前端高手进阶第30讲:前端热点技术之 Serverle
严格意义上来说,Serverless 并不属于前端技术,但对于那些想提升自己知识广度,想往全栈工程师方向发展的前端工程师而言,是一个非常高效的工具。而对于那些只想专注于前端领域的工程师而言,了解 Serverless 背后的思想,对提升开发思维也会有一定的帮助。
下面我们就通过相关概念和具体案例来揭开 Serverless 的神秘面纱吧。
什么是 Serverless
Serverless 是由“Server”和“less”两个单词组合而成,翻译成中文就是“无服务器”的意思,所谓无服务器并非脱离服务器的 Web 离线应用,也不是说前端页面绕过服务端直接读写数据库,而是开发者不用再考虑服务器环境搭建和维护等问题,只需要专注于开发即可。也就是说 Serverless 不是语言或框架,而是一种软件的部署方式。传统的应用需要部署在服务器或虚拟机上,安装运行环境之后以进程的方式启动,而使用 Serverless 则可以省略这个过程,直接使用云服务厂商提供的运行环境。
Serverless 从何而来
Serverless 并不是一个全新的产物,而是一种构建和管理基于微服务架构的完整流程,允许在服务部署级别而不是在服务器部署级别来管理你的应用部署。与传统架构的不同之处在于,它完全由云厂商管理,由事件触发,以无状态的方式运行(可能只存在于一次调用的过程中)在容器内。
Serverless 的组成
Serverless 架构由两部分组成,即 FaaS 和 BaaS。
FaaS(Function-as-a-Service)函数即服务,一个函数就是一个服务,函数可以由任何语言编写,除此之外不需要关心任何运维细节,比如计算资源、弹性扩容,而且还可以按量计费,且支持事件驱动。
BaaS(Backend-as-a-Service)后端即服务,集成了许多中间件技术,比如数据即服务(数据库服务)、缓存、网关等。
Serverless 的特点
了解完 Serverless 的基础概念,我们再来看看它有哪些特点。
免维护
Serverless 不仅提供了运行代码的环境,还能自动实现负载均衡、弹性伸缩这类高级功能,极大地降低了服务搭建的复杂性,有效提升开发和迭代的速度。
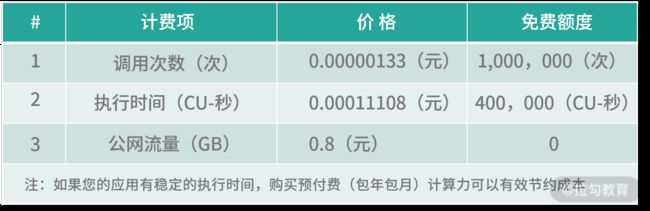
费用
如果只考虑 FaaS,那么费用是比较便宜的。
以阿里云的函数计算为例,费用包括调用次数、执行时间、公网流量 3 个因素。调用次数和执行时间都有免费额度,即使超过,单次/每秒的费用也非常低,这种按需收费的方式就避免了资源的浪费。
流量费用则稍贵,达到 0.8 元/GB,而且没有免费额度,所以对于通信数据量比较大的场景还是要慎重使用。
深度绑定
通常使用某个云厂商的 Serverless 产品时,可能会包括多种产品,如函数计算、对象存储、数据库等,而这些产品和云厂商又深度绑定,所以如果要进行迁移,成本相对于部署在服务器而言会增加很多。
运行时长限制
通常云厂商对于 Serverless 中的函数执行时间是有限制的,如阿里云的函数计算产品,最大执行时长为 10 分钟,如果执行长时间任务,还需要单独申请调整时长上限,或者自行将超时函数拆分成粒度更小的函数,但是这种方式会增加一定的开发成本。
冷启动
由于函数是按需执行的,首次执行时会创建运行容器,一般这个创建环境的时间在几百毫秒,在延迟敏感的业务场景下需要进行优化,比如定时触发函数或者设置预留实例。
Serverless 的应用场景
以阿里云的函数计算为例,可以分为两类:事件函数和 HTTP 函数。
-
事件函数。事件函数的执行方式有两种,一种是通过 SDK 提供的 API 函数调用它,基于此可以进行一些轻量计算操作,比如对图片进行压缩、格式转换,又或者执行一些 AI 训练任务;另一种是通过配置时间和间隔,让其自动执行,一些常见的自动执行场景包括文件备份、数据统计等。
-
HTTP 函数。每一个 HTTP 函数都有特定的域名来供外部访问,当这个域名被访问时,函数将会被创建并执行。可以使用 HTTP 函数为前后端分离架构的 Web 应用提供后端数据支撑,比如提供获取天气 API 查看实时天气,或者提供 API 来读写数据库。
Serverless 实例
下面来分析讲解一个使用阿里云函数计算来实现代码自动部署的例子。函数要实现的功能就是,当 GitHub 仓库中的某个分支有新的提交时,拉取最新代码并编译,然后将编译生成的代码部署到 OSS 存储的静态服务器上。

自动部署流程图
在这个例子中,两种函数都会用到。
首先是 HTTP 函数负责接收 GitHub 发出的 webhook 请求,当收到请求后使用内部模块调用一个事件函数,在这个事件函数中执行具体的操作。虽然理论上一个 HTTP 函数可以实现,但拆解成两个函数可以有效避免函数执行时间过长导致的 webhook 请求超时报错。
下面是 HTTP 函数源码:
/**
* ACCOUNT_ID 主账号ID
* ACCESS_KEY_ID 访问 bucket 所需要的 key
* ACCESS_KEY_SECRET 访问 bucket 所需要的 secret
* REGION bucket 所在的 region
* BUCKET 用于存储配置文件的 bucket
*/
const {
ACCOUNT_ID,
ACCESS_KEY_ID,
ACCESS_KEY_SECRET,
REGION,
BUCKET
} = process.env
const FCClient = require('@alicloud/fc2');
const OSS = require('ali-oss')
const getRawBody = require('raw-body')
/**
*
* @param {string} filePath 函数计算配置文件路径
*/
const getOSSConfigFile = async (filePath) => {
try {
const client = new OSS({
region: REGION,
accessKeyId: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
bucket: BUCKET
});
const result = await client.get(filePath);
const content = result.content ? result.content.toString() : '{}'
return JSON.parse(content)
} catch(e) {
console.error(e)
return {}
}
}
exports.handler = (req, resp) => {
getRawBody(req, async (e, payload) => {
const body = JSON.parse(payload)
if (e) {
console.error(e)
resp.setStatusCode(400)
resp.send(‘请求体解析失败’)
return
}
let cfg
try {
let config
config = await getOSSConfigFile(/config/${body.repository.name}.json) || {}
cfg = config.action[body.action]
if (!cfg) {
console.error(config.action, body.action)
throw Error(‘未找到对应仓库的配置信息.’)
}
} catch (e) {
console.error(e)
resp.setStatusCode(500)
resp.send(e.message)
return
}
if (cfg) {
const client = new FCClient(ACCOUNT_ID, {
accessKeyID: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
region: cfg.region
});
client.invokeFunction(cfg.service, cfg.name, JSON.stringify(cfg)).catch(console.error)
resp.send(client.invokeFunction(${cfg.service}, ${cfg.name}, ${JSON.stringify(cfg)}))
}
})
}
简单的实现方式就是解析 webhook 请求体内部的参数,获取仓库名和分支名传递给事件函数,但考虑可扩展性,对每个项目仓库使用了单独的配置文件。具体到代码中就是调用 getOSSConfigFile() 函数来从 OSS 存储上读取仓库相关的配置文件信息,然后通过 invokeFunction() 函数调用事件函数并将配置信息传递给事件函数。
这样的好处在于,之后要新增其他仓库或其他分支的时候,只需要新增一个配置文件就可以了。
再来看看事件函数的入口函数实现。
前面在讲 Serverless 函数冷启动问题的时候提到过,函数执行完成后会存活一段时间,在这段时间内再次调用会执行之前创建的函数,短时间内重复执行的话会因为已经存在目录导致拉取失败,所以创建了随机目录并修改工作目录到随机目录下以获取写权限。
然后再根据配置文件中的信息,按串行加载对应的执行模块并传入参数。
const fs = require('fs')
/**
*
* @param {*} event
* {
* repo 仓库地址
* region bucket 所在区域
* bucket 编译后部署的bucket
* command 编译命令
* }
* @param {*} context
* @param {*} callback
*/
exports.handler = async (event, context, callback) => {
const {events} = Buffer.isBuffer(event) ? JSON.parse(event.toString()) : event
let dir = Math.random().toString(36).substr(6)
// 设置随机临时工作目录,避免容器未销毁的情况下,重复拉取仓库失败
const workDir = `/tmp/${dir}`
// 为了保证后续流程能找到临时工作目录,设置为全局变量
global.workDir = workDir
try {
fs.mkdirSync(workDir)
} catch(e) {
console.error(e)
return
}
process.chdir(workDir);
try {
await events.reduce(async (acc, cur) => {
await acc
return require(`./${cur.module}`)(cur)
}, Promise.resolve())
callback(null, `自动部署成功.`);
} catch(e) {
callback(e)
}
}
具体有哪些模块呢?一般的部署过程主要包括 3 步:拉取仓库代码、安装依赖并构建、将生成的代码上传部署。
拉取代码对于手动操作而言很简单,一条 git clone 命令就搞定了,但在自动化实现的时候会碰到一些麻烦的细节问题。
首先身份认证问题。由于是私有仓库,所以只能通过密钥文件或账号密码的形式来认证访问权限。如果通过账号密码的形式登录,则要模拟键终端交互,这个相对而言实现成本较高,所以采用了配置 ssh key 的方式。具体是根据前面传入的配置信息找到私钥文件所在地址并下载到本地,但是因为权限问题,并不能直接保存到当前用户的 .ssh 目录下。
另一个问题是在首次进行 git clone 操作的时候,终端会出现一个是否添加 known hosts 的提示,在终端中操作的时候需要键盘输入 “Y” 或者 “N” 来继续后面的操作。这里可以通过一个选项本来关闭这个提示。
具体实现参考下面的 shell 脚本。
#!/bin/sh
ID_RSA=/tmp/id_rsa
exec /usr/bin/ssh -o StrictHostKeyChecking=no -o GSSAPIAuthentication=no -i $ID_RSA "$@"
解决了比较麻烦的身份认证和终端交互问题之后,剩下的逻辑就比较简单了,执行 git clone 命令拉取仓库代码就行,为了加快速下载速度,可以通过设置 --depth 1 这个参数来指定只拉取最新提交的代码。
const OSS = require('ali-oss')
const cp = require('child_process')
const { BUCKET, REGION, ACCESS_KEY_ID, ACCESS_KEY_SECRET } = process.env
const shellFile = 'ssh.sh'
/**
*
* @param {string} repoURL 代码仓库地址
* @param {string} repoKey 访问代码仓库所需要的密钥文件路径
* @param {string} branch 分支名称
*/
const downloadRepo = async ({repoURL, repoKey, branch='master'}, retryTimes = 0) => {
try {
console.log(`Download repo ${repoURL}`);
process.chdir(global.workDir)
const client = new OSS({
accessKeyId: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
region: REGION,
bucket: BUCKET
});
await client.get(repoKey, `./id_rsa`);
await client.get(shellFile, `./${shellFile}`);
cp.execSync(`chmod 0600 ./id_rsa`);
cp.execSync(`chmod +x ./${shellFile}`);
cp.execSync(`GIT_SSH="./${shellFile}" git clone -b ${branch} --depth 1 ${repoURL}`);
console.log('downloaded');
} catch (e) {
console.error(e);
if (retryTimes < 2) {
downloadRepo({repoURL, repoKey, branch}, retryTimes++);
} else {
throw e
}
}
};
module.exports = downloadRepo
安装依赖并构建这个步骤没有太多复杂的地方,通过子进程调用 yarn install --check-files 命令,然后执行 package.json 文件中配置的脚本任务即可。具体代码如下:
const cp = require('child_process')
const install = (repoName, retryTimes = 0) => {
try {
console.log(‘Install dependencies.’);
cp.execSync(yarn install --check-files);
console.log(‘Installed.’);
retryTimes = 0
} catch (e) {
console.error(e.message);
if (retryTimes < 2) {
console.log(‘Retry install…’);
install(repoName, ++retryTimes);
} else {
throw e
}
}
}
const build = (command, retryTimes = 0) => {
try {
console.log(‘Build code.’)
cp.execSync(${command});
console.log(‘Built.’);
} catch (e) {
console.error(e.message);
if (retryTimes < 2) {
console.log(‘Retry build…’);
build(command, ++retryTimes);
} else {
throw e
}
}
};
module.exports = ({
repoName,
command
}) => {
const {
workDir
} = global
process.chdir(${workDir}/${repoName})
install(repoName)
build(command)
}
最后上传部署可以根据不同的场景编写不同的模块,比如有的可能部署在 OSS 存储上,会需要调用 OSS 对应的 SDK 进行上传,有的可能部署在某台服务器上,需要通过 scp 命令来传输。
下面是一个部署到 OSS 存储的例子。
const path = require('path');
const OSS = require('ali-oss');
// 遍历函数
const traverse = (dirPath, arr = []) => {
var filesList = fs.readdirSync(dirPath);
for (var i = 0; i < filesList.length; i++) {
var fileObj = {};
fileObj.name = path.join(dirPath, filesList[i]);
var filePath = path.join(dirPath, filesList[i]);
var stats = fs.statSync(filePath);
if (stats.isDirectory()) {
traverse(filePath, arr);
} else {
fileObj.type = path.extname(filesList[i]).substring(1);
arr.push(fileObj);
}
}
return arr
}
/**
*
* @param {string} repoName
*
*/
const deploy = ({ dist = '', source, region, accessKeyId, accessKeySecret, bucket, repoName }, retryTimes = 0) => new Promise(async (res) => {
const { workDir } = global
console.log('Deploy.');
try {
const client = new OSS({
region,
accessKeyId,
accessKeySecret,
bucket
});
process.chdir(`${workDir}/${repoName}`)
const root = path.join(process.cwd(), source)
let files = traverse(root, []);
await Promise.all(files.map(({ name }, index) => {
const remotePath = path.join(dist, name.replace(root + '/', ''));
console.log(`[${index}] uploaded ${name} to ${remotePath}`);
return client.put(remotePath, name);
}));
res();
console.log('Deployed.');
} catch (e) {
console.error(e);
if (retryTimes < 2) {
console.log('Retry deploy.');
deploy({ dist, source, region, accessKeyId, accessKeySecret, bucket }, ++retryTimes);
} else {
throw e
}
}
})
module.exports = deploy
由于未找到阿里云 OSS SDK 中上传目录的功能,所以只能通过深度遍历的方式来逐个将文件进行上传。考虑编译后生成地文件数量并不多,这里没有做并发数限制,而是将全部文件进行批量上传。
总结
虽然 Serverless 并不属于前端开发范畴,但确实是一个具有通用性、开箱即用的产品。本课时的主要目的是起到一个抛砖引玉的作用,通过概念介绍以及函数计算的具体实例让你对其有一个初步的认识和了解。希望你在工作中能通过具体实践,不断探索它的使用边界和场景。
最后布置一道作业题:尝试部署一个 Serverless 服务。