复刻ChatGPT语言模型系列-(一)基座模型选取
前言
今天开始我将会推出一系列关于复刻ChatGPT语言模型的博文。本系列将包括以下内容:
- 复刻ChatGPT语言模型系列-(一)基座模型选取
- 复刻ChatGPT语言模型系列-(二)参数高效微调
- 复刻ChatGPT语言模型系列-(三)指令学习微调
- 复刻ChatGPT语言模型系列-(四)文本生成解码
- 复刻ChatGPT语言模型系列-(五)强化学习RLHF
- 复刻ChatGPT语言模型系列-(六)LLM模型评估
在本系列的第一篇博文中,我们将会探讨如何选取一个好的预训练语言模型作为基座。选择一个优秀的基座模型非常重要,因为它会直接影响到后续模型的训练和性能表现。乱花渐欲迷人眼,目前社区涌现出许多优秀的大模型,这让我们选择起来十分困难。因此,本文将介绍并分析这些大模型,从中选择出适合作为基座的模型。我们将深入探究这些模型的特点和性能,并分析其优缺点。本文旨在为大家提供选取基座模型的参考意见,帮助大家更好地复刻ChatGPT语言模型。
以下是目前已经开放的基座模型清单,本文将专注介绍已开源模型,而其他模型则请读者自行了解。
| 模型名称 | 发布时间 | 发布机构 | 语言 | 参数规模 | Tokens规模 | 模型结构 | 是否开源 |
|---|---|---|---|---|---|---|---|
| T5 | 2019-10 | 英 | 13B | T5-style | √ | ||
| GPT-3 | 2020-05 | OpenAI | 英 | 175B | 300B | GPT-style | x |
| CPM1 | 2021-03 | Tsinghua | 中 | 2.6B | GPT-style | √ | |
| LaMDA | 2021-05 | 英 | 137B | 2.8T | GPT-style | x | |
| CPM2 | 2021-07 | Tsinghua | 中 | 11B/198B(MoE) | Encoder-Decoder | √ | |
| Jurassic | 2021-08 | AI21 | 英 | 178B | 300B | GPT-style | x |
| MT-NLG | 2021-10 | Microsoft, NVIDIA | 英 | 530B | 270B | GPT-style | x |
| ERNIE 3.0 | 2021-12 | Baidu | 中 | 260B | 300B | Multi-task | x |
| Gopher | 2021-12 | DeepMind | 英 | 280B | 300B | GPT-style | x |
| Chinchilla | 2022-04 | DeepMind | 英 | 70B | 1.4T | GPT-style | x |
| PaLM | 2022-04 | 多语言 | 540B | 780B | GPT-style | x | |
| OPT | 2022-05 | Meta | 英 | 125M-175B | 180B | GPT-style | √ |
| BLOOM | 2022-07 | BigScience | 多语言 | 176B | 366B | GPT-style | √ |
| GLM-130B | 2022-08 | Tsinghua | 中、英 | 130B | 400B | GLM-style | √ |
| Wenzhong | 2022-09 | IDEA | 中 | 3.5B | GPT-style | √ | |
| LLaMA | 2023-02 | Meta | 多语言 | 7B-65 B | 1.4T | GPT-sryle | √ |
| MOSS | 2023-04 | FUDAN | 中、英 | 16B | 700B | GPT-sryle | √ |
参考链接:https://zhuanlan.zhihu.com/p/614766286
微调模型
| 模型名称 | 发布时间 | 发布机构 | 语言 | 模态 | 参数规模 | 基础模型 | 是否开源 |
|---|---|---|---|---|---|---|---|
| GPT-3.5 | 2021-06 | OpenAI | 多语言 | 文本 | 175B | GPT-3 | x |
| FLAN | 2021-09 | 英 | 文本 | 137B | LaMDA | x | |
| T0 | 2021-10 | Hugging Face | 英 | 文本 | 13B | T5 | √ |
| Flan-PaLM | 2022-10 | 多语言 | 文本 | 540B | PaLM | x | |
| BLOOMZ | 2022-11 | Hugging Face | 多语言 | 文本 | 176B | BLOOM | √ |
| mT0 | 2022-11 | Hugging Face | 多语言 | 文本 | 13B | mT5 | √ |
| ChatGPT | 2022-11 | OpenAI | 多语言 | 文本 | 173B | GPT3.5 | x |
| Alpaca | 2023-3-14 | StandFord | 英 | 文本 | 7B | LLaMA | √ |
| ChatGLM | 2023-3-14 | Tsinghua | 中、英 | 文本 | {:[6B],[130B]:} | GLM | √ |
| GPT-4 | 2023-3-14 | OpenAI | 多语言 | 文本、图像 | √ | GPT-4 | x |
| ERNIE Bot | 2023-3-15 | Baidu | 中 | 文本、图像 | 260B√ | ERNIE | x |
| Bard | 2023-3-21 | 英 | 文本 | 137B | LaMDA | x | |
| MOSS | 2023-4 | FUDAN | 中、英 | 文本 | 16B | CodeGen | √ |
CPM
CPM模型是由智源、清华开发的一种基于大规模中文训练数据进行生成式预训练的中文预训练语言模型。该模型具有26亿个参数和100GB中文训练数据,是目前最大的中文预训练语言模型之一。CPM模型在各种中文自然语言处理任务中表现出色,包括对话、文章生成、填空测试和语言理解等任务。
论文标题:CPM: A large-scale generative Chinese Pre-trained language model
论文地址:CPM: A large-scale generative Chinese Pre-trained language model - ScienceDirect
模型结构:基于Transformer的自回归模型,GPT类结构;
训练数据:100G中文语料;
改动点:较GPT3采用更大的batch_size。
OPT
OPT-175B是Meta AI在2022年5月3日发布的一款开放模型,是模型参数超过千亿级别的开放模型之一。相比于GPT-3,该模型更加开放便于访问,并在以下五个方面表现出其开放性:
-
论文:该模型提供了某些能力可能存在的证明,并揭示可以建立在此基础上的一般思想。
-
API访问:该模型允许研究人员探索和评估现有基础模型的能力和局限性,例如推理和偏差。
-
模型权重:研究人员可以使用该模型的权重来逐步改进现有模型、开发更深入的可解释技术和更有效的微调方法。
-
训练数据:该模型让研究人员更好地理解训练数据在模型行为中的作用,例如情境学习从何而来。
-
计算:该模型允许研究人员尝试新的架构、培训目标/程序、进行数据集消融,并在不同领域开发全新的模型。虽然这种方法具有最大的理解和改进潜力,但也相当昂贵。
作为一个大规模的语言模型,OPT-175B具有超过1750亿个参数,是目前为止最大的语言模型之一。该模型通过在公开可用的数据集上进行训练,允许更多的社区参与了解这项基础新技术。为了保持完整性并防止滥用,Meta AI将在非商业许可下发布他们的模型,以专注于研究用例。该模型的访问权限将授予学术研究者、政府机构、民间社会和学术界组织的人员,以及世界各地的工业研究实验室。
项目地址:GitHub - facebookresearch/metaseq: Repo for external large-scale work
论文地址:https://arxiv.org/pdf/2205.01068.pdf
模型结构: Decoder Only
| Model | #L | #H | d_model | LR | Batch |
|---|---|---|---|---|---|
| 125M | 12 | 12 | 768 | 6.0 e-4 | 0.5M |
| 350M | 24 | 16 | 1024 | 3.0 e-4 | 0.5M |
| 1.3B | 24 | 32 | 2048 | 2.0 e-4 | 1M |
| 2.7B | 32 | 32 | 2560 | 1.6 e-4 | 1M |
| 6.7B | 32 | 32 | 4096 | 1.2 e-4 | 2M |
| 13B | 40 | 40 | 5120 | 1.0 e-4 | 4M |
| 30B | 48 | 56 | 7168 | 1.0 e-4 | 4M |
| 66B | 64 | 72 | 9216 | 0.8 e-4 | 2M |
| 175B | 96 | 96 | 12288 | 1.2 e-4 | 2M |
训练过程:
OPT与GPT3的训练过程比较如下:
| Model | GPU | FLOPs | days |
|---|---|---|---|
| OPT | 1024 80G A100 | √4.30E+23 | 33 |
| GPT3 | 10,000 32G V100 | √3.14E+23 | 14.8 |
Meta将OPT系列模型的训练过程记录在logbook中,地址如下:metaseq/README.md at main · facebookresearch/metaseq · GitHub。这个logbook主要记录了作者训练OPT系列模型的辛酸历程,包括遇到的一些问题、讨论分析以及解决方法。
有兴趣的可以仔细阅读原文,或者OPT logbook:训练大规模语言模型的一些经验。
总结如下,Meta主要遇到收敛/数值稳定性问题、机器故障问题。
-
面对收敛/数值稳定性问题:Meta主要采取降低学习率、参照成熟框架设置参数、切换激活函数的方法;
-
面对机器故障问题:Meta主要开发监控、自动化工具进行监测。
LLAMA
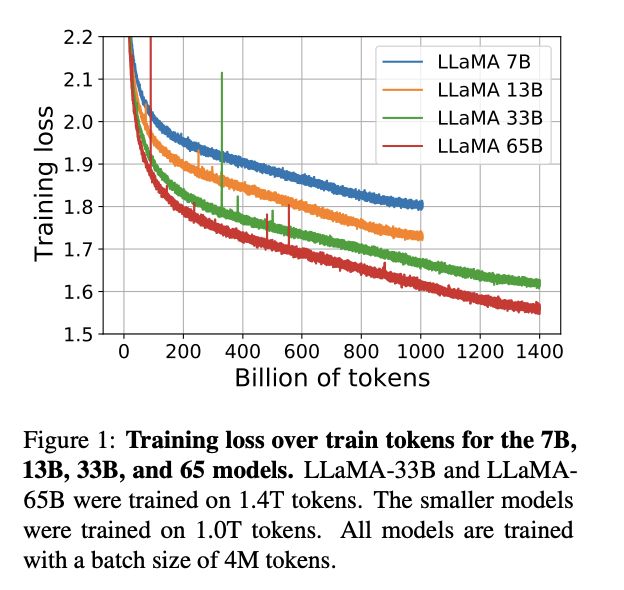
LLaMA(Large Language Model Meta AI),由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。
关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4万亿个 token 上训练的,而最小的模型 LLaMA-7B 是在 1万亿个 token 上训练的。
论文标题:LLaMA: Open and Efficient Foundation Language Models
论文链接:https://arxiv.org/pdf/2302.13971.pdf
模型结构:
- PreLayerNorm-RMSNorm-Root Mean Square Layer Normalization
- ROPE旋转位置编码(替换绝对/相对位置编码)
- SwiGLU激活函数(替换ReLU)-GLU Variants Improve Transformer
改动点:
过了1T的Token:过去的研究发现最好的性能不是在最大的模型上,而是在过了更多token的模型上;
与OpenAI提出大模型缩放法则不同的是,DeepMind认为当前许多大模型是训练不充分的;
OpenAI在《Scaling Laws for Neural Language Models》中,指出在给定计算量的时候,模型性能的提升主要在于增加参数规模而不是增加数据量;
DeepMind在《Training Compute-Optimal Large Language Models》中,指出在每条曲线的最小值的左侧,模型太小了——在较少数据上训练的较大模型将是一种改进。在每条曲线的最小值的右侧,模型太大——在更多数据上训练的较小模型将是一种改进。最好的模型处于最小值。
BLOOM
BLOOM 是 BigScience(一个围绕研究和创建超大型语言模型的开放协作研讨会)中数百名研究人员合作设计和构建的 176B 参数开源大语言模型,同时,还开源了BLOOM-560M、BLOOM-1.1B、BLOOM-1.7B、BLOOM-3B、BLOOM-7.1B 其他五个参数规模相对较小的模型。BLOOM 是一种 decoder-only 的 Transformer 语言模型,它是在 ROOTS 语料库上训练的,该数据集包含 46 种自然语言和 13 种编程语言(总共 59 种)的数百个数据来源。
论文标题:BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
论文链接:https://arxiv.org/pdf/2211.05100.pdf
模型结构:
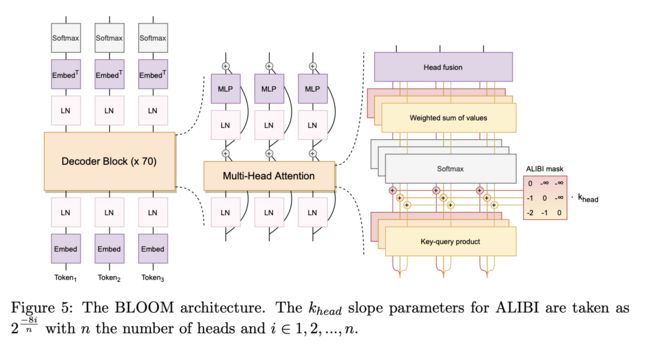
核心介绍:
-
基于Megatron-LM GPT2模型开发,模型结构为Decoder-only类型;
-
ALiBi Positional Embeddings。它允许外推比训练模型的输入序列更长的输入序列,同时有助于加速训练收敛。因此,即使训练时使用长度为 2048 的序列,模型也可以在推理过程中处理更长的序列。思路来源于: Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation;
-
Embedding LayerNorm。在 embedding 层之后立即添加额外的归一化层(
layer norm层)。这个方法来源于 bitsandbytes^17库 (Dettmers et al., 2022),作者的实验发现这样可以显著提高训练的稳定性。另外,模型最终的训练是在bfloat16下进行的。思路来源于:8-bit Optimizers via Block-wise Quantization
同时开发人员也记录了项目的开发过程:千亿参数开源大模型 BLOOM 背后的技术,关键信息如下:
-
基于Megatron-DeepSpeed 实现了 3D 并行以允许大模型以非常有效的方式进行训练。包括数据并行 (Data Parallelism,DP)、张量并行 (Tensor Parallelism,TP)、流水线并行 (Pipeline Parallelism,PP)。
-
用 FP16 训练巨型 LLM 模型是一个禁忌。FP16会产生精度溢出,使用BF16进行训练。
-
CUDA 融合核函数。为了快速高效地训练 BLOOM,有必要使用 Megatron-LM 提供的几个自定义 CUDA 融合核函数。特别地,有一个 LayerNorm 的融合核函数以及用于融合缩放、掩码和 softmax 这些操作的各种组合的核函数。Bias Add 也通过 PyTorch 的 JIT 功能与 GeLU 融合。这些操作都是瓶颈在内存的,因此将它们融合在一起以达到最大化每次显存读取后的计算量非常重要。因此,例如,在执行瓶颈在内存的 GeLU 操作时同时执行 Bias Add,运行时间并不会增加。这些核函数都可以在 Megatron-LM repository 代码库 中找到。
-
硬件故障也颇有挑战。
WenZhong
闻仲语言模型出自IDEA研究院的封神榜模型系列,专注于生成任务,提供了多个不同参数量的生成模型,例如GPT2等。
Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,成为中文AIGC和认知智能的基础设施。
项目地址:GitHub - IDEA-CCNL/Fengshenbang-LM: Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,成为中文AIGC和认知智能的基础设施。
GLM
GLM-130B 是清华大学与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言模型,拥有 1300亿个参数,使用通用语言模型(General Language Model, GLM)的算法进行预训练。 2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。GLM-130B 在广泛流行的英文基准测试中性能明显优于 GPT-3 175B(davinci),而对 OPT-175B 和 BLOOM-176B 没有观察到性能优势,它还在相关基准测试中性能始终显著优于最大的中文语言模型 ERNIE 3.0 Titan 260B。GLM-130B 无需后期训练即可达到 INT4 量化,且几乎没有性能损失;更重要的是,它能够在 4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPU 上有效推理,是使用 100B 级模型最实惠的 GPU 需求。
GLM介绍
论文标题:GLM: General Language Model Pretraining with Autoregressive Blank Infilling
论文地址:https://arxiv.org/pdf/2103.10360v2.pdfhttps://arxiv.org/pdf/2103.10360v2.pdf
训练目标:

max θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x corrupt , s z < i ) ] \max _\theta \mathbb{E}_{\boldsymbol{z} \sim Z_m}\left[\sum_{i=1}^m \log p_\theta\left(\boldsymbol{s}_{z_i} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{\boldsymbol{z}_{
p θ ( s i ∣ x corrupt , s z < i ) = ∏ j = 1 l i p ( s i , j ∣ x corrupt , s z < i , s i , < j ) \begin{aligned} & p_\theta\left(\boldsymbol{s}_i \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{\boldsymbol{z}_{
模型结构:
- 改变层归一化、残差网络结构的顺序(避免出现数值错误)
- 新增线性层输出结果
- 使用GeLUs激活函数替代ReLU
微调方式:
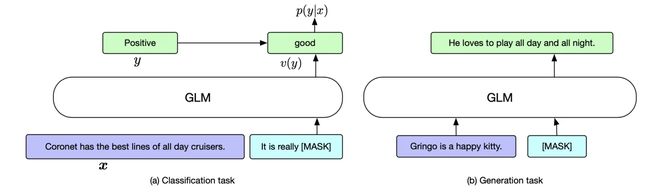
- 对于分类任务,对于token分类,就使用目标token的表示;对于序列分类那就是使用cls的表示。
- 对于生成任务,partB 部分直接换成 mask 即可。
讨论分析:
| BERT | XLNET | Encoder-Decoder | UniLM |
|---|---|---|---|
| BERT中不能很好处理连续的多个token; mask token是独立的,不能捕捉mask token之间的依赖关系。 | xlnet使用了双流的注意力机制,改变了transformer的结构,增加了耗时。 | 使用了两个transformer模型实现了单向和双向注意力,加入token来识别mask span,浪费模型能力;训练和微调不一致。 | 在自编码框架下使用了mask来统一单双向的注意力。对于生成任务来说,还是不够高效。 |
与bert对比
bert是自编码模型,预测mask的字符。因为模型中的mask token是独立的,bert不能捕捉mask token之间的依赖性。bert的另一个缺点是不能预测多个连续的mask token,尤其是待预测长度未知情况下。
与xlnet的对比
都是自回归的模型。xlnet需要知道预测token的长度;使用双流注意力机制解决了信息泄漏的问题,改变了transfomer的结构,增加了耗时;xlnet决定一个token是否被独立预测。
与编码解码模型对比
T5也是处理的空白填充的任务目标,但是GLM使用了单个的transformer编码器学习单向和双向的注意力。通过共享参数使参数比编码解码模型更有效。T5在编码和解码阶段使用不同的位置编码,使用哨兵标记来识别不同的mask跨度,哨兵标记造成了模型能力的浪费和预训练微调的不一致性。
与UniLM对比
UniLM是通过在自编码框架下改变在双向,单向,互相之间的attention mask来统一预训练目标;由于自编码模型的独立假设,自回归模型不能完全捕捉当前token对于前面token的依赖。对于微调下游任务来说,自编码会比自回归更加低效。
GLM130B
- 130B的原因是该大小能够在一个A100服务器(40G*8)上进行推理
- 千亿模型训练的问题:硬件故障、梯度爆炸、内存溢出、3D并行、无法恢复优化器状态、TCP通信阻塞
- [MASK]、[gMASK]分别用作短文本、长文本生成
- 结构优化点:RoPE、DeepNorm、GeLU
- 预训练:95%的MASK自回归任务、5%的多任务指令学习(T0、DeepStruct)
- 400B的Token,但是据估计130B模型需要4T的Token
- GLM-130B FP16-需要260G显存存储模型权重
UniLM
许多人指出GLM和UniLM的模型结构非常相似。下面将对UniLM的模型结构进行详细介绍。
UniLM是微软研究院在Bert的基础上,最新产出的预训练语言模型,被称为统一预训练语言模型。 它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,Unilm在抽象摘要、生成式问题回答和语言生成数据集的抽样领域取得了最优秀的成绩。
论文标题:Unified Language Model Pre-training for Natural Language Understanding and Generation
论文地址:https://arxiv.org/pdf/1905.03197.pdf
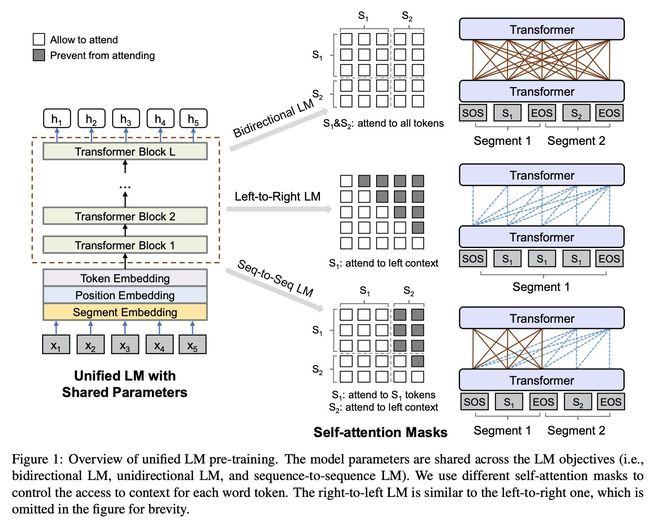
预训练阶段:
-
输入:Token Embedding、Position Embedding、Segment Embedding(区分任务目标)
-
预训练目标:随机掩码[MASK]语言模型+NSP
-
单向语言模型:predict the masked token of “x1x2 [MASK] x4”, only tokens x1, x2 and itself can be used.
-
双向语言模型:predict the masked token of “x1x2 [MASK] x4”, all tokens can be used.
-
Seq2Seq语言模型: given source segment t1t2 and its target segment t3t4t5, we feed input “[SOS] t1 t2 [EOS] t3 t4 t5 [EOS]” into the model. While both t1 and t2 have access to the first four tokens, including [SOS] and [EOS], t4 can only attend to the first six tokens.
-
训练过程:1/3训练双向语言模型;1/3训练Seq2Seq语言模型;1/6训练从左到右单向语言模型;1/6训练从右到左单向语言模型;BERT-Large作为初始化模型;15%概率掩码,80%为[MASK],10%为随机Token,10%保持不变
微调阶段:
- NLU任务:类似于BERT,取[SOS]表征句子输入
- NLG任务:“[SOS] S1 [EOS] S2 [EOS]”. The model is fine-tuned by masking some percentage of tokens in the target sequence at random, and learning to recover the masked words. EOS也会被MASK
MOSS
MOSS是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
以下根据知乎回答总结MOSS的训练过程:
MOSS 001(OpenChat 001)
-
数据来源:从OpenAI的论文附录里扒了一些它们API收集到的user prompt,然后用类似Self-Instruct的思路用text-davinci-003去扩展出大约40万对话数据。
-
基座模型:16B基座(CodeGen)
-
实验结果:一月份的OpenChat 001就已经具备了指令遵循能力和多轮能力,而且还惊喜的发现它具有很强的跨语言对齐能力,它的基座预训练语料中几乎不存在中文,但是却可以理解中文并用英文回答。
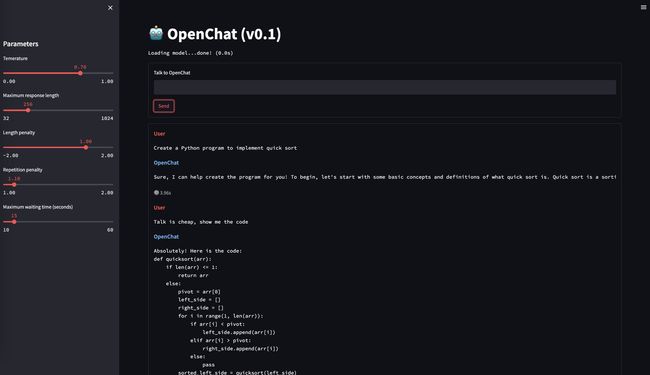
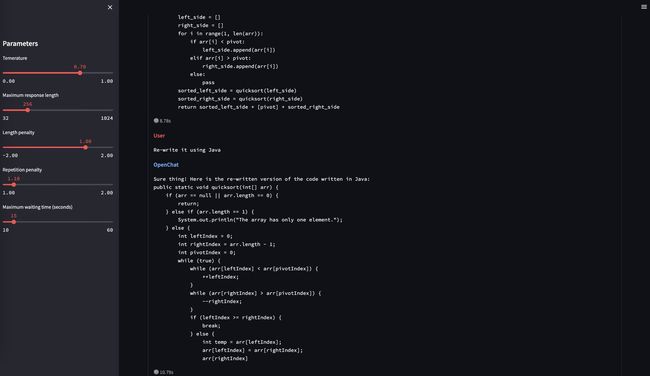
MOSS 002
-
优化点:OpenChat 001不具备中文能力,不知道关于自己的信息(比如名字、能力等),且安全性较低
-
数据来源:一方面加入了约30B中文token继续训练基座,另一方面也加入了大量中英文helpfulness, honesty, harmlessness对话数据,这部分数据共计116万条对话,目前也全部已在huggingface开源:fnlp/moss-002-sft-data · Datasets at Hugging Face
MOSS 003
-
优化点1:继续加大中文语料的预训练,截止目前MOSS 003的基座语言模型已经在100B中文token上进行了训练,总训练token数量达到700B,其中还包含约300B代码。
-
优化点2:在开放内测后,我们也收集了一些用户数据,我们发现真实中文世界的用户意图和OpenAI InstructGPT论文中披露的user prompt分布有较大差异(这不仅与用户来自的国家差异有关,也跟产品上线时间有关,早期产品采集的数据中存在大量对抗性和测试性输入),于是我们以这部分真实数据作为seed重新生成了约110万常规对话数据,涵盖更细粒度的helpfulness数据和更广泛的harmlessness数据。此外,还构造了约30万插件增强的对话数据,目前已包含搜索引擎、文生图、计算器、方程求解等。

基座模型选取
基于训练一个中文ChatGPT模型的出发点,需要选用具备中文支持性高、模型参数量大且已开源的基座模型。我们的候选项包括GLM、LLAMA、MOSS、BLOOM、CPM、闻仲模型,接下来将在这些候选项中进行比较,以确定最终选项。
-
首先是CPM模型,其训练语料中,文章、对话语料居多,模型参数量较少,微调后的模型泛化性较差,生成结果与对话风格较大;
-
另外,闻仲模型,模型参数量同样较小;
-
接下来,LLAMA模型,尽管该模型在英文支持性方面表现不错,但据统计其Tokenizer中仅包括约700个中文字符,中文支持性较差;
-
BLOOM模型虽然支持多语言,但是其中文语料仅占16%,这意味着其可能无法提供足够的中文知识;
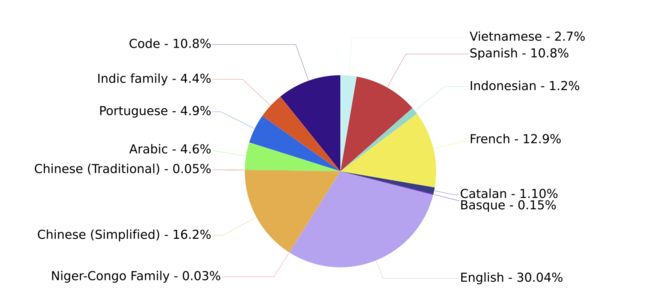
- GLM模型则是支持中英文双语的130B模型,是亚洲唯一入选斯坦福大模型评测的模型。GLM模型在中文支持性和模型参数量方面表现出色,此外,该模型已开源,可以为我们提供强大的基座模型。
综上所述,GLM模型是复刻中文ChatGPT的一个较优基座模型选择。
当然目前也有不少基于其他基座模型的工作,比如:
GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署 (Chinese LLaMA & Alpaca LLMs)
GitHub - LianjiaTech/BELLE: BELLE: Be Everyone’s Large Language model Engine(开源中文对话大模型)
总结
本文着重探讨如何选取一个好的预训练语言模型作为基座,最终选择在中文支持性和模型参数量方面表现出色的GLM模型。后续系列包括:
- 复刻ChatGPT语言模型系列-(二)参数高效微调
- 复刻ChatGPT语言模型系列-(三)指令学习微调
- 复刻ChatGPT语言模型系列-(四)文本生成解码
- 复刻ChatGPT语言模型系列-(五)强化学习RLHF
- 复刻ChatGPT语言模型系列-(六)LLM模型评估