Python使用的一些细节点
数(number,不可变的)
数是不可变的,包括整数、浮点数、布尔型和复数。除了数之外,其余的几种数据数据类型都是可迭代对象(可迭代对象是对整体中的单个元素级别进行操作,而非整体)。
#该内置函数返回的是十进制。当参数带有小数点时,只是单纯取整数部分,既不是向上取整,也
不是向下取整。但可以import math,然后使用其中的floor来向下取整,使用ceil来向上取整
int()
#该内置函数返回的是浮点数
float()
#该内置函数返回False或True,其中返回False的规则:数字0,0.0,0j, None, 空字符串,
#空列表,空元组,空字典,空集合
bool()
#复数定义时虚部是以j为J结尾,例如a = 2 + 1j、b = 1J(j和J前面的系数不能省略) ,另外转
#换为复数的内置函数如下所示
complex() #小整数对象池:Python 为了优化速度,避免整数频繁申请和销毁内存空间,把范围在 [-5, 256]
#之间的数字放在提前建立好的小整数对象池里面,不会被垃圾回收,在这范围内的数值如果相等,
#地址也就相同,因为使用的都是同一个对象。
a = 257 #在Python中,变量是可以被赋值的标签,也可以说变量指向特定的值。
b = 257
print(id(a))
print(id(b))
a = 256
b = 256
print(id(a))
print(id(b))
a = -5
b = -5
print(id(a))
print(id(b))
a = -6
b = -6
print(id(a))
print(id(b)).....................................................................................................................
字符串(str,字符串是不可变的序列)
用单引号或双引号引起的都是字符串,也就是说在pthon中不区分字符和字符串。
name = "张三"
age = "18"
print("我是", name, ", 我今年", age, "岁了, ", "明年我", int(age)+1, "岁!", sep="")
# %格式化(传统的格式化方式)
print('我是%s, 我今年%s岁了, 明年我%d岁!' % (name, age, int(age)+1))
# format格式化(Python2.6引入)
print('我是{}, 我今年{}岁了, 明年我{}岁!'.format(name, age, int(age)+1))
print('我是{v1}, 我今年{v2}岁了, 明年我{v3}岁!'.format(v1=name, v2=age, v3=int(age)+1))
print('我是{0}, 我今年{1}岁了, 明年我{2}岁!'.format(name, age, int(age)+1))
# f-string格式化(Python3.6引入)
print(f'我是{name}, 我今年{age}岁了, 明年我{int(age)+1}岁!')str1 = '' #空字符串,直接print(str(''))是看不到的,要想看到可以print([str()])
str2 = ' ' #不是空字符串,里面有空格
#很多时候我们并不希望字符串转义,比方说在输入一串网址的时候,里面正好有反斜杠和字母造成
#了转义,此时为了让该字符串不转义,可以在字符串前面加一个字母 r,表示原始字符串,所有转义
#都不进行,也就是起到了抑制转义的效果。
print(r"www.baidu.com\n") # 原始字符串
print(R"www.baidu.com\n") # 原始字符串full_name = f"{'zhang'} {'shuaifeng'}"
message = f"Come on, {full_name.title()}! "
# strip删除message中感叹号后面的空格。这里需要注意字符串是不可变的数据类型,对其strip操作时会并
# 不是在原字符串基础上进行原地操作,而是在其副本上进行操作。所以下面将对副本的操作结果关联到原来
# 的变量message,既需要再将新值关联到原来的变量。
message = message.strip()
print(message)#chr(i) 内置函数返回 Unicode 码位为整数 i 的字符,它是 ord() 的逆函数
#ord(c)内置函数返回单字符对应的 Unicode 码位,它是 chr() 的逆函数
print(chr(97))
print(ord('a')).....................................................................................................................
列表(list,列表是可变的序列)
在Python中用方括号[]表示列表,如果要访问列表中的元素,只需要使用索引(从左到右的话从0开始,从右到左的话从-1开始)即可。
1)修改、添加和删除元素
列表是可变的,也就是说你创建的大多数列表将是动态的,这意味着创建列表后,可随着程序的运行增删元素,列表的长度会动态变化。需要注意的是列表中元素的地址并不一定是连续的,每个元素都有自己的地址,列表这个整体本身也有自己的地址。
motorcyles = ['honda', 'yamaha', 'suzuki']
print(motorcyles)
# 修改列表元素
# motorcyles[0] = 'ducati'
# print(motorcyles)
# 在列表中添加元素:在列表尾添加元素
# motorcyles.append('ducati')
# print(motorcyles)
# 在列表中添加元素:在列表中插入元素
# motorcyles.insert(0, 'ducati')
# print(motorcyles)
# 从列表中删除元素:使用del语句删除元素,删除后就无法再访问被删元素了。(这里需要注意使用
# 删除元素一般都是解除变量的引用del 语句在删除变量时,不是直接删除数据,而是解除变量对数据
# 的引用,当数据引用计数为0时,数据就变为了一个可回收的对象,然后内存会被不定期回收)
# del motorcyles[0]
# print(motorcyles)
# 从列表中删除元素:使用pop方法删除列表元素,被删后可接着使用它的值
# popped_motorcyles = motorcyles.pop() # 删除末尾元素
# print(motorcyles)
# print(popped_motorcyles)
# popped_motorcyles = motorcyles.pop(0) # 指定索引,删除任意位置元素
# print(motorcyles)
# print(popped_motorcyles)
# 从列表中删除元素:根据值删除
removed_motorcyles = 'honda'
motorcyles.remove(removed_motorcyles)
print(motorcyles)
print(f'\n{removed_motorcyles.title()}')2)管理列表
cars = ['bmw', 'audi', 'toyota', 'subaru']
# 使用对象方法sort对列表进行永久排序,修改后再也无法恢复到原来的排列顺序(对列表进行了原地操作)
# cars.sort()
# print(cars)
# cars.sort(reverse=True)
# print(cars)
# 使用全局的内置函数sorted对列表进行临时排序(新建了列表的副本,对列表的副本进行的操作。新建操作
# 的函数一般都有返回值?)
print("Here is the original list:")
print(cars)
print("Here is the sorted list:")
print(sorted(cars)) #新建操作的函数一般都有返回值
print("Here is the original list again:")
print(cars)
#使用对象方法reverse反转列表,也是永久反转(对列表的原地操作)lst = ['4', '3', '1000', '7', '19']
# 内置函数reversed(seq)对给定序列返回一个反向迭代器(迭代器一定是可迭代对象,因此可以将其转
# 换为列表等,另外需要注意的是迭代器只能从头到尾迭代一次,因此下面第二次打印为空列表)
ret = reversed(lst)
#内置函数list([iterable])将一个iterable对象转化为列表并返回,如果没有传入参数返回空的列表
print(list(ret)) # ['19', '7', '1000', '3', '4']
print(list(ret)) # []3)使用列表的一部分元素(切片)
遍历列表
如果要遍历列表的部分元素,可在for循环中使用切片
players = ['charles', 'martina', 'michael', 'florence', 'eli']
for player in players[:3]:
print(player.title())复制列表
要复制列表(创建一个副本),可以创建一个起始于第一个元素,终止于最后一个元素的切片,即复制整个列表。
#示例一:利用切片让my_foods和friend_foods分别指向不同的列表
my_foods = ['pizza', 'falafel', 'carrot cake']
friend_foods = my_foods[:] # 切片操作会对列表这个序列复制一个副本进行操作
my_foods.append("cannoli")
friend_foods.append("ice cream")
print(f"My foods are:\n{my_foods}") # ['pizza', 'falafel', 'carrot cake', 'cannoli']
print(f"My friend's foods are:\n{friend_foods}") # ['pizza', 'falafel', 'carrot cake', 'ice cream']
#示例二:直接列表变量赋值,这种做法实际上是让新变量friend_foods关联到与my_foods相关联的列表,
#因此这二个变量指向同一个列表
my_foods = ['pizza', 'falafel', 'carrot cake']
friend_foods = my_foods # 若是这样的话就不能得到二个列表。这里是将my_foods赋给friend_foods,而不是my_foods的副本。
my_foods.append("cannoli")
friend_foods.append("ice cream")
print(f"My foods are:\n{my_foods}") # ['pizza', 'falafel', 'carrot cake', 'cannoli', 'ice cream']
print(f"My friend's foods are:\n{friend_foods}") # ['pizza', 'falafel', 'carrot cake', 'cannoli', 'ice cream']4)创建数值列表
借助range创建数值列表
range()函数的返回值是一个整数序列(这个序列是不可变的)。要创建数值列表,可使用list()函数将range()的返回结果转换为列表。如果将range()作为list()的参数,输出将是一个数值列表。
有几个Python函数可以处理数值列表,比如,可以使用min(), max(), sum()
numbers = list(range(6))
print(numbers) # [0, 1, 2, 3, 4, 5]
numbers = list(range(1, 6))
print(numbers) # [1, 2, 3, 4, 5]
numbers = list(range(2, 11, 2))
print(numbers) # [2, 4, 6, 8, 10]
#使用下面代码来生成一个squares列表
squares = []
for value in range(1, 11):
squares.append(value**2)
print(squares) #[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
print(min(squares)) # 1
print(max(squares)) #100
print(sum(squares)) #385列表推导式
前面的生成squares数值列表的方式包含好几行代码,而列表推导式只需要编写一行代码就能生成这样的列表。列表推导式将for循环和创建新元素的代码合并成一行,并自动追加新元素。
squares = [vaule**2 for vaule in range(1, 11)] #注意这里for语句末尾没有冒号
print(squares) #[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
.....................................................................................................................
元组(tuple, 元组是不可变的,不可变的列表称为元组)
列表非常适用于存储在程序运行期间可能变化的数据集,列表是可以修改的。然而有时候需要创建一系列不可修改的元素,元组可满足这种要求。Python将不能修改的值称为不可变的,而不可变的列表称为元组。相比于列表,元组是更简单的数据结构,如果需要存储一组在程序的整个声明周期内都不变的值,就可以使用元组。
1)将可迭代对象转为元组
#返回一个新的 tuple 对象,其元素来自于 iterable,如果未指定iterable,则将返回空元组
tuple([iterable])2)定义元组
元组看起来很像列表,但适用圆括号而不是方括号来标识,这里需要注意其实严格来说,元组是由逗号标识的,圆括号只是让元组看起来更加整洁清晰,如果知只定义包含一个元素的元组,必须在这个元素后面加上逗号,比如:
my_t = (3,)
print(my_t) # (3,)
my_t = 3, # 3,会封包成一个元组
print(my_t) #(3,)
my_t = (3) #不写逗号的话会输出数值3,这里的括号仅起一个优先级的作用
print(my_t) #3
3)操作元组
定义好元组后,就可以使用用索引、切片等来访问和遍历其元素,就像列表一样。
虽然不能修改元组的元素,但可以给表示元组的变量赋值,例如:
dims = (200, 50) #这里存储一个长宽不变的矩形
print('Origin dims:')
for dim in dims:
print(dim)
dims = (400, 100) #定义一个新元组,赋值给原元组变量
print('modified dims:')
for dim in dims:
print(dim).....................................................................................................................
运算符使用的一些细节
1)赋值运算符
增强的赋值运算符(+=、//=、**= 等)
# a+=b为原地操作,a = a+b为新建操作
lis1 = [1, 2]
lis2 = lis1
lis1 = lis1 + [3, 4]
print(lis1) # [1, 2, 3, 4]
print(lis2) # [1, 2]
lis1 = [1, 2]
lis2 = lis1
lis1 += [3, 4]
print(lis1) # [1, 2, 3, 4]
print(lis2) # [1, 2, 3, 4]# //=取整赋值运算符
a = 3
c = 7
c //= a
print(c) # 2:= 海象运算符(Python3.8新增)
# 海象运算符,可在表达式内部为变量赋值,记得加括号,不然就是赋值len(string) + 5的返回值了
string = "hello world"
print((length := len(string)) + 5) # 16
print(f"string的长度为{length}") # string的长度为11序列赋值
#可以在一行代码给多个变量赋值,这种做法常用于将一些列整数赋给一组变量:
x, y, z = 1, 2, 3
a, b = 3, 4 # 等同于 (a,b) = (3,4)
print(a, b)
(a, b) = (3, 4)
print(a, b)
[a, b] = [3, 4]
print(a, b)
a, b, c = [3, 4, 5]
print(a, b, c)
a, b, c = "你好吗"
print(a, b, c)多目标赋值
a = b = c = [1, 2, 3]
b.append(4)
print(a, b, c) # [1, 2, 3, 4] [1, 2, 3, 4] [1, 2, 3, 4]2)逻辑运算符(优先级not>and>or)
and:左边为加,返回左边,否则返回右边
or:左边为真,返回左边,否则返回右边
not:假,返回True;真,返回False
# None, False, 0, 空字符串/空列表/空元组/空字典/空集合都会被认定为 False
a = 2
b = "hello world"
c = []
d = 0
# 左边为假,返回左边;否则返回右边
print(c and a) # []
print(c and d) # []
print(d and c) # 0
print(a and c) # []
print(a and b) # "hello world"
print(b and a) # 2
# 左边为真,返回左边;否则返回右边
print(a or c) # 2
print(a or b) # 2
print(b or a) # "hello world"
print(c or a) # 2
print(c or d) # 0
print(d or c) # []
# 假,返回真;真,返回假
print(not a) # False
print(not b) # False
print(not c) # True
print(not (a and c)) # True
# 优先级:not > and > or
print(not a or c) # []#all(iterable):如果 iterable 的所有元素均为真值(或 iterable 为空)则返回True
#any(iterable):如果 iterable 的任一元素为真值则返回 True(可迭代对象为空,返回 False)
print(all(['False', 'None', ' ', '0']))
print(any([False, None, '', 0]))3)成员运算符:in和not in
str1 = "hello world"
list1 = [1, 2, 3, 4, 5]
tuple1 = (1, 2, 3, 4, 5)
set1 = {1, 2, 3, 4, 5}
a = "hel" in str1
b = 4 in list1
c = 4 in tuple1
d = 4 in set1
print(a,b,c,d) # True True True True
a = "hel" not in str1
b = 4 not in list1
c = 4 not in tuple1
d = 4 not in set1
print(a,b,c,d) # False False False False4)身份运算符:is和not is
#is用于判断两个标识符是不是引用自一个对象,类似判断 id(a) == id(b)
#is not判断两个标识符是不是引用自不同对象,类似判断 id(a) != id(b)
a = 257
b = 257
print(a == b)
print(a is b)
print(id(a))
print(id(b))
a = 256
b = 256
print(a == b)
print(a is b)
print(id(a))
print(id(b)).....................................................................................................................
条件结构和循环结构使用注意点
1)条件语句(Python并不要求if - elif结构后面必须有else代码块)
三元表达式
score = 77
result = print("优") if score >= 90 else print("良") if score >= 80 else \
print("及格") if score >= 60 else print("差")
print(result)2)for...in和for...in...else的区别:前者在break后执行else后的语句
'for 变量 in 可迭代对象
执行语句......
'
# 输出结果为1 5 2 5 3
for i in [1, 2, 3, 4]: #这里的冒号告诉Python,下一句是循环的第一行
print(i)
if i > 2:
break
print(5)
#输出结果为1 2 3,由此可见,break后不会执行print(5)
for i in [1, 2, 3, 4]:
print(i)
if i > 2:
break
else:
print(5)
3)while...else和while的区别:前者在break后执行else后的语句
#输出结果为:first secod
count = 0
while True:
print('first')
count = count + 1
if count >= 1:
break
print('second')
#输出结果为:first
count = 0
while True:
print('first')
count = count + 1
if count >= 1:
break
else:
print('second').....................................................................................................................
函数使用的一些注意点
def f(x):
print(x)
#fun和f关联的地址相同?
fun = f
print(id(f))
print(id(fun))
#输出结果
2049674338800
2049674338800带*的形参是不定长参数,只能接受位置参数(打包成元组),不能接受关键字参数(“a = xxx”的形式)。带**的形参也是不定长参数,该参数要永远放在形参列表的最后面,只能接受关键字参数(将关键字参数打包成字典),不能接受位置参数。
def fun(**kwargs):
print(kwargs) # {'a': 1, 'b': 2, 'c': 3, 'd': 4}
fun(a=1, b=2, c=3, d=4).....................................................................................................................
Python中的其他一些细节
1)PyCharm的一些快捷键
ctrl + p 显示函数的参数信息
ctrl + ? 批量注释/批量去掉注释,另外还可以在选中要注释的内容后按单引号或者双引号来多行注释
home 把光标移动到行的开头
end 把光标移动到行的结尾
ctrl + r 替换
shift + enter 在当前行下方新建一行
ctrl + alt + enter 在当前行上方新建一行2)anaconda
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
3)拼接
显式的行拼接:Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠(\)来实现多行语句
""" 下面 a,b 两种写法都是可以的,结果是一样的 """
a = 1 + 2 + 3
b = 1 + \
2 + \
3隐式的行拼接:圆括号、方括号或花括号以内的多行语句,无需使用反斜杠(\)
month_names = ['Januari', 'Februari', 'Maart', #These are the
'April', 'Mei', 'Juni', #Dutch names
'Juli', 'Augustus', 'September', # forthe months
'Oktober', 'November', 'December'] # ofthe year4)注释
Python中,注释使用井号来标识
5)查询关键字和查询内置函数的方法
#查关键字方法1
help("keywords")
#查关键字方法2
import keyword
print(keyword.kwlist)
#查内置函数
import builtins
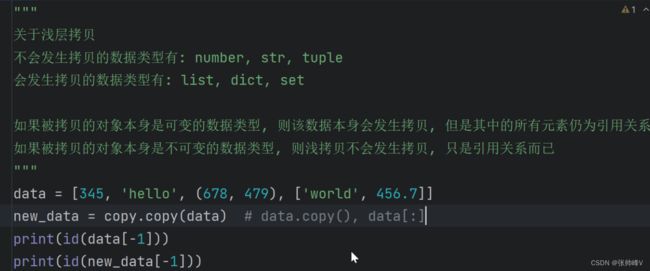
print(dir(builtins))6)浅拷贝和深拷贝