采用MPI_Send 和MPI_Recv 编写代码来实现包括MPI_Bcast、MPI_Alltoall、MPI_Gather、MPI_Scatter 等MPI 群集通信函数的功能
本文引自百度文库
一、实验内容
1、采用MPI_Send 和MPI_Recv 编写代码来实现包括MPI_Bcast、MPI_Alltoall、MPI_Gather、MPI_Scatter 等MPI 群集通信函数的功能。
2、给出抽象的并行算法描述、程序源代码及运行时性能加速图表。
二、抽象并行算法描述
ⅰ、MPI_Bcast算法描述:
输入:并行处理器个数ProcessNumber
输出:所有进程收到来自Root进程的消息
Procedure MPI_Bcast_a
Begin
对所有处理器同时执行如下的算法:
(1)if 进程为Root进程
(1.1)将message写入消息缓冲
(1.2)for index=0 to size-1 do
向index发送相同的message消息
end for
(2)进程不是Root进程
(2.1)接收消息
End
2、MPI_Alltoall算法描述:
输入:并行处理器个数ProcessNumber
输出:所有进程收到来自其他进程不同的消息
Procedure MPI_Alltoall_a
Begin
对所有处理器同时执行如下的算法:
(1)将message写入消息缓冲
(2)for index=0 to size-1 do
分别向index发送不同的message消息
end for
(3)for source=0 to size-1 do
接收来自source的message消息
end for
End
3、MPI_Gather算法描述:
输入:并行处理器个数ProcessNumber
输出: Root进程从通信域Comm的所有进程接收消息
Procedure MPI_Gather_a
Begin
对所有处理器同时执行如下的算法:
(1)if 进程为Root进程
(1.1)for source=0 to size-1 do
接收来自source的message消息
end for
(2)向Root进程发送自己的消息
End
4、MPI_Scatter算法描述:
输入:并行处理器个数ProcessNumber
输出:向所有进程发送不同的消息
Procedure MPI_Scatter_a
Begin
对所有处理器同时执行如下的算法:
(1)if 进程为Root进程
(1.1)将message写入消息缓冲
(1.2)for index=0 to size-1 do
向index发送不同的message消息
end for
(2)进程不是Root进程
(2.1)接收消息
End
三、程序源代码
#include "mpi.h" /*MPI head file*/
#include <stdio.h>
#include <string.h>
#define ProNum 4
void MPI_Bcast_a(int rank,int size,int tag){ //
int index;
char message[100];
MPI_Status status;
if (rank==0){
strcpy(message,"Hello,the message is from process root!\n ");
for(index=0;index<size;index++){
MPI_Send(message,strlen(message), MPI_CHAR, index, tag, MPI_COMM_WORLD); /*sending data to node#1*/
}
printf("There are %d processes in the group.\n",size);
}
else{
MPI_Recv(message,100, MPI_CHAR, 0, tag, MPI_COMM_WORLD, &status);
printf("Process %d received %s\n",rank,message);
}
}
void MPI_Alltoall_a(int rank,int size,int tag){ //
int index,source;
char message[100];
char buffers[ProNum][100];//if buffers *[100],there will be errors.
char buffer[10];
MPI_Status status;
strcpy(message,"Hello,the message is from process ");
//message="Hello,the message is from process ";
snprintf(buffer,10,"%d",rank);
strcat(message,buffer);
for(index=0;index<size;index++){
MPI_Send(message,strlen(message), MPI_CHAR, index, tag, MPI_COMM_WORLD); /*sending data to node#1*/
}
printf("There are %d processes in the group.\n",size);
for(source=0;source<size;source++){
MPI_Recv(buffers[source],100, MPI_CHAR,source, tag, MPI_COMM_WORLD, &status);
printf("Process %d received %s\n",rank,buffers[source]);
}
}
void MPI_Gather_a(int rank,int size,int tag){ //
int index,source;
char message[100];
char buffers[ProNum][100];//
char buffer[10];
MPI_Status status;
strcpy(message,"Hello,the message is from process ");
//message="Hello,the message is from process ";
snprintf(buffer,10,"%d",rank);
strcat(message,buffer);
MPI_Send(message,strlen(message), MPI_CHAR, 0, tag, MPI_COMM_WORLD); /*sending data to node#1*/
printf("There are %d processes in the group.\n",size);
if(rank==0){
for(source=0;source<size;source++){
MPI_Recv(buffers[source],100, MPI_CHAR,source, tag, MPI_COMM_WORLD, &status);
printf("Process %d received %s\n",rank,buffers[source]);
}
}
}
void MPI_Scatter_a(int rank,int size,int tag){ //
int index,source;
char message[100];
//char buffers[ProNum][100];//if buffers *[100],there will be errors.
char buffer[10];
MPI_Status status;
strcpy(message,"Hello,the message is to process ");
//message="Hello,the message is from process ";
if(rank==0){
for(index=0;index<size;index++){
snprintf(buffer,10,"%d",index);
strcat(message,buffer);
MPI_Send(message,strlen(message), MPI_CHAR, index, tag, MPI_COMM_WORLD); /*sending data to node#1*/
}
}
printf("There are %d processes in the group.\n",size);
MPI_Recv(message,100, MPI_CHAR,0, tag, MPI_COMM_WORLD, &status);
printf("Process %d received %s\n",rank,message);
}
int main( int argc, char** argv )
{
int rank, size,index, tag=1;
int senddata,recvdata;
MPI_Status status;
MPI_Init(&argc, &argv); /*initializing */
MPI_Comm_rank(MPI_COMM_WORLD, &rank); /*Process#*/
MPI_Comm_size(MPI_COMM_WORLD, &size); /*Total processes#*/
MPI_Bcast_a(rank,size,tag);
MPI_Alltoall_a(rank,size,tag);
MPI_Gather_a(rank,size,tag);
MPI_Scatter_a(rank,size,tag);
MPI_Finalize(); /*quit from MPI world*/
return (0);
}
四、实验结果对比
实验进行了相关数据的对比,主要将数据分为两组进行对比(1)在曙光4000A上的自编写的函数(2)在曙光4000A上使用系统自带的函数。
实验结果数据如下表:
(1)MPI_Bcast:
| 运行时间(s) 处理器个数 |
Real time |
user CPU time |
system CPU time |
|||
| MPI_Bcast |
实验程序 |
MPI_Bcast |
实验程序 |
MPI_Bcast |
实验程序 |
|
| 2 |
|
0.403 |
|
0.041 |
|
0.078 |
| 4 |
|
0.618 |
|
0.071 |
|
0.112 |
| 8 |
|
1.224 |
|
0.123 |
|
0.187 |
| 16 |
|
1.876 |
|
0.205 |
|
0.361 |
| 32 |
|
3.618 |
|
0.390 |
|
0.722 |
| 64 |
|
6.804 |
|
0.702 |
|
1.175 |
表1 MPI_Bcast运行性能
(2)MPI_Alltoall:
| 运行时间(s) 处理器个数 |
Real time |
user CPU time |
system CPU time |
|||
| MPI_Alltoall |
实验程序 |
MPI_Alltoall |
实验程序 |
MPI_Alltoall |
实验程序 |
|
| 2 |
|
0.439 |
|
0.050 |
|
0.072 |
| 4 |
|
0.630 |
|
0.066 |
|
0.107 |
| 8 |
|
1.151 |
|
0.109 |
|
0.198 |
| 16 |
|
1.998 |
|
0.233 |
|
0.353 |
| 32 |
|
7.323 |
|
0.439 |
|
0.674 |
| 64 |
|
17.233 |
|
0.881 |
|
1.441 |
表2 MPI_Alltoall运行性能
(3)MPI_Gather:
| 运行时间(s) 处理器个数 |
Real time |
user CPU time |
system CPU time |
|||
| MPI_Gather |
实验程序 |
MPI_Gather |
实验程序 |
MPI_Gather |
实验程序 |
|
| 2 |
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
| 8 |
|
|
|
|
|
|
| 16 |
|
|
|
|
|
|
| 32 |
|
|
|
|
|
|
| 64 |
|
|
|
|
|
|
表3 MPI_Gather运行性能
(4)MPI_Scatter:
| 运行时间(s) 处理器个数 |
Real time |
user CPU time |
system CPU time |
|||
|
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
| 8 |
|
|
|
|
|
|
| 16 |
|
|
|
|
|
|
| 32 |
|
|
|
|
|
|
| 64 |
|
|
|
|
|
|
表4 MPI_Scatter运行性能
五、实验结果
上图为测试输出时所产生结果图,表明各个线程所接收数据并且输出的相应过程,在数据字段填充的是各个发送端ID信息,用于验证信息是否发送正确。争对该程序如果信息发送正确那么在输出报文的get * Process data:* 两处应该是相同的。
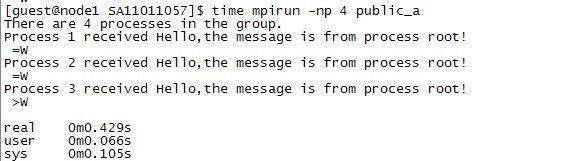
图1 MPI_Bcast接收信息显示

图2 MPI_Alltoall接收信息显示
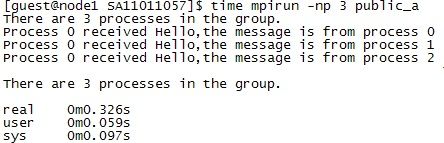
图3 MPI_Gather接收信息显示
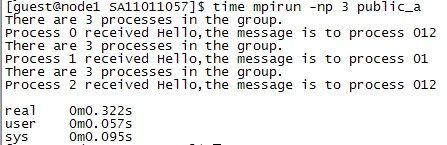
图4 MPI_Scatter接收信息显示
六、程序运行时性能加速图表
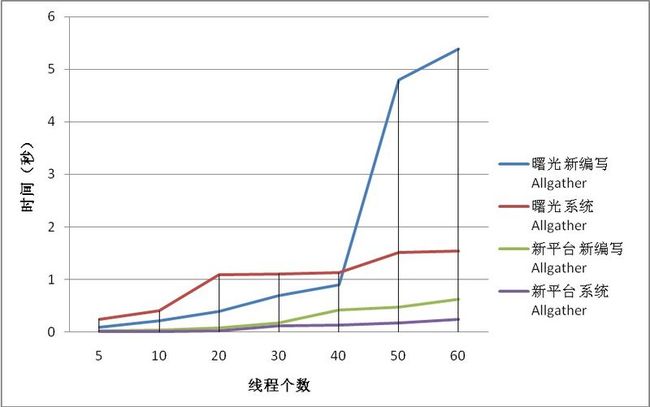
图5 两种情况下MPI_Bcast时间花费对比图
图6 两种情况下MPI_Alltoall时间花费对比图
图7 两种情况下MPI_Gather时间花费对比图
图8 两种情况下MPI_Scatter时间花费对比图
七、实验分析
经过上述实验得出的结论有以下几点(1)曙光4000A平台上运行程序的速度很高;(2)自编写函数性能低于系统自带函数,但是在自编写的Alltoall函数测试中,线程数目低于8时,自编写Alltoall函数花费时间小于系统自带的Alltoall函数的测试时间。