Tansformer-GPT-1,GPT-2,GPT-3,BERT&Instruct-GPT简介
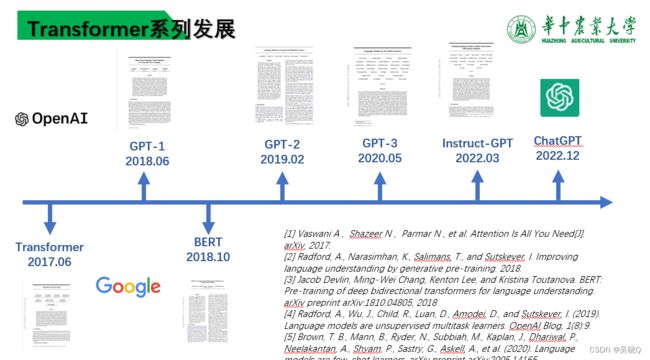
Transformer简述
Transformer模型是一种新型的神经网络结构,由Google在2017年提出,主要用于自然语言处理任务。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer模型在处理长序列数据时具有更高的并行计算能力和更强的语义表示能力。

Transformer模型的基本结构由编码器(encoder)和解码器(decoder)两部分组成,每个部分都包含多个相同的模块。每个模块中有两个子层,分别是多头自注意力机制(self-attention)和前馈神经网络(feed-forward network)。自注意力机制使得模型可以自适应地学习每个词之间的相互依赖关系,前馈神经网络则用于对每个词的特征进行非线性变换和组合。
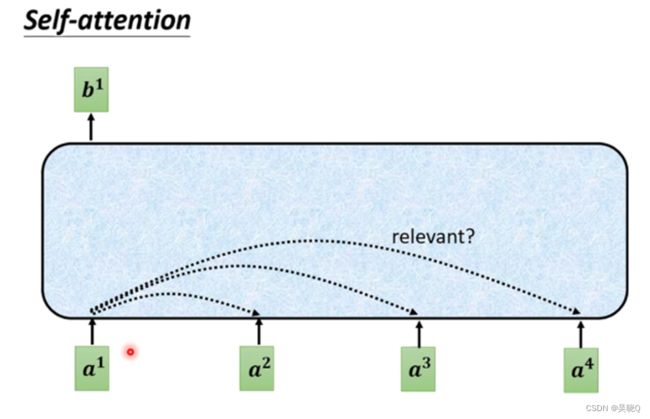
自注意力机制是指在每个编码器和解码器模块中,通过将每个词向量与其他词向量相乘得到每个词的加权表示,其中权重由每个词的语义相关性决定。这样,每个词就可以得到与它相关的上下文信息,而不需要像RNN那样依赖于先前的状态信息。同时,由于Transformer模型中每个词的表示可以同时考虑整个句子的上下文,因此它在处理长序列数据时可以更好地保持信息的完整性和一致性。
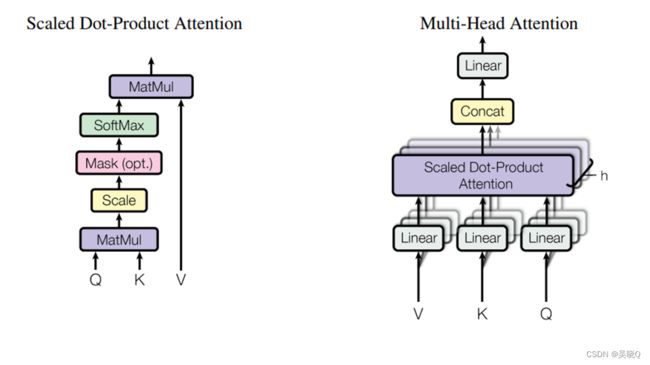
在多头注意力机制中,输入序列首先通过多个不同的线性层,分别映射到不同的维度空间中,然后对这些维度空间中的表示进行自注意力计算,得到多组加权表示。最后,将这些加权表示进行拼接并经过一个线性变换,得到最终的表示结果。
通过这种方式,多头注意力机制可以在不同的视角下学习输入序列的表示,从而让模型在处理复杂任务时更加灵活和准确。
GPT-1
GPT-1(Generative Pre-training Transformer-1)是由OpenAI于2018年发布的第一个基于Transformer模型的预训练语言模型。GPT-1主要针对的是生成型NLP任务,如文本生成、机器翻译、对话系统等。
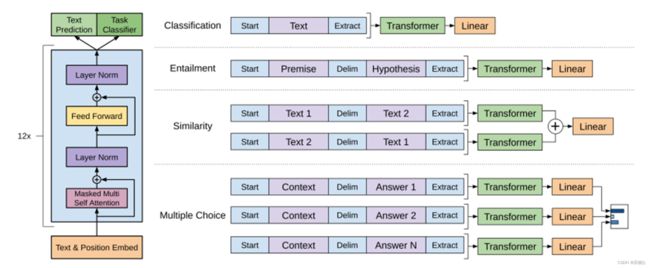
GPT-1的结构和Transformer类似,也由多个相同的编码器组成。每个编码器由12个自注意力头组成,每个头学习一个不同的词之间的关系,然后将这些关系融合起来作为编码器的输出。此外,GPT-1还包含一个额外的位置嵌入(position embedding),用于标记输入序列中每个词的位置信息。
GPT-1的表现已经在多个NLP任务上进行了测试,包括文本生成、文本分类、命名实体识别等。结果表明,GPT-1在生成型任务上表现出了很好的效果,但在其他任务上的表现则与其他模型相比略显不足。然而,GPT-1的发布为后续更高级别的预训练语言模型奠定了基础,并为自然语言处理领域的发展开创了新的局面。
BERT
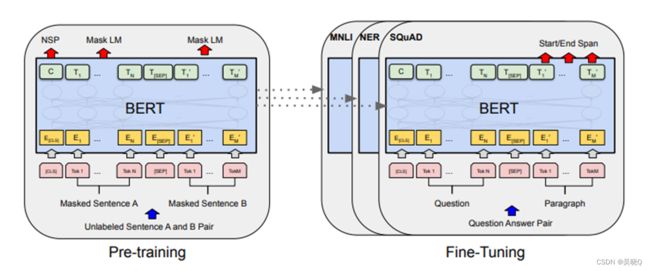
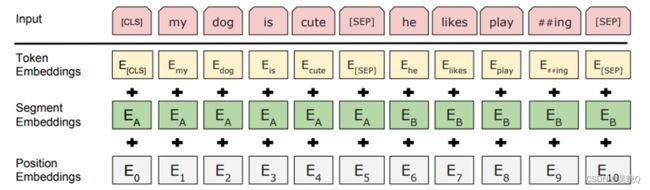
GPT-2
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI于2019年发布的一种基于Transformer模型的预训练语言模型,是GPT-1的升级版。相比于GPT-1,GPT-2在模型规模和预训练数据量上都有了很大的提升。
GPT-2的结构和GPT-1类似,都是由多个编码器组成,每个编码器由12个自注意力头组成。不同的是,GPT-2的模型参数规模比GPT-1大了10倍,达到了1.5亿个参数,预训练数据量也比GPT-1大了10倍,达到了40GB。这使得GPT-2可以学习到更复杂和更丰富的语言表示,从而在生成型任务中表现得更加出色。
创新点 在于去掉了GPT-1中的标注词,使用自然语言的prompt,使得对话更加自然,并且更加注重zero-shot(规模更大了).
GPT-3
GPT-3(Generative Pre-trained Transformer 3)是由OpenAI于2020年发布的一种基于Transformer模型的预训练语言模型,是GPT系列中最大、最强大的一款模型。相比于GPT-2,GPT-3在模型规模和预训练数据量上都有了巨大的提升。
GPT-3的结构和GPT-2类似,都是由多个编码器组成,每个编码器由多个自注意力头组成。不同的是,GPT-3的模型参数规模比GPT-2大了100倍,达到了1.75万亿个参数,预训练数据量也比GPT-2大了10倍以上,达到了570GB。这使得GPT-3可以学习到更加复杂和更加精细的语言表示,从而在多个自然语言处理任务中取得更好的效果。

GPT-3的预训练过程采用了一种名为“万能逼近”的方法。该方法使用了大规模的无监督数据进行预训练,并且在预训练的同时,还对多个任务进行了微调,从而使得模型可以同时完成多个任务。这使得GPT-3在生成型任务和分类型任务等多个自然语言处理任务中都有出色的表现。
GPT-3在生成文本方面表现出了非常惊人的能力。它可以生成各种类型和长度的文本,包括文章、诗歌、对话等。此外,GPT-3还可以根据输入文本的提示进行不同领域的文本生成,如代码、科技、小说等。除了生成文本,GPT-3还可以完成问答、文本分类、命名实体识别等多种自然语言处理任务,甚至可以通过对话与用户进行交互。
GPT大地改进是:
1,更大的模型与参数,更大的训练量
2,应用Sparse Tranformer 指的是通过稀疏化Transformer模型中的attention矩阵来达到减少内存消耗、降低计算力的方法。基本是从图论或者文本特点的角度出发进行简化。
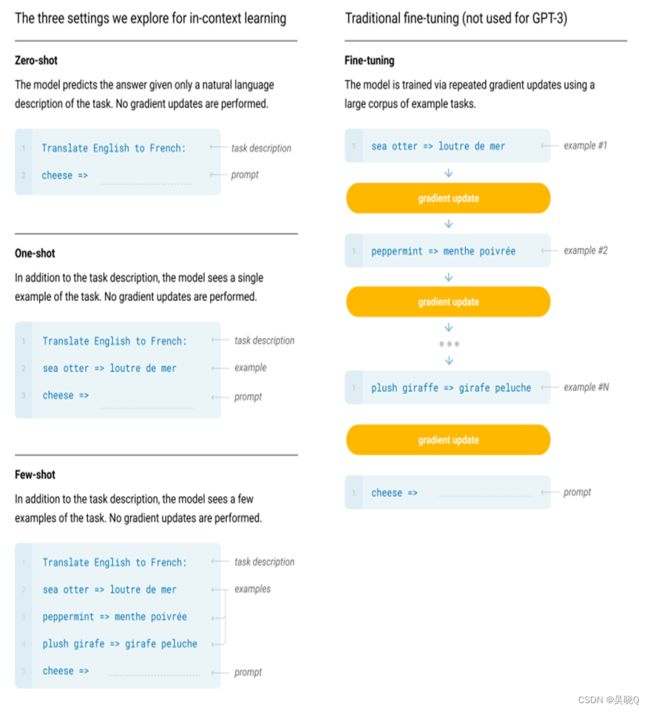
3,few-shot但模型不更新权重,不更新任务
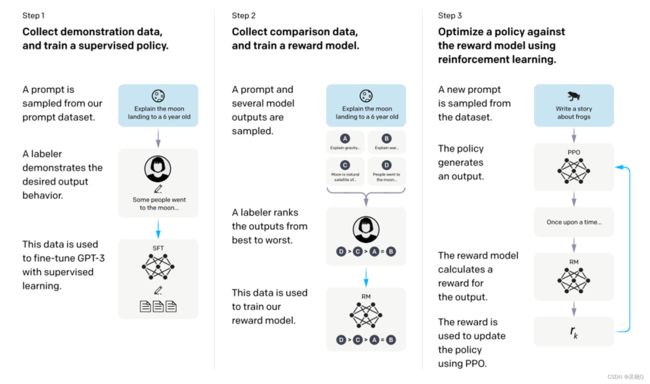
Instruct-GPT
添加了人为的强化学习。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结:
在这个时代,预训练语言模型已成为自然语言处理领域的一个重要研究方向。Transformer模型作为其中的代表,已经取得了令人瞩目的成就。从GPT-1到GPT-3,这一系列预训练语言模型在文本生成、文本分类、问答系统等多个领域都有出色的表现,甚至已经超越了人类在某些任务上的表现。
然而,预训练语言模型的发展也面临着一些挑战。一方面,大规模的预训练模型需要庞大的计算资源和存储空间,这对于一些中小型企业或研究机构可能会造成困难。另一方面,由于预训练语言模型的黑盒特性,其生成的结果往往难以解释和理解,这可能会给人类带来一定的风险和挑战。