和鲸社区数据分析每周挑战【第九十四期:中风患病预测分析】
和鲸社区数据分析每周挑战【第九十四期:中风患病预测分析】
文章目录
-
- 和鲸社区数据分析每周挑战【第九十四期:中风患病预测分析】
- 一、前言
-
- 1、背景描述
- 2、数据说明
- 3、数据集预览
- 二、数据读取和数据预处理
- 三、探索性数据分析
-
- 1、绘制相关性矩阵
- 2、中风患病预测分析
一、前言
本周的挑战内容为:中风患病预测分析
大家可以去我的和鲸鱼主页查看这个项目
1、背景描述
中风是一种医学疾病,由于流向大脑的血液不足导致细胞死亡。中风主要有两种类型:缺血性中风(缺乏血液流动导致)和出血性中风(出血导致)。两者都会导致大脑的某些部分停止正常运作。
中风的体征和症状可能包括一侧身体无法移动或感觉,理解或说话问题,头晕或一侧视力丧失。症状和体征通常在中风发生后不久就会出现。
如果症状持续不到一两个小时,中风就是短暂性脑缺血发作(TIA),也称为小中风。
出血性中风还可能伴有严重的头痛。中风的症状可能是永久性的。长期并发症可能包括肺炎和膀胱失控。
中风的主要危险因素是高血压。
其他危险因素包括高血胆固醇、吸烟、肥胖、糖尿病、以前的TIA、终末期肾病和心房颤动。
缺血性中风通常是由血管堵塞引起的,尽管也有一些不太常见的原因。
出血性中风是由出血直接进入大脑或进入大脑膜之间的空间引起的。
出血可能是由于脑动脉瘤破裂引起的。诊断通常基于身体检查,并辅以医学成像,如CT扫描或MRI扫描。
CT扫描可以排除出血,但不一定排除缺血,早期的CT扫描通常不会显示缺血。其他检查,如心电图(ECG)和血液检查,以确定危险因素和排除其他可能的原因。低血糖也可能引起类似的症状。
2、数据说明
- 《中国成人超重和肥胖症预防控制指南》的BMI分类:
| BMI | 身体质量指数说明 |
|---|---|
| < 18.5 | 体重过轻 |
| 18.5 - 23.9 | 体重正常 |
| 24 - 27.9 | 超重 |
| > 28 | 肥胖 |
-
血糖水平
正常空腹血糖浓度的预期值介于
70 mg/dL 到 100 mg/dL之间。
或:3.9 mmol/L 和 5.6 mmol/L 之间
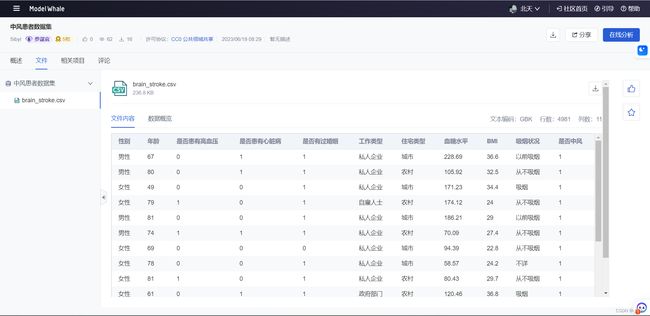
3、数据集预览
数据集来源于本次活动提供:
二、数据读取和数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from sklearn.model_selection import validation_curve
# 加载数据集
data = pd.read_csv('brain_stroke.csv', encoding='gbk')
# 处理缺失值
data.fillna(data.mean(), inplace=True)
data.head()

# 使用 LabelEncoder 对分类特征进行编码
le = LabelEncoder()
categorical_features = ['性别', '工作类型', '住宅类型', '吸烟状况']
for col in categorical_features:
data[col] = le.fit_transform(data[col])
三、探索性数据分析
1、绘制相关性矩阵
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
plt.figure(figsize=(12, 10))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.title('相关矩阵')
plt.show()

2、中风患病预测分析
# 分割数据集
X = data.drop('是否中风', axis=1)
y = data['是否中风']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化数据
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建神经网络模型
model = MLPClassifier(hidden_layer_sizes=(12, 8), activation='relu', solver='adam', random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 打印分类报告和混淆矩阵
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
precision recall f1-score support
0 0.95 1.00 0.97 943
1 0.00 0.00 0.00 54
accuracy 0.94 997
macro avg 0.47 0.50 0.49 997
weighted avg 0.89 0.94 0.92 997
[[941 2]
[ 54 0]]
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {:.2f}%".format(accuracy * 100))
Accuracy: 94.38%
# 绘制损失和准确率曲线
train_scores, valid_scores = validation_curve(
MLPClassifier(hidden_layer_sizes=(12, 8), activation='relu', solver='adam', random_state=42),
X_train, y_train,
param_name="max_iter",
param_range=np.arange(1, 100, 10),
cv=5,
scoring="accuracy"
)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(np.arange(1, 100, 10), np.mean(train_scores, axis=1), label="Training accuracy")
plt.plot(np.arange(1, 100, 10), np.mean(valid_scores, axis=1), label="Validation accuracy")
plt.title('Validation Curve - Accuracy')
plt.xlabel('Number of iterations')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
train_losses, valid_losses = validation_curve(
MLPClassifier(hidden_layer_sizes=(12, 8), activation='relu', solver='adam', random_state=42),
X_train, y_train,
param_name="max_iter",
param_range=np.arange(1, 100, 10),
cv=5,
scoring="neg_log_loss"
)
plt.plot(np.arange(1, 100, 10), -np.mean(train_losses, axis=1), label="训练损失")
plt.plot(np.arange(1, 100, 10), -np.mean(valid_losses, axis=1), label="验证损失")
plt.title('验证曲线 - 损失')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.legend()
plt.tight_layout()
plt.show()
