字符串之谜:如何找到出现频率最高的字符?

博主:小猫娃来啦
文章核心:如何找到出现频率最高的字符?
文章目录
- 需要统计字符出现次数的场景
- charAt()方法
- 查找出现次数最多的字符
-
- 单个字符的情况
- 多个字符出现次数相同的处理
- 对charAt()方法进行效率评估
- charAt()方法的实际应用举例
需要统计字符出现次数的场景
一般的,我们遇到统计字符串出现的次数这种需求时,会在以下一些场景中:
-
在字符串处理过程中,经常需要统计某个字符或字符序列在字符串中出现的次数。例如,校验密码强度时可以统计大写字母、小写字母、数字和特殊字符出现的次数。
-
在Web开发中,需要对用户输入进行验证。统计某些特定字符的出现次数可以用于验证或限制用户的输入。例如,统计输入字符串中逗号、句号或其他特殊字符的出现次数。
-
在数据分析和可视化中,统计字符出现次数可以用来生成柱状图、词云等图表,以展示文本或数据集中不同字符的频率分布。
-
在搜索或替换文本内容时,可能需要统计目标字符或字符串在源文本中出现的次数。这有助于确定匹配的数量或判断是否需要进行替换操作。
-
在编写算法或解决编程问题时,统计字符出现次数可以作为重要的条件或优化策略。例如,判断一个字符串是否是回文可以统计字符出现的次数来进行比较。
一言以蔽之,密码校验,表单验证,可视化数据统计等多种场景下,我们都会遇到这个问题。所以还是蛮重要的,我们看看实现原理到底是什么?具体逻辑又是什么?
这边我推荐一个方法——charAt()
接下来具体看看这个方法
charAt()方法
charAt() 是 JavaScript 字符串对象的一个方法,用于获取指定位置上的字符。
语法如下:
str.charAt(index)
参数 index 表示要获取的字符的位置。注意,字符位置是从 0 开始计数的,即字符串的第一个字符位置是 0,第二个字符位置是 1,依此类推。
charAt() 方法会返回位于指定位置上的字符。如果指定的位置超出字符串长度的范围,返回的结果将是空字符串("")。
举例说明:
const str = "ygugudqwwqeoysakh";
const char1 = str.charAt(4);
console.log(char1); // 输出:u
const char2 = str.charAt(30);
console.log(char2); // 输出:"",因为索引超出了字符串的长度
在这个例子中,首先定义了一个字符串 str,然后通过 charAt() 方法获取了字符串中位于第 4 个位置上的字符,并将其赋值给变量 char1,最后打印输出结果为 “u”。
(0对应y,1对应g,2对应u,3对应g,4对应u,5对应d。。。。) == 下标
接着,尝试通过 charAt() 方法获取索引超过字符串长度的字符(例如第 3 个位置),由于超出了字符串的长度,返回的结果为空字符串 “”。
查找出现次数最多的字符
单个字符的情况
字符串中出现次数最多的字符(以单个字符为例):
function findMostFrequentChar(str) {
const charMap = {};
let maxCount = 0;
let mostFrequentChar = '';
for (let i = 0; i < str.length; i++) {
const char = str.charAt(i);
if (char !== ' ') { // 忽略空格字符
if (charMap[char]) {
charMap[char]++;
} else {
charMap[char] = 1;
}
if (charMap[char] > maxCount) {
maxCount = charMap[char];
mostFrequentChar = char;
}
}
}
return mostFrequentChar;
}
// 调用
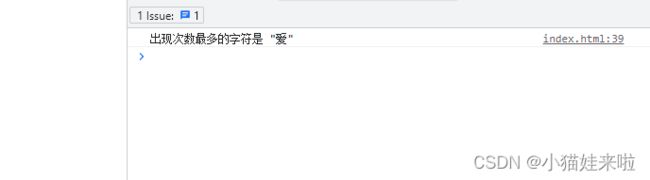
const sentence = "我爱他,也爱你";
const mostFrequentChar = findMostFrequentChar(sentence);
console.log(`出现次数最多的字符是 "${mostFrequentChar}"`);
打印结果:
但是如果我们输入的是这样的:
const sentence = "我爱他";
const mostFrequentChar = findMostFrequentChar(sentence);
console.log(`出现次数最多的字符是 "${mostFrequentChar}"`);
打印结果:
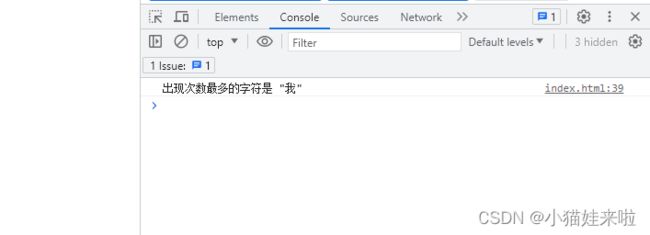
这时候,“我”,“爱”,“你”三个字符,各出现了一次。那么charAt()方法会直接锁定第一个出现次数最多的字符,而忽略其他出现次数相同的字符。
这确实是一个问题,所以多个字符出现次数相同时应该如何处理呢?
我们往下看
多个字符出现次数相同的处理
根据刚刚我们的尝试,发现如果有多个字符出现相同次数时,只会统计第一个。
此时,我们应该将出现次数相同的字符放在一个数组内,并全部打印获取到。因此我们需要略微调整代码的逻辑,使得它看起来更加合理,最终实现此功能。
以下是我们修改后的代码:
function findMostFrequentChars(str) {
const charMap = {};
let maxCount = 0;
const mostFrequentChars = [];
for (let i = 0; i < str.length; i++) {
const char = str.charAt(i);
if (char !== ' ') { // 忽略空格字符
if (charMap[char]) {
charMap[char]++;
} else {
charMap[char] = 1;
}
if (charMap[char] > maxCount) {
maxCount = charMap[char];
mostFrequentChars.length = 0; // 清空数组
mostFrequentChars.push(char);
} else if (charMap[char] === maxCount) {
mostFrequentChars.push(char);
}
}
}
return mostFrequentChars;
}
// 调用函数并打印结果
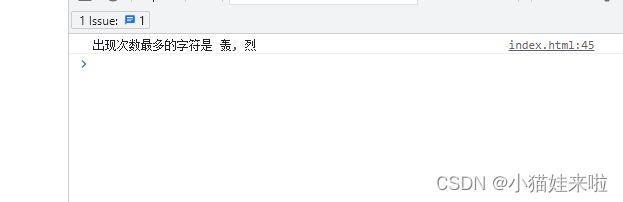
const sentence = "我爱她轰轰烈烈最疯狂";
const mostFrequentChars = findMostFrequentChars(sentence);
console.log(`出现次数最多的字符是 ${mostFrequentChars.join(', ')}`);
打印结果:
在修改后的代码中,我们添加了一个 mostFrequentChars 数组,用于存储所有出现次数最多的字符。
当发现一个字符的出现次数超过当前记录的最大次数时,我们清空 mostFrequentChars 数组,并将该字符添加到数组中。
如果遇到另一个字符的出现次数与最大次数相同,我们也将其添加到 mostFrequentChars 数组中。
最后,函数返回包含出现次数最多的字符的数组。
然后调用函数,并打印结果,发现是正确的,非常舒服和解压。
对charAt()方法进行效率评估
1.从时间复杂度来说,charAt() 方法的平均时间复杂度是 O(1),即常数时间复杂度。这是因为它直接通过索引来获取指定位置的字符,不受字符串长度的影响。
2.从空间复杂度来说,charAt() 方法没有额外的空间消耗,只返回指定位置的字符,所以空间复杂度是 O(1)。
3.从性能方面来说,与其他字符串操作方法相比,charAt() 方法通常是较高效的选择。对于大部分情况而言,在已知索引位置的情况下,直接使用 charAt() 方法可以快速获取指定位置上的字符。
4.从场景方面来说,charAt() 方法适用于需要按照索引位置访问或处理字符串中的字符的情况,例如获取某个特定位置的字符、遍历字符串等。但如果需要频繁地修改字符串或进行复杂的字符串操作,可能会有更适合的方法,如使用数组或字符串拼接方法。
charAt()方法的实际应用举例
⭐⭐字符串截取:可以使用charAt()方法根据索引获取字符串中的单个字符,从而进行字符串的截取操作。
function getFirstCharacter(str) {
return str.charAt(0);
}
var myString = "Hello";
console.log(getFirstCharacter(myString)); // 输出:H
⭐⭐循环遍历字符串:可以使用charAt()方法结合循环来遍历字符串,并对每个字符执行特定操作。
var myString = "Hello";
for (var i = 0; i < myString.length; i++) {
var character = myString.charAt(i);
console.log(character);
}
// 输出:
// H
// e
// l
// l
// o
⭐⭐判断字符串中是否含有某个字符:可以使用charAt()方法获取指定位置的字符,并与目标字符进行比较,判断是否相等。
function containsCharacter(str, targetChar) {
for (var i = 0; i < str.length; i++) {
if (str.charAt(i) === targetChar) {
return true;
}
}
return false;
}
var myString = "Hello";
console.log(containsCharacter(myString, "e")); // 输出:true
console.log(containsCharacter(myString, "z")); // 输出:false
