Python数据分析与展示-Numpy、Pandas
一、概述
1、numpy(ndarray):一个开源的python科学计算基础库。具有广播功能函数;整合C/C++/Fortran代码的工具;线性代数、傅里叶变换、随机数生成等功能。是SciPy、Pandas等数据处理或科学计算库的基础。
2、pandas(series、dataframe):是Python第三方库,提供高性能易用数据类型和分析工具。基于Series、Dataframe两种数据类型的各种操作:基本操作、运算操作、特征类操作、关联类操作
二、关于numpy
1、数据的维度:
(1)一维数据:由对等关系的有序或无序数据构成,采用线性方式组织(列表([])和集合({})类型)
【注】列表与数组的对比:列表中的数据类型可以不同,但数组中的数据类型都得一样
(2)二维数据:有多个以为去诶数据构成,是一维数据的组合形式(列表类型)
(3)多维数据:由一维或二维数据在新维度(如时间维度)上扩展而成(列表类型)
(4)高维数据:仅利用最基本的二元关系展示数据间的复杂结构(字典类型或数据表达格式)
2、numpy的数组对象ndarray:
(1)为什么要使用numpy:数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据;设置专门的数组对象,经过优化,可以提升这类应用的运算速度
(3)关于ndarray:是一个多维数组对象,由两部分构成——实际的数据;描述这些数据的元数据(数据维度、数据类型等)
【注】ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始
(4)基本操作:
np.array()
生成一个ndarray数组,轴(axis)——保持数据的维度;秩(rank)——轴的数量
eg:np.array([[0,1,2,3,4],
[9,8,7,6,5]])
ndarray对象的属性:
.ndim:秩,即轴的数量或维度的数量
.shape:ndarray对象的尺度,对于矩阵,n行m列
.size:ndarray对象元素的个数,相当于.shape中n*m的值
.dtype:ndarray对象的元素类型
【注】ndarray的元素类型:bool、intc、intp、int8、int16、int32、int64、unit8、unit16、uint32、uint64、float16、float32、float64、complex64(复数)、complex128
.itemsize:ndarray对象中每个元素的大小,以字节为单位
ndarray数组的创建方法:
(1)从Python中的列表、元组等类型创建ndarray数组
x = np.array(list/tuple)
x = np.array(list/tuple,dtype=np.float32)
(2)使用numpy中的函数创建ndarray数组。如:arange、ones、zeros等
np.arange(n)
np.ones(shape) #shape格式为(n,m)
np.zeros(shape)
np.full(shape,val):根据shape生成一个数组,每个元素值都为val
np.eye(n):创建一个正方的n*n单位矩阵,对角线为1,其余为0
eg:np.linspace(1,10,4,endpoint=False):10不作为最后一个元素,相当于生成了五个元素,去掉了10
b = a.astype(np.float):改变a的数据类型
b = a.tolist():ndarray数组向列表转变
(3)从字节流(rawa bytes)中创建ndarray数组
(4)从文件中读取特定格式,创建ndarray数组



数组的索引和切片:
(1)一维数组(与python的列表类似):
a[2]
a[1:4:2]:从1到4之间,步长为2
(2)多维数组:
a[0,1,2]
a[:,:,::2]
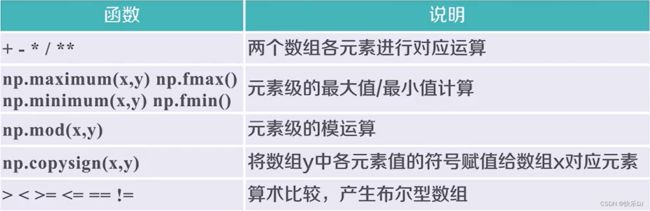
ndarray数组的运算:
二元函数:


(5)数据的CSV文件存取
CSV文件:只能有效存取一维和二维数组
CSV(Comma-Seperated Value,逗号分隔值)
CSV是一种常见的文件格式,用于存储批量数据
(1)存储
np.savetxt(frame,array,fmt='%.18e',delimiter=none)
frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
array:存入文件的数组
fmt:写入文件的格式,例如:%d%.2f%.18e
delimiter:分割字符串,默认是任何空格
eg: np.savetxt('a.csv',a,fmt='%d',delimiter=',')
(2)读入
np.loadtxt(frame,dtype=np.float,delimiter=none,unpack=False)
frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
dtype:数据类型,可选
多维数据(该方法需要读取时知道存入文件时数组的维度和元素类型)
(1)存储
a.tofile(frame,sep='',format='%s')
frame:文件、字符串
sep:数据分割字符串,如果是空串,写入文件为二进制
eg:a.tofile('b.dat',sep=',',format='%d')
(2)读入
np.fromfile(frame,dtype=float,count=-1,sep='')
count:读入元素个数,-1表示读入整个文件
sep:数据分割字符串,如果是空串,写入文件为二进制
numpy的边界文件存取(多维):
(1)存储
np.save(fname,array)或np.savez(fname,array)
fname:文件名,以.npy为扩展名,压缩扩展名为.npa
array:数组变量
(2)读入
np.load(fname,array)
(6)numpy的随机数函数
eg:np.random.rand(3,4,5)
eg:np.random.randint(100,200,(3,4)):100到200之间3行4列

(7) numpy的统计函数
axis=None是统计函数的标配函数
axis=1:对每行操作 axis=0:对每列操作
eg:np.argmax(b):扁平化后的下标
eg:np.unravel_index(np.argmax(b),b.shape):重塑成多维下标

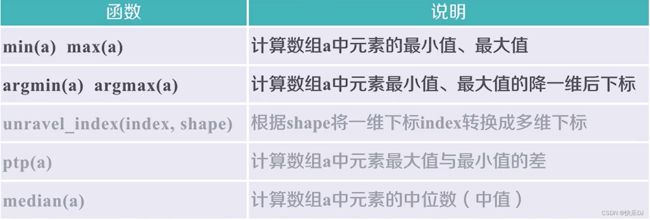
(8) np.random的梯度函数

三、关于pandas
1、Series类型
(1)定义:由一组数据及与之相关的数据索引组成
(2)创建:Python列表、标量值、Python字典、ndarray、其他函数
标量值:s = pd.Series(25,index=['a','b','c']) #不能省略index
Python字典:d = pd.Series({'a':9,'b':8})
(3)基本操作:包括index和values两部分;操作类似ndarray;类似字典类型
'c' in b:
b.get('f',100):b中是否有索引f,若有则输出,否则,输出100
2、Dataframe类型
(1)定义:由共用相同索引的一组列组成
(2)创建:二维ndarray、由一维ndarray、列表、字典、元组或series构成的字典、series类型、其他的Dataframe类型
d = pd.DataFrame(np.arange(10).reshape(2,5))
3、Pandas库的数据类型操作
(1)重新索引:.reindex()能够改变或重排Series和Dataframe索引
【注】index索引列标;columns索引行标

 (2)删除指定索引对象:.drop()能删除Pandas指定行或列索引
(2)删除指定索引对象:.drop()能删除Pandas指定行或列索引
4、Pandas库的数据类型运算
