3.0--3.2
3. DataFrame编程详解
3.1 创建DataFrame
在Spark SQL中SparkSession是创建DataFrames和执行SQL的入口
创建DataFrames有三种方式:
- 从一个已存在的RDD进行转换
- 从JSON/Parquet/CSV/ORC等结构化文件源创建
- 从Hive/JDBC各种外部结构化数据源(服务)创建
| 核心要义:创建DataFrame,需要创建 “RDD + 元信息schema定义” + 执行计划 rdd来自于数据 schema则可以由开发人员定义,或者由框架从数据中推断 |
3.1.1 使用RDD创建DataFrame
- 将RDD关联case class创建DataFrame
| Scala
object DataFrameDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
//1.SparkSession,是对SparkContext的增强
val session: SparkSession = SparkSession.builder()
.config(conf)
.getOrCreate()
//2.创建DataFrame
//2.1先创建RDD
val lines: RDD[String] = session.sparkContext.textFile("data/user.txt")
//2.2对数据进行整理并关联Schema
val tfBoy: RDD[Boy] = lines.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
Boy(name, age, fv) //字段名称,字段的类型
})
//2.3将RDD关联schema,将RDD转成DataFrame
//导入隐式转换
import session.implicits._
val df: DataFrame = tfBoy.toDF
//打印DataFrame的Schema信息
df.printSchema()
//3.将DataFrame注册成视图(虚拟的表)
df.createTempView("v_users")
//4.写sql(Transformation)
val df2: DataFrame = session.sql("select * from v_users order by fv desc, age asc")
//5.触发Action
df2.show()
//6.释放资源
session.stop()
}
}
case class Boy(name: String, age: Int, fv: Double) |
- 将RDD关联普通class创建DataFrame
| Scala
object C02_DataFrameDemo2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark = SparkSession.builder()
.appName("DataFrameDemo2")
.master("local[*]")
.getOrCreate()
//2.创建RDD
val lines: RDD[String] = spark.sparkContext.textFile("data/user.txt")
//2将数据封装到普通的class中
val boyRDD: RDD[Boy2] = lines.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
new Boy2(name, age, fv) //字段名称,字段的类型
})
//3.将RDD和Schema进行关联
val df = spark.createDataFrame(boyRDD, classOf[Boy2])
//df.printSchema()
//4.使用DSL风格的API
import spark.implicits._
df.show()
spark.stop()
}
}
//参数前面必须有var或val
//必须添加给字段添加对应的getter方法,在scala中,可以@BeanProperty注解
class Boy2(
@BeanProperty
val name: String,
@BeanProperty
val age: Int,
@BeanProperty
val fv: Double) {
} |
| 普通的scala class 必须在成员变量加上@BeanProperty属性,因为sparksql需要通过反射调用getter获取schema信息 |
- 将RDD关联java class创建DataFrame
| Scala
object SQLDemo4 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val lines = spark.sparkContext.textFile("data/boy.txt")
//将RDD关联的数据封装到Java的class中,但是依然是RDD
val jboyRDD: RDD[JBoy] = lines.map(line => {
val fields = line.split(",")
new JBoy(fields(0), fields(1).toInt, fields(2).toDouble)
})
//强制将关联了schema信息的RDD转成DataFrame
val df: DataFrame = spark.createDataFrame(jboyRDD, classOf[JBoy])
//注册视图
df.createTempView("v_boy")
//写sql
val df2: DataFrame = spark.sql("select name, age, fv from v_boy order by fv desc, age asc")
df2.show()
spark.stop()
}
} |
| Java
public class JBoy {
private String name;
private Integer age;
private Double fv;
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public Double getFv() {
return fv;
}
public JBoy(String name, Integer age, Double fv) {
this.name = name;
this.age = age;
this.fv = fv;
}
} |
- 将RDD关联Schema创建DataFrame
| Scala
object SQLDemo4 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val lines = spark.sparkContext.textFile("data/boy.txt")
//将RDD关联了Schema,但是依然是RDD
val rowRDD: RDD[Row] = lines.map(line => {
val fields = line.split(",")
Row(fields(0), fields(1).toInt, fields(2).toDouble)
})
val schema = StructType.apply(
List(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv", DoubleType),
)
)
val df: DataFrame = spark.createDataFrame(rowRDD, schema)
//打印schema信息
//df.printSchema()
//注册视图
df.createTempView("v_boy")
//写sql
val df2: DataFrame = spark.sql("select name, age, fv from v_boy order by fv desc, age asc")
df2.show()
spark.stop()
}
} |
3.1.2 从结构化文件创建DataFrame
(1)从csv文件(不带header)进行创建
csv文件内容:
| Plain Text
1,张飞,21,北京,80.0
2,关羽,23,北京,82.0
3,赵云,20,上海,88.6
4,刘备,26,上海,83.0
5,曹操,30,深圳,90.0 |
代码示例:
| Scala
val df = spark.read.csv("data_ware/demodata/stu.csv")
df.printSchema()
df.show() |
结果如下:
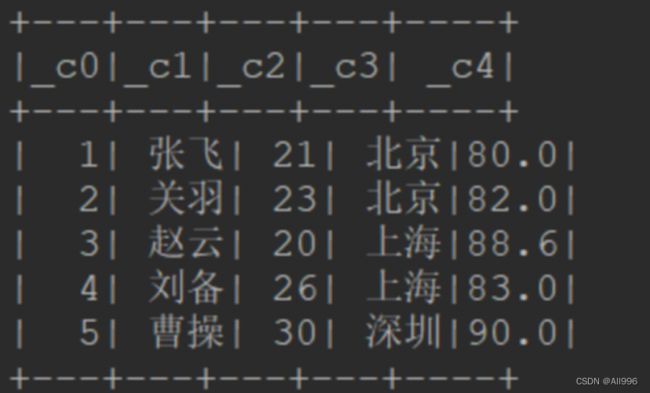
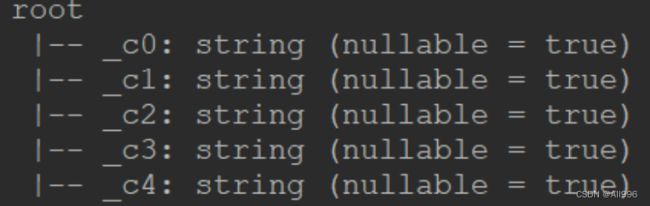
可以看出,框架对读取进来的csv数据,自动生成的schema中,
字段名为:_c0,_c1,.....
字段类型全为String
不一定是符合我们需求的
(2)从csv文件(不带header)自定义Schema进行创建
// 创建DataFrame时,传入自定义的schema
// schema在api中用StructType这个类来描述,字段用StructField来描述
| Scala
val schema = new StructType()
.add("id", DataTypes.IntegerType)
.add("name", DataTypes.StringType)
.add("age", DataTypes.IntegerType)
.add("city", DataTypes.StringType)
.add("score", DataTypes.DoubleType)
val df = spark.read.schema(schema).csv("data_ware/demodata/stu.csv")
df.printSchema()
df.show() |
Schema信息:
| Plain Text
root
|-- id: integer (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- city: string (nullable = true)
|-- score: double (nullable = true) |
输出数据信息:
| SQL
+---+------+---+------+-----+
| id|name |age|city |score|
+---+------+---+------+-----+
| 1| 张飞| 21| 北京| 80.0|
| 2| 关羽| 23| 北京| 82.0|
| 3| 赵云| 20| 上海| 88.6|
| 4| 刘备| 26| 上海| 83.0|
| 5| 曹操| 30| 深圳| 90.0|
+---+------+---+------+-----+ |
(3)从csv文件(带header)进行创建
csv文件内容:
| Plain Text
id,name,age,city,score
1,张飞,21,北京,80.0
2,关羽,23,北京,82.0
3,赵云,20,上海,88.6
4,刘备,26,上海,83.0
5,曹操,30,深圳,90.0 |
注意:此文件的第一行是字段描述信息,需要特别处理,否则会被当做rdd中的一行数据
代码示例:关键点设置一个header=true的参数
| Scala
val df = spark.read
.option("header",true) //读取表头信息
.csv("data_ware/demodata/stu.csv")
df.printSchema()
df.show() |
结果如下:
root
| Plain Text
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- age: string (nullable = true)
|-- city: string (nullable = true)
|-- score: string (nullable = true)
+---+----+---+----+-----+
| id|name|age|city|score|
+---+----+---+----+-----+
| 1| 张飞| 21| 北京| 80.0|
| 2| 关羽| 23| 北京| 82.0|
| 3| 赵云| 20| 上海| 88.6|
| 4| 刘备| 26| 上海| 83.0|
| 5| 曹操| 30| 深圳| 90.0|
+---+----+---+----+-----+ |
问题:虽然字段名正确指定,但是字段类型还是无法确定,默认情况下全视作String对待,当然,可以开启一个参数 inferSchema=true 来让框架对csv中的数据字段进行合理的类型推断
| Scala
val df = spark.read
.option("header",true)
.option("inferSchema",true) //推断字段类型
.csv("data_ware/demodata/stu.csv")
df.printSchema()
df.show() |
如果推断的结果不如人意,当然可以指定自定义schema
让框架自动推断schema,效率低不建议!
(4)从JSON文件进行创建
准备json数据文件
| JSON
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19} |
代码示例
| JSON
val df = spark.read.json("data_ware/demodata/people.json")
df.printSchema()
df.show() |
(5)从Parquet文件进行创建
Parquet文件是一种列式存储文件格式,文件自带schema描述信息
准备测试数据
任意拿一个dataframe,调用write.parquet()方法即可将df保存为一个parquet文件
代码示例:
| Scala
val df = spark.read.parquet("data/parquet/") |
(6)从orc文件进行创建
代码示例
| Scala
val df = spark.read.orc("data/orcfiles/") |
3.2.3外部存储服务创建DF
(1)从JDBC连接数据库服务器进行创建
实验准备
在一个mysql服务器中,创建一个数据库demo,创建一个表student,如下:
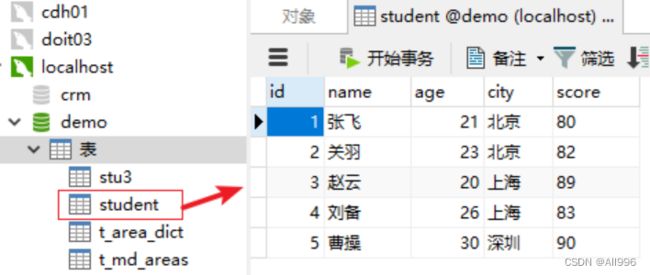
注:要使用jdbc连接读取数据库的数据,需要引入jdbc的驱动jar包依赖
| XML
mysql
mysql-connector-java
8.0.30
|
代码示例
| Scala
val props = new Properties()
props.setProperty("user","root")
props.setProperty("password","root")
val df = spark.read.jdbc("jdbc:mysql://localhost:3306/demo","student",props)
df.show() |
结果如下:
| Plain Text
+---+------+---+------+-----+
| id|name |age|city |score|
+---+------+---+------+-----+
| 1| 张飞| 21| 北京| 80.0|
| 2| 关羽| 23| 北京| 82.0|
| 3| 赵云| 20| 上海| 88.6|
| 4| 刘备| 26| 上海| 83.0|
| 5| 曹操| 30| 深圳| 90.0|
+---+------+---+------+-----+ |
SparkSql添加了spark-hive的依赖,并在sparkSession构造时开启enableHiveSupport后,就整合了hive的功能(通俗说,就是sparksql具备了hive的功能);
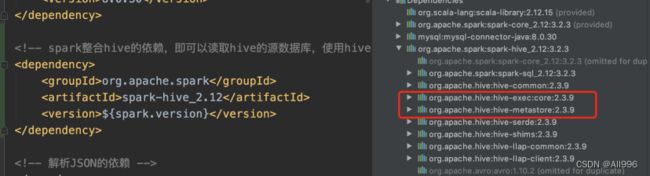
既然具备了hive的功能,那么就可以执行一切hive中能执行的动作:
只不过,此时看见的表是spark中集成的hive的本地元数据库中的表!
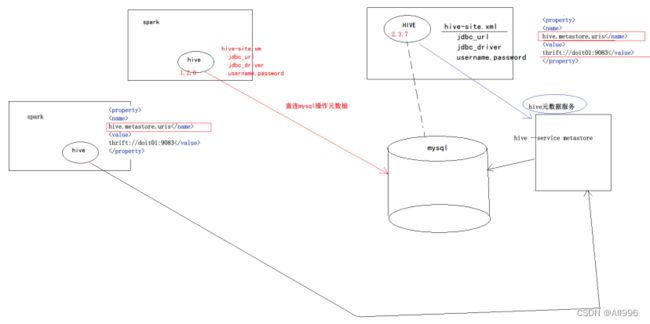
如果想让spark中集成的hive,看见你外部集群中的hive的表,只要修改配置:把spark端的hive的元数据服务地址,指向外部集群中hive的元数据服务地址;
有两种指定办法:
- 在spark端加入hive-site.xml ,里面配置 目标元数据库 mysql的连接信息
这会使得spark中集成的hive直接访问mysql元数据库
- 在spark端加入hive-site.xml ,里面配置 目标hive的元数据服务器地址
这会使得spark中集成的hive通过外部独立的hive元数据服务来访问元数据库
(2)从Hive创建DataFrame
Sparksql通过spark-hive整合包,来集成hive的功能
Sparksql加载“外部独立hive”的数据,本质上是不需要“外部独立hive”参与的,因为“外部独立hive”的表数据就在hdfs中,元数据信息在mysql中
不管数据还是元数据,sparksql都可以直接去获取!
步骤:
- 要在工程中添加spark-hive的依赖jar以及mysql的jdbc驱动jar
| XML
mysql
mysql-connector-java
8.0.30
org.apache.spark
spark-hive_2.12
3.2.3
|
- 要在工程中添加hive-site.xml/core-site.xml配置文件
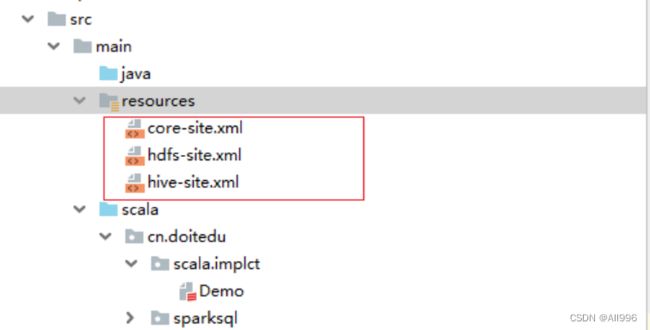
- 创建sparksession时需要调用.enableHiveSupport( )方法
| Scala
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
// 启用hive支持,需要调用enableHiveSupport,还需要添加一个依赖 spark-hive
// 默认sparksql内置了自己的hive
// 如果程序能从classpath中加载到hive-site配置文件,那么它访问的hive元数据库就不是本地内置的了,而是配置中所指定的元数据库了
// 如果程序能从classpath中加载到core-site配置文件,那么它访问的文件系统也不再是本地文件系统了,而是配置中所指定的hdfs文件系统了
.enableHiveSupport()
.getOrCreate() |
- 加载hive中的表
| Scala
val df = spark.sql("select * from t1") |
注意点:如果自己也用dataframe注册了一个同名的视图,那么这个视图名会替换掉hive的表
(3)从Hbase创建DataFrame
其实,sparksql可以连接任意外部数据源(只要有对应的“连接器”即可)
Sparksql对hbase是有第三方连接器(华为)的,但是久不维护!
建议用hive作为连接器(hive可以访问hbase,而sparksql可以集成hive)
在hbase中建表
| Shell
create 'doitedu_stu','f' |
插入数据到hbase表
| Shell
put 'doitedu_stu','001','f:name','zhangsan'
put 'doitedu_stu','001','f:age','26'
put 'doitedu_stu','001','f:gender','m'
put 'doitedu_stu','001','f:salary','28000'
put 'doitedu_stu','002','f:name','lisi'
put 'doitedu_stu','002','f:age','22'
put 'doitedu_stu','002','f:gender','m'
put 'doitedu_stu','002','f:salary','26000'
put 'doitedu_stu','003','f:name','wangwu'
put 'doitedu_stu','003','f:age','21'
put 'doitedu_stu','003','f:gender','f'
put 'doitedu_stu','003','f:salary','24000'
put 'doitedu_stu','004','f:name','zhaoliu'
put 'doitedu_stu','004','f:age','22'
put 'doitedu_stu','004','f:gender','f'
put 'doitedu_stu','004','f:salary','25000' |
创建hive外部表映射hbase中的表
| SQL
CREATE EXTERNAL TABLE doitedu_stu
(
id string ,
name string ,
age int ,
gender string ,
salary double
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ( 'hbase.columns.mapping'=':key,f:name,f:age,f:gender,f:salary')
TBLPROPERTIES ( 'hbase.table.name'='default:doitedu_stu')
; |
工程中放置hbase-site.xml配置文件
| XML
hbase.rootdir
hdfs://doit01:8020/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
doit01:2181,doit02:2181,doit03:2181
hbase.unsafe.stream.capability.enforce
false
|
工程中添加hive-hbase-handler连接器依赖
| XML
org.apache.hive
hive-hbase-handler
2.3.7
org.apache.hadoop
hadoop-common
|
以读取hive表的方式直接读取即可
| Scala
spark.sql("select * from doitedu_stu") |
3.2 输出DF的各种方式
3.2.1 展现在控制台
| Scala
df.show()
df.show(10) //输出10行
df.show(10,false) // 不要截断列 |
3.2.2 保存为文件
| Scala
object Demo17_SaveDF {
def main(args: Array[String]): Unit = {
val spark = SparkUtil.getSpark()
val df = spark.read.option("header",true).csv("data/stu2.csv")
val res = df.where("id>3").select("id","name")
// 展示结果
res.show(10,false)
} |
保存结果为文件: parquet,json,csv,orc,textfile
文本文件是自由格式,框架无法判断该输出什么样的形式
| Scala
res.write.parquet("out/parquetfile/")
res.write.csv("out/csvfile")
res.write.orc("out/orcfile")
res.write.json("out/jsonfile") |
要将df输出为普通文本文件,则需要将df变成一个列
| Scala
res.selectExpr("concat_ws('\001',id,name)")
.write.text("out/textfile") |
3.2.3 保存到RDBMS
将dataframe写入mysql的表
| Scala
// 将dataframe通过jdbc写入mysql
val props = new Properties()
props.setProperty("user","root")
props.setProperty("password","root")
// 可以通过SaveMode来控制写入模式:SaveMode.Append/Ignore/Overwrite/ErrorIfExists(默认)
res.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/demo?characterEncoding=utf8","res",props) |
3.2.4 写入hive
开启spark的hive支持
| Scala
val spark = SparkSession
.builder()
.appName("")
.master("local[*]")
.enableHiveSupport()
.getOrCreate() |
放入配置文件

写代码:
| Scala
// 将dataframe写入hive,saveAsTable就是保存为hive的表
// 前提,spark要开启hiveSupport支持,spark-hive的依赖,hive的配置文件
res.write.saveAsTable("res") |
3.2.5 DF输出时的分区操作
Hive中对表数据的存储,可以将数据分为多个子目录!
比如:
| Shell
create table tx(id int,name string) partitioned by (city string);
load data inpath ‘/data/1.dat’ into table tx partition(city=”beijing”)
load data inpath ‘/data/2.dat’ into table tx partition(city=”shanghai”) |
Hive的表tx的目录结构如下:
| Plain Text
/user/hive/warehouse/tx/
city=beijing/1.dat
city=shanghai/2.dat |
查询的时候,分区标识字段,可以看做表的一个字段来用
| SQL
Select * from tx where city=’shanghai’ |
那么,sparksql既然是跟hive兼容的,必然也有对分区存储支持的机制!
- 能识别解析分区
有如下数据结构形式:
| Scala
/**
* sparksql对分区机制的支持
* 识别已存在分区结构 /aaa/city=a; /aaa/city=b;
* 会将所有子目录都理解为数据内容,会将子目录中的city理解为一个字段
*/
spark.read.csv("/aaa").show() |
- 能将数据按分区机制输出
| Scala
/**
* sparksql对分区机制的支持
* 将dataframe存储为分区结构
*/
val dfp = spark.read.option("header",true).csv("data/stu2.csv")
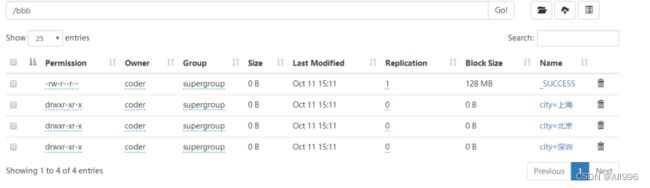
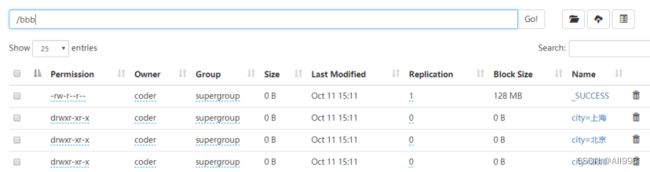
dfp.write.partitionBy("city").csv("/bbb")
/**
* 将数据分区写入hive
* 注意:写入hive的默认文件格式是parquet
*/
dfp.write.partitionBy("sex").saveAsTable("res_p") |
输入结构如下: