大数据技术训练舱:从零开始部署Hadoop3高可用集群(基于CentOS7)
大数据技术的学习任重而道远,很多小伙伴都会卡在诸多的基础问题上,因此作为大数据技术方面的布道者,我将开启一个全新的学习实践与指导计划:
从零开始,一步步由浅入深,系统化的开展大数据技术实践的学习指导,手把手的教会我们怎么应用大数据技术框架,再配合上大数据技术、分布式架构的原理研究、系统优化、框架协作等高级内容,使得我们能更深刻的掌握大数据技术。期待能促进更多的工程师朝着大数据、人工智能、物联网等新一代技术方向前进与突破。
全文一万七千字,三十幅示意图,内容包括:CentOS7集群构建、ZooKeeper集群部署、HDFS HA(高可用)部署、YARN HA(高可用)部署、Hadoop集群验证、MapReduce代码样例验证等。
手机微信打开浏览器网址预览 https://zhuanlan.zhihu.com/p/451266781?
https://zhuanlan.zhihu.com/p/451266781?
目录
1. 准备工作
1) 复制节点构建集群
2) 集群节点间ssh免密登陆
2. ZooKeeper集群部署
1) 上传解压
2) 环境配置
3).测试
4).加入自启动
3. HDFS高可用集群部署
1) 上传解压
2) 环境配置
4. YARN高可用集群配置
5. 结束配置与初始化
1) 配置文件分发
2) 初始化
6. 启动与验证
1) 启动HDFS
2) 启动YARN
3) 验证HDFS
3) 验证YARN
4) 结尾
7. 结束
样例下载
1. 准备工作
前期准备工作包括了
-
CenOS 7虚拟化安装与配置,
-
Java虚拟机的安装,
-
Hadoop相关部署包的下载,
-
Hadoop集群所需基础环境的配置。
第一点CenOS 7虚拟化安装与配置和第二点Java虚拟机的安装:
需要我们参考第一章:大数据技术训练舱——从零开始安装、配置CentOS 7
第三点Hadoop相关部署包的下载:
这就包括了ZooKeeper部署包、Hadoop部署包。ZooKeeper是分布式协调系统,主要用于Hadoop的高可用(HA)协调;
Hadoop部署包括了HDFS(Hadoop分布式文件系统)和YARN(Hadoop资源管理者)。
ZooKeeper最新版3.7下载地址
Hadoop最新版本3.3.1下载地址
第四点Hadoop集群所需基础环境的配置,包括:
1) 复制节点构建集群
2) 集群节点间ssh免密登陆
我们本次集群实践至少需要三个CentOS节点,我们有两种办法实现,第一种办法就是按照中的安装步骤连续安装三个节点;
第二种办法比较简单,需要将第一次安装后的CentOS虚拟化文件再复制两份,然后进行二次修改。
1) 复制节点构建集群
步骤:
(1) MacOS的VMware Fusion会生成一份虚拟机文件,如下图2.1所示,我将“CentOS 7 64 位”文件又复制了两份。Windows的VMware Workstaion则会将很多虚拟机文件放在一个目录里,因此我们需要再复制两份目录。

图2.1
(2) 我们需要对复制过的文件进行IP和主机名修改,MacOS的VMware Fusion直接打开复制后的文件,Windows的VMware Workstaion则打开复制后目录里的.vmx文件。需要注意一点:修改IP之前尽量关闭第一个节点。
我们打开后,VMware会提示“复制”或“移动”,请选择复制。
(3) 系统启动后,通过与第一个节点相同设定root用户名和密码登陆,我们首先修改IP,参考大数据技术训练舱——从零开始安装、配置CentOS 7中第3部分的网络配置,修改ifcfg-ens33配置文件,将新的两个节点的IP从192.168.83.4修改为192.168.83.5和192.168.83.6,
#新增的两个节点修改此IP为192.168.83.5或192.168.83.6
IPADDR=192.168.83.4(4) 然后我们进行主机名的修改,在192.168.83.5节点上执行:
hostnamectl set-hostname datanode-2在192.168.83.6节点上执行:
hostnamectl set-hostname datanode-3各个节点重启后,我们将形成主机/IP的映射关系如下:
192.168.83.4 datanode-1
192.168.83.5 datanode-2
192.168.83.6 datanode-3(5) 请将上面这三条IP/主机名映射关系记录分别追加到这三个节点的/etc/hosts文件里:
vim /etc/hosts如下图2.2所示:

图2.2
2) 集群节点间ssh免密登陆
Hadoop集群具有远程节点控制的需要,因此集群节点之间需要设置为ssh免密登录模式。
步骤:
(1) 通过ssh分别登陆datanode-1、datanode-2、datanode-3,若/root/.ssh目录不存在,创建此目录并修改目录权限属性。
mkdir /root/.ssh
chmod -R 0600 /root/.ssh(2) 登陆datanode-1节点制作公私密钥。生成ssh登陆公私密钥id_rsa、id_rsa.pub,追加authorized_keys,修改目录内的文件权限属性。
ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
chmod 0600 /root/.ssh/id_rsa
chmod 0600 /root/.ssh/authorized_keys(3) 复制id_rsa、authorized_keys到其他节点。
scp /root/.ssh/authorized_keys root@datanode-2:/root/.ssh/
scp /root/.ssh/id_rsa root@datanode-2:/root/.ssh/
scp /root/.ssh/authorized_keys root@datanode-3:/root/.ssh/
scp /root/.ssh/id_rsa root@datanode-3:/root/.ssh/做到这一步,我们准备工作已经完成,我们可以在这三个节点上用ssh datanode-(序号)的命令执行测试,看看互相之间ssh登陆是否已经不需要密码了。 注意只要/root/.ssh目录及下面的密钥没有实现0600权限属性,就无法实现免密登陆。
2. ZooKeeper集群部署
ZooKeeper是Hadoop高可用环境的分布式协调系统,因此我们搭建Hadoop HA集群之前一定先部署ZooKeeper集群。
1) 上传解压
首先我们需要将下载到本机的ZooKeeper部署包上传至这三个节点,Mac系统如下:
scp /Users/你的用户名/Downloads/apache-zookeeper-3.7.0-bin.tar.gz [email protected]:/root
scp /Users/你的用户名/Downloads/apache-zookeeper-3.7.0-bin.tar.gz [email protected]:/root
scp /Users/你的用户名/Downloads/apache-zookeeper-3.7.0-bin.tar.gz [email protected]:/rootWindows平台请参考大数据技术训练舱——从零开始安装、配置CentOS 7中Java环境安装的jdk包上传。
我们选择了这三个节点同时为ZooKeeper的集群节点,分别ssh登陆datanode-1、datanode-2、datanode-3,解压到/opt目录,并做好软链,三节点分别执行:
tar -zxvf /root/apache-zookeeper-3.7.0-bin.tar.gz -C /opt/
ln -s /opt/apache-zookeeper-3.7.0-bin /opt/zookeeper2) 环境配置
登陆datanode-1节点编辑/etc/profile:
vim /etc/profile追加 ZooKeeper bin目录到PATH,实现ZK命令全局可执行:
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin并使其执行生效:
source /etc/profileProfile文件复制给其他两个节点:
scp /etc/profile root@datanode-2:/etc
scp /etc/profile root@datanode-3:/etc生成ZooKeeper配置文件,并编辑:
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
vim /opt/zookeeper/conf/zoo.cfg配置zoo.cfg,ZK数据放在在/home/data/zkdata下,端口为2888,3888
dataDir=/home/data/zkdata
server.1=datanode-1:2888:3888
server.2=datanode-2:2888:3888
server.3=datanode-3:2888:3888如下图2.3蓝框所示:
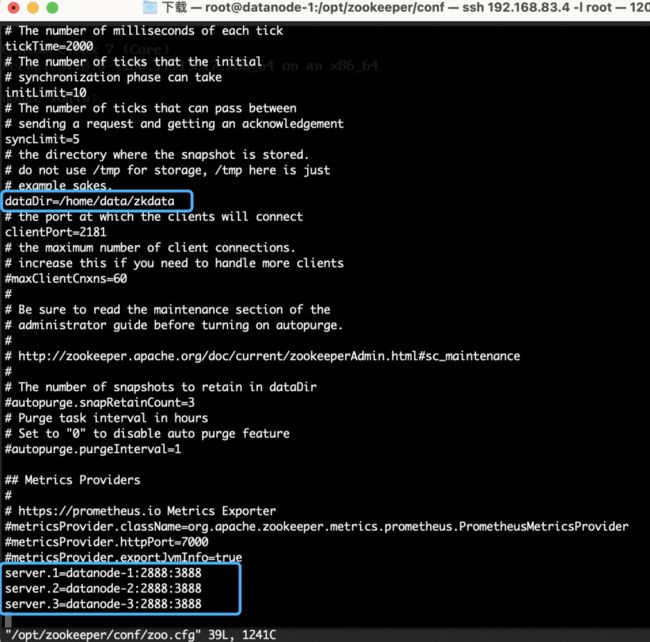
图2.3
分发zoo.cfg到其他节点:
scp /opt/zookeeper/conf/zoo.cfg root@datanode-2:/opt/zookeeper/conf
scp /opt/zookeeper/conf/zoo.cfg root@datanode-3:/opt/zookeeper/conf创建数据目录和集群标识:
mkdir -p /home/data/zkdata
echo "1" > /home/data/zkdata/myid登陆datanode-2,执行上面操作,但集群标识为2
mkdir -p /home/data/zkdata
echo "2" > /home/data/zkdata/myid登陆datanode-3,执行上面操作,但集群标识为3
mkdir -p /home/data/zkdata
echo "3" > /home/data/zkdata/myid分别登陆三个节点,启动zookeeper:
zkServer.sh start3).测试
每台机器jps查看验证zk进程:
jps如下图2.3蓝色框所示:

图2.3
任意节点登陆ZK客户端,验证zk客户端,获取配置路径ZNode信息,并退出:
zkCli.sh
get /zookeeper/config
quit如下图2.4蓝色框所示:

图2.4
我们也可以分别三个节点验证当前ZK节点属于Leader还是Follower,注:ZK集群只有一个Leader:
zkServer.sh status如下图2.5所示,datanode-3节点为ZK集群的Leader节点:
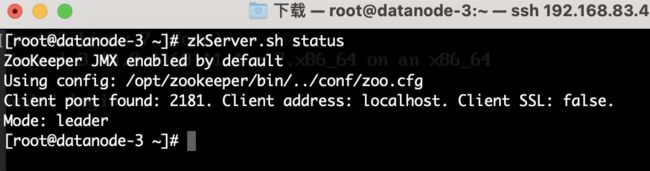
图2.5
4).加入自启动
登陆datanode-1节点增加并编辑systemctl自启动文件:
vim /etc/systemd/system/zookeeper.service编辑内容:
[Unit]
Description=zookeeper.service
After=network.target
ConditionPathExists=/opt/zookeeper/conf/zoo.cfg
[Service]
Type=forking
Environment=JAVA_HOME=/usr/jdk1.8.0_311
User=root
Group=root
ExecStart=/opt/zookeeper/bin/zkServer.sh start
ExecStop=/opt/zookeeper/bin/zkServer.sh stop
[Install]
WantedBy=multi-user.target分发到其他节点:
scp /etc/systemd/system/zookeeper.service root@datanode-2:/etc/systemd/system
scp /etc/systemd/system/zookeeper.service root@datanode-3:/etc/systemd/system分别ssh登陆datanode-1、datanode-2、datanode-3,增加到系统自启动服务,并kill掉ZK进程,该用systemctl启动验证:
systemctl enable zookeeper
jps |grep QuorumPeerMain|awk '{print $1}'|xargs kill -9
systemctl start zookeeper
jps3. HDFS高可用集群部署
HDFS(Hadoop分布式文件系统)是Hadoop生态的数据底座,很多上层大数据技术框架最终会依赖对HDFS的读与写,HDFS是Hadoop部署的关键部分。HDFS为集中式元数据管理,其中主服务NameNode部署可以分为单机版和高可用版(HA)两种,作为以高可靠为目的的大数据存储系统,高可用性非常关键,因此作为训练目的,我们应该掌握高可用版的部署,同样我们也要面对高可用的部署复杂度。
1) 上传解压
首先我们需要将下载到本机的Hadoop部署包上传至这三个节点,Mac系统如下:
scp /Users/你的用户名/Downloads/hadoop-3.3.1.tar.gz [email protected]:/root
scp /Users/你的用户名/Downloads/hadoop-3.3.1.tar.gz [email protected]:/root
scp /Users/你的用户名/Downloads/hadoop-3.3.1.tar.gz [email protected]:/root我们选择了这三个节点为HDFS的集群节点,通过ssh分别登陆datanode-1、datanode-2、datanode-3,解压到/opt目录,并做好软链,三节点分别执行:
tar -zxvf hadoop-3.3.1.tar.gz -C /opt
ln -s /opt/hadoop-3.3.1 /opt/hadoop2) 环境配置
登陆datanode-1节点编辑/etc/profile:
vim /etc/profile追加 Haddop bin目录到PATH,实现Hadoop命令全局可执行:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin并使其执行生效:
source /etc/profile将profile分发到其他节点:
scp /etc/profile root@datanode-2:/etc
scp /etc/profile root@datanode-3:/etc编辑hadoop环境变量
vim /opt/hadoop/etc/hadoop/hadoop-env.shvi非编辑模式,查询关键字“export JAVA_HOME”,输入下面关键字、回车、查询:
/export JAVA_HOME查询到"#export JAVA_HOME=",vi进入编辑模式取消注释,修改为:
export JAVA_HOME=/usr/jdk1.8.0_311vi非编辑模式,查询关键字“export HADOOP_HOME”,输入下面关键字、回车、查询:
/export HADOOP_HOME查询到“#export HADOOP_HOME=”,vi进入编辑模式取消注释,修改为:
export HADOOP_HOME=/opt/hadoop编辑HDFS参数配置文件:
vim /opt/hadoop/etc/hadoop/hdfs-site.xml在
dfs.nameservices
fsnss
dfs.permissions.enabled
false
dfs.ha.namenodes.fsnss
nn1,nn2
dfs.namenode.rpc-address.fsnss.nn1
datanode-1:9820
dfs.namenode.rpc-address.fsnss.nn2
datanode-2:9820
dfs.namenode.http-address.fsnss.nn1
datanode-1:9870
dfs.namenode.http-address.fsnss.nn2
datanode-2:9870
dfs.namenode.shared.edits.dir
qjournal://datanode-1:8485;datanode-2:8485;datanode-3:8485/fsnss
dfs.client.failover.proxy.provider.fsnss
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/home/data/dfs/journal/node/local/data
dfs.ha.automatic-failover.enabled
true
编辑core-site.xml
vim /opt/hadoop/etc/hadoop/core-site.xml在
fs.defaultFS
hdfs://fsnss
hadoop.tmp.dir
/home/data/dfs/hadoop/
ha.zookeeper.quorum
datanode-1:2181,datanode-2:2181,datanode-3:2181
4. YARN高可用集群配置
YARN是Hadoop资源管理和和作业调度的核心组件,是MapReduce V2框架的主要组成部分。
按照高可用计算架构部署,datanode-1、datnode-2两个节点组成ResourceManager(RM) HA,负责整个集群的资源管理和调度。
编辑yarn-site.xml
vim /opt/hadoop/etc/hadoop/yarn-site.xml在
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
mycls
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
datanode-1
yarn.resourcemanager.hostname.rm2
datanode-2
yarn.resourcemanager.webapp.address.rm1
datanode-1:8088
yarn.resourcemanager.webapp.address.rm2
datanode-2:8088
yarn.resourcemanager.zk-address
datanode-1:2181,datanode-2:2181,datanode-3:2181
yarn.nodemanager.resource.detect-hardware-capabilities
true
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/user/container/logs
mapreduce.map.memory.mb
1536
编辑mapred-site.xml:
vim /opt/hadoop/etc/hadoop/mapred-site.xml在
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
datanode-1:10020
mapreduce.jobhistory.webapp.address
datanode-1:19888
mapreduce.jobhistory.intermediate-done-dir
/mr-history/tmp
mapreduce.jobhistory.done-dir
/mr-history/done
5. 结束配置与初始化
1) 配置文件分发
scp /opt/hadoop/etc/hadoop/hadoop-env.sh root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/hadoop-env.sh root@datanode-3:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/hdfs-site.xml root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/hdfs-site.xml root@datanode-3:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/core-site.xml root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/core-site.xml root@datanode-3:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@datanode-3:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/mapred-site.xml root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/mapred-site.xml root@datanode-3:/opt/hadoop/etc/hadoop2) 初始化
(1) 登陆datanode-1,连接ZooKeeper,格式化ZKFC(ZK故障转移控制):
hdfs zkfc -formatZK下图2.6 日志打印中的蓝色框代表初始化成功。
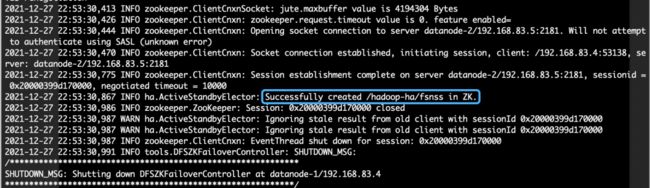
图2.6
登陆ZooKeeper,检查hadoop-ha节点是否创建:
zkCli.sh
ls /hadoop-ha
quit下图2.7 ZooKeeper中创建的ZNode节点/hadoop-ha/fsnss
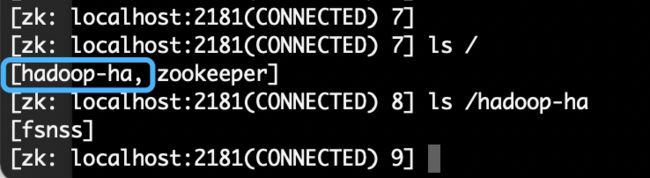
图2.7
通过ssh分别登陆datanode-1、datanode-2、datanode-3,启动journalnode:
hdfs --daemon start journalnode通过jps命令,查看journalnode节点进程是否启动正常,如下图2.8所示:

图2.8
重返datanode-1节点,格式化namenode nn1:
hdfs namenode -format nn1如下图2.9所示,代表格式化成功:
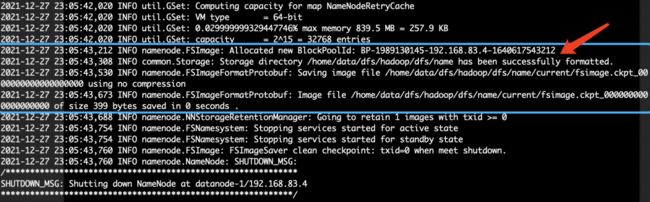
图2.9
启动namenode nn1,准备namenode nn2格式化同步:
hdfs --daemon start namenode通过jps命令,查看namenode节点进程是否启动正常,如下图2.10所示:

图2.10
登陆datanode-2节点,执行namenode nn2格式化同步:
hdfs namenode -bootstrapStandby如下图2.11所示,代表格式化同步成功:
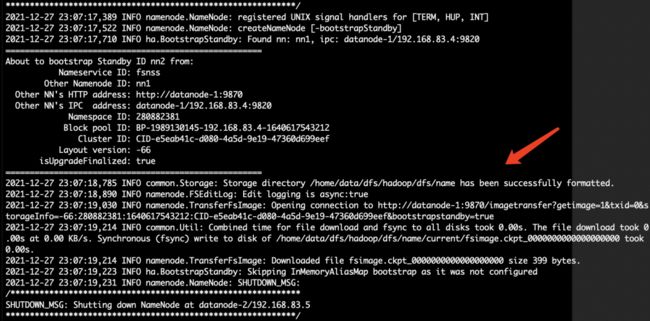
图2.11
启动namenode nn2,组成高可用:
hdfs --daemon start namenode通过jps命令,查看namenode节点进程是否启动正常,如下图2.12所示:
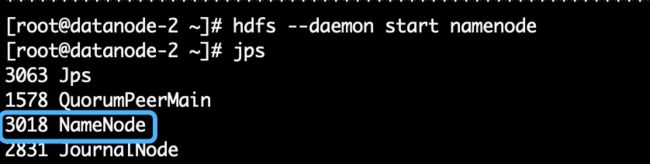
图2.12
我们查看一下高可用的状态:
hdfs haadmin -getAllServiceState这时候,我们得到的是nn1、nn2都属于准备状态:
datanode-1:9820 standby
datanode-2:9820 standby 我们将namenode nn1变为激活状态成为主服务:
hdfs haadmin -transitionToActive --forcemanual nn1如下图2.13所示,执行过程选择‘Y’,然后再查看一下高可用状态,我们会发现nn1已经变为active状态。
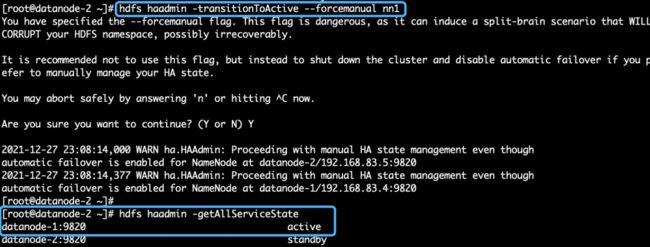
图2.13
我们打开客户端浏览器,输入nn1的地址(谁处于Active状态就输入谁的IP地址):
http://192.168.83.4:9870就能看到HDFS管理界面,如下图2.14所示,只不过这时候还没有任何DataNode节点:
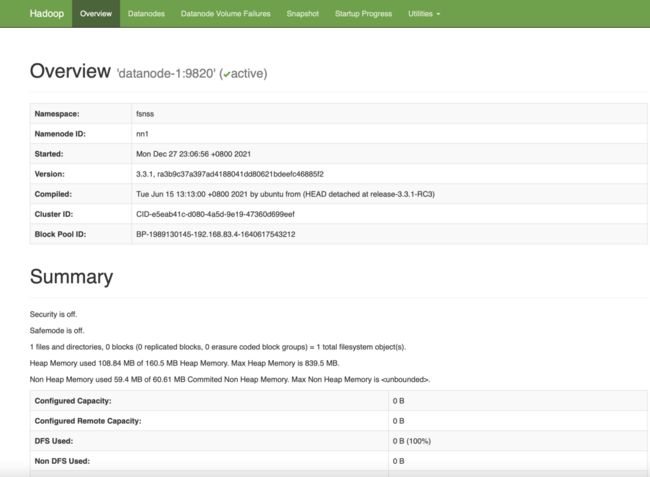
图2.14
重返datanode-1节点,编辑works列表:
vim /opt/hadoop/etc/hadoop/workers删除localhost,增加这三个节点为DataNode节点:
datanode-1
datanode-2
datanode-3编辑start-dfs.sh、stop-dfs.sh:
vim /opt/hadoop/sbin/start-dfs.shvim /opt/hadoop/sbin/stop-dfs.sh在第一行之后处加入root和Hadoop用户的绑定:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root如下图2.15所示:
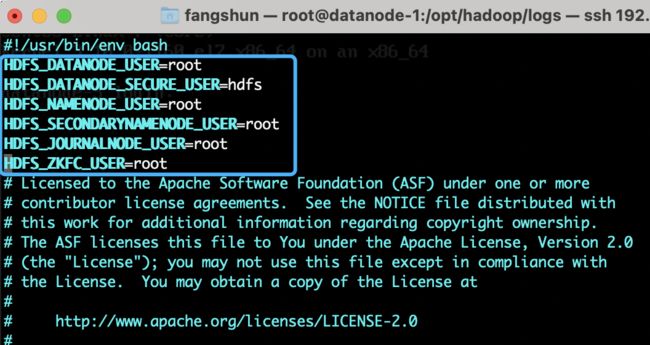
图2.15
编辑start-yarn.sh、stop-yarn.sh:
vim /opt/hadoop/sbin/start-yarn.shvim /opt/hadoop/sbin/stop-yarn.sh在第一行之后处加入root和Hadoop用户的绑定:
YARN_RESOURCEMANAGER_USER=root
HADOOP_USER_NAME=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root如下图2.16所示:
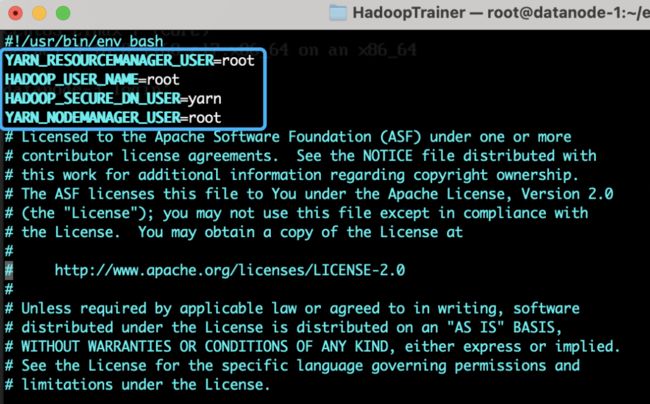
图2.16
配置文件分发:
scp /opt/hadoop/etc/hadoop/workers root@datanode-2:/opt/hadoop/etc/hadoop
scp /opt/hadoop/etc/hadoop/workers root@datanode-3:/opt/hadoop/etc/hadoop
scp /opt/hadoop/sbin/start-dfs.sh root@datanode-2:/opt/hadoop/sbin
scp /opt/hadoop/sbin/start-dfs.sh root@datanode-3:/opt/hadoop/sbin
scp /opt/hadoop/sbin/stop-dfs.sh root@datanode-2:/opt/hadoop/sbin
scp /opt/hadoop/sbin/stop-dfs.sh root@datanode-3:/opt/hadoop/sbin
scp /opt/hadoop/sbin/start-yarn.sh root@datanode-2:/opt/hadoop/sbin
scp /opt/hadoop/sbin/start-yarn.sh root@datanode-3:/opt/hadoop/sbin
scp /opt/hadoop/sbin/stop-yarn.sh root@datanode-2:/opt/hadoop/sbin
scp /opt/hadoop/sbin/stop-yarn.sh root@datanode-3:/opt/hadoop/sbin通过ssh分别登陆datanode-1、datanode-2、datanode-3,jps命令显示的Java进程中,除了保留ZooKeeper进程之外,其他全部Kill:
jps |grep -v 'QuorumPeerMain\|Jps'|awk '{print $1}'|xargs kill -96. 启动与验证
1) 启动HDFS
登陆datanode-1节点,执行HDFS集群启动:
start-dfs.sh如下图2.17所示,NameNode高可用[datanode-1、datanode-2],Journal集群[datanode-1、datanode-2、datanode-3],ZKFC服务[datanode-1、datanode-2]全部正常启动。
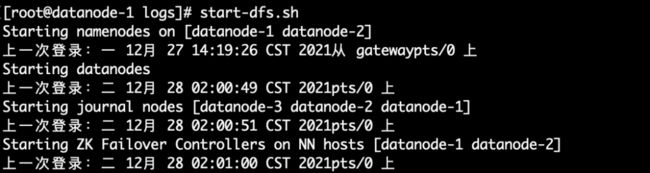
图2.17
我们分别登陆三个节点,用jps验证包括DataNode进程是否正常启动,如下图2.18所示:
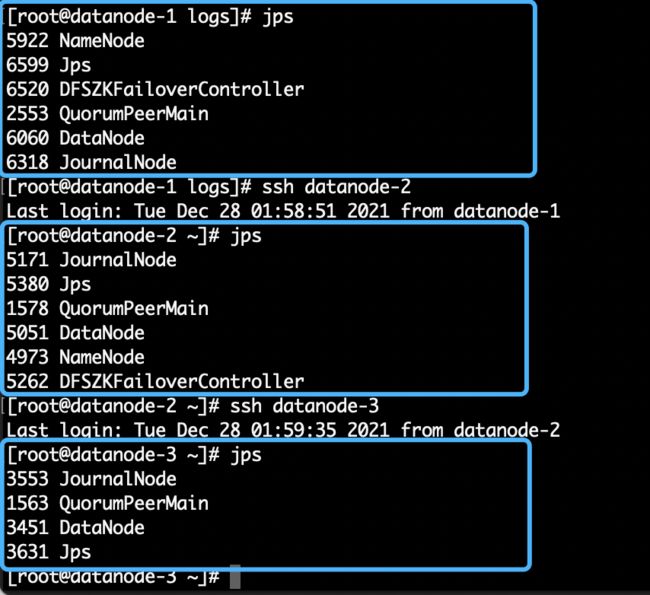
图2.18
HDFS进程列表:
| datanode-1 | NameNode、DFSZKFailoverController、QuorumPeerMain、DataNode、JournalNode |
| datanode-2 | NameNode、DFSZKFailoverController、QuorumPeerMain、DataNode、JournalNode |
| datanode-3 | QuorumPeerMain、DataNode、JournalNode |
2) 启动YARN
重返datanode-1节点,执行YARN集群启动:
start-yarn.sh 如下图2.19所示,ResourceManager高可用[datanode-1、datanode-2],各个节点NodeManager正常启动:
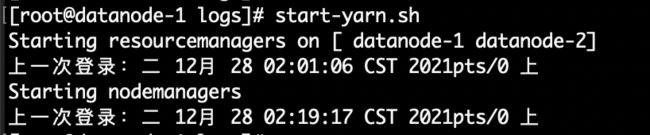
图2.19
我们分别登陆三个节点,用jps验证,如下图2.20所示:
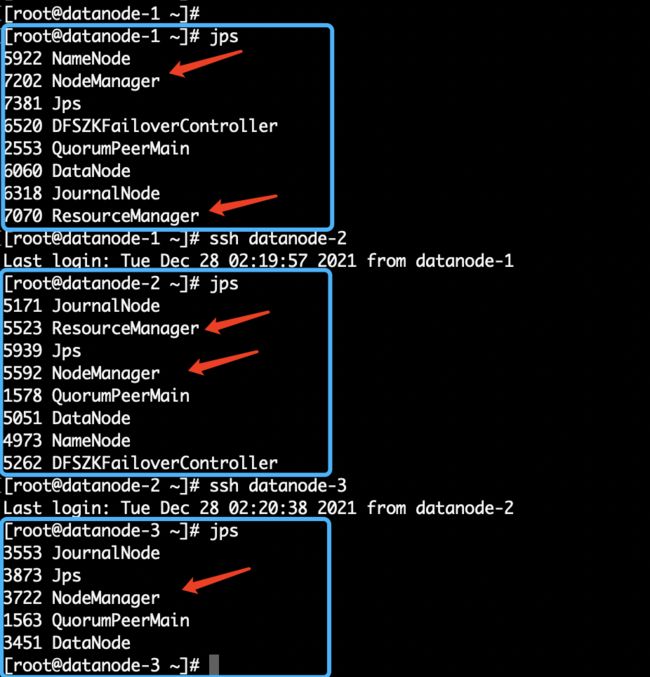
图2.20
启动工作任务记录服务:
mapred --daemon start historyserver在datanode-1节点启动了JobHistoryServer进程,如下图2.21所示:

图2.21
至此,Hadoop安装已经结束。
3) 验证HDFS
我们做一个简单的HDFS验证:
hdfs dfs -mkdir /sdk
hdfs dfs -put jdk-8u311-linux-x64.tar.gz /sdk
hdfs dfs -ls /sdk我们为HDFS根目录创建了sdk子目录,并上传JDK包,查看sdk目录,如下图2.22所示:
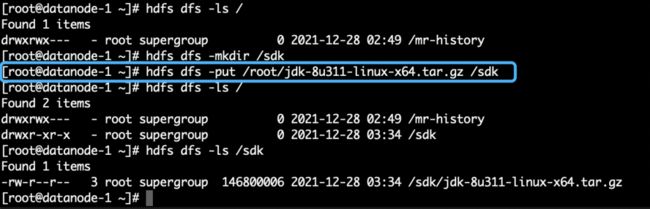
图2.22
我们再看看HDFS界面管理端,如下图2.23是sdk上传的目录:
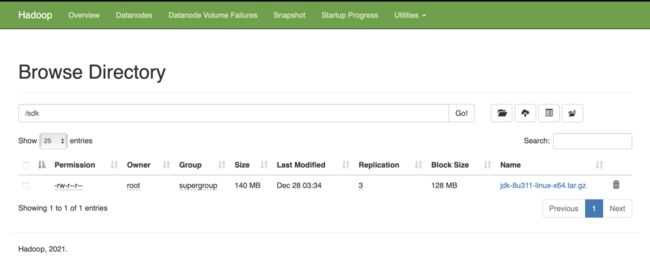
图2.23
下图2.24是HDFS管理端监控的三个数据节点[datanode-1、datanode-2、datanode-3]。
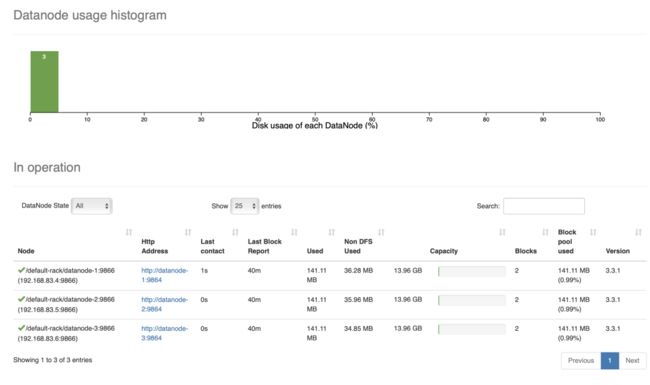
图2.24
3) 验证YARN
我们编写一个MapReduce样例程序来验证Yarn系统是否正常。
我们的目标是:将一组三份存有数字的乱序文件通过MapRedue程序排序计数后输出,特点是三个Map任务的输出经过混洗排序后,通过自定义分区划分的范围,分别交给三个Reduce进行计数,并输出给三个排序过的文件。
分区划分:小于数字500一组、大于等于500并小于1000一组,大于等于1000一组。
如下图2.25所示的三份乱序文件
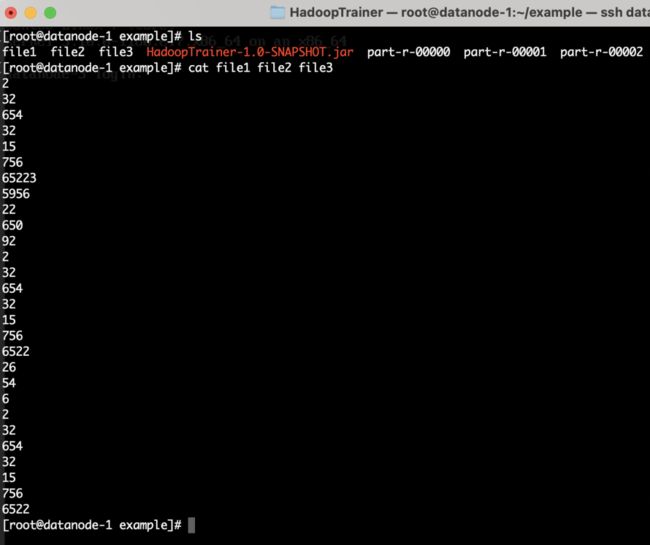
图2.25
如下图2.26所示,MapReduce排序后的三份计数后的文件。
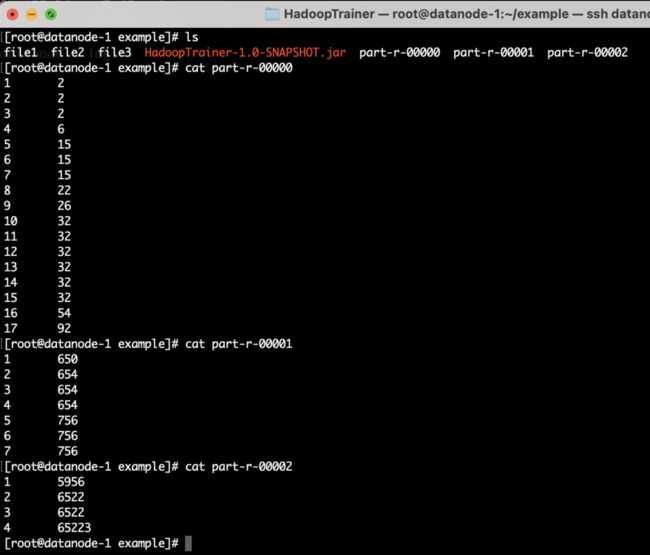
图2.26
我们先将三份乱序文件上传到HDFS:
hdfs dfs -put file* /example/simple1/sort/input
hdfs dfs -ls /example/simple1/sort/input如下图2.27所示
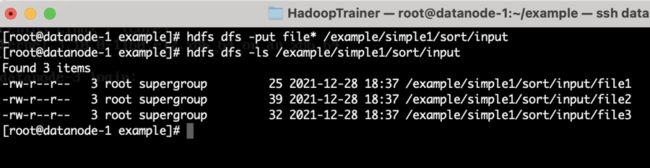
图2.27
我们执行打包好的MR测试程序:
hadoop jar HadoopTrainer-1.0-SNAPSHOT.jar 如下图2.28所示,展示了MR整个执行日志输出过程,红色箭头指向的任务为:
job: job_1640683809954_0003,我们可以在Yarn管理端查看此任务日志。
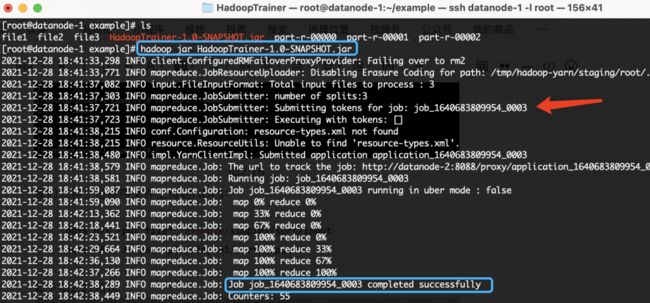
图2.28
我们从图中可以看到Map任务为3个,Reduce任务为3个。
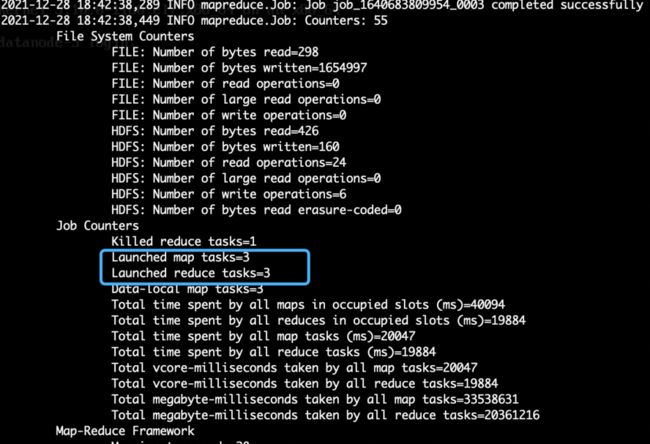
图2.29
客户端打开Yarn管理端需要将IP和节点名加入到host里面,Mac系统:
sudo vi /etc/hosts加入IP节点名映射:
192.168.83.4 datanode-1
192.168.83.5 datanode-2
192.168.83.6 datanode-3浏览器输入Yarn管理端地址,以下两个地址均可,Yarn启动后会确定其中一个为活动地址,若输入的是HA备份地址,会重定向到活动地址:
http://datanode-2:8088/cluster
http://datanode-1:8088/cluster如下图2.30所示,已完成任务列表中蓝色框标注的就是刚才执行的任务job_1640683809954_0003。
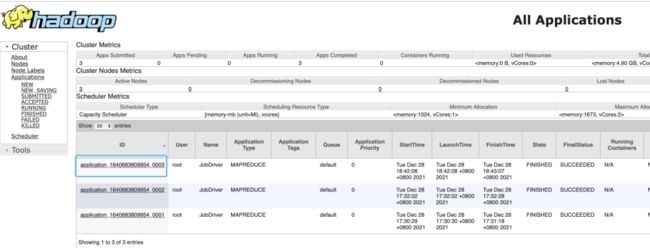
图2.30
4) 结尾
ZooKeeper集群已经加入系统自启动,方便反复开关OS的学习场景。
Hadoop启动顺序:
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserverHadoop停止顺序:
stop-yarn.sh
stop-dfs.sh
jps |grep JobHistoryServer|awk '{print $1}'|xargs kill -97. 结束
整个Hadoop高可用集群及相关系统的部署、配置和验证就正式结束了。Hadoop集群作为当今大数据技术的基础数据底座非常重要,尽管部署过程非常复杂,步骤特别多,不过本文尽可能对每一步都做到细致入微,目的是让初学者手把手的照着做,也能正确部署好Hadoop平台,为后续的大数据技术学习,解决一入门就遇到这个高门槛。
样例下载
链接: https://pan.baidu.com/s/1LH-seaDDICeRyuz-wNA3Tg 密码: tvcb
本文章由公众号「守护石 」出品,版权所有,未经许可,禁止转载