Traffic Signs Recognition with 95% Accuracy using CNN&Keras
Traffic Signs Recognition
导读
本文采用CNN模型和Keras库
使用GTSRB数据集
构建模型可以分为四部分:1、先探索数据集 2、构建CNN模型 3、训练和验证模型 4、使用测试数据测试模型
保存模型并使用Python自带包tkinter实现GUI
一、数据集

下载完数据后,可以看出在Train文件夹中包含43个文件夹序号从0到42,每个文件夹代表不同的类。
载入所需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
import tensorflow as tf
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from keras.models import Sequential, load_model
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
如果在导入包的时候有报错,可以参考我之前发的几篇
开始探索数据集
关于遍历文件夹还有很多写法,这里就不一一举例了
data = []
labels = []
classes = 43 #共有43个文件夹
cur_path = os.getcwd()
for i in range(classes):
path = os.path.join(cur_path,'Train',str(i))
images = os.listdir(path)
for a in images: # 迭代
try:
image = Image.open(path + '/'+ a) #因为在macos上采用'/',windows改成'//'
image = image.resize((30,30))
image = np.array(image)
#sim = Image.fromarray(image)
data.append(image)
labels.append(i)
except:
print("Error loading image")
#Converting lists into numpy arrays
data = np.array(data)
labels = np.array(labels)
print(data.shape, labels.shape)

数据的形状是(39209、30、30、3),这意味着有39,209张尺寸为30×30像素的图像,最后的3表示数据包含彩色图像(RGB值)。
然后开始分割数据集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)

将y_train和t_test 进行one-hot encoding
![]()
二、开始构造CNN模型
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=X_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(43, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
使用Adam优化器编译模型,该优化器性能良好,损失为“categorical_crossentropy”,因为有多个类要分类。
三、开始训练模型
可以选用batch_size=64或者32,64拟合效果好一点

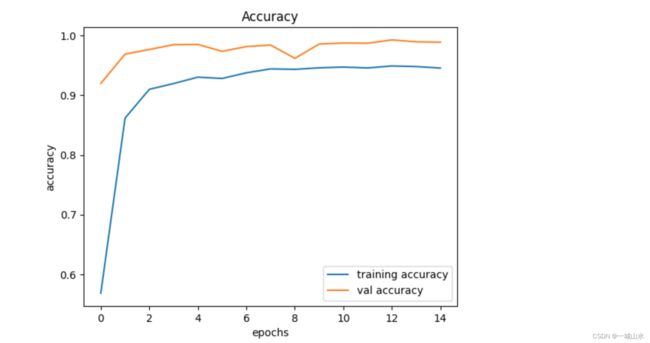
可以看出epochs=10轮以后 开始稳定,模型在训练数据集上获得了98%的精度。使用matplotlib,我们绘制图表的准确性和损失。


四、使用测试数据测试模型
数据集中包含一个测试文件夹,在Test.csv文件中,有与图像路径及其各自的类标签相关的详细信息。使用pandas提取图像路径和标签。然后,为了预测模型,必须将图像大小调整为30×30像素,并制作一个包含所有图像数据的数字数组。从sklearn.metrics中,导入accuracy_score,并观察了模型如何预测实际标签。在这个模型中,实现了96%的精度。

保存模型以便后续GUI做准备

五、Traffic Signs Classifier GUI
使用Tkinter将交通标志分类器构建成一个图形用户界面。Tkinter是标准python库中的GUI工具包。首先使用Keras加载了训练有素的模型“my_model.h5”,然后,构建用于上传图像的GUI,并使用一个按钮进行分类,该按钮调用classify()函数。classify()函数正在将图像转换为形状的维度(1、30、30、3)。这是因为为了预测交通标志,必须提供与构建模型时相同的维度。

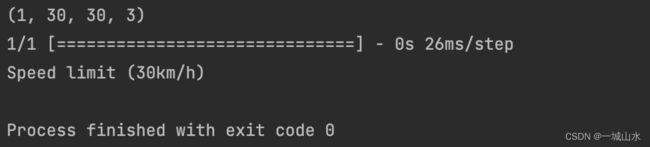
完整代码可以共享,需要请评论或私聊