轻量级网络的核心是在尽量保持精度的前提下,从体积和速度两方面对网络进行轻量化改造,本文对轻量级网络进行简述,主要涉及以下网络:
- SqueezeNet系列
- ShuffleNet系列
- MnasNet
- MobileNet系列
- CondenseNet
- ESPNet系列
- ChannelNets
- PeleeNet
- IGC系列
- FBNet系列
- EfficientNet
- GhostNet
- WeightNet
- MicroNet
- MobileNext
SqueezeNet系列
SqueezeNet系列是比较早期且经典的轻量级网络,SqueezeNet使用Fire模块进行参数压缩,而SqueezeNext则在此基础上加入分离卷积进行改进。虽然SqueezeNet系列不如MobieNet使用广泛,但其架构思想和实验结论还是可以值得借鉴的。
SqueezeNet
SqueezeNet是早期开始关注轻量化网络的研究之一,使用Fire模块进行参数压缩。

SqueezeNet的核心模块为Fire模块,结构如图1所示,输入层先通过squeeze卷积层($1\times 1$卷积)进行维度压缩,然后通过expand卷积层($1\times 1$卷积和$3\times 3$卷积混合)进行维度扩展。Fire模块包含3个参数,分别为squeeze层的$1\times 1$卷积核数$s_{1x1}$、expand层的$1\times 1$卷积核数$e_{1x1}$和expand层的$3\times 3$卷积核数$e_{3x3}$,一般$s_{1x1}<(e_{1x1}+e_{3x3})$
SqueezeNext
SqueezeNext是SqueezeNet实战升级版,直接和MobileNet对比性能。SqueezeNext全部使用标准卷积,分析实际推理速度,优化的手段集中在网络整体结构的优化。

SqueezeNext的设计沿用残差结构,没有使用当时流行的深度分离卷积,而是直接使用了分离卷积,设计主要基于以下策略:
- Low Rank Filters
低秩分解的核心思想就是将大矩阵分解成多个小矩阵,这里使用CP分解(Canonical Polyadic Decomposition),将$K\times K$卷积分解成$K\times 1$和$1\times K$的分离卷积,参数量能从$K^2$降为$2K$。 - Bottleneck Module
参数量与输入输出维度有关,虽然可以使用深度分离卷积来减少计算量,但是深度分离卷积在终端系统的计算并不高效。因此采用SqueezeNet的squeeze层进行输入维度的压缩,每个block的开头使用连续两个squeeze层,每层降低1/2维度。 - Fully Connected Layers
在AlexNet中,全连接层的参数占总模型的96%,SqueezeNext使用bottleneck层来降低全连接层的输入维度,从而降低网络参数量。
ShuffleNet系列
ShuffleNet系列是轻量级网络中很重要的一个系列,ShuffleNetV1提出了channel shuffle操作,使得网络可以尽情地使用分组卷积来加速,而ShuffleNetV2则推倒V1的大部分设计,从实际出发,提出channel split操作,在加速网络的同时进行了特征重用,达到了很好的效果。
ShuffleNet V1
ShuffleNet的核心在于使用channel shuffle操作弥补分组间的信息交流,使得网络可以尽情使用pointwise分组卷积,不仅可以减少主要的网络计算量,也可以增加卷积的维度。

在目前的一些主流网络中,通常使用pointwise卷积进行维度的降低,从而降低网络的复杂度,但由于输入维度较高,pointwise卷积的开销也是十分巨大的。对于小网络而言,昂贵的pointwise卷积会带来明显的性能下降,比如在ResNext unit中,pointwise卷积占据了93.4%的计算量。为此,论文引入了分组卷积,首先探讨了两种ShuffleNet的实现:
- 图1a是最直接的方法,将所有的操作进行了绝对的维度隔离,但这会导致特定的输出仅关联了很小一部分的输入,阻隔了组间的信息流,降低了表达能力。
- 图1b对输出的维度进行重新分配,首先将每个组的输出分成多个子组,然后将每个子组输入到不同的组中,能够很好地保留组间的信息流。
图1b的思想可以简单地用channel shuffle操作进行实现,如图1c所示,假设包含$g$组的卷积层输出为$g\times n$维,首先将输出reshape()为$(g, n)$,然后进行transpose(),最后再flatten()回$g\times n$维。
ShuffleNet V2
ShuffleNetV1的pointwise分组卷积以及bottleneck结果均会提高MAC,导致不可忽视的计算损耗。为了达到高性能以及高准确率,关键是在不通过稠密卷积以及过多分组的情况下,获得输入输出一样的大维度卷积。ShuffleNet V2从实践出发,以实际的推理速度为指导,总结出了5条轻量级网络的设计要领,并根据要领提出了ShuffleNetV2,很好地兼顾了准确率和速度,其中channel split操作十分亮眼,将输入特征分成两部分,达到了类似DenseNet的特征重用效果。

ShuffeNetV1的unit结构如图3ab所示,在V1的基础上加入channel split操作,如图3c所示。在每个unit的开头,将特征图分为$c-c^{'}$以及$c^{'}$两部分,一个分支直接往后传递,另一个分支包含3个输入输出维度一样的卷积。V2不再使用分组卷积,因为unit的开头已经相当于进行了分组卷积。在完成卷积操作后,将特征concate,恢复到unit的输入大小,然后进行channel shuffle操作。这里没有了element-wise adddition操作,也节省了一些计算量,在实现的时候将concat/channel shuffle/channel split合在一起做了,能够进一步提升性能。
空间下采样时对unit进行了少量的修改,如图3d所示,去掉了channel split操作,因此输出大小降低一倍,而维度则会增加一倍。
MnasNet

论文提出了移动端的神经网络架构搜索方法,该方法主要有两个思路,首先使用多目标优化方法将模型在实际设备上的耗时融入搜索中,然后使用分解的层次搜索空间让网络保持层多样性的同时,搜索空间依然很简洁,MnasNet能够在准确率和耗时中有更好的trade off
MobileNet系列
MobileNet系列是很重要的轻量级网络家族,出自谷歌,MobileNetV1使用深度可分离卷积构建轻量级网络,MobileNetV2提出创新的inverted residual with linear bottleneck单元,虽然层数变多了,但是整体网络准确率和速度都有提升,MobileNetV3则结合AutoML技术与人工微调进行更轻量级的网络构建。
MobileNetV1
MobileNetV1基于深度可分离卷积构建了非常轻量且延迟小的模型,并且可以通过两个超参数进一步控制模型的大小,该模型能够应用到终端设备中,具有很重要的实践意义。

MobileNet通过深度可分离卷积优进行计算量优化,将标准卷积转化为深度卷积和$1\times 1$pointwise卷积,每层后面都会接BN和ReLU。
MobileNetV2

MobileNetV2首先表明高维特征实际可以用紧凑的低维特征表达,然后提出了新的层单元inverted residual with linear bottleneck,该结构与残差网络单元类似,都包含shorcut,区别在于该结构是输入输出维度少,中间通过线性卷积先扩展升维,然后通过深度卷积进行特征提取,最后再映射降维,可以很好地保持网络性能且网络更加轻量。
MobileNetV3

MobileNetV3先基于AutoML构建网络,然后进行人工微调优化,搜索方法使用了platform-aware NAS以及NetAdapt,分别用于全局搜索以及局部搜索,而人工微调则调整了网络前后几层的结构、bottleneck加入SE模块以及提出计算高效的h-swish非线性激活。
CondenseNet
DenseNet基于特征复用,能够达到很好的性能,但是论文认为其内在连接存在很多冗余,早期的特征不需要复用到较后的层。为此,论文基于可学习分组卷积提出CondenseNet,能够在训练阶段自动稀疏网络结构,选择最优的输入输出连接模式,并在最后将其转换成常规的分组卷积分组卷积结构。

分组卷积的学习包含多个阶段,前半段训练过程包含多个condensing阶段,结合引导稀疏化的正则化方法来反复训练网络,然后将不重要的filter剪枝。后半部分为optimization阶段,这个阶段对剪枝固定后的网络进行学习。
ESPNet系列
ESPNet系列的核心在于空洞卷积金字塔,每层具有不同的dilation rate,在参数量不增加的情况下,能够融合多尺度特征,相对于深度可分离卷积,深度可分离空洞卷积金字塔性价比更高。另外,HFF的多尺度特征融合方法也很值得借鉴 。
ESPNet

ESPNet是用于语义分割的轻量级网络,核心在于ESP模块。如图a所示,该模块包含point-wise卷积和空洞卷积金字塔,分别用于降低计算复杂度以及重采样有效感受域不同的特征。ESP模块比其它卷积分解方法(mobilenet/shufflenet)更高效,ESPNet能在GPU/笔记本/终端设备上达到112FPS/21FPS/9FPS。
另外,论文发现,尽管空洞卷积金字塔带来更大的感受域,但直接concate输出却会带来奇怪网格纹路。为了解决这个问题,论文提出图b的HFF操作,在concate之前先将输出进行层级相加。相对于添加额外的卷积来进行后处理,HFF能够有效地解决网格纹路而不带来过多的计算量。另外,为了保证网络的梯度传递,在ESP模块添加了一条从输入到输出的shortcut连接。
ESPNetV2
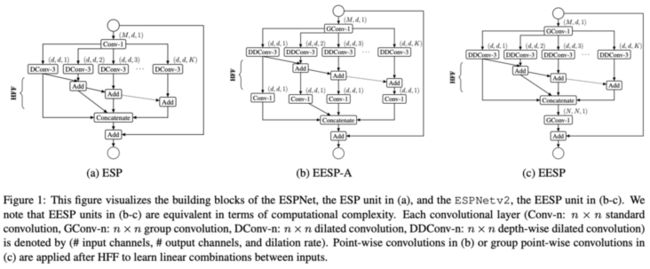
ESPNetv2在ESPNet的基础上结合深度分离卷积的设计方法,进行了进一步的模型轻量化。首先将point-wise卷积替换为分组point-wise卷积,然后将计算量较大的空洞卷积替换为深度可分离空洞卷积,最后依然使用HFF来消除网格纹路,输出特征增加一次特征提取,得到图b的结构。考虑到单独计算K个point-wise卷积等同于单个分组数为K的point-wise分组卷积,而分组卷积的在实现上更高效,于是改进为图c的最终结构。
ChannelNets

论文提出channel-wise卷积的概念,将输入输出维度的连接进行稀疏化而非全连接,区别于分组卷积的严格分组,以类似卷积滑动的形式将输入channel与输出channel进行关联,能够更好地保留channel间的信息交流。基于channel-wise卷积的思想,论文进一步提出了channel-wise深度可分离卷积,并基于该结构替换网络最后的全连接层+全局池化的操作,搭建了ChannelNets。
PeleeNet

基于DenseNet的稠密连接思想,论文通过一系列的结构优化,提出了用于移动设备上的网络结构PeleeNet,并且融合SSD提出目标检测网络Pelee。从实验来看,PeleeNet和Pelee在速度和精度上都是不错的选择。
IGC系列
IGC系列网络的核心在分组卷积的极致运用,将常规卷积分解成多个分组卷积,能够减少大量参数,另外互补性原则和排序操作能够在最少的参数量情况下保证分组间的信息流通。但整体而言,虽然使用IGC模块后参数量和计算量降低了,但网络结构变得更为繁琐,可能导致在真实使用时速度变慢。
IGCV1
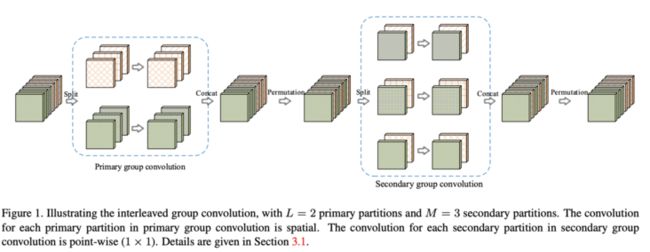
Interleaved group convolution(IGC)模块包含主分组卷积和次分组卷积,分别对主分区和次分区进行特征提取,主分区通过输入特征分组获得,比如将输入特征分为$L$个分区,每个分区包含$M$维特征,而对应的次分区则分为$M$个分区,每个分区包含$L$维特征。主分组卷积负责对输入特征图进行分组特征提取,而次组卷积负责对主分组卷积的输出进行融合,为$1\times 1$卷积。IGC模块形式上与深度可分离卷积类似,但分组的概念贯穿整个模块,也是节省参数的关键,另外模块内补充了两个排序模块来保证channel间的信息交流。
IGCV2

IGCV1通过两个分组卷积来对原卷积进行分解,减少参数且保持完整的信息提取。但作者发现,因为主分组卷积和次分组卷积在分组数上是互补的,导致次卷积的分组数一般较小,每个分组的维度较大,次卷积核较为稠密。为此,IGCV2提出Interleaved Structured Sparse Convolution,使用多个连续的稀疏分组卷积来替换原来的次分组卷积,每个分组卷积的分组数都足够多,保证卷积核的稀疏性。
IGCV3

基于IGCV和bootleneck的思想,IGCV3结合低秩卷积核和稀疏卷积核来构成稠密卷积核,如图1所示,IGCV3使用低秩稀疏卷积核(bottleneck模块)来扩展和输入分组特征的维度以及降低输出的维度,中间使用深度卷积提取特征,另外引入松弛互补性原则,类似于IGCV2的严格互补性原则,用来应对分组卷积输入输出维度不一样的情况。
FBNet系列
FBNet系列是完全基于NAS搜索的轻量级网络系列,分析当前搜索方法的缺点,逐步增加创新性改进,FBNet结合了DNAS和资源约束,FBNetV2加入了channel和输入分辨率的搜索,FBNetV3则是使用准确率预测来进行快速的网络结构搜索。
FBNet

论文提出FBNet,使用可微神经网络搜索(DNAS)来发现硬件相关的轻量级卷积网络,流程如图1所示。DNAS方法将整体的搜索空间表示为超网,将寻找最优网络结构问题转换为寻找最优的候选block分布,通过梯度下降来训练block的分布,而且可以为网络每层选择不同的block。为了更好地估计网络的时延,预先测量并记录了每个候选block的实际时延,在估算时直接根据网络结构和对应的时延累计即可。
FBNetV2
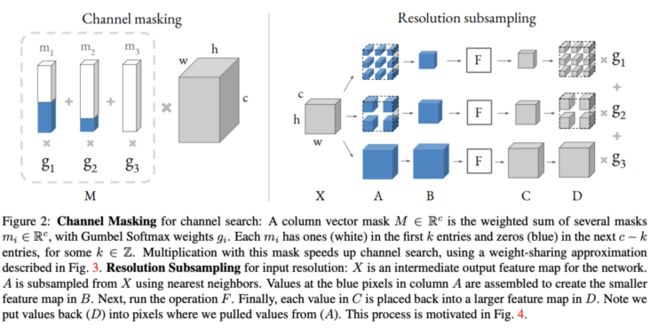
DNAS通过训练包含所有候选网络的超网来采样最优的子网,虽然搜索速度快,但需要耗费大量的内存,所以搜索空间一般比其它方法要小,且内存消耗和计算量消耗随搜索维度线性增加。为了解决这个问题,论文提出DMaskingNAS,将channel数和输入分辨率分别以mask和采样的方式加入到超网中,在带来少量内存和计算量的情况下,大幅增加$10^{14}$倍搜索空间。
FBNetV3

论文认为目前的NAS方法大都只满足网络结构的搜索,而没有在意网络性能验证时的训练参数的设置是否合适,这可能导致模型性能下降。为此,论文提出JointNAS,在资源约束的情况下,同时搜索最准确的训练参数以及网络结构。FBNetV3完全脱离了FBNetV2和FBNet的设计,使用的准确率预测器以及基因算法都已经在NAS领域有很多应用,主要亮点在于将训练参数加入到了搜索过程中,这对性能的提升十分重要。
EfficientNet
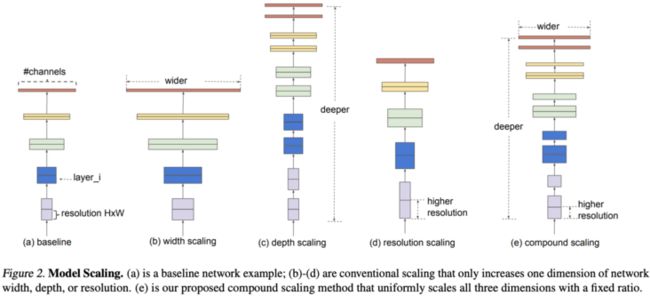
论文对模型缩放进行深入研究,提出混合缩放方法,该方法可以更优地选择宽度、深度和分辨率的维度缩放比例,从而使得模型能够达到更高的精度。另外,论文通过NAS神经架构搜索提出EfficientNet,配合混合缩放方法,能够使用很少量的参数达到较高的准确率。
GhostNet

训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,相似的特征图类似于对方的ghost。但冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,于是提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图数量,Ghost模块的整体的参数量和计算量就已经降低了。
WeightNet
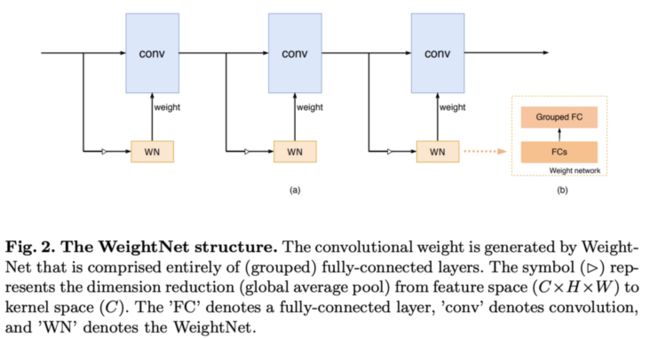
论文提出了一种简单且高效的动态生成网络WeightNet,该结构在权值空间上集成了SENet和CondConv的特点,在激活向量后面添加一层分组全连接,直接产生卷积核的权值,在计算上十分高效,并且可通过超参数的设置来进行准确率和速度上的trade-off。
MicroNet

论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。
MobileNext
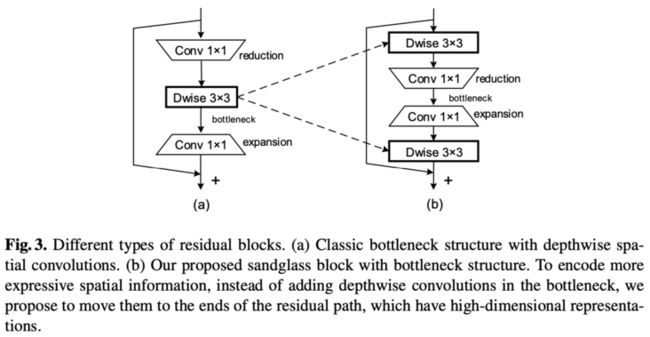
论文深入分析了inverted residual block的设计理念和缺点,提出更适合轻量级网络的sandglass block,基于该结构搭建的MobileNext。sandglass block由两个depthwise卷积和两个pointwise卷积组成,部分卷积不需激活以及shorcut建立在高维度特征上。根据论文的实验结果,MobileNext在参数量、计算量和准确率上都有更优的表现。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
