Neo4j图数据库的使用笔记
Neo4j图数据库的使用笔记
win系统安装Neo4j图数据库
安装准备:
-
neo4j-3.4.0版本的zip包
-
找个目录解压安装zip包
-
启动neo4j
下载neo4j-3.4.0版本的zip包
可以去neo4j官网下载,也可以去微云数聚官网下载。
微云数聚是neo4j在国内的代理商。

解压到F:\neo4j\neo4j-chs-community-3.4.0-windows
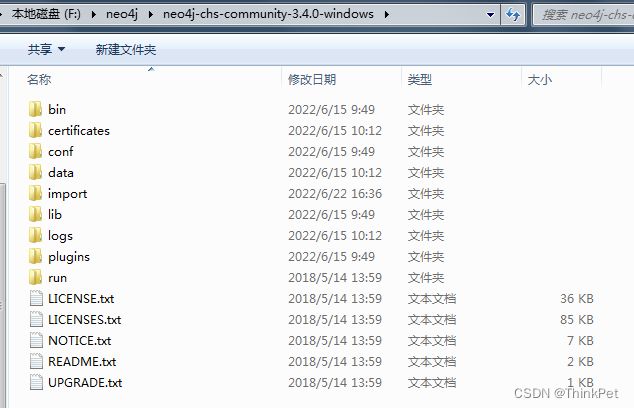
控制台方式启动neo4j
进入bin目录后,在cmd执行 neo4j.bat console 即可启动neo4j
启动成功后,会暴雷2个端口
7687是java 客户端连接端口
7474是neo4j自带的web管理端口

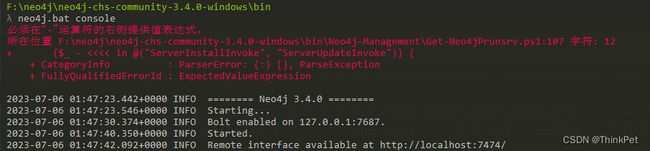
通过7474端口访问neo4j提供的web管理工具
第一次登录时,要输入账户密码,默认的账户是neo4j,密码也是neo4j
登录后,可以再修改密码。
neo4j数据库的概念和特点
neo4j在社交网络分析、推荐系统、知识图谱、网络安全分析等领域被广泛使用。它提供了丰富的功能和工具来管理和操作图数据,并且容易集成到Java和其他编程语言中
neo4j的一些概念特点如下
图数据库
neo4j使用图数据模型来存储数据。图由节点和关系组成,节点用于表示实体,关系用于表示实体之间的关联。
节点Node
节点是图中的实体,可以包含属性来描述实体的特征。
每个节点都有一个唯一的标识符ID,用于在图中识别和访问
关系Relationship
关系用于表示节点之间的连接或关联。
关系可以具有方向,并且可以包含属性。
关系连接两个节点,并且可以用标签来描述关系的类型
属性Property
节点和关系都可以包含属性,属性是键值对形式的的数据。
属性可以用于存储节点的特征信息或关系的属性
Cypher查询语言
Neo4j使用Cypher查询语言来进行查询和操作。
Cypher使用类似SQL的语法,但是针对图数据库进行了优化和扩展
ACID事务
Neo4j支持ACID(原子性、一致性、隔离箱、持久性)事务,
可以确保数据库的数据一致性和可靠性
高性能和可扩展性
neo4j以图的方式存储数据,这使得在遍历 和 查询图数据时非常高效。
同时Neo4j提供了水平和垂直的可扩展性,可以处理大规模的数据集和高并发访问。
neo4j清库方法
清空所有数据
需要在web控制台里执行以下cql语句
match(n) optional match(n)-[r]-() delete n,r
按 节点标签 删除数据
match(n:组织) optional match(n)-[r]-() delete n,r

neo4j索引的添加/查看/删除
neo4j也是可以设置索引的,索引可以加快neo4j的查询速度
neo4j添加索引
-- 对节点的uuid属性加索引
create index on :人员(uuid);
create index on :事件(uuid);
create index on :组织(uuid);
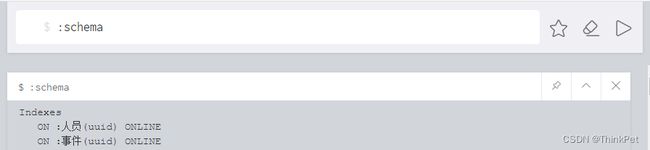
查看neo4j数据库全部索引
:schema
删除Node上已存在的索引
drop index on :人员(uuid);
drop index on :事件(uuid);
neo4j数据库的备份和恢复
win版本neo4j备份
neo4j-admin.bat dump --database=graph.db --to=F:/bak/qbfx.dump

win版neo4j恢复 (恢复之前要先删除graph.db目录)
neo4j-admin.bat load --from=F:/bak/qbfx.dump --database=graph.db

linux版本neo4j备份
./bin/neo4j stop
./bin/neo4j-admin dump --database=graph.db --to=/data/backup/qbfx.dump --force
./bin/neo4j start
linux版本neo4j恢复数据
./bin/neo4j stop
./bin/neo4j-admin load --from=/data/backup/qbfx.dump --database=graph.db --force
./bin/neo4j start
常用的Cypher语句
新建一个Node
新建1个 Node,节点标签是 人员,节点属性是 {name:‘ryt’,age:21}
merge(:人员 {name:'ryt',age:21});
新建一个关联
建立关联 至少要存在2个节点,这里先再建一个节点。
merge(:人员 {name:'myl',age:20});
然后对刚刚建的2个节点,新增关联关系。
找到名字为ryt和myl的2个人,
设置关联关系是 配偶,
关系属性是{name:‘夫妻’,ts:‘20230706’}
match(a),(b) where a.name='ryt' and b.name='myl' merge (a)-[r:配偶 {name:'夫妻',ts:'20230706'}]->(b);
查询所有的xx关系路径
这里查询所有的 配偶 关联关系路径,LIMIT 25意思是限制返回25条
MATCH p=()-[r:`配偶`]->() RETURN p LIMIT 25;
也可以进一步限定节点类型查询关系路径,如
match path=(n:人员)-[r:`共有常住地`]-(b:人员) where n.uuid='4da921fa477248aaa5593da51b3cc002' return path;
查询指定深度的关系路径
深度:2个节点之间间隔的层高
如a–>d–>b , 则a与b直接存在关系路径,且深度为2
如a—>e—>f---->b ,则a与b直接存在关系路径,且深度为3
查询某节点 到其他任意节点的深度为3的路径
match path=(n:人员)-[*..3]-(b)
where n.uid='rr23r23r' and b.uid in ['fretewr','erfw','erf','wer']
return path;
查询a节点到b节点的深度为3的路径
match path=(a:人员)-[*..3]-(b:人员)
where a.uid='rr23r23r' and b.uid='kertyt'
return path;
查询当前节点到指定深度的相关节点有哪些
例:查询当前人员节点 指向 其他(人员或组织)节点 之间的深度为3的 节点有哪些
match(n:人员)-[*..3]-(m)
where n.uid='rr23r23r' and (m:人员 or m:组织)
return m;
修改某个Node节点的属性
例:修改节点的名称
match (n) where n.uid = 'rr23r23r' set n.name = 'lily';
判断是否存在某个Node节点
判断节点是否存在,需要用到count函数。
下面这个例子,返回的是一个布尔值FALSE或TRUE
match (n:人员 {uid:'rr23r23r',name:'lily'}) with count(n) > 0 as node_exist return node_exist;