FPGA_学习_11_IP核_RAM_乒乓操作
本篇博客学习另一个IP核,RAM。 用RAM实现什么功能呢? 实现乒乓操作。 乒乓操作是什么呢?
参考:
FPGA中的乒乓操作思想_fpga中乒乓操作的原因_小林家的龙小年的博客-CSDN博客
何为乒乓操作_fanyuandrj的博客-CSDN博客
以下是本人理解:
乒乓操作可以实现低速模块处理高速数据,这种处理方式可以实现数据的串并转换,就是数据位宽之间的转换,是面积与速度互换原则的体现。
例如:
数据位宽的转换,要将8位的数据转换为16位,按照传统方法,每两个时钟周期完成一次转换,输出数据的变化与时钟信号不是同步的。使用乒乓操作,数据写入数据缓冲模块的时候使用50M的时钟,读出时使用25M的时钟,每次读出16位,这样不仅实现了数据位宽的转换,还使得输出的数据可以被一个低速的时钟同步。

乒乓骚操作1:
假设输入数据的时钟50Mhz,100个8位的数据先写入 数据缓冲模块1, 然后再100个8位的数据写入 数据缓冲模块2,与此同时,输出模块读取 数据缓冲模块1的数据。 如果输出模块读取时钟也是50Mhz, 待100个8位的数据已存入 数据缓冲模块2时, 先前写入 数据缓冲模块1的100个8位的数据,已经被输出模块读取完了。
下面再次把100个8位的数据先写入 数据缓冲模块1,与此同时,输出模块读取 数据缓冲模块2的数据。 如果输出模块读取时钟也是50Mhz, 待100个8位的数据已存入 数据缓冲模块1时, 先前写入 数据缓冲模块2的100个8位的数据,也已经被输出模块读取完了。
如此循环,就可以,... 嗯,... , 我反正暂时不清楚这个操作有什么意义。
乒乓骚操作2:
假设输入数据的时钟50Mhz,100个8位的数据先写入 数据缓冲模块1, 然后再100个8位的数据写入 数据缓冲模块2,与此同时,输出模块读取 数据缓冲模块1的数据。 如果输出模块读取时钟也是25Mhz, 待100个8位的数据已存入 数据缓冲模块2时, 要想把先前写入 数据缓冲模块1的100个8位的数据全部取出,输出模块读取的位宽得1次读16位。
50Mhz 8位宽的写100的时间 = 25Mhz 16位宽的读50次的时间。
下面再次把100个8位的数据先写入 数据缓冲模块1,与此同时,输出模块读取 数据缓冲模块2的数据。 如果输出模块读取时钟是25Mhz读取位宽是16位, 待100个8位的数据已存入 数据缓冲模块1时, 先前写入 数据缓冲模块2的100个8位的数据,也已经被输出模块读取完了,50个16位。
如此循环,好像有那么点意思了,连续的 50M 8位宽数据,变成了连续的25M 16位宽的数据。 时钟变慢了,位宽变大了。
本文先尝试实现乒乓骚操作1,后续如果我功力深厚了再来尝试实现乒乓骚操作2
1 RAM IP核配置步骤
(Vivado 赛灵思)
截图warning!
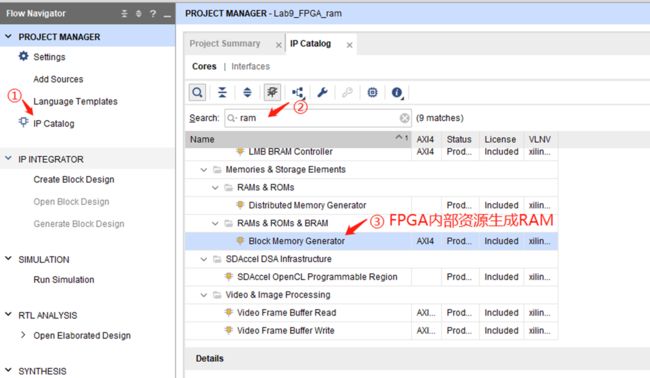
Block Memory Generator是用FPPA内部专用存储资源给你生成RAM。
上面Distributed Memory Generator这个是用D触发器和查找表来帮你实现的RAM。
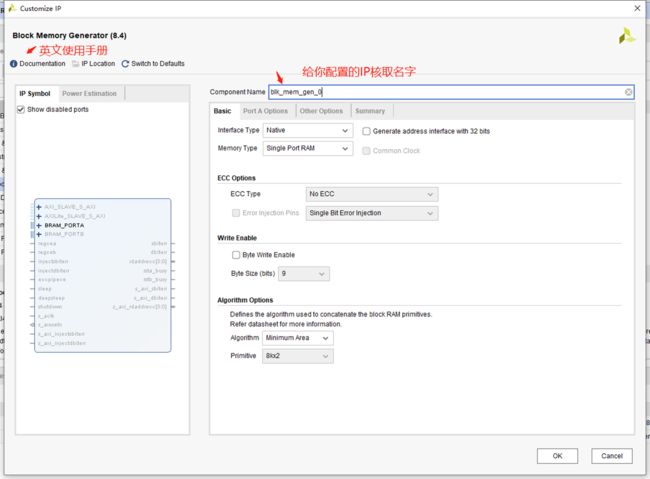
我取名IP_RAM
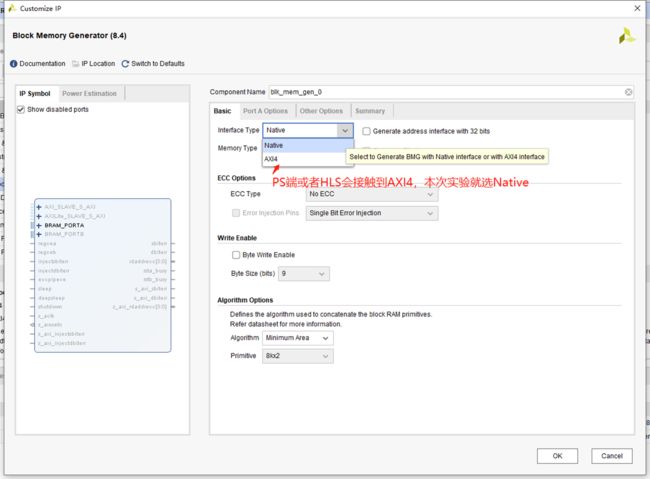
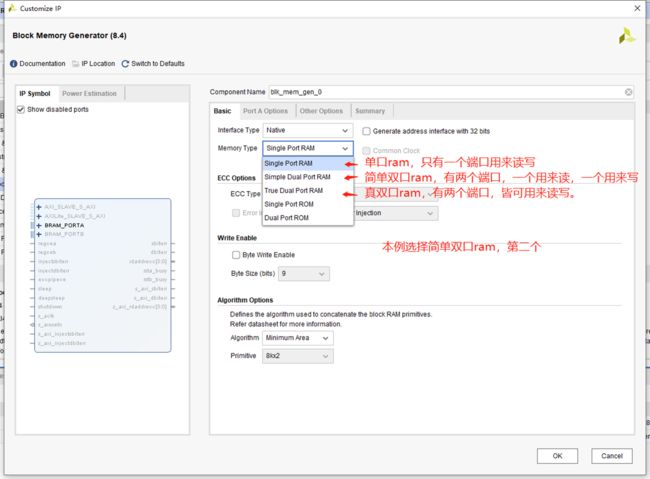
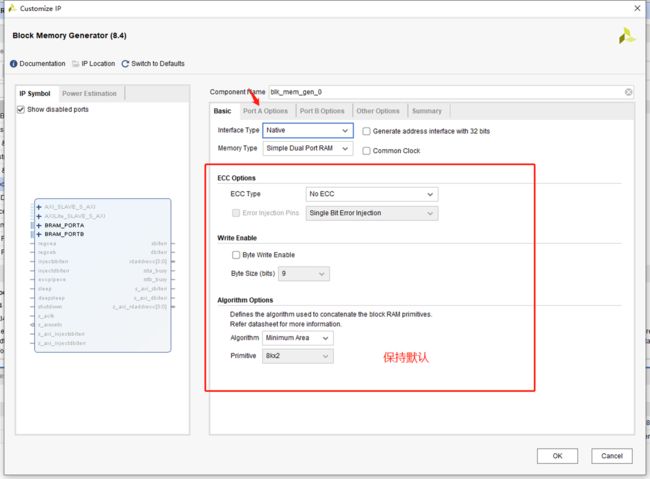
 本次实验位宽为8,深度为256
本次实验位宽为8,深度为256



 OK后,后面的弹窗你就一顿OK,下一步就可以了。
OK后,后面的弹窗你就一顿OK,下一步就可以了。

我们是看Verilog的例化模板。
2 时序图

乒乓操作是要例化两个简单双口RAM的IP核的,绿线上面例化的第一个简单双口RAM→RAM1的相关时序,绿线下面是例化的第而个简单双口RAM→RAM2的相关时序。
RAM_wea_d表示RAM_wea延迟(delay)一拍,可用于指示当前是RAM1输出有效还是RAM2的输出有效。
画时序图是费劲的活儿,但是画完自己的理解确实也会更进一分。
{signal: [
{name: 'clk', wave: 'p...........................................' },
{},
{name: 'rst_n', wave: '01..........................................' },
{},
{name: 'RAM1_wea', wave: '01....0....1....0....1....0....1....0....1..' },
{},
{name: 'RAM1_addra', wave: '2.22222.....22222.....22222.....22222.....22' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{name: 'RAM1_dina', wave: '2.22222.....22222.....22222.....22222.....22' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{},
{name: 'RAM1_addrb', wave: '2......22222.....22222.....22222.....22222..' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{name: 'RAM1_doutb', wave: '2.......22222.....22222.....22222.....22222.' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{},
{name: 'RAM2_wea', wave: '0.....1....0....1....0....1....0....1....0..' },
{},
{name: 'RAM2_addra', wave: '2......22222.....22222.....22222.....22222..' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{name: 'RAM2_dina', wave: '2......22222.....22222.....22222.....22222..' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{},
{name: 'RAM2_addrb', wave: '2.22222.....22222.....22222.....22222.....22' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{name: 'RAM2_doutb', wave: '2..22222.....22222.....22222.....22222.....2' , data: ['0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255','0','1','2','...','255']},
{},
{name: 'RAM1_wea_d', wave: '0.1....0....1....0....1....0....1....0....1.' },
{}
]}
3 测试代码
本博客先暂时只实现第一种乒乓操作
`timescale 1ns / 1ps
module ram_pp(
input wire clk ,
input wire rst_n ,
output reg [7:0] dout
);
//==================================================================
// Parameter define
//==================================================================
parameter MAX = 256 - 1;
//==================================================================
// Internal Signals
//==================================================================
// 一个简单双口RAM的IP里面,a代表写,b代表读
reg RAM1_wea ; // 写-使能
reg [7:0] RAM1_addra ; // 写-地址
wire [7:0] RAM1_dina ; // 写-数据
reg [7:0] RAM1_addrb ; // 读-地址
wire [7:0] RAM1_doutb ; // 读-数据
reg RAM2_wea ;
reg [7:0] RAM2_addra ;
wire [7:0] RAM2_dina ;
reg [7:0] RAM2_addrb ;
wire [7:0] RAM2_doutb ;
reg RAM1_wea_d ; // RAM1的写使能延迟一拍
IP_RAM inst_RAM1 (
.clka(clk), // input wire clka 写-时钟
.wea(RAM1_wea), // input wire [0 : 0] wea 写-使能
.addra(RAM1_addra), // input wire [7 : 0] addra 写-地址
.dina(RAM1_dina), // input wire [7 : 0] dina 写-数据
.clkb(clk), // input wire clkb 读-时钟
.addrb(RAM1_addrb), // input wire [7 : 0] addrb 读-地址
.doutb(RAM1_doutb) // output wire [7 : 0] doutb 读-数据
); // 谨记:不要同时读写同一地址的数据。
IP_RAM inst_RAM2 (
.clka(clk), // input wire clka 写-时钟
.wea(RAM2_wea), // input wire [0 : 0] wea 写-使能
.addra(RAM2_addra), // input wire [7 : 0] addra 写-地址
.dina(RAM2_dina), // input wire [7 : 0] dina 写-数据
.clkb(clk), // input wire clkb 读-时钟
.addrb(RAM2_addrb), // input wire [7 : 0] addrb 读-地址
.doutb(RAM2_doutb) // output wire [7 : 0] doutb 读-数据
);
// 在对RAM1做写操作的时候,与此同时对RAM2做读操作
// 对RAM1做写操作完成,RAM2的做读操作也会完成,此时则对RAM1做读操作,对RAM2做写操作
// 对RAM2做写操作完成,RAM1的做读操作也会完成,此时则对RAM2做读操作,对RAM1做写操作
// 如此循环。
// 上面的文字描述有点绕,但告诉了我们三个道理。
// 1、一个RAM在写,则另一个RAM必然在读,所以两个RAM的写使能是完全相反的电平。
// 2、当RAM2写完的时候,就到我RAM1写了,这时候RAM1写使能拉高。
// 3、当RAM1写完的时候,RAM1进入读操作,这时候RAM1写使能拉低。
//----------------------------- RAM1_wea -----------------------------
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM1_wea <= 1'b0;
end
// RAM2写完,到RAM1写,RAM1_wea拉高
else if ( RAM2_addra == MAX && RAM1_wea == 1'b0) begin
RAM1_wea <= 1'b1;
end
// RAM1写完,则RAM1变成读,RAM1_wea拉低
else if ( RAM1_addra == MAX && RAM1_wea == 1'b1) begin
RAM1_wea <= 1'b0;
end
else begin
RAM1_wea <= RAM1_wea;
end
end
//----------------------------- RAM2_wea -----------------------------
always @(*) begin
RAM2_wea <= ~RAM1_wea;
end
//----------------------------- RAM1_addra -----------------------------
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM1_addra <= 'd0;
end
else if (RAM1_wea == 1'b1) begin
if (RAM1_addra == MAX) begin
RAM1_addra <= 'd0;
end
else begin
RAM1_addra <= RAM1_addra + 1'b1;
end
end
else begin
RAM1_addra <= 'd0;
end
end
//----------------------------- RAM1_addrb -----------------------------
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM1_addrb <= 'd0;
end
else if (RAM1_wea == 1'b0) begin
if (RAM1_addrb == MAX) begin
RAM1_addrb <= 'd0;
end
else begin
RAM1_addrb <= RAM1_addrb + 1'b1;
end
end
else begin
RAM1_addrb <= 'd0;
end
end
//----------------------------- RAM2_addra -----------------------------
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM2_addra <= 'd0;
end
else if (RAM2_wea == 1'b1) begin
if (RAM2_addra == MAX) begin
RAM2_addra <= 'd0;
end
else begin
RAM2_addra <= RAM2_addra + 1'b1;
end
end
else begin
RAM2_addra <= 'd0;
end
end
//----------------------------- RAM2_addrb -----------------------------
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM2_addrb <= 'd0;
end
else if (RAM2_wea == 1'b0) begin
if (RAM2_addrb == MAX) begin
RAM2_addrb <= 'd0;
end
else begin
RAM2_addrb <= RAM2_addrb + 1'b1;
end
end
else begin
RAM2_addrb <= 'd0;
end
end
//----------------------------- RAM1_dina -----------------------------
assign RAM1_dina = RAM1_addra;
//----------------------------- RAM2_dina -----------------------------
assign RAM2_dina = RAM2_addra;
//----------------------------- RAM1_wea_d -----------------------------
// 由于RAM的输出信号要延迟一拍
// 因此利用RAM1的写使能信号RAM1_wea,延迟一拍作为整个模块输出dout的读有效信号。
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
RAM1_wea_d <= 1'b0;
end
else begin
RAM1_wea_d <= RAM1_wea;
end
end
//----------------------------- dout -----------------------------
always @(*) begin
// RAM1_wea_d为高,则RAM1正在进行写操作,这时候不能读RAM1,而RAM2这时候正在输出,正好读RAM2的数据。
if (RAM1_wea_d == 1'b1) begin
dout <= RAM2_doutb;
end
// RAM1_wea_d为低,则RAM1正在进行读操作,这时候正好RAM1在输出,正好读RAM1
else begin
dout <= RAM1_doutb;
end
end
endmodule
这个代码里面的注释是目前为止我写的最多的啦,希望看了会帮助理解。
4 仿真代码
`timescale 1ns/1ps
module tb_ram_pp (); /* this is automatically generated */
parameter MAX = 256 - 1;
reg clk;
reg rst_n;
wire [7:0] dout;
ram_pp inst_ram_pp (.clk(clk), .rst_n(rst_n), .dout(dout));
initial begin
clk = 1;
forever #(10) clk = ~clk;
end
initial begin
rst_n <= 0;
#200
rst_n <= 1;
end
endmodule
这个仿真代码比较简单,因为咱们写的ram_pp模块本身的输入输出接口很少,所以不怎么操心,直接调用ram_pp模块就行了。
By the way,我用的Modelsim仿真,本文不讨论怎么搞Modelsim仿真。
5 仿真结果


刚仿真出来的时候我以为哪里有问题,因为发现第一个周期是没有输出的。 后来想明白了原因,因为更早之前RAM没写入任何数据,所以它第一个周期就应该没有输出。 另外,建议仿真的时长弄长一点(我用的30us),从第二个周期开始看。
仿真结果来看,实验和预期的目标时序是相符的,实验是成功的。