MySQL索引优化实战&EXPLAIN解析
先来介绍一下具体的业务场景
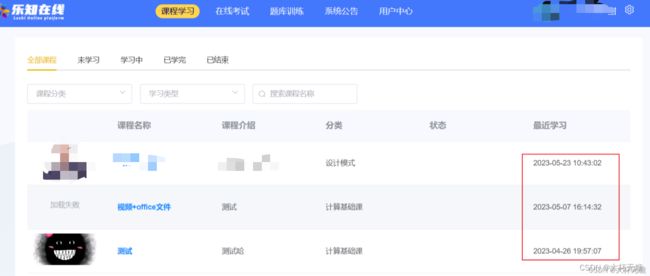
当用户登录后,需要查看能够学习的课程,不同的用户看到的课程是不同的,课程存在权限,权限是被下面lesson_user_permissions表控制的,其中sys_user_id 和 lesson_id 作为联合主键
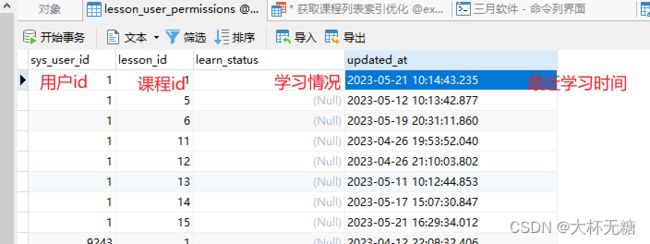
另外还有一个lesson表

我们的业务需求是,根据最近学习时间来降序排列课程。
最初的逻辑大致逻辑
从token里面取出来用户id,然后去lesson_user_permissions表里面找出来所有的lesson_id,然后根据lesson_id集合再去lessons表里面去查找数据,把两个表的数据拼在一起,然后再对结构体对象根据最近学习时间来进行降序排列。
使用索引和连表查询进行优化的思路
我们对lesson_user_permissions建立联合索引,联合索引的三个字段是sys_user_id 升序,updated_at降序,lesson_id降序。 这时在查lesson_user_permissions表的时候,我们查出来的lesson_id已经是根据updated_at排好序的了。然后我们拿着排好序的lesson_id直接根据主键去查找课程就行。
查看了一下navicat,发现其通过可视化的页面 无法建立降序的索引 ,navicat肯定也有终端命令行
然后再终端中执行对表建立索引的命令
![]()
SQL语句如下:
Explain
select l2.name,l1.updated_at from lesson_user_permissions as l1 INNER JOIN lessons as l2
where l1.lesson_id = l2.id and l1.sys_user_id = 1 ORDER BY l1.updated_at DESC
Explain结果如下

我们刚好可以使用此结果去对照我们学习的理论知识
解析Explain
一、id
两个字段的id都是1

和上面的理论完成相同,我们就不再过多说明了
二、select_type
我们一个大查询的里面实际上是包含了很多的小查询,这个字段就表差每次小查询的查询类型。这个字段有好几个取值,上面的结果是SIMPLE,除了SIMPLE,还有PRIMARY,UNION等等,既然没有用到,就不再展开了。 解释一下SIMPLE的含义,查询语句中不包含UNION或者子查询的查询都算作是SIMPLE类型 。 我们上面的两条记录都符合这个要求,所以是SIMPLE。
三、table
就是查询表的名称
四、partitions 忽略即可
五、type 是对这个表进行查询的访问方法 (单表访问方式)
MySQL单表访问方式具体细节:单表访问方式range_大杯无糖的博客-CSDN博客
完整的访问方法如下:system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL。
我们第一个表的查询方式是ref ,我们来具体分析一下,再看一下原来的SQL语句
select l2.name,l1.updated_at from lesson_user_permissions as l1 INNER JOIN lessons as l2
where l1.lesson_id = l2.id and l1.sys_user_id = 1 ORDER BY l1.updated_at DESC对于lesson_user_permissions 的访问过程中,l1.lesson_id = l2.id and l1.sys_user_id = 1 是筛选条件,我们忽略前面的筛选条件,只看只后面的筛选条件 l1.sys_user_id = 1
ref 访问方式的定义是:某个普通的二级索引列与常数进行等值比较 。
首先我们上面建立的索引idx_userId_updatedAt_lessonId_desc 的最左方的列是userId,如果不是最左方的话,应该是不行的。 至于为什么是最左边的列才可以,此处不再详细介绍了,大家知道结论就可以了。我们使用了联合索引的一部分进行等值查询, 同时我们还满足是等值查询,所以我们此处的访问方法是ref 。
接下来分析第二个表的访问方法PRIMARY,此处就很好理解了,我们是通过lesson_user_permissions表的lesson_id 去lessons表中查询,l1.lesson_id = l2.id 此时这个筛选条件 就发挥作用了,最终lessons是根据主键进行查询的。
上面分析可能是有些模糊,我们来通过理论详细的分析一下,连表查询的过程,这样能更加清楚的理解第二个表的查询过程。
那么这个连接查询的大致执行过程如下(连表查询原理):
- 选取驱动表,选取lesson_user_permissions作为驱动表,找到该表的筛选条件 sys_user_id = 1,选取访问方法ref 进行访问,然后拿到结果集。
- 针对从驱动表中取出来的结果集中的每一条记录,分别到 lessons表中查找记录,此时,对于lessons表来说,筛选条件 l1.lesson_id = l2.id 就变了,比如说此时 l2.id = 5 ,这个5 就是在第一步查找的结果集中的一条,然后此时lessons表 就是通过主键查询了,通过主键进行等值查询,效率最快, 按照正常情况,此处的type字段应该是const,但是却显示了一个 eq_ref, 我们来看一下eq_ref的具体含义:在连接查询的时候,被驱动表是通过主键或者唯一二级索引列进行等值匹配的方式进行访问 。 完全符合我们的情况。

下面是possible_keys,该字段是可能用到的索引,后面的key是具体用到索引

可以看到,对于lesson_user_permissions来说,可能用到的索引possible_keys有PRIMARY,idx_userId_updatedAt_lessonId_desc,实际用到的索引key是idx_userId_updatedAt_lessonId_desc 。 关于为什么lesson_user_permissions用到的索引是 idx_userId_updatedAt_lessonId_desc ,而不是联合主键中的一个主键做索引,是有理论支持的,同时这也是我们故意设计成这样的,从而达到对索引的优化。 具体原理如下:
我们先来查看一下,一个表里面的所有的索引的情况(解析表的索引情况)

通过Non_unique我们可以知道,这个表里面有两个索引,Key_name是索引的名称,Non_unique,Seq_in_index 两个字段共同得知,两个索引都是联合索引,Seq_in_index是联合索引中的字段排序,Column_name 则是排序字段的具体名称,Collation是该索引字段是升序还是降序排列。
Cardinality表示索引列中不重复值的数量的估计值,我们看第一行sys_user_id的该值是377,也就是说,在整个表里面,存储了337位不同同学的id,这个值很正常,因为小组差不多就是这么多号人。 第二行updated_at对应的是1536,这个也正常,因为几乎所有的时间都是不同的。然后第三行代码的是lesson_id,表明这个表里面有1575门不同的课,这个就不正常了,暂时保留疑问,后面再说。
Sub_part 对于存储字符串或者字节串的列来说,有时候我们只想对这些前n个字符或者字节建立索引,那么这个属性表示的就是那个n值。 如果对完整的列建立索引的话,该属性的值就是Null。
Packed,忽略
Null代表 该索引列 是否被存储为Null值
Index_type 使用索引的类型,我们最常见的就是BTREE,B+树索引
Comment 索引列注释信息
Index_comment 索引注释信息
那么为什么会选用我们自己建立的组合索引,而不是选择主键索引呢?(索引适用条件&索引成本分析)
再来查看一下SQL语句
select l2.name,l1.updated_at from lesson_user_permissions as l1
INNER JOIN lessons as l2
where l1.lesson_id = l2.id
and l1.sys_user_id = 1
ORDER BY l1.updated_at DESC根据连表查询连接原理分析,我们可以得知,lesson_user_permissions作为驱动表,我们进行单表方法的时候,筛选条件是 l1.sys_user_id = 1 ORDER BY l1.updated_at DESC ,我们有两个索引PRIMARY,idx_userId_updatedAt_lessonId_desc,选用idx_userId_updatedAt_lessonId_desc 自建索引的关键在于 我们是用了updated_at进行降序排列。 因为idx_userId_updatedAt_lessonId_desc 就是先根据userid升序,然后再根据updated_at进行降序排列,如果我们使用了idx_userId_updatedAt_lessonId_desc ,直接就是排好序的。 如果我们使用PRIMARY的话,我们还要再次排序。
为了验证这一点,我们重新写一个SQL,把降序改成升序(不写降序默认就是升序)
select l2.name,l1.updated_at from lesson_user_permissions as l1
INNER JOIN lessons as l2
where l1.lesson_id = l2.id
and l1.sys_user_id = 1
ORDER BY l1.updated_at
这个时候,我们的自建索引idx_userId_updatedAt_lessonId_desc 就不再生效了。
我们再往后面看其他的字段
六、key_len
这个代表的是当优化器觉得使用某个索引执行查询的时候,该索引记录的最大长度,它由下面的三部分构成:
- 对于固定长度类型的索引列来说,他实际占用的存储空间的最大长度就是该固定值,对于指定字符集的变长类型的索引列来说,比如说索引列的类型是VARCHAR(100),使用的字符集是utf8,那该列实际占用的最大存储空间就是100 * 3 = 300 个字节。
- 如果索引列可以存储NULL值,则key_len比不可以存储NUll值时多1个字节
- 对于变长字段来说,都会有2个字节的空间来存储该变长字段的实际长度
这就很好解释为什么我们查出来的两条记录都是8的原因了
在lesson_user_permissions表中,我们用的是idx_userId_updatedAt_lessonId_desc索引,按照我的预想,第一个字段user_id肯定是用上了,第二个字段updated_at也一定是用上了,这个时候,key_len一定是大于8的,应该是8+8+8 = 24 ,但是此时的结果却是 8,我暂时没有分析出来这个原因。 如果有知道的大佬可以评论区解释一下。
在lessons表中,我们使用主键索引,主键的类型是bigint类型,主键不能是空,主键是定长字段,所以就是8。
七、ref
代表的含义是:当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const 、eq_ref 、ref_or_null 、unique_subquery、index_subquery的时候,ref列 展示的就是与索引列做等值匹配的东西,比如说是个常数,或者是一个列

在 lesson_user_permissions驱动表中,ref 是const ,说明在使用 idx_userId_updatedAt_lessonId_desc 的时候,与user_id列做等值匹配的是一个常数1
在 lessons 被驱动表中,访问方式是eq_ref,对应的ref列的值是exam.l1.lesson_id,这说明在对被驱动表进行访问的时候会用到PRIMARY索引,也就是聚簇索引会与一个列进行等值匹配的条件,于lessons表做等值匹配 的对象就是exam.l1.lesson_id,l1就是 lesson_user_permissions表。
八 、 rows
如果查询优化器决定使用全表扫描的方式对某个表执行查询的时候,执行计划的rows列就代表预计需要扫描的行数,如果使用索引来执行查询时,计划执行的rows 列的代表预计扫描的索引记录行数。
九、filtered
这个字段比较陌生,我们详细介绍一下,我们之前说过MySQL中查询采取的是循环嵌套连接算法,驱动表被访问一次,被驱动表可能会被访问多次,所以对于两表连接查询来说,他的查询成本有两部分组成:一是单次查询驱动表的成本,二是多次查询被驱动表的成本(具体查询多少次取决于对驱动表查询的结果集有多少条记录)
我们把对驱动表查询得到的条数称之为扇出。 扇出值越小,对被驱动表的查询次数也越少,连接查询的总成本也就越低。 当查询优化器想计算整个联查查询所使用的成本时,就需要计算驱动表的扇出值。
有时候扇出值的计算很容易,比如说对驱动表全表扫描,或者是通过二级索引来查询。
不容易计算的情况有,对驱动表查询的时候没有索引的字段,只有非索引字段,或者是有索引字段,但是同时也有非索引字段,或者是有多个索引字段,这个时候我们只能确定适用一个索引字段,那这个时候,另外的索引字段就不再是索引字段了。
如果不是索引字段的筛选,查询优化器又不会真的去执行,那就只能考猜了。
如果使用的是全表扫描的方式执行的单表查询,那么计算驱动表扇出值的时候需要猜满足搜索条件的记录到底有多少条。
如果使用的是索引执行的单表扫描,那么计算驱动表扇出的时候需要猜 满足除了使用对应索引列的搜索条件外的其他搜索条件的记录有多少条。
这个猜的过程就是condition filtering。
我们此处的值是100 ,原因就是我们没有除了索引列之外的查询条件。
十、Extra
说明一些额外情况,通过这个额外信息,我们可以更加准确的理解MySQL到底将如何执行给的查询语句。 这里面有好多的情况,我们本次该字段的结果是 Using index。 这个字段的意思是:当我的查询列表以及搜索条件中只包含属于索引的列,也就是可以使用索引覆盖的情况下,在Extra将会提示该额外信息。这说明,我们确实是通过idx_userId_updatedAt_lessonId_desc 来进行排序了,没有执行回表操作。
Explain到此算是没了,但是我们没有看到执行索引去查询的时候的成本。 如果想要查看执行成本的话,可以使用下面的方法
Explain FORMAT = JSON
select l2.name,l1.updated_at from lesson_user_permissions as l1
INNER JOIN lessons as l2
where l1.lesson_id = l2.id
and l1.sys_user_id = 1
ORDER BY l1.updated_at Desc
{
"query_block": {
"select_id": 1, #整个查询只有一个SELECT关键词,该关键字对应的id号是1
"cost_info": {
"query_cost": "3.85" #执行整个查询的成本预计
},
"ordering_operation": {
"using_filesort": false, #没有使用文件排序
"nested_loop": [ #几个表之间采用嵌套循环连接算法执行
{
"table": {
"table_name": "l1", #l1是驱动表
"access_type": "ref", #访问方式
"possible_keys": [ #可能用到的索引
"PRIMARY",
"idx_userId_updatedAt_lessonId_desc"
],
"key": "idx_userId_updatedAt_lessonId_desc", #用到的索引
"used_key_parts": [ #用到的索引的字段
"sys_user_id"
],
"key_length": "8", #索引长度
"ref": [ #当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const 、eq_ref 、ref_or_null 、unique_subquery、index_subquery的时候,ref列 展示的就是与索引列做等值匹配的东西
"const" #代表是一个常数
],
"rows_examined_per_scan": 8, #查询一次驱动表大约要扫描8条数据
"rows_produced_per_join": 8, #驱动表的扇出是8条
"filtered": "100.00", #满足除了索引列筛选条件条件之外的数据/满足索引条件筛选后的数据
"using_index": true, #是否出现了索引覆盖
"cost_info": {
"read_cost": "0.25", #下面重点介绍
"eval_cost": "0.80",#下面重点介绍
"prefix_cost": "1.05",#下面重点介绍
"data_read_per_join": "320"#下面重点介绍
},
"used_columns": [ #该表中使用到的列,也就是返回给用户的结果中包含的列
"sys_user_id",
"lesson_id",
"updated_at"
]
}
},
{
"table": {
"table_name": "l2",
"access_type": "eq_ref",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"id"
],
"key_length": "8",
"ref": [
"exam.l1.lesson_id"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 8,
"filtered": "100.00",
"cost_info": {
"read_cost": "2.00",
"eval_cost": "0.80",
"prefix_cost": "3.85",
"data_read_per_join": "54K"
},
"used_columns": [
"id",
"name"
]
}
}
]
}
}
}read_cost 由两部分组成:IO成本 + 检测 rows * (1 - filter) 条记录的cpu成本
eval_cost 是检测 rows * filter条记录的成本
prefix_cost 单独查询s1表的成本 read_cost + eval_cost
data_read_per_join 表示在此次查询中需要读取的数据量
总结
知识不光要学习,还要应用。 用理论指导实践,实践来进一步检验理论。
遗留问题
我们在使用Explain 的时候,我们可以查看到可能用到的索引和实际用到的索引,但是我们无法看命MySQL是如何在如何具体的选出来这个实际用到的索引,这里面就牵扯到了MySQL决定选用哪个索引的成本计算。 这些内容准备写在下一篇博客中。