第十五章 原理篇:YOLOv8
找工作也太难了吧根本找不到工作我哭死。
参考教程:
https://mmyolo.readthedocs.io/en/latest/recommended_topics/algorithm_descriptions/yolov8_description.html
https://zhuanlan.zhihu.com/p/599761847【这个写的挺不错】
https://zhuanlan.zhihu.com/p/633094573【正负样本匹配策略】
文章目录
- 版本回顾
-
- yolov1
- yolov2
- yolov3
- yolov4
- yolov5
- yoloX
- yolov7
- YOLOv8
-
- Backbone
- Neck
- Head
-
- yolov5 detect
- yolov8 detect
- Loss
-
- 正负样本匹配
-
- 流程解析
- get_pos_mask
- select_highest_overlaps
- asiigned target
- 类别损失
- 位置损失
版本回顾
目标检测模型可以分为两种,一种是one-stage模型,它的优点是速度快、适合做实时的检测。另一种是two-stage模型,它的速度通常比较慢,但是效果会相对好一点。
yolo系列就是one-stage模型的代表之作,我们首先来看一下在yolo系列在从v1到v7的更新发展中,都有哪些比较重要的改动。
yolov1
对于一个大小为224x224的输入图像,经过32倍下采样后吗,得到大小为7x7的feature map,并在这个feature map上进行目标检测的预测。
使用两个全连接层进行线性回归,最终得到的输出大小为 7 × 7 × ( 2 × ( 4 + 1 ) + 20 ) 7\times7\times(2\times(4+1)+20) 7×7×(2×(4+1)+20)。其中4代表了xywh,1代表了置信度,20代表了物体的类别。2代表的则是anchor的数量。
这里anchor=2,是考虑到物体的bbox可能有不同的形态和大小,比如说有的物体的bbox是长而窄的,有的是短而宽的。为了让模型能够学习到两种anchor,在训练阶段,只对结果中iou比较高的box做惩罚,iou低的那个不管,目的是使得模型天然地学会不同size/ratio的bbox。
yolov1的优点是简单快速,缺点是每个cell只能预测一个类别,如果出现重叠的话就无法识别。并且对小物体检测效果一般。
yolov2
yolov2又称yolo9000,因为它在做目标检测的同时完成了对9000个类别的分类。yolov2相对v1做出了比较多的改动。
- 使用darknet作为backbone。
- 添加BN层。
- 使用k-means聚类的方法来获得anchor,v2中使用的是5个anchor。
- 使用受限的位置坐标预测。预测相对于anchor的offset而不是直接预测坐标。
- fine-grained features。使用passthrough将高低层特征融合。
它的缺点是target生成的部分和v1一致,所以即使有5个anchor,每个cell也只有一个物体。
对于一个大小为416x416的输入图像,最终得到的输出大小为 13 × 13 × k × ( 4 + 1 + c l a s s e s ) 13\times13\times k\times(4+1+classes) 13×13×k×(4+1+classes)。在这里k=5,classes=20。
yolov3
yolov3使用Darknet53作为backbone,不使用池化层,而是使用卷积层来进行下采样。
在yolov3中,开始使用上采样处理多个feature map,也就是FPN的结构。因此它会在多个feature map上进行预测。对于一个大小为416x416的输入,v3会在13x13,26x26,52x52的输出上进行预测。
三个输出层,每一层都有3个anchor,一共是9个anchor。每一个层的输出大小为 W × H × 3 × ( 4 + 1 + 80 ) W\times H\times3\times(4+1+80) W×H×3×(4+1+80)。3是anchor的数量,4是xywh,1是confidence,80是coco数据集分类的类别。
在正负样本匹配上,yolov3采用的方法是:anchor和目标框左上角对齐后计算iou,和目标框重合度最大的anchor为正样本。【为了扩充正样本数量,实际操作中可以将大于某个阈值的全设为正样本】。
yolov4
在网络结构上,yolov4采用的是CSPDarknet53作为backbone,也就是在darknet中引入了CSP结构。在backbone中使用的激活函数都是Mish,在后续的结构中使用的则是leakyReLU。
此外,yolov4使用了path aggregation network,在完成自上向下的信息传递后,再自底向上,将浅层信息再次带回给深层。
yolov4还采用了一些别的优化策略。
- eliminate grid sensitivity。对于形如 b x = σ ( t x ) + c x bx = \sigma(tx)+cx bx=σ(tx)+cx的中心点预测, σ ( t x ) \sigma(tx) σ(tx)很难处理落在边界上的情况,因此加入一个缩放因子来解决这个问题 b x = 2 × σ ( t x ) − 0.5 + c x bx = 2\times\sigma(tx)-0.5 +cx bx=2×σ(tx)−0.5+cx。
- mosaic data augmentation
- 正负样本匹配。因为修改了中心点预测的边界,所以正样本的范围更广了。变成了三倍。
- 针对512x512的输入优化了anchor。
- 注意力机制。使用了spatial attention module。
yolov5
作为一个一直在维护更新的框架,v5的模型结构也发生过一些变化:
- Backbone: Focus + CSP + SPP -> 6x6conv + CSP + SPPF
- Neck: FPN+PAN -> FPN+CSP-PAN
- Head: 3个检测头
同时它也在v4的基础上进一步消除grid敏感度。在v4中使用了缩放因子优化中心点预测的结果,在v5中则是加强了对w和h的限制。
b w = p w × e t w − > b w = p w × ( 2 × σ ( t w ) ) 2 bw = pw\times e^{tw} ->bw = pw\times(2\times\sigma(tw))^2 bw=pw×etw−>bw=pw×(2×σ(tw))2
在之前的版本中 e t w e^{tw} etw是不受限的,很容易出现梯度爆炸,修改后预测结果的范围被限制在了[0,4]之间。这也带来了正负样本匹配机制上的变化,v4增加了距离上的可选择性,v5增加了anchor大小上的可选择性,只要大小比在[0.25,4]之间,都会认为是正样本。
yoloX
yolox的主要变化在于,使用了解耦的检测头。作者认为reg和cls关注点不同,放在一起会限制表达。
并且yoloX进行的是anchor free的预测。没有anchor的大小来参考了,而是直接预测目标的相对位置。对于一个大小为640x640的输入,会得到在三个featuremap上的结果 W × H × ( 5 + 80 ) W\times H\times(5+80) W×H×(5+80)。三个feature map的大小分别是20x20,40x40,80x80,也就是说一共会得到8500个框。
同时采用了名为SImOTA的正负样本匹配策略。在GT附近挑选候选框作为备选,并根据cost和iou进行筛选。
yolov7
yolov7在模型中引入了re-parameter的方法,并且使用了更多的跳层结构:ELAN,ELAN-W,MP Conv,SPPCSPC等。
在正负样本匹配上,它将v5的匹配方法和x的进行结合。使用v5方法中选出的正样本框作为备选,然后根据cost和iou进行筛选。
yolov7在某些实现中还是用了辅助预测头。辅助头的正负样本匹配的备选范围更广。
YOLOv8
首先来看一下yolov8中都做了哪些改进。
- backbone: 基于yolov7中ELAN的设计,将yolov5中的C3模块用C2F取代。
- head: 使用解耦的检测头,并且从anchor-based转为了anchor-free。
- loss: 使用了名为TaskAlignedAssigner的正负样本匹配策略。并且使用了Distribution Focal Loss。
- data augmentation: 在最后10个training epoch里会不使用mosaic。
Backbone

首先来看一下backbone整体上的差别。
yolov5的stem layer使用的是一共kernel_size=6的卷积,在早期版本中使用的其实是Focus结构,后发现直接使用size=6的卷积能达到同样的效果,所以才直接使用卷积。
在yolov8中使用的是kernel_size=2的卷积,这其实是和v7中一致的。
在剩下的stage中,args都没有什么变化,比较明显的区别是v5中的C3在v8中换成了C2f。并且,the block number has been changed from 3-6-9-3 to 3-6-6-3.

来看一下C3和C2f的区别。
yolov5中的C3就是第一个backbone图中的CSPLayer。C3也就是CSP Bottleneck with 3 convolutions,与之相似的还有C1和C2。

下面源码中的self.cv2代表的就是上图左侧的分支。self.cv1代表的是右侧分支第一个ConvModule。而后经过n个bottleneck后,和左侧分支concat在一起,再经过self.cv3,也就是最下面的这个ConvModule。
这里的bottleneck只要最终的输出结果,用nn.Sequential()进行组合,在forward中会顺序执行多个module。
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
# 这一部分代码展开来写的话就是
# x1 = self.cv1(x)
# x2 = self.cv2(x)
# out = torch.cat((self.m(x1),x2),1)
# return self.cv3(out)
在C2f中增加了更多的跳层连接,看起来也更复杂。

虽然看起来很复杂,但是看代码实现还是比较简单的,和C3的主要区别是,C2f中每个bottlenect的输出都被拿出来,用于最后的concat了。在源码中提供了两个版本的forward,一个是带split的,一个是不带的。
下面源码中的self.cv1就是上图的第一个ConvModule。self.cv1的输出通道是2*self.c,也是为了split的时候可以分成两个大小为self.c的部分。理论上来说这个下面代码中的split和chunk的结果应该是一样的。
self.cv2的输入维度是(2+n)*self.c,因为它的输入concat了split的2个结果和n个bottleneck的结果。
这里的n个bottleneck是用nn.ModuleList()组合在一起的,nn.ModuleList()本身没有forward()的实现,在下面的代码中是按index的顺序来调用bottleneck的。
class C2f(nn.Module):
"""CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
# 这行代码展开来写的话就是
# for m in self.m:
# cur = y[-1]
# out = m(cur)
# y.append(out)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
Neck
下面两个图,左图为yolov8的neck部分的结构,右图为yolov5的neck部分的结构,首先一个比较明显的区别是,yolov5中neck部分的C3结构在yolov8中也被替换成了C2f。


上采样部分对应的config如下图。我们可以看到v8中去掉了v5config中第31行和第36行的两个1x1卷积,并且把C3的结构改成了C2f。
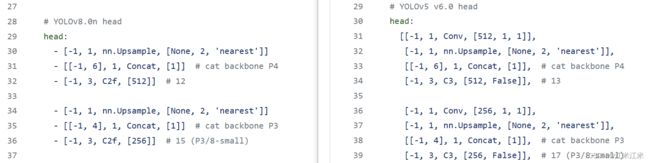
而再往后的下采样+融合部分,除了block的改变外,没有其它改动。
要注意的是,在yolov5 anchor-based版本中,最后一层detect的输入参数还包括了anchor,下面的图中没有包括是因为图例是从yolov8的repo中截取的。

Head
head部分的改动同样是很大的。
- 使用了解耦的检测头。将分类和回归分开。
- anchor-based预测改为了anchor-free的预测。
- 移除了objectness(也就是confidence)的分支。

yolov5 detect
首先来看一下yolov5部分detect的源码。
先看一下构造函数__init__()的部分。它的输入参数中,nc表示分类的类别,如果使用的是coco数据集那么nc默认是80,anchors是预设的anchor的大小。ch是用于预测的三个feature map的通道数。
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.empty(0) for _ in range(self.nl)] # init grid
self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use inplace ops (e.g. slice assignment)
这个构造函数中,和我们的检测头相关的部分就是
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch)
ch中有多少个feature map,就需要接多少个检测头,检测头就是这个ModuleList里的
nn.Conv2d(x, self.no * self.na, 1)
self.na是anchor的数量,在实际使用中是3,self.no = self.nc(分类数)+ 5,在实际使用中是85。
这个分类头就是用1x1的卷积实现feature map通道数的改变,通道这一维度就是我们的预测结果。
在forward部分,输入x是三个featuremap,对每个featuremap用我们的ModueList中的卷积进行处理就好。
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
yolov8 detect
同样先来看一下__init__()的部分,因为在yolov8中是一个anchor-free的预测,所以输入参数中不再有anchor了。
yolov8中使用了DFL(Distribution Focal Loss)。在解耦检测头的设计上也有一点小细节。
def __init__(self, nc=80, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
先来详细看一下代码部分。同时回顾一下结构图。

self.cv2和self.cv3都是用ModuleList组合起来的和featuremap个数相同的block。
和代码中相对应的,self.cv2就是结构图的上面这条分支,用于预测bbox;self.cv3就是下面这条分支,用于预测cls。从代码中我们可以看到,self.cv2中的hidden layer的通道数是c2,self.cv3中hidden layer的通道是c3,两者并不是相等的。因为yolov8认为两个检测头需要有两种不同的表征,所以hidden layer也应该是不一样的。
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100))
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
v8中的预测头已经不包括对objectness的预测,更符合one-stage的概念。
在forward中,对输入的每一个featuremap,进行两个检测头的预测,并把结果concat在一起。
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
Loss
在前面已经提到,yolov8的检测头只包括了box的检测头和cls的检测头,不再有objectness的检测头,那么它的损失函数也就不需要再包括confidence损失,而只分为了类别损失和位置损失。
源码链接:https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/utils/loss.py
正负样本匹配
首先来看一下yolov8中采用的正负样本匹配方法。
源码连接:
https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/utils/tal.py#L57
yolov8中采用的Task-Aligned Assigner是一种在训练过程中动态地调整正负样本分配比例的方法。
正样本是按照分类和回归的加权分数来进行选择的。
t = s α + u β t = s^\alpha + u^\beta t=sα+uβ
- 对于每一个ground truth,assigner都会计算它对于每一个anchor的alignment metric。
- 对于每一个ground truth,基于alignment metric的结果,最大的k个样本被选为正样本。
这部分可以稍微看一下源码【不一定能看懂】。
流程解析
为什么叫流程解析不叫源码解析,因为不想花时间去看复杂的源码。
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
输入的几个参数分别是:pd_scores(预测分数),pd_bboxes(预测框),anc_points(anchor),gt_labels(真实类别),gt_bboxes(真实框)。
在yolov8的损失计算中,就会使用assigner的forward()完成正负样本的匹配。
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
loss的计算也是基于这个assigner返回的target_boxes和target_scores。
看一下在forward()中都做了哪些计算。
get_pos_mask
筛选正样本。整个过程分为三部分:
- 初步筛选,筛出candidates。
- 计算candidates的score。
- 从candidates中选出最终的目标。
首先是筛选出落在gt范围内的candidates。
得到gt的左上角和右下角的值,让anchor_point减去lt,让rb减去anchor_point,如果结果都是正数,说明anchor_point在lt-rb的范围内,也就是落在gt的内部。
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
n_anchors = xy_centers.shape[0]
bs, n_boxes, _ = gt_bboxes.shape
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
# return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)
return bbox_deltas.amin(3).gt_(eps)
得到了初筛的结果后,要在该结果的基础上进行精细化筛出,保留topk的正样本。
下一步就是计算alignment metric,计算的方式是分别计算出box和gt的iou和score,代入公式后得到最终的分数。
得到分数后,从中选出top K的备选。
select_highest_overlaps
同别的动态分配的策略一样,这样分配也可能出现一个anchor被分配给多个gt的情况。
首先判断是否有anchor被分配给了多个gt。采用的是用mask求和的方法,如果大于1,说明存在重复分配。
比较该anchor和多个gt的iou结果,保留iou最大的那个。
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
# (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# Find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
asiigned target
在前面的步骤中,我们已经获得了要用的target_gt_idx和fg_mask。
target_gt_idx: 代表与每个anchor最匹配的gtbox的索引。
fg_mask: 代表该anchor的正还是负。
类别损失
分类的类别不需要额外处理,直接进行计算就可以。从代码中找出来和类别损失相关的部分。通过sigmoid函数来计算每个类别的概率,然后再计算全局的类别损失。
首先是__init__()部分,类别损失使用的是BCEWithLogists。也就是sigmoid和BCELoss的结合。
self.bce = nn.BCEWithLogitsLoss(reduction='none')
然后来看一下forward()部分。这一部分没有对输出的cls和gt进行特别的处理,就是中规中矩的计算过程。
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum
位置损失
yolov8中的bbox的损失分为了两部分,第一部分是iou损失,第二部分是dfl损失。
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum