死信是什么,如何运用RabbitMQ的死信机制?
系列文章目录
手把手教你,本地RabbitMQ服务搭建(windows)
消息队列选型——为什么选择RabbitMQ
RabbitMQ 五种消息模型
RabbitMQ 能保证消息可靠性吗
推或拉? RabbitMQ 消费模式该如何选择
死信是什么,如何运用RabbitMQ的死信机制?
- 系列文章目录
- 前言
- 一、死信与AMQP
- 二、产生死信的场景
-
- 1. 消费失败
- 2. 超时
-
- 消息TTL
- 队列TTL
- 3. 队列饱和
- 三、死信的处理
-
- 1. DLX 死信交换机
- 2. 死信队列
- 3. 一些细节逻辑
-
- (1)死信的路由问题
- (2)死信的循环问题
- 四、死信功能Demo
- 五、死信的应用
-
- 1. 消息堆积报警
- 2. 异常消息检查
- 3. 延迟消费
前言
我们在上次讨论RabbitMQ的消息可靠性时,已经提到了死信队列(详见系列文章《RabbitMQ 能保证消息可靠性吗》),死信概念是RabbitMQ的重要特性,官网也有该特性的介绍,那么这种设计有什么用,我们又该怎么使用死信呢?一起开始本次的学习吧

一、死信与AMQP
死信是指由于某些原因无法被正常投递到目标地址的邮件或消息,而在MQ的语义下,就是无法被消费的mq消息。
从AMQP的规范原文中(AMQP0-9 版本协议文档),我们也可以看到死信相关的说明:

The server SHOULD track the number of times a message has been delivered to clients and when a message is redelivered a certain number of times e.g. 5 times without being acknowledged,the server SHOULD consider the message to be unprocessable (possibly causing client
applications to abort), and move the message to a dead letter queue.
The server SHOULD track the number of times a message has been delivered to clients and when a message is redelivered a certain number of times e.g. 5 times without being acknowledged,the server SHOULD consider the message to be unprocessable (possibly causing client
applications to abort), and move the message to a dead letter queue.
服务器应跟踪消息已传递给客户端的次数,当消息被重新传递一定次数(例如5次)而未得到确认时,服务器应认为该消息无法处理(可能导致客户端要中止的应用程序),并将消息移动到死信队列中。
因此,不难看出RabbitMQ 有死信这种设计,主要是遵从了AMQP规范,其目的是针对一些暂时无法处理的消息,避免其无限循环的同时,也能保证这些MQ消息不会因为暂时无法处理而丢失,能够帮助开发者更好地控制消息的处理流程,提高系统的可靠性和稳定性。
二、产生死信的场景
1. 消费失败
即消费者无法处理消息,或处理失败,最后返回给rabbitMQ服务器一个否定的Ack,并且要求不要重新入队,一般有以下两个方法
// 拒绝单个消息
void basicReject(long deliveryTag, boolean requeue);
// 拒绝一个或多个消息
void basicNack(long deliveryTag, boolean multiple, boolean requeue);
我们以一段 basicReject的代码为例:
// 新建消费者
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println("Received message: " + message);
// 模拟处理消息失败
boolean messageProcessedSuccessfully = false;
if (!messageProcessedSuccessfully) {
System.out.println("Message processing failed, rejecting message...");
// 注意第二个参数设置为为false
channel.basicReject(envelope.getDeliveryTag(), false);
System.out.println("Message rejected");
}
}
};
// 推模式,消费者监听队列
channel.basicConsume(QUEUE_NAME, true, consumer);
需要注意的是,如果是Ack因为网络原因没有发送到RabbitMQ服务器,消息是不会因此就置为死信的。同样,如果Ack 的参数为 requeue = true ,消息也不会被置为死信,而是重新发送到队列尾部(尾部不一定是最后)
2. 超时
超时(Expiration) 一定是因为有个限时(Time-To-Live),而在rabbitMQ中,我们可以为队列和消息设置其TTL。需要注意的是:为队列设置TTL,并不代表队列本身的有效时长,而是指分发进入该队列的消息的有效时长,当消息进入该队列久于该时长,则消息超时.
消息TTL
消息的有效时长设置,是通过 AMQP.BasicProperties 进行设置的
AMQP.BasicProperties properties = new AMQP.BasicProperties().builder()
.deliveryMode(2) // 消息持久化
.expiration("60000") // 有效时长60秒
.build();
channel.basicPublish("", queueName, properties, message.getBytes("UTF-8"));
如上述代码,即消息如果在60秒内没有被消费,则会被自动从队列中移除
队列TTL
为队列设置时长,则需要在声明队列时加上参数 x-message-ttl
Map<String, Object> args = new HashMap<>();
args.put("x-message-ttl", 60000);
channel.queueDeclare(queueName, false, false, false, args);
同样,此时队列中的消息如果在60秒内没有被消费,则会被自动从队列中移除,当队列TTL 和 消息TTL同时设置时,取其中的较小值,为消息有效期
3. 队列饱和
同设置有效时间一样,我们也可以给队列设置个消息上限(消息条数或数据量大小),使用到的参数分别为 x-max-length 和 x-max-length-bytes
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-max-length", 10); // 最大10条
args.put("x-max-length-bytes", 1000); // 最大1000长度的 byte数组
channel.queueDeclare("myqueue", false, false, false, args);
如果超出该限制,rabbitMQ默认将从队列头部拿消息进行移除(一般是队列中最老的),当然这种溢出的处理策略也有其他选择,比如设置 x-overflow 参数为 drop-head (默认), reject-publish 或 reject-publish-dlx
channel.queueDeclare(QUEUE_NAME, true, false, false,
new java.util.HashMap<String, Object>() {{
put("x-overflow", "reject-publish");
}});
三种策略的含义如下:
- drop-head:丢弃队列头部
- reject-publish:拒绝新消息入队尾,如果消息开启了"发布确认",则向消息发布者发送nack
- reject-publish-dlx:与 reject-publish 一样,但如果指定死信交换机,会将该消息转发至死信交换机
三、死信的处理
1. DLX 死信交换机
针对死信的处理,可以选择丢弃和死信交换机(在配置了死信交换机的情况下),我们讨论的自然是后者,这里就画一幅死信交换机的流程图

我们不难发现,死信的现象总是在队列中发生的,因此我们可以给队列设置一个"死信交换机",当出现死信的时候,队列就可以把死信转发给死信交换机。其代码如下
channel.exchangeDeclare("some.exchange.name", "direct");
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "some.exchange.name");
// 为队列 myqueue 设置一个死信交换机,该死信交换机的名字为some.exchange.name
channel.queueDeclare("myqueue", false, false, false, args);
必须注意的是,所谓的”死信交换机“的功能其实和普通交换机并无区别,它只是因为特殊用法,而被我们叫做”死信交换机“而已。
当为一个队列设置了死信交换机时,我们可以在管理面板上,看到该队列的DLX标志。
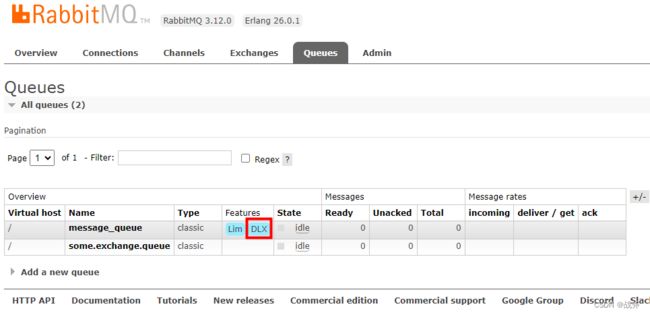
2. 死信队列
绑定在死信交换机上的队列就叫死信队列,因为交换机本身并不存消息,所以死信最终是存储于死信队列中,当然,死信队列本身与普通队列,功能上也没有什么区别。
3. 一些细节逻辑
(1)死信的路由问题
死信从队列转发给死信交换机,也是带有路由键的,如果我们没有特别设置,那么路由键就是消息自身的路由键,如果我们做了如下设置,那么所有由该队列发给死信交换机的消息,路由键都会变成 messageDead.dl
Map<String, Object> args = new HashMap<String, Object>();
// 设置一个死信交换机
args.put("x-dead-letter-exchange", dlxName);
// 设置死信路由键,此处将所有死信的路由键设置为"messageDead.dl"
args.put("x-dead-letter-routing-key", "messageDead.dl");
channel.queueDeclare(QUEUE_NAME, false, false, false, args);
(2)死信的循环问题
一般的消息流程是由交换机分发给队列,然而死信却是从队列发送给交换机。因此不难想象,能否构建一个环状结构,让一个死信又经由死信交换机,最后又回到同一个队列呢?我们不卖关子,环可以构建,但消息不会反复,直接摘抄官方文档如下:
It is possible to form a cycle of message dead-lettering. For instance, this can happen when a queue dead-letters messages to the default exchange without specifying a dead-letter routing key. Messages in such cycles (i.e. messages that reach the same queue twice) will be dropped if there was no rejections in the entire cycle.
有可能形成消息死信的循环。例如,当将死信消息发送到默认交换机而不指定死信路由键时,可能会发生这种情况。如果整个周期中没有拒绝,则此类循环中的消息(即两次到达同一队列的消息)将被丢弃。
四、死信功能Demo
学习完上面的内容,我们实际来运行个demo测试下死信的功能是否如上所诉。
如下代码,我们给一个长度为20的队列设置了死信交换机,然后向该队列发送三十条路由键为”messageAlive“的MQ消息,而与死信交换机绑定的死信队列,则监听着"messageDead.#"的路由
public class AsyncPublisher {
private final static String QUEUE_NAME = "message_queue";
private static final int MESSAGE_COUNT = 30;
private static ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String message = "Hello, RabbitMQ!";
// 声明个容量20条的,带死信交换机的队列
channel.exchangeDeclare("myExchange", "topic");
declareQueueWithDLX(channel);
channel.queueBind(QUEUE_NAME,"myExchange","messageAlive");
// 异步发布确认
channel.confirmSelect();
channel.addConfirmListener(new ConfirmCallback() {
@Override
public void handle(long deliveryTag, boolean multiple) throws IOException {
System.err.println("Sucess to publish message.");
if (multiple) {
ConcurrentNavigableMap<Long, String> confirmed = outstandingConfirms.headMap(deliveryTag, true);
confirmed.clear();
} else {
outstandingConfirms.remove(deliveryTag);
}
}
}, new ConfirmCallback() {
@Override
public void handle(long deliveryTag, boolean multiple) throws IOException {
System.err.println("Failed to publish message.");
}
});
for (int i = 0; i < MESSAGE_COUNT; i++) {
long nextSeqNo = channel.getNextPublishSeqNo();
channel.basicPublish("myExchange", "messageAlive", null, message.getBytes());
outstandingConfirms.put(nextSeqNo, message);
}
System.out.println("All messages published successfully.");
channel.close();
connection.close();
}
static void declareQueueWithDLX(Channel channel) throws IOException {
String dlxName = "some.exchange.name";
String dlqName = "some.exchange.queue";
// 声明个交换机,作为死信交换机,类型为topic
channel.exchangeDeclare(dlxName, "topic");
// 声明个死信队列
channel.queueDeclare(dlqName, false, false, false, null);
// 将死信队列与死信交换机绑定,此处设定路由
channel.queueBind(dlqName, dlxName, "messageDead.#");
Map<String, Object> args = new HashMap<String, Object>();
// 设置一个死信交换机
args.put("x-dead-letter-exchange", dlxName);
// 设置队列最大消息量为 20
args.put("x-max-length", 20);
//args.put("x-dead-letter-routing-key", "messageDead.dl");
channel.queueDeclare(QUEUE_NAME, false, false, false, args);
}
}
预测最终结果:正常队列20条消息是满的,而死信队列因为设置了路由,且关注的是"messageDead.#" , 当死信使用着原始的路由键messageAlive进入死信交换机时,无法被分发到任何队列,所以死信队列一条消息也不会被分发到,我们看看结果:
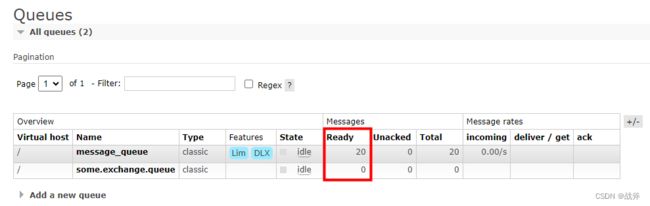
结果符合预期,如果我们把上文 declareQueueWithDLX 方法中的
args.put("x-dead-letter-routing-key", "messageDead.dl");
取消注释,即让死信路由键生效,那么所有发送给死信交换机的消息,都会使用该路由键 “messageDead.dl” ,而不是原来消息的路由键。我们删除队列,再运行一次,预测死信队列将出现十条死信。

结果符合预期,且其中队列的 DLK 标志即 x-dead-letter-routing-key
五、死信的应用
我们把目光回到开头,介绍死信的部分,我们提及了死信机制的目的:是针对一些暂时无法处理的消息,避免其无限循环的同时,也能保证这些MQ消息不会因为暂时无法处理而丢失,能够帮助开发者更好地控制消息的处理流程,提高系统的可靠性和稳定性。
那么在实际中,我们会如何运用死信队列完成上述目的呢?
1. 消息堆积报警
我们可以使用定长队列,如果消费端的消费能力长期小于生产者的生产能力,将会导致大量消息堆积在MQ的队列中,此时使用定长队列,就能在消息溢出时,进入死信交换机->死信队列,只要我们为死信队列建立一个消费着,就可以及时获取到消息堆积情况,并发出报警了
2. 异常消息检查
当一些消息因为暂时无法处理,而被消费端拒收时,此时为队列设置死信转发,就能避免让该消息重复入队并被循环获取,同时还让该异常消息备份进死信队列中,而不至于丢失。这些消息后续可以取出进行重新处理,或分析其异常原因
3. 延迟消费
可以为队列设置TTL,配合死信机制达到延时队列的效果,对于某些需要延迟处理的消息,可以将其发送到TTL队列中,等待一定的时间后,再将其投递到死信队列中,然后被死信队列消费者消费掉。