【文献阅读】gem5-gpu: A Heterogeneous CPU-GPU Simulator
题目:gem5-gpu: A Heterogeneous CPU-GPU Simulator
时间:2014
会议/期刊:IEEE Comput. Archit
研究机构:
作者:Jason Power, Joel Hestness, Marc S. Orr, Mark D. Hill, and David A. Wood
gem5-gpu: A Heterogeneous CPU-GPU Simulator
Abstract
gem5-gpu是一个新的模拟器,为紧密集成的CPU-GPU系统建模。它建立在gem5(一个模块化的全系统CPU模拟器)和GPGPU-Sim(一个详细的GPGPU模拟器)的基础上。gem5-gpu通过Ruby路由大多数内存访问,Ruby是gem5中一个高度可配置的内存系统。通过这样做,它能够模拟许多系统配置,从具有连贯缓存和跨越CPU和GPU的单一虚拟地址空间的系统到保持独立的GPU和CPU物理地址空间的系统。应用程序可以启动非阻塞式内核,允许CPU和GPU同时执行。我们介绍了gem5-gpu的软件架构和简短的性能验证。我们还讨论了该模拟器可能的扩展。gem5-gpu是开源的,可在gem5-gpu.cs.wisc.edu上获得。
Index Terms— Modeling techniques, simulators, heterogeneous (hybrid) systems,
general-purpose graphics processors
1 Introduction
计算机架构正在从多核时代过渡到异构时代[9]。许多系统正在运送集成的CPU和图形处理单元(GPU)[9], [5], [8]。不断提高的集成度提出了新的研究问题。
历史上,计算机架构师使用周期级模拟器来探索和评估新的处理器设计。我们利用两个成熟的模拟器,gem5[3]和GPGPU-Sim[2]。gem5是一个多核全系统模拟器,具有多个CPU、ISA和内存系统模型。面向对象的设计、灵活的配置支持以及它的成熟度使gem5成为研究通用CPU和多核平台的流行工具。GPGPU-Sim是一个详细的通用GPU(GPGPU)模拟器[2]。GPGPUSim为GPGPU计算单元(CUs)–NVIDIA称之为流式多处理器–以及GPGU内存系统建模。
为了探索异构系统的设计空间,我们引入了gem5-gpu模拟器,它结合了GPGPU-Sim的CU模型和gem5的CPU和内存系统模型。gem5-gpu建立在相关CPU-GPU模拟器的理念之上,但做出了不同的设计选择。It captures interactions with execution-driven simulation rather than well-partitioned tracedriven simulation, e.g., MacSim [1]. 它使用了比MV5[6]更详细的–因此更慢的–GPU组件,并且不依赖于被废弃的m5模拟器。它比Multi2Sim[10]或FusionSim[11]支持更灵活的内存层次和一致性协议,但可能会增加仿真时间。gem5-gpu是唯一具有以下所有优势的模拟器。
- 详细的高速缓存一致性模型。
- 全系统仿真。
- 检查点。
- 与最新的gem5模拟器紧密集成,以及
- 增加了GPGPU编程模型和整个系统架构的可扩展性。
通过将GPGPU-Sim的CU模型集成到gem5中,gem5-gpu可以捕捉异构处理器中CPU和GPU之间的互动。特别是,GPGPU-Sim的CU内存访问流经gem5的Ruby内存系统,从而实现了广泛的异构缓存层次和一致性协议。gem5-gpu还提供了一个可调整的DMA引擎,以模拟具有独立CPU和GPU物理地址空间的配置中的数据传输。通过这些功能,gem5-gpu可以模拟现有和未来的异构处理器。
gem5-gpu是开源的,可在gem5-gpu.cs.wisc.edu上获得。
本文首先介绍了GPGPU和基础设施的背景(第2和第3节),gem5-gpu的设计(第4节),简要验证(第5节)和未来的方向(第6节)。
2 Heterogeneous Computing
通用GPU计算是指将计算offload到可编程的GPU上运行的做法。通常针对GPGPU计算的应用包括数据并行的图像处理、科学和数值算法,尽管有一种趋势是更不规则的并行工作负载,如图形分析。
Work units offloaded to the GPU are called kernels (内核). Kernels can be structured to execute thousands of threads on the GPU in a single-instruction, multiple-thread (SIMT) fashion. 在具有独立的CPU和GPU地址空间的系统中,如独立的GPU,数据在GPU地址空间和CPU地址空间之间明确地被复制。
编写应用程序以利用GPU的优势,需要用户级调用GPGPU应用编程接口(runtime),该runtime与控制GPGPU设备的内核级驱动程序接口。目前,最流行的GPGPU runtimes是CUDA和OpenCL。
有一种趋势是简化GPGPU计算的编程模型。异构系统架构(HSA)基金会,一个由公司和大学组成的联盟,已经宣布未来支持异构统一内存访问(hUMA, heterogeneous uniform memory access)[9]。hUMA为程序员提供了一个CPU和GPU之间的共享虚拟地址空间。此外,implementations of hUMA provide the CPU and GPU with a coherent view of the virtual address space. 英伟达(NVIDIA)支持类似的结构,即统一的虚拟寻址(UVA)[7]。gem5-gpu开发的一个主要目标是以灵活和可扩展的方式支持这些未来的编程模型和架构方向。
3 The Giant’s Shoulders
3.1 gem5
gem5 simulation infrastructure(gem5.org)是一个以社区为中心的模块化系统建模工具,由许多大学和工业研究实验室开发[3]。gem5包括多个CPU、内存系统和ISA模型。它提供两种执行模式,(1)系统调用仿真system call emulation,可以使用仿真的系统调用运行用户级二进制文件;(2)全系统full-system,对所有必要的设备进行建模,以启动和运行未经修改的操作系统。最后,gem5还支持对系统状态的检查点,这使得模拟可以跳到感兴趣的区域。
gem5的两个具体特点使其特别适合于开发异构CPU-GPU模拟器。
-
首先,gem5为新架构组件的模块化集成提供了几种机制。当新组件需要通过内存系统进行通信时,它们可以利用gem5灵活的端口接口来发送和接收消息。此外,gem5 EXTRAS接口可用于指定编译到gem5二进制中的外部代码。这个接口使得从gem5的基础设施中添加和删除复杂的组件变得简单。
-
其次,gem5包括详细的高速缓存和内存模拟器Ruby。Ruby is a flexible infrastructure built on the domain specific language, SLICC, which is used to specify cache coherence protocols (高速缓存一致性协议). 使用Ruby,开发者可以明确地定义高速缓存层次和一致性协议,包括那些在新兴异构处理器中预期的协议。
目前,gem5不包括GPU的模型。
3.2 GPGPU-Sim
GPGPU-Sim是一个详细的GPGU模拟器(gpgpu-sim.org),有强大的出版记录支持[2]。它对现代NVIDIA显卡的计算架构进行建模。GPGPU-Sim可以执行 编译为PTX(NVIDIA中间指令集)的应用程序 或 反汇编的本地GPU machine code。GPGPU-Sim对计算管道的功能和时序部分进行建模,包括线程调度逻辑、高库存寄存器文件、特殊功能单元和内存系统。GPGPU-Sim包括所有类型的GPU内存以及缓存和DRAM的模型。
GPGPU应用程序可以访问多种内存类型。全局内存是主要的数据存储器,大多数数据都存放在这里,类似于CPU应用程序中的堆。它通过虚拟地址进行访问,并在芯片上进行缓存。其他GPU特定的内存类型包括constant,用于处理GPU的只读数据;scratchpad,一个软件管理的、明确寻址的、低延迟的内核缓存;本地,主要用于溢出寄存器;参数,用于存储计算内核参数;指令,用于存储内核指令;纹理,一个图形特定的、明确寻址的缓存。
GPGPU-Sim主要consume未经修改的GPGPU源代码,这些代码被链接到GPGPU-Sim的自定义GPGPU runtime library。修改后的runtime library拦截所有GPGPU特定的函数调用并模拟其效果。When a compute kernel is launched, the GPGPU-Sim runtime library initializes the simulator and executes the kernel in timing simulation. 主仿真循环继续执行,直到内核完成后才从runtime library call返回控制。GPGPU-Sim是一个功能优先functional-first的模拟器;it first functionally executes all instructions, then feeds them into the timing simulator.
GPGPU-Sim在对异构系统建模时有一些限制:
- 没有主机CPU的时序模型。
- 没有主机-设备拷贝的时序模型。
- 僵化的缓存模型。
- 没有办法对主机-设备的相互作用进行建模。
由于这些限制,对探索CPU-GPU混合芯片作为异构计算平台感兴趣的研究人员不能只依赖GPGPU-Sim。
4 gem5-gpu Architecture
图1显示了gem5-gpu可以模拟的一个架构实例:在同一芯片上集成了一个四核CPU和一个八CU GPU。CPU、CU的数量以及连接它们的拓扑结构是完全可配置的。gem5-gpu开箱即提供的两种片上拓扑结构是共享和分离的内存层次结构(即分别是集成和独立的GPU)。
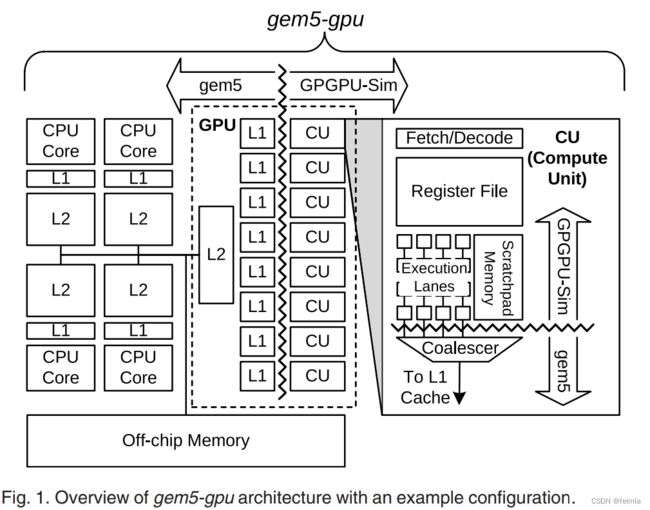
许多CU组成了GPU,每个CU都有取/解码逻辑,一个大的register file,以及许多(通常是32或64)执行通道。当访问全局内存时,每个通道将其地址发送给凝聚器coalescer,coalescer将内存访问合并到同一高速缓存块。GPU还可能包含一个缓存层次,存储来自最近全局内存访问的数据。
4.1 gem5 ↔ GPGPU-Sim Interface
我们的目标之一是在gem5和GPGPU-Sim之间有一个干净的接口。虽然有许多可能的选择,但我们选择了内存接口,如图1所示。我们为gem5添加了一个伪指令,以方便调用模拟器的DMA引擎和GPU功能。然后,gem5-gpu通过gem5的端口接口port interface将通用内存指令——对全局地址空间的访问——从GPGPU-Sim导向Ruby。
4.2 Memory System Modeling
gem5-gpu使用Ruby来模拟大多数CU内存访问的功能和时间。gem5对load-store pipeline进行了建模,包括凝聚coalescing、虚拟地址转换virtual address translation和高速缓存仲裁逻辑cache arbitration logic。通过使用gem5中的port interface,gem5-gpu可以灵活地改变执行通道的数量、CU的数量、高速缓存的层次结构等,并在未来纳入其他GPU模型。
目前,GPGPU-Sim只向gem5发出通用内存指令,包括对global and constant memory的访问。我们利用GPGPU-Sim to model memory operations to scratchpad and parameter memory。纹理和本地内存Texture and local memory目前不受支持,尽管它们只需要简单的模拟器增强。
gem5-gpu支持CPU和GPU之间的共享虚拟地址空间(即,GPU使用CPU页表进行虚拟到物理的转换)。另外,通过一个配置选项,gem5-gpu可以建立独立的GPU和CPU物理地址空间。
4.3 Detailed Cache Coherence Models
gem5-gpu利用了gem5的高速缓存一致性建模语言cache coherence modeling languageSLICC。在配置gem5-gpu时,可以使用任何缓存一致性协议,包括目前随gem5发布的众多协议。 然而,这些包含的协议假定了一个homogeneous cache topology。
为了增强这些协议以实现异构计算,gem5-gpu增加了一个异构缓存一致性协议系列:MOESI_hsc (heterogeneous system coherence with MOESI states)。MOESI_hsc对系统中包含的所有CPU缓存使用MOESI协议。对于GPU缓存,我们增加了一个二级缓存控制器,在GPU和CPU二级缓存之间提供一致性。MOESI_hsc对GPU L1缓存的建模与目前的GPU缓存架构类似:write-through and only valid and invalid states。此外,GPU L1缓存可能包含陈旧的数据 that is flushed at synchronization points and kernel boundaries.
gem5-gpu还包括MOESI_hsc的一个分割版本,它为具有独立的CPU和GPU物理地址空间的架构建模。当使用该模型时,CPU和GPU之间的通信需要通过DMA引擎进行显式内存拷贝。
除了提供详细的缓存一致性模型外,gem5-gpu还可以使用gem5提供的任何网络拓扑结构(如网状、环状、横杆)。gem5-gpu的默认配置使用集群拓扑结构,将CPU和GPU划分为两个群集。每个集群的访问都要通过一个共同的互连到目录和内存控制器。
4.4 Application Programming Interface
为了避免 实现或连接现有GPGPU驱动和runtime 的复杂性,gem5-gpu提供了一个纤细(slim)的运行时和驱动仿真。与GPGPU-Sim类似,gem5-gpu runs unmodified GPGPU applications by linking against the gem5-gpu GPGPU runtime library. 当用户应用程序调用GPGPU运行时函数时,gem5 pseudo-instructions execute to make upcalls into the simulator. 这种组织结构具有灵活性和可扩展性,便于添加和测试新功能以及集成新的GPU模型。
5 Performance Validation
我们使用memory microbenchmarks和Rodinia benchmarks的一个子集[4]进行gem5-gpu的验证,重点是全局内存性能。在这些测试中,我们对GPGPU-Sim v3.0.2和gem5-gpu进行配置,以尽可能地模拟NVIDIA GTX 580 discrete GPU system parameters。对于memory access microbenchmarks, including coalescing, cache, off-chip latency and bandwidth,我们发现gem5-gpu的性能在所有情况下都与GTX580独立GPU密切匹配。
Fig. 2 presents a region of interest (ROI) run time comparison for Rodinia benchmarks running in GPGPU-Sim and gem5-gpu normalized to the GTX 580. 除了GPU kernel运行时间外,该图还包括CPU执行和CPU与GPU之间的内存拷贝时间(GPGPU-Sim没有为这些提供计时模型)。在大多数情况下,gem5-gpu的ROI运行时间都在GTX580的22%以内。
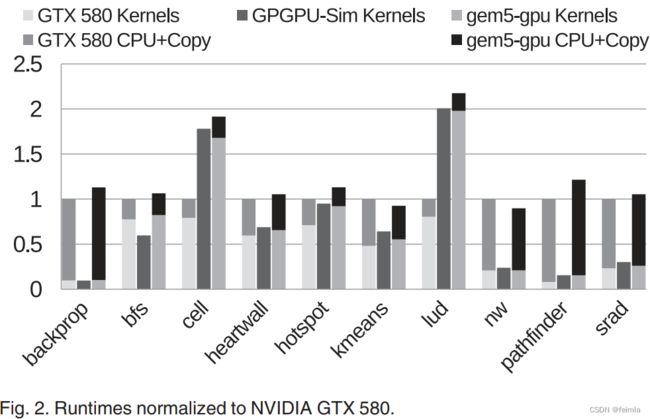
在所有情况下,gem5-gpu的内核运行时间都与独立的GPGPU-Sim高度相关。小的差异归因于不同的内存系统模型。这些与GTX580之间的主要性能差异是由于GPGPU-Sim的CU模型保真度造成的。特别是,诸如cell、lud和pathfinder等基准测试显示,由于GPGPU-Sim CU在寄存器处理方面的延迟升高,以及使用PTX中间表示法而不是目标代码,内核运行时间增加。这些CU建模问题已在GPGPU-Sim的最新版本中得到解决,我们计划在未来将这些变化引入gem5-gpu。
6 Future Work
由于对gem5的改动很小,我们将努力与gem5更紧密地结合,以方便gem5-gpu的使用。此外,随着GPGPU-Sim和gem5的发展,gem5-gpu将利用这些开源项目的新功能和错误修复。
尽管我们发现gem5-gpu是一个有用的工具,在我们研究组内外都有使用,但我们计划解决一些局限性。首先,gem5-gpu目前只限于x86 ISA。我们计划在未来将gem5-gpu扩展到支持ARM ISA。gem5-gpu目前只支持NVIDIA的GPGPU运行时间CUDA。OpenCL与CUDA密切相关,需要对gem5-gpu进行最小的修改以实现对OpenCL的支持。最后,我们计划在未来支持GPGPU-Sim之外的其他GPU模型。gem5-gpu和GPGPU-Sim之间的接口是可扩展的,可以轻松地添加其他GPU模型。
7 Conclusions
在本文中,我们介绍了gem5-gpu的概况,这是一个独特的异构模拟器,它结合了最先进的全系统CPU模拟器和GPGPU模拟器,即gem5和GPGPU-Sim。gem5-gpu为架构师提供了一个灵活的系统,以实验当前和未来的异构架构。
gem5-gpu是开源的,可在gem5-gpu.cs.wisc.edu上获得。更多信息也可以通过加入gem5-gpu邮件列表找到:[email protected]。我们期待着与架构社区合作,改进gem5-gpu,并纳入更多的功能和想法。