MYSQL实战45讲笔记--深入浅出索引
深入浅出索引
索引的常见模型
索引模型:是哈希表、有序数组和搜索树。
区别:
哈希表是一种以键 - 值(key-value)存储数据的结构,只要输入待查找的值即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
有序数组在等值查询和范围查询场景中的性能就都非常优秀。
N 叉树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引擎中了。
InnoDB 的索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。,InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
基于非主键索引的查询需要多扫描一棵索引树。在应用中应该尽量使用主键查询。
索引维护
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
合并:当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
自增主键:是指自增列上定义的主键,定义: NOT NULL PRIMARY KEY AUTO_INCREMENT。
插入新记录的时候可以不指定 ID 的值,系统会获取当前 ID 最大值加 1 作为下一条记录的 ID 值。
自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,我们还可以从存储空间的角度来看。假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型(bigint)则是 8 个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
业务字段直接做主键的场景,比如:有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
这就是典型的 KV 场景。
“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
eg:在下面这个表 T 中,执行 select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行?
mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB;
insert nto T values (100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');

执行流程:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
回到主键索引树搜索的过程,称为回表。这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
覆盖索引
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”查询需求,称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,使用覆盖索引是一个常用的性能优化手段。
需要注意的是,在引擎内部使用覆盖索引在索引 k 上其实读了三个记录,R3~R5(对应的索引 k 上的记录项),但是对于 MySQL 的 Server 层来说,它就是找引擎拿到了两条记录,因此 MySQL 认为扫描行数是 2。
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时需要权衡考虑。
最左前缀原则
B+ 树这种索引结构,可以利用索引的“最左前缀”,来定位记录。
用(name,age)联合索引来分析。索引项是按照索引定义里面出现的字段顺序排序的。
当要是查到所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历得到所有需要的结果。
不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
在建立联合索引的时候,如何安排索引内的字段顺序。
评估标准是,索引的复用能力。因为可以支持最左前缀,所以当已经有了 (a,b) 这个联合索引后,一般就不需要单独在 a 上建立索引了。因此,第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
查询条件里面只有 b 的语句,是无法使用 (a,b) 这个联合索引的.
要考虑的原则就是空间了。比如上面的情况,name 字段是比 age 字段大的 ,就创建一个(name,age) 的联合索引和一个 (age) 的单字段索引。
索引下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
在没有使用ICP的情况下,MySQL的查询:
-
存储引擎读取索引记录;
-
根据索引中的主键值,定位并读取完整的行记录;
-
存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
-
存储引擎读取索引记录(不是完整的行记录);
-
判断条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录;
-
条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
-
存储引擎把记录交给层,层检测该记录是否满足条件的其余部分。
例如:联合索引(name, age)为例。检索出表中“名字第一个字是张,而且年龄是 10 岁的所有男孩”。
mysql> select * from tuser where name like '张 %' and age=10 and ismale=1;
这个语句在搜索索引树的时候,只能用 张,找到的第一个满足条件的记录id为1。
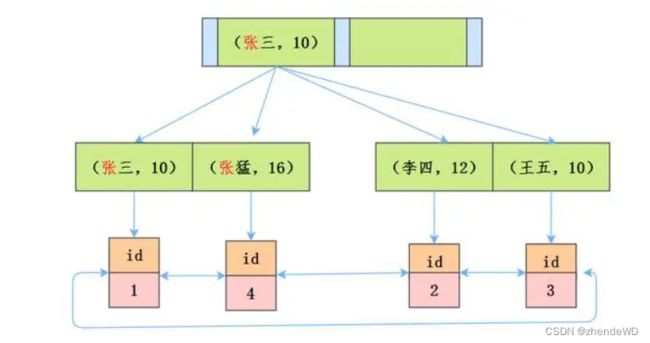
没有使用ICP
在MySQL 5.6之前,存储引擎根据通过联合索引找到name likelike ‘张%’ 的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
需要回表两次,把联合索引的另一个字段age浪费了。

使用ICP
MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到,由于联合索引中包含列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。只回表了一次
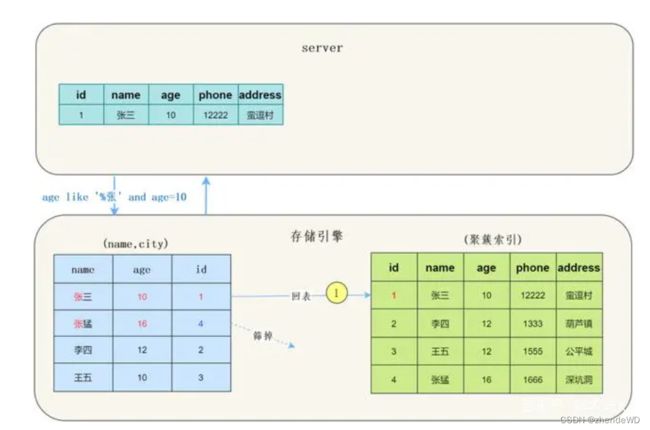
索引下推使用条件
只能用于range、 ref、 eq_ref、ref_or_null访问方法;
只能用于InnoDB和 MyISAM存储引擎及其分区表;
对存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引下推的目的是为了减少回表次数,也就是要减少IO操作。对于的聚簇索引来说,数据和索引是在一起的,不存在回表这一说。
引用了子查询的条件不能下推;
引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
相关系统参数
索引条件下推默认是开启的,可以使用系统参数optimizer_switch来控制器是否开启。
查看默认状态:
mysql> select @@optimizer_switch\G;
*************************** 1\. row
: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
1 row in set (0.00 sec)
切换状态:
set ="index_condition_pushdown=off";
set ="index_condition_pushdown=on";