HDFS基础
文章目录
-
-
-
- HDFS基础
-
- 块
- HDFS的特点
- HDFS的组成
- fsimage和edit log
- HDFS的读写流程
- HDFS的数据完整性
- HDFS的可靠性保证
- HDFS的高可用
- HA的系统配置
- NameNode Federation(联邦)
- HDFS缓存
- HDFS权限控制
- 其他
-
-
HDFS基础
HDFS( Hadoop Distributed File System)是一个分布式的文件系统。
块
在HDFS中,文件被分割成一个个块(block)。在HDFS1.0中默认每个block 的大小是64M,在HDFS2.0中,默认每个block的大小是128M。例如某个文件大小为500M,那么在HDFS2.0中,文件会被分割为4个块,3个128M的和1个116M的。
多副本机制:在HDFS中每个block默认为3个副本,即有2个备份。副本数可以在hdfs-site.xml中通过配置dfs.relication来设置。dfs.replication.max设置副本的最大个数,默认为512。dfs.replication.min设置副本的最小个,默认为1.数dfs.datanode.data.dir 设置块在本机文件系统的存储地址。dfs.blocksize 块大小的设置。需要注意的是,3副本不是绝对的,当集群中的DataNode个数小于3的时候,则副本个数不为3
副本的存储策略:机架感知策略。第一个副本,在客户端相同的节点(如果客户端是集群外的一台机器,就随机算节点,但是系统不会挑选太满或者太忙的节点)。第二副本,放在不同的机架的节点(节点是随机的)。第三个副本,放在与第二个副本同机架但是不同节点上。
距离计算(用来判断连个DataNode的远近情况):
distance(/D1/R1/H1,/D1/R1/H1)=0 在同一个机房,同一个机架,同一个节点(机器)上,也就是同一个DataNode。distance(/D1/R1/H1,/D1/R1/H3)=2 在同一个机房,同一个机架,不同一个节点(机器)上。distance(/D1/R1/H1,/D1/R2/H3)=4 在同一个机房,不同一个机架distance(/D1/R1/H1,/D2/R1/H3)=6 不同机房
HDFS的特点
- 用来存储超大文件,不适合存储小文件。比如在HDFS2.0中一个文件块的大小事128M,那么就算小文件没有达到128M,它也会占用一个block。一个block的元数据信息大概是150字节。而元数据信息存储在NameNode的内存中的,所以量的小文件会造成Namenode内存的浪费。
- 可以构建在低成本的硬件上,对计算机的硬件要求不是很高。这一点主要归功于它的容错性。
- 不适合低延迟数据访问,HDFS的设计更多是的为了高数据吞吐量的应用,高吞吐量必然会需要更多的时间,因此不适合低延迟数据的访问。
- HDFS只支持单用户写入,并且只能以追加的方式写入,不支持在任意位置的修改
HDFS的组成
在HDFS1.0中有三部分组成:Namenode、SecondaryNamenode、Datanode。
-
Namenode:
1、管理者文件系统的命名空间,维护者文件系统树中的所有文件和目录。
2、存储元数据,元数据信息的种类有:文件名目录及它们之间的层级关系,文件目录的所有者及其权限,每个文件块的名及文件有哪些块组成
3、元信息里有两类很重要的映射数据:1、文件名–>block 2、block—>datanode 。当查找文件的时候,用户先通过Namenode找到datanode:文件名–>block---->datanode, 然后去找通过datanode找到block,datanode告诉用户block的path
4、Namenode中的数据以两种文件存储在本地:fsimage和edit log。当Namenode启动时,它从硬盘中读取edit log和fsImage,将所有edit log中的事务作用在内存中的fsImage上,并将这个新版本的fsImage从内存中保存到本地磁盘上,然后删除旧的edit log
-
SecondaryNamenode:可以看做是第二Namenode,但是它不是Namenode的备份,当节点出现故障的时候,它不会替代Namenode。Namenode只在启动的时候合并edit log和fsImage,因为在运行的过程中频繁的写fsImage会影响系统性能。而在运行的时候,随时间的推移会产生非常多的edit log,那么一旦Namenode重新启动,那么会花费非常多的时间来进行合并操作,而SecondaryNamenode就是用来帮助Namenode在其运行的时候替其合并edit log和fsimage 的。
-
DataNode:
1、负责存储数据块,负责为客户端提供数据块读写服务(数据的读写是直接和DataNode交互的)。
2、根据Namenode的指示进行创建、删除和复制等操作
3、心跳机制定期(3秒钟)报告块信息(例如DataNode的存储状态、工作状态等)。Namenode中
block—>datanode这一映射关系就是这样得到的。
4、DataNode之间进行通信,如副本拷贝。
fsimage和edit log
Namenode的元数据信息是加载在内存中的,但是数据存在内存中的话不安全,掉电会丢失,所以数据需要持久化到磁盘中。持久化的方式就是fsimage和edit log。
fsimage是元数据的镜像文件,存储某一段时间内的namenode内存元数据,存储在磁盘,在系统启动的时候加载。但是在系统运行期间,会产生一些新的元数据信息,这些新的元数据信息都保存在内存中并被持久化到另一个文件edit log中。
随着editlog不断增大,时间不断增加,SecondaryNamenode 会周期性合并fsimage和deits 合并成新的fsimage。

具体流程如上图所示:
- SecondaryNamenode通知Namenode,我要合并文件了,请将接下来产生的新的日志内容先写入到edits.new
- SecondaryNamenode通过http协议得到Namenode上的fsimage和edits
- SecondaryNamenode将fsimage与editlog合并,生成一个新的文件–fsimage.ckpt。这步之所以在SecondaryNamenode中进行,是因为比较耗时,如果在namenode进行,或导致整个系统卡顿。
- SecondaryNamenode将生成的fsimage.ckpt通过http协议发送至Namenode。
- Namenode将fsimage.ckpt重命名为fsimage替换掉原有的fsimage,将edits.new重命名为edits替换掉原有的edits。
触发SecondaryNamenode合并的条件:
- fs.checkpoint.period默认是3600秒,每隔一个小时,Secondarynamenode就要下载fsimage和edits,进行数据的同步。
- fs.checkpoint.sizeedits一直在变大。一旦达到,就要进行合并。只要达到这两个条件的其中一个,都会进行合并。
HDFS的读写流程
读流程

- 客户端(client)首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
- DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息,确定文件块的起始位置。对于每一个数据块,元数据节点返回保存数据块副本的DataNode的地址列表,这个列表根据DataNode和客户端之间的距离进行了排序。距离客户端近的排在前面。
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
- 如果第一块的数据读完了,就会连接关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
- 如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续,如果所有的块都读完,客户端调用FSDataInputStream.close()方法关闭流
- 如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像。
写流程

- 客户端(client)首先调用FileSystem对象的create方法,其实是一个DistributedFileSystem的实例
- DistributedFileSystem调用create方法创建新文件
- DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
- 前两步结束后会返回FSDataOutputStream的对象,与读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream。DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
- DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,依此类推。
- DFSOutputStream还有一个队列叫ack queue,也是由packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
- 如果在写的过程中某个datanode发生错误,会采取以下几步:1) pipeline被关闭掉;2)为了防止丢包ack queue里的packet会同步到data queue里;3)把产生错误的datanode上当前在写但未完成的block删掉;4)block剩下的部分被写到剩下的两个正常的datanode中;5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
- 客户端完成写数据后调用FSDataOutputStream.close()方法关闭写入流
- DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
- 需要注意的是,packet在传输的过程中,是先保存在内存中的,然后发送给下一个DataNode,不是持久化到磁盘后才发送的。另外ack信息是从后往前传的,与packet传递方向相反。在最后一个DataNode会对数据进行校验。
HDFS的数据完整性
HDFS通过对数据计算校验和(CRC32)来检查数据有没有被损坏,可以通过core-site.xml文件中的io.bytes.per.checksum来配置数据校验和的字节数,默认每512字节计算一次校验和。
- 客户端数据在写入HDFS的时候会,pipline的最后一个DataNode会计算校验和。
- 客户端数据在读取的时候也会计算校验和,如果检测到错误,会报告Namenode。
- 每个DataNode有一个后台进程DataBlockScanner,定期验证存储在这个节点上的所有数据块,如果数据块有问题,则会在心跳中告诉NameNode。
- 数据块的修复是指删除掉坏的数据块,从该数据块的其他副本中再复制出一个。
HDFS的可靠性保证
- 心跳机制,Namenode和DataNode之间维持心跳检测,当某一个DataNode出现问题,导致NameNode没有成功接收到心跳。NameNode接下来就不会将任何IO操作派发给该DataNode,该DataNode上的数据被认为是无效的,NameNode会检测当前集群中是否有文件的副本数小于设置值,如果小于,就会复制新的副本到其他的DataNode上。
- HDFS上的数据存储的时候都会设置多个副本。
- HDFS上的数据会通过校验和的方式来保证数据的完整性。
- SecondaryNamenode定期合并fsimage与editlog,并备份。
- 文件删除并不是马上从NameNode的命名空间移除,而是存放在.Trash目录,随时可以恢复,直到超过了设定的时间才真正删除,设置时间可以通过hdfs-site.xml中的fs.trash.interval决定,单位为秒。
HDFS的高可用
在HDFS2.0中,通过在同一个集群中运行两个NameNode(active NameNode和standby NameNode)来解决单点故障。
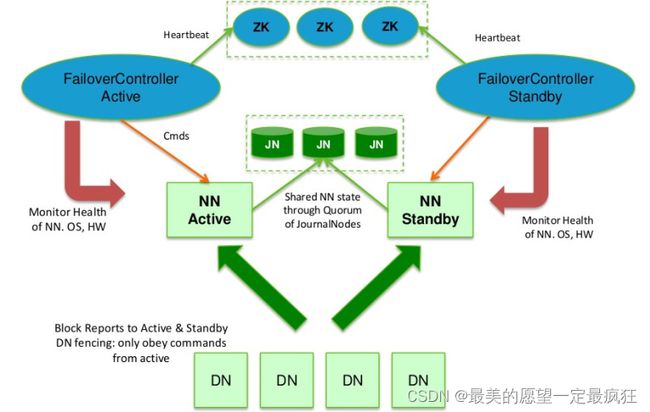
- 在任何时间,只有一台机器处于Active状态,另一台机器是处于Standby状态。
- active NameNode负责集群中所有客户端的操作。
- standby NameNode主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
- 为了保证数据的一致性,DataNode会向两个NameNode同时发送心跳
- JN (JournalNode)是一组守护进程,通常为奇数个,至少为3个。JournalNode守护进程是相对轻量级的。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的edit log。为了防止脑裂的发生,JNs只允许一个 NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态,这也是为什么JN推荐选用QJM,而不是NFS。
- JN通常有两种选择:一种是NFS(需要额外的磁盘空间),另外一种QJM(不需要空间)
- 通过zookeeper来实现active NameNode的切换。每个NameNode都有一个ZKFC(zookeeper FailoverController)进程,它们部署在同一个节点上。
QJM:最低法定人数管理机制,原理:用2n+1台JN机器存储editlog,每次写数据操作属于大多数(>=n+1)的时候,返回成功(认为当前写成功),保证高可用。QJM本质也是一个小集群
HA的系统配置
- NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置
- JournalNode machines:在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
- 在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
- 通常来说NN和JN不在一个机器上。ZKFC和NN在同一个机器上。RM(Yarn中的资源管理器)和NN在同一个机器。上。DN和NM(Yarn中的NodeManager)在同一个机器上。在实际工作中,Zookeeper是单独维护的独立集群。
NameNode Federation(联邦)
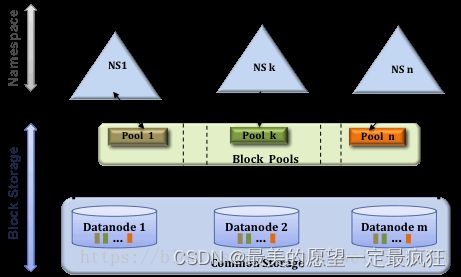
优点:减轻NameNode的压力,解决NameNode的扩展性。在联邦中,每个NameNode都管理了集群中的命名空间的一部分。它们相互独立的。例如NameNode1管理/usr下的目录,NameNode管理/share下的目录。但是底层的DN是共享的,可能一个DN中存储的数据块数据不同的NameNode的。
在实际生产环境中,HA几乎是必备的,而当集群规模在1000台以下时,几乎不需要联邦,另外通过Cloudera Manager可以很方便的部署HA和联邦
HDFS缓存
对于访问频繁的文件,其对应的块可能被缓存在DataNode的内存中,加快访问速度。HDFS中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的文件或文件夹,文件夹是以非迭代方式缓存的。NameNode会和保存着所需快数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中。
缓存的详细介绍
HDFS权限控制
目前HDFS的权限控制与Linux一致,包括用户、用户组、其他用户组三类权限
首先参数上要开启基本权限和访问控制列表功能
– dfs.permissions.enabled
– dfs.namenode.acls.enabled
常用命令
- hdfs dfs -getfacl /file
- hdfs dfs -setfacl -m user:mapred:r-- /file
- hdfs dfs -setfacl -x user:mapred /file
参考
其他
HDFS配置文件
HDFS 命令行操作
HDFS配置文件
HDFS 命令行操作
web UI :通过NameNode的50070端口号来访问