeiler-Lehman (WL)图同构检验相当的表达能力,这对于现实时间的图数据已经是足够的了。我们进一步将我们的理论结果扩展到具有k阶超边的超图上,表明具有k阶广义token embedding的Transformer至少与k-IGN和k-WL测试一样具有表达能力。
二、方法
TokenGT是一个纯Transformer的架构,使用token-wise embedding来表征图信息,包括node identifier和type identifier两部分。对于一个图,和条边,以及节点和边的特征。在TokenGT中,我们将图的每个节点和边当做一个独立的token(也就是说一共有个token),其特征也就是。
一种朴素的处理图的方法是直接将输入给Transformer,然而这是不合适的,因为图的连通性被丢弃了。为了能够完整地表示图信息,TokenGT采用一种token-wise embedding来增强,具体的,也就是使用标准正交的node identifier和可训练的type identifier来编码一个token是一个节点还是一条边。本文证明了采用这样一种简单表示方法的Transformer具有很强的Graph学习能力。
Node Identifiers
TokenGT采用的token-wise embedding的第一个部分是标准正交的node Identifier,用来表示给定的输入图的连通结构。对于一个输入图,我们首先提供个node-wise的标准正交向量作为node Identifier,然后按照以下方式来增强图的token特征向量:
①对于每个节点,增强变成;
②对于每条边,增强变成。
直观地来看,Transformer可以通过这些增强的token来完全识别图的连通结构,这是因为比较两个token之间的node Identifier可以揭示它们的关联信息(incidence information)。举例来说,对于一条边是否与节点相连,当且仅当时才有否则为。这允许Transformer识别和利用图的连通性结构,例如,当局部的信息很重要时,通过对相关联的pair对施加更多权重。
TokenGT对Node Identifier矩阵的唯一要求是标准正交,因此在实际应用中有多种选择,本文列举了两种:
①正交随机特征(Orthogonal random features, ORFs),也就是对随机高斯矩阵进行QR分解得到Q矩阵,采用的行向量。
②对图的拉普拉斯矩阵进行特征分解,然后采用的行向量。
ORFs并没有编码任何图结构信息,这是因为它们是完全随机的。这意味着基于ORFs的node Identifier只需要从node Identifier提供的关联信息中编译和识别图结构。虽然这是很有挑战性的,但是实验结果表明Transformer具备这样的能力。
与ORFs相比,拉普拉斯特征向量提供了一种图的positional embeddings,它描述了图上节点之间的距离。实验结果显示拉普拉斯特征向量比ORFs展示出更好的性能,这是因为其编码了位置信息。拉普拉斯特征向量的一个有趣的方面是,它们可以被看作是NLP Transformer对正余弦位置编码的推广,因为一维链图的特征向量是正弦和余弦函数。因此,通过选择拉普拉斯特征向量作为node Identifier,TokenGT可以被解释为涉及关系结构的输入的NLP Transformer的直接扩展。
Type Identifiers
Token-wise embedding的第二个部分是可训练的type Identifier,用于标识一个token是节点还是边。对于一个输入图,首先准备一个可训练的参数矩阵,包含两个type Identifier和,分别对应节点和边。然后对上面增强过的token继续进行增强:
①对于每个节点,增强变成;
②对于每条边,增强变成。
这些embedding提供了关于给定token是节点还是边的信息,这是至关重要的,例如,当注意力头试图专门关注节点token而忽略边token时。
Main Transformer
有了node Identifier和type Identifier,现在我们可以得到输入给Transformer的特征向量,将通过一个参数矩阵映射到维就可以输入给Transformer了。对于图级的预测任务,TokenGT会加入一个特殊token[graph]与其对应的可训练的embedding,这类似于BERT和ViT的做法。因此在面对图级任务时,模型的输入为。
归纳偏差
类似于语言和视觉领域的Transformer模型,TokenGT将输入的节点和边视为独立的token,并对它们应用自注意力。与当前的图神经网络(GNN)相比,这种方法导致了更少的归纳偏差,其中稀疏图结构或者更基本的图的排列对称性被故意整合到每一层中。对于TokenGT,这些信息完全作为输入的一部分,通过token-wise embedding提供,模型必须学会如何从数据中解释和利用这些信息。尽管这种弱归纳偏差可能会引发关于模型表达能力的质疑,但本文的理论分析表明,得益于token-wise embedding和自注意力的表达能力,TokenGT是一个强大的图学习器。
三、实验
大规模图回归任务
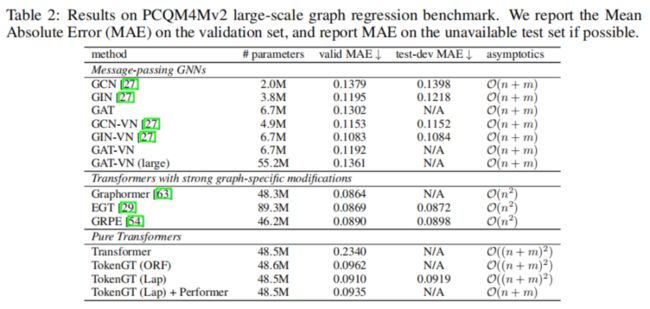 大规模图
大规模图
每层的Attention距离
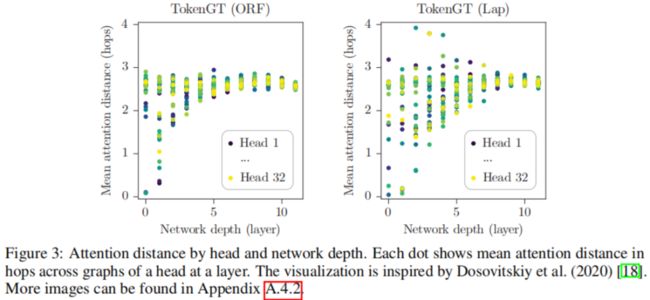 每层的Attention距离
每层的Attention距离