【Redis故障排查】「连接失败问题排查和解决」带你深入分析一下Redis阻塞原因以及问题排查方案指南
Redis阻塞原因以及问题排查
尽管我们在日常工作中经常使用Redis作为数据库的缓存,以大大减轻数据库压力并提升用户体验,但Redis也可能出现阻塞情况,导致整个系统变慢,进而影响用户体验。
因此,在面对Redis阻塞的情况下,我们可以从以下七个方面进行全面的分析,以确定造成Redis阻塞的具体原因。
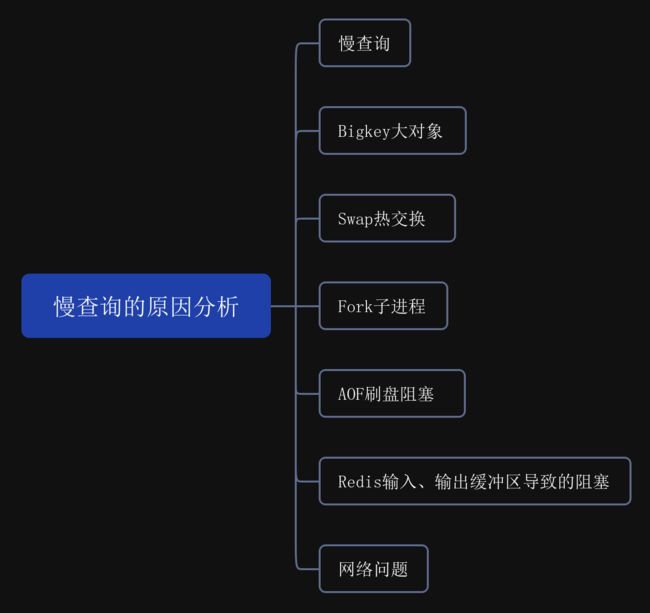
慢查询
因为Redis是单线程的,所以如果出现大量的慢查询,可能会导致redis-server阻塞,可以通过slowlog get n 获取慢日志查看详细情况,如下所示。
> slowlog get 3
34
1688630099
14659
LPOP
Automatic:Plan:wait:RestoreList
192.168.0.168:17777
33
1688608199
12247
LPOP
Automatic:Plan:process:RestoreList
192.168.0.168:61399
32
1688562824
15059
LPOP
Automatic:Plan:process:RestoreList
192.168.0.168:56006
查看慢查询配置
在Redis中,慢查询日志是用来记录执行时间超过阈值的命令的。可以通过配置慢查询相关的参数来控制记录的条件和日志的保存位置。
可以使用CONFIG GET slowlog-*命令来查看现有的Redis配置。这个命令用于获取Redis慢查询日志的相关配置。
CONFIG GET slowlog-*
slowlog-log-slower-than
10000
slowlog-max-len
128
使用CONFIG GET slowlog-*命令可以获取与慢查询日志有关的配置项及其对应的值。该命令会返回一个列表,列表中包含了以slowlog-*开头的配置项的名称和对应的值。
参数介绍分析
slowlog-log-slower-than是Redis的一个配置项,用于设置慢查询日志的阈值。它表示执行时间超过该阈值的命令会被记录到慢查询日志中。在您提供的示例中,slowlog-log-slower-than被配置为10000,单位是微秒(μs),即10毫秒。
这意味着当一个命令的执行时间超过10毫秒时,它将被Redis记录到慢查询日志中。
slowlog-max-len是Redis的另一个配置项,表示慢查询日志的最大长度。它决定了慢查询日志中可以保存的记录数量。在您提供的示例中,slowlog-max-len被配置为128,即最多保存128条慢查询日志记录。
当慢查询日志中的记录达到最大长度后,新的慢查询会替换掉最旧的记录。
通过配置这些参数,您可以根据实际需求,灵活地设置Redis的慢查询日志的阈值和最大长度。这样可以帮助您及时发现影响性能的慢查询操作,并对其进行优化。
注意,执行
CONFIG GET slowlog-*命令需要具备访问Redis配置的权限。如果您没有对应的权限,将无法执行该命令。
bigkey大对象
大对象(bigkey)可能导致以下问题:
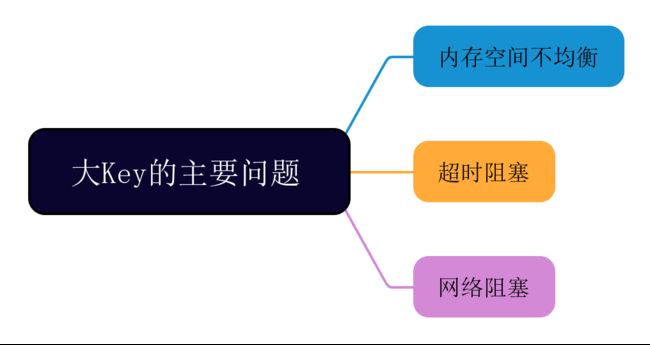
-
内存空间不均衡:在Redis Cluster中,大对象会导致节点的内存使用不均衡。一些节点可能会存储更多的大对象,而另一些节点可能只保存较小的键值对,从而导致内存分配不平衡。
-
超时阻塞:由于Redis是单线程的,处理大对象会占用更多的处理时间,可能导致其他操作的阻塞。如果一个大对象的存取操作耗时较长,那么有可能会造成其他请求的延迟或阻塞。
-
网络阻塞:获取大对象时会产生大量网络流量,尤其在分布式环境中。如果每次获取大对象的操作都会涉及传输大量数据,可能会导致网络拥塞或延迟。
性能问题影响
如果一个大对象几乎不会被访问到,那么对性能的影响相对较小,主要存在内存空间不均衡的问题。但是,如果一个大对象是一个热点key(频繁访问),它将对系统的性能产生重大的影响。
拆分键值
需要根据实际情况来评估和管理大对象,如果一个大对象经常被访问,可能需要将其分解成多个小的键值对,或者使用其他数据结构来存储和处理该对象,以减轻Redis的负担。
集群分片
同样,可以考虑使用Redis的分片、集群等功能来均衡内存使用,并增加系统的扩展性和容错性。
可以通过redis-cli -h {ip} -p {port} bigkeys发现大对象。
swap热交换
前提介绍
首先,Redis在版本3.0之后,从内部代码中删除了对交换空间(swap space)的支持和依赖。因此,Redis 3.0及更高版本不再使用交换空间进行内存交换。
在早期版本的Redis中,如果Redis实例的内存超过可用最大内存限制,操作系统会使用交换空间进行内存交换。然而,这种行为被发现会导致严重的性能下降,并且将Redis带入不稳定的状态,因此在Redis 3.0中已经放弃了对交换空间的依赖。
识别Redis进程号
redis-cli info server | grep process_id
根据进程号查询内存交换信息
cat /proc/{process_id}/smaps | grep Swap
如果交换量都是0kb或者个别的4kb都是正常现象
官方建议
Redis官方建议用户合理配置最大可用内存,并确保Redis实例具有足够的可用内存来容纳数据和处理操作,以避免内存交换问题。这样做可以提高Redis的性能和稳定性,确保良好的的用户体验。
我们可以使用指标"used_memory"来了解Redis当前使用的内存情况。通过监测used_memory的值,可以确定Redis是否接近或超过了最大可用内存的阈值,从而及时做出相应的调整。
为了避免内存交换问题,需要合理配置Redis的内存限制,并确保Redis实例有足够的可用内存来容纳数据和处理操作。这可以通过监控内存使用情况、调整Redis的缓存策略、设置合理的最大内存限制等手段来实现。
分布式Redis集群
为了提高性能和避免内存交换问题,建议单独部署Redis实例或使用分布式Redis集群,并且配置足够的内存,以便满足实际需求和预防潜在的性能问题。
Fork子进程
当Redis执行持久化操作(RDB生成或AOF重写)时,会使用fork系统调用创建一个子进程来完成工作。在执行fork操作时,子进程会复制父进程的内存空间,包括所有数据集的内存表,这会导致fork操作的耗时与内存量(数据集)相关。
根据经验,每GB内存的fork操作耗时大约在20毫秒左右。因此,为了避免长时间的阻塞,需要严格控制每个Redis实例可使用的最大内存在10GB以内,以减少fork操作的执行时间。
查看对应INFO STATS命令分析
可以通过使用Redis的INFO STATS命令来获取lastest_fork_usec指标,它表示Redis最近一次fork操作的耗时。通过监控这个指标,可以了解每次fork操作的耗时情况,并根据需要采取适当的措施,如降低fork操作的频率或调整内存配置,以减少阻塞情况的发生。
INFO STATS
# Stats
total_connections_received:513883995
total_commands_processed:4448904052
instantaneous_ops_per_sec:43
total_net_input_bytes:524046943608
total_net_output_bytes:562840058709
instantaneous_input_kbps:2.20
instantaneous_output_kbps:0.24
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:7725231
expired_stale_perc:0.00
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:1361084505
keyspace_misses:311319261
pubsub_channels:28
pubsub_patterns:6
latest_fork_usec:15086
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
总之,了解fork操作对性能的影响以及控制内存使用是重要的,以确保Redis实例的稳定性和良好的性能。
AOF刷盘阻塞
当Redis开启AOF(Append-Only File)持久化的同时,文件刷盘操作通常每秒执行一次。但是,当硬盘压力过大时,执行fsync操作需要等待写入完成,这可能会导致延迟。
INFO PERSISTENCE
要查看Redis日志或使用INFO PERSISTENCE命令可以获取到aof_delayed_fsync指标,它表示延迟执行的fsync操作的次数。
> INFO PERSISTENCE
# Persistence
loading:0
rdb_changes_since_last_save:1062773605
rdb_bgsave_in_progress:0
rdb_last_save_time:1672120744
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:-1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:0
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:5
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:4104192
aof_current_size:669972573
aof_base_size:366781665
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
Redis的输入/输出缓冲区也可能导致阻塞
当Redis无法及时处理写入数据或无法将数据及时发送到磁盘,输入/输出缓冲区可能会增长,并导致阻塞。为了避免这种情况,可以根据实际情况调整Redis的相关配置参数,如client-output-buffer-limit和aof-rewrite-incremental-fsync等,以控制输入/输出缓冲区的大小和行为。
综上所述,理解和监控aof_delayed_fsync指标以及适时调整Redis的相关配置参数,可以帮助应对可能导致阻塞的硬盘压力和输入/输出缓冲区的问题。
输入缓冲区
要查看输入缓冲区的总容量(qbuf)和剩余容量(qbuf-free),你可以使用Redis的INFO MEMORY命令。
在Redis客户端中,执行以下步骤:
-
使用
INFO MEMORY命令获取内存使用情况的相关信息。INFO MEMORY -
在命令输出中,你会看到关于内存使用的详细信息,包括输入缓冲区的总容量和剩余容量。
# Memory
used_memory: 123456
used_memory_human: 120.57K
used_memory_rss: 456789
used_memory_rss_human: 445.68K
used_memory_peak: 789012
used_memory_peak_human: 770.67K
-
参数介绍
used_memory字段表示Redis使用的总内存。used_memory_human字段表示Redis使用的总内存的人类可读形式。used_memory_rss字段表示Redis的物理内存占用。used_memory_rss_human字段表示Redis的物理内存占用的人类可读形式。used_memory_peak字段表示Redis使用的内存峰值。used_memory_peak_human字段表示Redis使用的内存峰值的人类可读形式。
注意:
qbuf和qbuf-free字段在这个输出中可能不显式地列出,但是你可以根据上面提到的字段来推断Redis的输入缓冲区容量。如果used_memory_peak字段和used_memory_peak_human字段的值为0,那么说明没有分配查询缓冲区,每次只能处理一个命令。
redis为每个客户端分配了输入缓冲区,会将客户端发送命令临时保存,然后取出来执行。
- qbuf 表示总容量(0 表示没有分配查询缓冲区)
- qbuf-free 表示剩余容量(0 表示没有剩余空间);
大小不能超过 1G,当大小超过1G时会将客户端自动关闭,输入缓冲区不受 maxmemory 限制。
Blocked_Clients
当大量的 key 进入输入缓冲区且无法被消费时,即可造成 redis 阻塞;通过 client list 命令可定位发生阻塞的客户端;通过 info clients 命令的 blocked_clients 参数可以查看到当前阻塞的命令。
输出缓冲区
redis-server端实现的一个读取缓冲区,redis-server 在接收到客户端的请求后,把获取结果写入到 client buffer 中,而不是直接发送给客户端。从而可以继续处理客户端的其他请求,这样异步处理方式使 redis-server 不会因为网络原因阻塞其他请求的处理。
网络问题
连接拒绝
当出现网络闪断或Redis连接拒绝时,你可以使用以下方法来解决问题:
网络闪断:
- 检查网络连接是否正常。确保网络连接稳定,没有断开或中断。
- 检查网络带宽是否耗尽。如果网络带宽达到极限,可能会导致闪断。你可以联系网络管理员或提供商以解决带宽问题。
Redis连接拒绝:
- 确认maxclients设置。在Redis配置文件(redis.conf)中,找到
maxclients设置项,确保其值足够大以容纳你的并发连接数。你可以通过修改配置文件来增加maxclients的值。 - 检查已建立的连接数。使用Redis的
INFO STATS命令可以获取有关连接的统计信息。关注rejected_connections字段的值,如果该值增加,说明已经达到了maxclients的限制。你可以通过增加maxclients或优化现有连接以减少连接数来解决此问题。
连接溢出
进程限制
进程可打开的最大文件数控制(ulimit -n)是限制系统中同时存在的文件描述符数量的设置。对于Redis来说,高并发情况下需要处理大量的连接,因此需要增大该值。
增大Redis连接
建议增大ulimit -n的值来满足Redis的连接需求。你可以通过修改系统的配置文件来设置该值。例如,在Linux系统中,可以编辑/etc/security/limits.conf文件或/etc/sysctl.conf文件,并添加如下配置来增大该值:
# /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
# /etc/sysctl.conf
fs.file-max = 65535
然后重启系统或使用sysctl -p命令加载配置。这样可以增大系统对打开文件数量的限制,为Redis提供足够的文件描述符。
backlog队列溢出
backlog队列溢出是指由于系统对于特定端口的TCP连接使用的backlog队列溢出,导致连接无法进入队列,造成连接丢失。
你可以通过定时执行netstat -s | grep overflowed命令来统计backlog队列溢出情况。如果溢出的数量较多,可以考虑增加backlog队列的大小。
参数来增大backlog队列
在Redis中,默认backlog队列大小为511,而系统默认的backlog队列大小为128。你可以通过修改Redis的配置文件(redis.conf)中的tcp-backlog参数来增大backlog队列的大小。例如,将其设置为1024:
tcp-backlog 1024
网络延迟
网络延迟是指数据在网络中的传输所需要的时间。若要优化网络延迟,你可以考虑以下几个方面:
-
确保网络连接的稳定性。检查网络设备和链路,确保没有断开、抖动或故障。可以联系网络管理员或服务提供商来解决网络问题。
-
优化Redis的网络配置。可以调整Redis的
timeout参数,增加客户端与Redis服务器之间的超时时间,以适应网络延迟的情况。默认超时时间为0,即永不超时。你可以根据实际情况适度增加这个时间。 -
使用合适的网络协议及相关优化技术。选择较低的网络协议延迟、使用TCP/IP的Nagle算法或开启TCP_NODELAY选项来减少延迟等方式,都可以帮助优化网络延迟。
开启TCP_NODELAY
TCP_NODELAY是一个TCP套接字选项,用于控制是否启用Nagle算法。Nagle算法通过将数据缓存一小段时间,合并多个小数据包一起发送,以减少网络传输中的报文数量,提升网络吞吐量和效率。但是这种优化策略会增加网络传输的延迟,特别是对于需要实时响应的应用来说,Nagle算法可能会导致延迟较高的现象。
当启用TCP_NODELAY选项时,套接字禁用了Nagle算法,数据会立即发送,并且不会缓冲等待合并。这可以降低延迟,但会增加网络传输的负载。
在Redis中,默认情况下TCP_NODELAY是被禁用的,这意味着Nagle算法是启用的,适用于大部分情况。然而,如果你的应用对实时性要求较高,可以考虑启用TCP_NODELAY来减少延迟。
可以通过Redis的配置文件(redis.conf)中的tcp-keepalive参数来启用TCP_NODELAY。将其设置为1以启用该选项:
tcp-keepalive 1
需要注意的是,启用TCP_NODELAY可能会增加网络带宽的负载,特别是在高并发环境中使用时,可能会影响性能。因此,在启用该选项之前,应该仔细评估你的应用的实际需求,并进行相应的性能测试。
彩蛋介绍
在这里,我向大家推荐一本关于JVM优化和调优的实战系列书籍,《深入浅出Java虚拟机 — JVM原理与实战》。这本书是最新出版的,内容涵盖了与我们当前工作和开发实例密切相关的技术和实战案例。通过学习这本书,我们可以深入了解Java虚拟机的原理,并通过实践掌握优化和调优的技巧。我诚挚地推荐这本书给大家,相信它将为我们的工作和技术发展带来巨大的收益。希望大家能够抽出时间多多学习一下这本宝贵的资料。
【当当-点击链接】【京东-点击链接】
