贝叶斯分类器(Python实现+详细完整源码和原理)
在概率和统计学领域,贝叶斯理论基于对某一事件证据的认识来预测该事件的发生概率,
由结果推测原因的概率大小
首先,理解这个公式的前提是理解条件概率,因此先复习条件概率。
P(A|B)=P(AB)/P(B)
贝叶斯公式:
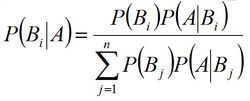
在机器学习领域,贝叶斯分类器是基于贝叶斯理论并假设各特征相互独立的分类方法,
基本方法是:使用特征向量来表征某个实体,并在该实体上绑定一个标签来代表其所属的类别。
优点:只需要极少数的训练数据,就可以建立起分类所需要的所有参数
抽象而言就是:贝叶斯分类器就是条件概率:给定一个实体,求解这个实体属于某一类的概率,这个实体用
一个长度为n的向量来表示,向量中的每一个元素表示相互独立的特征值的量。
=====================================================================================
以下是对水果分类的python代码实现:
| 类别 | 较长 | 不长 | 甜 | 不甜 | 黄色 | 不是黄色 | 总数 |
| 香蕉 | 400 | 100 | 350 | 150 | 450 | 50 | 500 |
| 橘子 | 0 | 300 | 150 | 150 | 300 | 0 | 300 |
| 其他水果 | 100 | 100 | 150 | 50 | 50 | 150 | 200 |
| 总数 | 500 | 500 | 650 | 350 | 800 | 200 | 1000 |
python文件结构:都在一个包下(Bayes)

bayes_classfier.py
-
#!/usr/bin/env python
-
# encoding: utf-8
-
"""
-
@Company:华中科技大学电气学院聚变与等离子研究所
-
@version: V1.0
-
@author: YEXIN
-
@contact: [email protected] 2018--2020
-
@software: PyCharm
-
@file: bayes_classfier.py
-
@time: 2018/8/16 16:49
-
@Desc:贝叶斯分类器
-
"""
-
###贝叶斯分类器源码
-
-
####训练数据集---->合适参数
-
datasets = {
'banala':{
'long':
400,
'not_long':
100,
'sweet':
350,
'not_sweet':
150,
'yellow':
450,
'not_yellow':
50},
-
'orange':{
'long':
0,
'not_long':
300,
'sweet':
150,
'not_sweet':
150,
'yellow':
300,
'not_yellow':
0},
-
'other_fruit':{
'long':
100,
'not_long':
100,
'sweet':
150,
'not_sweet':
50,
'yellow':
50,
'not_yellow':
150}
-
}
-
-
-
def count_total(data):
-
'''计算各种水果的总数
-
return {‘banala’:500 ...}'''
-
count = {}
-
total =
0
-
for fruit
in data:
-
'''因为水果要么甜要么不甜,可以用 这两种特征来统计总数'''
-
count[fruit] = data[fruit][
'sweet'] + data[fruit][
'not_sweet']
-
total += count[fruit]
-
return count,total
-
-
#categories,simpleTotal = count_total(datasets)
-
#print(categories,simpleTotal)
-
###########################################################
-
-
def cal_base_rates(data):
-
'''计算各种水果的先验概率
-
return {‘banala’:0.5 ...}'''
-
categories,total = count_total(data)
-
cal_base_rates = {}
-
for label
in categories:
-
priori_prob = categories[label]/total
-
cal_base_rates[label] = priori_prob
-
return cal_base_rates
-
-
#Prio = cal_base_rates(datasets)
-
#print(Prio)
-
############################################################
-
-
def likelihold_prob(data):
-
'''计算各个特征值在已知水果下的概率(likelihood probabilities)
-
{'banala':{'long':0.8}...}'''
-
count,_ = count_total(data)
-
likelihold = {}
-
for fruit
in data:
-
'''创建一个临时的字典,临时存储各个特征值的概率'''
-
attr_prob = {}
-
for attr
in data[fruit]:
-
#计算各个特征值在已知水果下的概率
-
attr_prob[attr] = data[fruit][attr]/count[fruit]
-
likelihold[fruit] = attr_prob
-
return likelihold
-
-
#LikeHold = likelihold_prob(datasets)
-
#print(LikeHold)
-
############################################################
-
-
def evidence_prob(data):
-
'''计算特征的概率对分类结果的影响
-
return {'long':50%...}'''
-
#水果的所有特征
-
attrs = list(data[
'banala'].keys())
-
count,total = count_total(data)
-
evidence_prob = {}
-
-
#计算各种特征的概率
-
for attr
in attrs:
-
attr_total =
0
-
for fruit
in data:
-
attr_total += data[fruit][attr]
-
evidence_prob[attr] = attr_total/total
-
return evidence_prob
-
-
#Evidence_prob = evidence_prob(datasets)
-
#print(Evidence_prob)
-
##########################################################
-
#以上是训练数据用到的函数,即将数据转化为代码计算概率
-
##########################################################
-
-
class navie_bayes_classifier:
-
'''初始化贝叶斯分类器,实例化时会调用__init__函数'''
-
def __init__(self,data=datasets):
-
self._data = datasets
-
self._labels = [key
for key
in self._data.keys()]
-
self._priori_prob = cal_base_rates(self._data)
-
self._likelihold_prob = likelihold_prob(self._data)
-
self._evidence_prob = evidence_prob(self._data)
-
-
#下面的函数可以直接调用上面类中定义的变量
-
def get_label(self,length,sweetness,color):
-
'''获取某一组特征值的类别'''
-
self._attrs = [length,sweetness,color]
-
res = {}
-
for label
in self._labels:
-
prob = self._priori_prob[label]
#取某水果占比率
-
#print("各个水果的占比率:",prob)
-
for attr
in self._attrs:
-
#单个水果的某个特征概率除以总的某个特征概率 再乘以某水果占比率
-
prob*=self._likelihold_prob[label][attr]/self._evidence_prob[attr]
-
#print(prob)
-
res[label] = prob
-
-
#print(res)
-
return res
-
============================================================================================
generate_attires.py
-
#!/usr/bin/env python
-
# encoding: utf-8
-
"""
-
@Company:华中科技大学电气学院聚变与等离子研究所
-
@version: V1.0
-
@author: YEXIN
-
@contact: [email protected] 2018--2020
-
@software: PyCharm
-
@file: generate_attires.py
-
@time: 2018/8/17 13:43
-
@Desc:产生测试数据集来测试贝叶斯分类器的预测能力
-
"""
-
import random
-
def random_attr(pair):
-
#生成0-1之间的随机数
-
return pair[random.randint(
0,
1)]
-
-
def gen_attrs():
-
#特征值的取值集合
-
sets = [(
'long',
'not_long'),(
'sweet',
'not_sweet'),(
'yellow',
'not_yellow')]
-
test_datasets = []
-
for i
in range(
20):
-
#使用map函数来生成一组特征值
-
test_datasets.append(list(map(random_attr,sets)))
-
return test_datasets
-
#print(gen_attrs())
======================================================================================
classfication.py
-
#!/usr/bin/env python
-
# encoding: utf-8
-
"""
-
@Company:华中科技大学电气学院聚变与等离子研究所
-
@version: V1.0
-
@author: YEXIN
-
@contact: [email protected] 2018--2020
-
@software: PyCharm
-
@file: classfication.py
-
@time: 2018/8/17 13:55
-
@Desc:使用贝叶斯分类器对测试结果进行分类
-
"""
-
import operator
-
import bayes_classfier
-
import generate_attires
-
def main():
-
test_datasets = generate_attires.gen_attrs()
-
classfier = bayes_classfier.navie_bayes_classifier()
-
for data
in test_datasets:
-
print(
"特征值:",end=
'\t')
-
print(data)
-
print(
"预测结果:", end=
'\t')
-
res=classfier.get_label(*data)
#表示多参传入
-
print(res)
#预测属于哪种水果的概率
-
print(
'水果类别:',end=
'\t')
-
#对后验概率排序,输出概率最大的标签
-
print(sorted(res.items(),key=operator.itemgetter(
1),reverse=
True)[
0][
0])
-
-
if __name__ ==
'__main__':
-
#表示模块既可以被导入(到 Python shell 或者其他模块中),也可以作为脚本来执行。
-
#当模块被导入时,模块名称是文件名;而当模块作为脚本独立运行时,名称为 __main__。
-
#让模块既可以导入又可以执行
-
-
main()
=====================================================================================
结果展示:
特征值: ['not_long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.08571428571428573, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['not_long', 'sweet', 'not_yellow']
预测结果: {'banala': 0.1076923076923077, 'orange': 0.0, 'other_fruit': 0.8653846153846153}
水果类别: other_fruit
特征值: ['not_long', 'sweet', 'yellow']
预测结果: {'banala': 0.24230769230769234, 'orange': 0.5769230769230769, 'other_fruit': 0.07211538461538461}
水果类别: orange
特征值: ['not_long', 'sweet', 'yellow']
预测结果: {'banala': 0.24230769230769234, 'orange': 0.5769230769230769, 'other_fruit': 0.07211538461538461}
水果类别: orange
特征值: ['not_long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.08571428571428573, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.7714285714285716, 'orange': 0.0, 'other_fruit': 0.04464285714285715}
水果类别: banala
特征值: ['not_long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.1928571428571429, 'orange': 1.0714285714285714, 'other_fruit': 0.04464285714285715}
水果类别: orange
特征值: ['not_long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.1928571428571429, 'orange': 1.0714285714285714, 'other_fruit': 0.04464285714285715}
水果类别: orange
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['not_long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.1928571428571429, 'orange': 1.0714285714285714, 'other_fruit': 0.04464285714285715}
水果类别: orange
特征值: ['not_long', 'sweet', 'not_yellow']
预测结果: {'banala': 0.1076923076923077, 'orange': 0.0, 'other_fruit': 0.8653846153846153}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.7714285714285716, 'orange': 0.0, 'other_fruit': 0.04464285714285715}
水果类别: banala
特征值: ['not_long', 'sweet', 'yellow']
预测结果: {'banala': 0.24230769230769234, 'orange': 0.5769230769230769, 'other_fruit': 0.07211538461538461}
水果类别: orange
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'banala': 0.3428571428571429, 'orange': 0.0, 'other_fruit': 0.5357142857142858}
水果类别: other_fruit
特征值: ['not_long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.1928571428571429, 'orange': 1.0714285714285714, 'other_fruit': 0.04464285714285715}
水果类别: orange
特征值: ['long', 'not_sweet', 'yellow']
预测结果: {'banala': 0.7714285714285716, 'orange': 0.0, 'other_fruit': 0.04464285714285715}
水果类别: banala