熬夜三晚之深度解析DuckDB MetaPipeline
深度解析DuckDB MetaPipeline
深度解析DuckDB MetaPipeline1.导语 2.基础理论 3.HashJoin深度解析 3.1 RESULT_COLLECTOR 3.2 PROJECTION 3.3 HASH_JOIN 4.Ready 4.1 翻转 4.2 MetaPipeline与pipeline 5.汇总
1.导语
DuckDB 是一个高性能的分析型数据库系统。它旨在快速、可靠且易于使用。
最近对DuckDB的代码比较感兴趣,就打算读一下看看,这个是一个C++开源项目,非常适合新手学习,特别是从事数据库行业的伙伴。
本节将会深度解析DuckDB的MetaPipeline,以实际两个表join为例
例如:
SELECT name, score FROM student st INNER JOIN score s ON st.id = s.stu_id;这个SQL最后的plan为:
➜ debug git:(master) ./duckdb stu
v0.8.1-dev416 9d5158ccd2
Enter ".help" for usage hints.
D EXPLAIN SELECT name, score FROM student st INNER JOIN score s ON st.id = s.stu_id;
┌─────────────────────────────┐
│┌───────────────────────────┐│
││ Physical Plan ││
│└───────────────────────────┘│
└─────────────────────────────┘
┌───────────────────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id ├──────────────┐
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │ │
│ EC: 4 │ │
│ Cost: 4 │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ SEQ_SCAN ││ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score ││ student │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id ││ id │
│ score ││ name │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 ││ EC: 3 │
└───────────────────────────┘└───────────────────────────┘在开始本篇文章之前,先问几个问题:
MetaPipeline到底发生了什么?
上面计划有几个Plan?
什么是Pipeline?
什么是MetaPipeline?
好了,进入正文。
2.基础理论
MetaPipeline 表示一组都具有相同Sink的Pipeline。
先讲一些预备知识:对于DuckDB,跟arrow类似,plan基本都长这个样子:
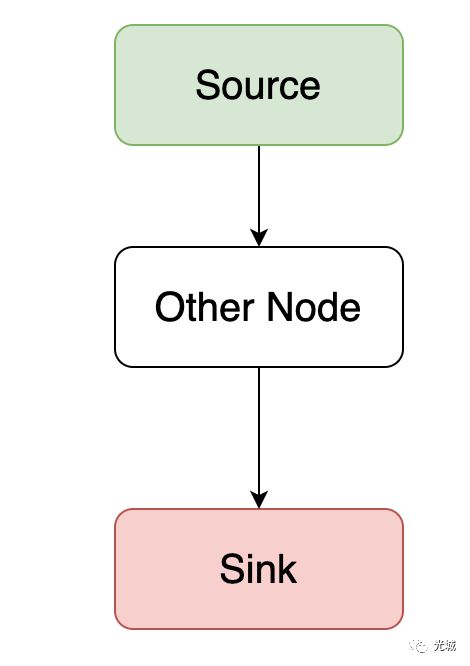
Source为输入,Sink为输出,Other Node就是其他节点,当然树不止长这个样子,还可以是多个source,像这样的一张图串起来多个节点就是一个Pipeline。
那么对于一个复杂的查询计划,Pipeline通常是多个,而且还存在一定的依赖关系,例如hashjoin节点必须依赖build端的pipeline产生的数据才可以,所以就有个MetaPipeline用于构建多个Pipeline依赖关系,在最后节点执行时就只有Pipeline了。
3.HashJoin深度解析
对于像这样的查询计划,发生了什么过程呢?构建了几个Pipeline?build端与probe端怎么构建的?
➜ debug git:(master) ./duckdb stu
v0.8.1-dev416 9d5158ccd2
Enter ".help" for usage hints.
D EXPLAIN SELECT name, score FROM student st INNER JOIN score s ON st.id = s.stu_id;
┌─────────────────────────────┐
│┌───────────────────────────┐│
││ Physical Plan ││
│└───────────────────────────┘│
└─────────────────────────────┘
┌───────────────────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id ├──────────────┐
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │ │
│ EC: 4 │ │
│ Cost: 4 │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ SEQ_SCAN ││ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score ││ student │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id ││ id │
│ score ││ name │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 ││ EC: 3 │
└───────────────────────────┘└───────────────────────────┘入口InitializeInternal先构建了一个MetaPipeline,其sink为NULL,随后使用这个meta_pipeline来继续构建pipeline。
auto root_pipeline = make_shared(*this, state, nullptr);
root_pipeline->Build(*physical_plan); 3.1 RESULT_COLLECTOR
Build会到用到对应的operator的BuildPipelines,physical_plan第一个operator为RESULT_COLLECTOR,于是调用PhysicalResultCollector::BuildPipelines,PhysicalResultCollector为PhysicalOperator的子类。
void PhysicalResultCollector::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline)当前pipeline会变为:也就是把当前operator作为current的source。
┌───────────────────────────┐
│ NULL │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ RESULT_COLLECTOR │ -> source
└───────────────────────────┘同时meta_pipeline还创建了一个child_meta_pipeline,sink节点为当前节点,即 RESULT_COLLECTOR
auto &child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, *this);┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└───────────────────────────┘随后使用child_meta_pipeline继续构建。
child_meta_pipeline.Build(plan);3.2 PROJECTION
继续往下是PhysicalProjection,这个并没有重写基类的BuildPipelines,于是调用:
void PhysicalOperator::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline)此时添加到当前pipeline的operators中,得到:
┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │ -> operators[0]
│ score │
└───────────────────────────┘继续构建它的子operator。
children[0]->BuildPipelines(current, meta_pipeline);3.3 HASH_JOIN
此时到了hash join:
void PhysicalJoin::BuildJoinPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline, PhysicalOperator &op)保存一份pipeline,后面用
vector> pipelines_so_far;
meta_pipeline.GetPipelines(pipelines_so_far, false);
auto last_pipeline = pipelines_so_far.back().get(); 创建一个子MetaPipeline,用于构建build端的hash join。
auto &child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, op);
child_meta_pipeline.Build(*op.children[1]);此时得到:
┌───────────────────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │ -> sink
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ student │ -> source
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ id │
│ name │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 3 │
└───────────────────────────┘probe端继续构建,这个BuildPipelines会继续往下调用构建,最后调用到tablescan的构建,由于tablescan并没有重写基类的BuildPipelines,所以还是使基类的,那边是设置source。
op.children[0]->BuildPipelines(current, meta_pipeline);于是得到:
┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │ -> operators[0]
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │ -> operators[1]
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id │ -> source
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
└───────────────────────────┘最后,使用步骤1保存的pipeline,创建了一个child metapipeline。
meta_pipeline.CreateChildPipeline(current, op, last_pipeline);得到:
┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │ -> operators[0]
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │ -> source
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└───────────────────────────┘CreateChildPipeline会为当前pipeline添加依赖关系,对于当前metapipeline,里面有两个pipeline:
pipelines[0] -> probe 端
pipelines[1] -> child pipelineCreateChildPipeline会去调用函数AddDependenciesFrom,表示继续添加依赖关系,从start开始,继续往dependencies添加。
假设当前metapipeline有n个pipeline, 图中表示pipelines[s] 为起始pipeline,pipelines[m]dependant,其实就是end,那么会把这中间的所有pipeline添加到当前dependant依赖数组里面。
pipelines[0]
....
pipelines[s] ---> start
.....
pipelines[m] ---> dependant
pipelines[n-1]结构为:
unordered_map> dependencies; 完成依赖关系后:
pipelines[m] : [pipelines[s]......pipelines[m-1]]由于这里的s = 0, m = 1,所以依赖关系就只有:
pipelines[1] : [ pipelines[0] ]pipelines[1] 就是child_pipeline。
即:
child_pipeline : [probe pipeline]小结1:meta_pipeline.CreateChildMetaPipeline
meta_pipeline.children会添加一个MetaPipeline(会创建一个新的pipeline),这个新的MetaPipeline的sink节点为当前operator。
维护当前pipeline与新pipeline的依赖关系。current.dependencies会添加这个新的pipeline,新的pipeline的parents会添加current。
// current、new_pipeline
current.dependencies.push_back(new_pipeline);
new_pipeline.parents.push_back(current);4.Ready
4.1 翻转
经过上面的执行,InitializeInternal Build就搞定了,此时便进入Ready阶段。
假设以上面hashjoin probe 的pipeline为例:
[result->project->hashjoin->scan] 那么source 为scan, sink为 result,operators[0] = project ,operators[1] = hashjoin。
pipeline的Ready会把这个operators顺序变为:[hashjoin, project]
ready前
┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │ -> operators[0]
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │ -> operators[1]
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id │ -> source
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
└───────────────────────────┘ready后
┌───────────────────────────┐
│ RESULT_COLLECTOR │ -> sink
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │ -> operators[0]
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │ -> operators[1]
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id │ -> source
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
└───────────────────────────┘4.2 MetaPipeline与pipeline
另外,在这个阶段,我们可以看到Build之后的MetaPipelie与pipeline的关系,分别如下。
第一个MetaPipeline
{pipelines[1], children[1]}
┌───────────────────────────┐
│ RESULT_COLLECTOR │
└───────────────────────────┘children MetaPipeline
上面的child MetaPipeline
{pipelines[2], children[1]}
需要注意Ready()之后除了operators逆序,可以看到operations数组顺序发生了变化。
pipelines[0]
┌───────────────────────────┐
│ RESULT_COLLECTOR │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
└───────────────────────────┘pipeline[1]
┌───────────────────────────┐
│ RESULT_COLLECTOR │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└───────────────────────────┘children MetaPipeline
上面child MetaPipeline
{pipelines[1], children[0]}
pipeline[0]
┌───────────────────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ student │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ id │
│ name │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 3 │
└───────────────────────────┘5.汇总
最后会从root_pipeline(这个是metapipeline)开始,递归所有metapipeline的pipelines数组,汇总得到打平后的pipelines。
root_pipeline->GetPipelines(pipelines, true);最终得到:
(lldb) p pipelines
(duckdb::vector, true>) $150 = {
std::__1::vector, std::__1::allocator > > = size=4 {
[0] = std::__1::shared_ptr::element_type @ 0x00006110001bf5d8 strong=3 weak=3 {
__ptr_ = 0x00006110001bf5d8
}
[1] = std::__1::shared_ptr::element_type @ 0x00006110001bf858 strong=2 weak=4 {
__ptr_ = 0x00006110001bf858
}
[2] = std::__1::shared_ptr::element_type @ 0x00006110001bfc18 strong=2 weak=2 {
__ptr_ = 0x00006110001bfc18
}
[3] = std::__1::shared_ptr::element_type @ 0x00006110001bfad8 strong=2 weak=3 {
__ptr_ = 0x00006110001bfad8
}
}
} 好了,相信通过本节的分析,你会对Pipeline与MetaPipeline有一个深刻的理解,本节完~