微服务spring cloud 五件套整合,eureka、rabbitMQ、hystrix、zuul、config、feign
目录
一、什么是微服务
二、Eureka注册中心
1、什么是注册中心
2、具体配置和代码
三、rabbit实现负载均衡
1、rabbit和Nginx的区别
2、具体配置和代码
四、hystrix熔断
1、什么是hystrix熔断
2、具体配置和代码
五、zuul路由
1、什么是zuul路由
2、具体配置和代码
六、feign介绍
1、什么是feign
2、具体配置和代码
七、Config配置
1、什么是Config配置
2、具体配置和代码
八、RabbitMQ消息中间件
1、什么是消息中间件
2、RabbitMQ的安装
3、RabbitMQ的工作流程
4、生产者的基本配置和代码
5、如何确保消息的可靠投递(可靠生产)
6、消费者消费消息(可靠消费)
7、死信队列
总结
一、什么是微服务
很多人把两种情况都叫做微服务,一种是把代码进行了分层部署,比如controller层、server层、实体层等分别部署在不同的服务器上,这种也有很多人称之为微服务架构,但是我个人不太赞同这种说法,因为微服务有几个基本的概念,① 每个服务必须有自己单独的数据库,② 其中一个微服务崩了或者断开了,其它微服务还能继续正常运行,不受影响。就上面这两条就都不满足了,所以我个人认为这种不能称为微服务架构。第二种是把一个项目不同的模块或者功能进行拆分,分别部署在不同的服务器上,两个服务之间的通信使用消息中间件或者其它稳定可靠的通信技术实现,如:把支付模块单独做成一个微服务,用户的个人信息单独做成一个服务等,需要使用的时候通过消息中间的件发布消息和订阅消费消息来完成通信,这样既可以几个项目共用一个微服务业务,也可以大大提高了系统的抗压性和可扩性,即使其中一个微服务断开,其他的也不受影响,还可以避免业务的重复开发。好处非常多,但是服务器的成本也会相应的增加,对开发人员也需要有一定的技术要求。
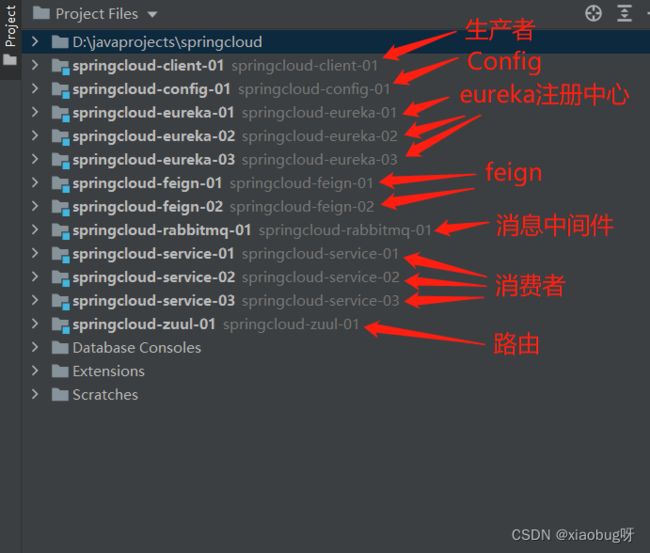
开始之前先看看整个项目的目录:
二、Eureka注册中心
1、什么是注册中心
你可以把注册中心看成一个统一的管理员,所有的微服务都注册登记在这上面,然后访问的时候可以直接通过微服务名称进行访问,就像spring管理依赖一样。
2、具体配置和代码
maven依赖(只有eureka是用的eureka-server,因为它是管理注册的,其它的都是eureka-client客户端注册者,而且所有注册者都需要添加eureka-client依赖,我后面就不贴这种重复的依赖了,不然这篇博客的长度就要超出天际了)
org.springframework.cloud
spring-cloud-starter-netflix-eureka-server
2.2.6.RELEASE
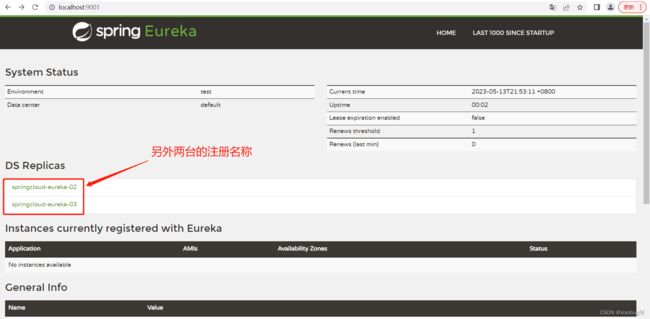
这里采用的是3台Eureka分布式服务
服务1:springcloud-eureka-01
server:
port: 9001
spring:
application:
name: springcloud-eureka-01
eureka:
client:
register-with-eureka: false #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-02:9002/eureka,http://springcloud-eureka-03:9003/eureka
fetch-registry: false #是否检索其他服务
instance:
hostname: springcloud-eureka-01服务2:springcloud-eureka-02
server:
port: 9002
spring:
application:
name: springcloud-eureka-02
eureka:
client:
register-with-eureka: false #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka/,http://springcloud-eureka-03:9003/eureka/
fetch-registry: false #是否检索其他服务
instance:
hostname: springcloud-eureka-02服务3:springcloud-eureka-03
server:
port: 9003
spring:
application:
name: springcloud-eureka-03
eureka:
client:
register-with-eureka: false #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka,http://springcloud-eureka-02:9002/eureka/
fetch-registry: false #是否检索其他服务
instance:
hostname: springcloud-eureka-03三台服务的启动类都是一样的
package com.bug.springcloudeureka02;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@EnableEurekaServer
@SpringBootApplication
public class SpringcloudEureka02Application {
public static void main(String[] args) {
SpringApplication.run(SpringcloudEureka02Application.class, args);
}
}Eureka配置完了,基本不用做其他的事,它只需要管理其他服务的注册即可,启动看看效果!
三、rabbit实现负载均衡
1、rabbit和Nginx的区别
能够学微服务的,应该都是有点开发基础了的吧,相信应该都用过nginx,没用过的也有点了解,nginx是做的请求转发,是在服务器端的,请求进入nginx后,再由nginx转发给不同的服务后端处理请求,从而实现负载均衡。而rabbit的负载均衡是在客户端的,它是通过Eureka里的注册列表实现的。在微服务里不是所有的微服务都需要注册进Eureka吗,既然所有的服务都在这里面了,那是不是就可以把请求通过不同的算法然后交给不同的服务处理呢?rabbit就是这样做的,它也支持随机、轮询、权重等的算法。
2、具体配置和代码
maven依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
2.2.6.RELEASE
我们一样采用3台服务作为例子,模拟分布式环境(这里是3台service服务生产者,生产消息)
第一台:
server:
port: 8001
spring:
application:
name: springcloud-service-01
eureka:
client:
register-with-eureka: true #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka/,http://springcloud-eureka-02:9001/eureka/,http://springcloud-eureka-03:9001/eureka/
fetch-registry: true #是否检索其他服务
instance:
hostname: springcloud-service-01第二台:
server:
port: 8002
spring:
application:
name: springcloud-service-01
eureka:
client:
register-with-eureka: true #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka/,http://springcloud-eureka-02:9001/eureka/,http://springcloud-eureka-03:9001/eureka/
fetch-registry: true #是否检索其他服务
instance:
hostname: springcloud-service-01第三台:
server:
port: 8003
spring:
application:
name: springcloud-service-01
eureka:
client:
register-with-eureka: true #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka/,http://springcloud-eureka-02:9001/eureka/,http://springcloud-eureka-03:9001/eureka/
fetch-registry: true #是否检索其他服务
instance:
hostname: springcloud-service-01启动类(启动类都是一样的,就不重复贴代码了):
package com.bug.springcloudservice02;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@EnableEurekaClient
@SpringBootApplication
public class SpringcloudService02Application {
public static void main(String[] args) {
SpringApplication.run(SpringcloudService02Application.class, args);
}
}具体的controller(controller代码也是一样的,不同的是打印不一样:服务提供者01进入、服务提供者02进入、服务提供者03进入):
package com.bug.springcloudservice01.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class Service01Controller {
@GetMapping("/testService")
public String testService(){
System.out.println("服务提供者01进入...");
return "服务提供者01进入...";
}
}消费者代码,client模拟消费端调用
maven依赖:
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
2.2.6.RELEASE
使用rabbit负载均衡需要加一个配置文件,命名为:Client01Config
package com.bug.springcloudclient01.config;
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import com.netflix.loadbalancer.RetryRule;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class Client01Config {
@LoadBalanced //启用ribbon调用
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
/**
* ribbon的负载均衡策略配置
* @return iRule
*/
@Bean
public IRule iRule(){
return new RandomRule();//随机策略
//return new RetryRule();//重试策略:正常轮训,出现问题后重试,重试不通过则调用其他服务提供者
}
}
controller代码
package com.bug.springcloudclient01.controller;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import javax.annotation.Resource;
@RestController
public class Client01Controller {
@Resource
RestTemplate restTemplate;
@GetMapping("/testClient01")
public String testClient01(){
String message = "消费者01进入...";
String result = restTemplate.getForEntity("http://springcloud-service-01/testService",String.class).getBody();
message += "调用服务提供者..." + result;
System.out.println(message);
return message;
}
}
启动类也是一样的,增加@EnableEurekaClient注解即可,就不重复贴代码了。
模拟的三台生产者和一台消费者就完工了,看看具体效果(多访问几次,这里采用的是随机策略):

OK 搞定,做个测试起了七个服务,差点给我电脑干冒烟了,电脑风扇一直嗡嗡的吹个不停......
整篇文章写完了回过头才看到消费者和生产者好像写反了,不过负载均衡代码是没问题的,实现的效果也是一样的,不改了,写完整篇文章太累了!
四、hystrix熔断
1、什么是hystrix熔断
很简单的一个需求,你的代码出现了bug、服务器报错了咋办?直接把报错信息反馈给用户?那是不是太不友好了,用户一看,哎呀~这什么垃圾系统,太破了,于是连着你们公司都被鄙视了。那如果是返回一个指定的错误页面或者返回一个指定的错误信息给用户呢?hystrix就是做这个事情的,而且它还很强大,因为它过载、报错啥的都能监听到,话不多说,直接上代码(这里是做技术测试,所以只在client客户端、消费端加hystrix了哈,其他地方你想加的话都是一样的)。
2、具体配置和代码
maven依赖:
org.springframework.cloud
spring-cloud-starter-hystrix
1.3.0.RELEASE
controller代码:
package com.bug.springcloudclient01.controller;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import javax.annotation.Resource;
@RestController
public class Client01Controller {
@Resource
RestTemplate restTemplate;
/**
* 设置熔断时间,单位毫秒,超过设置时间没返回则触发error方法
* ignoreExceptions = RuntimeException.class //忽略熔断,取消熔断
*/
@HystrixCommand(fallbackMethod="error",
commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")},
ignoreExceptions = RuntimeException.class
)
@GetMapping("/testClient01")
public String testClient01(){
String message = "消费者01进入...";
String result = restTemplate.getForEntity("http://springcloud-service-01/testService",String.class).getBody();
message += "调用服务提供者..." + result;
System.out.println(message);
return message;
}
//hystrix抛出异常或者超时调用的方法
public String error(Throwable throwable){
System.out.println("服务出错啦...");
return "服务出错啦...";
}
}
还是上面那个消费者,只是在里面加入了熔断,当超过指定的时间后,就会调用下面的error方法,具体怎么处理错误、返回什么就看公司的具体需求了。
启动类代码(增加注解@EnableCircuitBreaker启动熔断即可,还是贴一下代码吧):
package com.bug.springcloudclient01;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@EnableCircuitBreaker
@EnableEurekaClient
@SpringBootApplication
public class SpringcloudClient01Application {
public static void main(String[] args) {
SpringApplication.run(SpringcloudClient01Application.class, args);
}
}这个就不演示了,因为没写具体的业务,搞定收工。
五、zuul路由
1、什么是zuul路由
路由应该很多人都是懂的,不懂的也可以百度一下,一搜一大堆,这里就不啰嗦了。zuul的核心其实是过滤器,但是也能实现路由、异常处理等,而且通过过滤器还能实现动态路由、请求监控、请求认证、灰度发布等,是很强大的。
2、具体配置和代码
maven依赖:
org.springframework.cloud
spring-cloud-starter-netflix-zuul
2.2.1.RELEASE
application.yml配置:
server:
port: 5001
spring:
application:
name: springcloud-zuul-01
eureka:
client:
register-with-eureka: true #是否向自己注册
service-url:
defaultZone: http://springcloud-eureka-01:9001/eureka/,http://springcloud-eureka-02:9001/eureka/,http://springcloud-eureka-03:9001/eureka/
fetch-registry: true #是否检索其他服务
instance:
hostname: springcloud-zuul-01
zuul:
routes:
springcloud-feign-02.path: /bug/** #加上这个后,所有的请求就必须有/bug/这个路径前缀,不然就会404
ignored-services: "*"
启动类:
package com.bug.springcloudzuul01;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
@EnableZuulProxy
@SpringBootApplication
public class SpringcloudZuul01Application {
public static void main(String[] args) {
SpringApplication.run(SpringcloudZuul01Application.class, args);
}
}
需要添加一个配置文件,文件名称:ZuulFilter01
package com.bug.springcloudzuul01.filter;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
@Component
public class ZuulFilter01 extends ZuulFilter {
/**
* 过滤器的在请求中的执行顺序,在哪个生命周期前执行,也可以自定义
* @return pre:在路由之前执行,post、route、static
*/
@Override
public String filterType() {
return "pre";
}
/**
* 所有过滤器的执行顺序
* @return int 0
*/
@Override
public int filterOrder() {
return 0;
}
/**
* 是否启动该过滤器,true执行,false不执行
* @return boolean true
*/
@Override
public boolean shouldFilter() {
return true;
}
/**
* 过滤器的具体逻辑,可以在这里面做一些操作,如:增加token判断,没token的请求直接跳转到一个错误的页面
* @return Object
* @throws ZuulException 异常抛出
*/
@Override
public Object run() throws ZuulException {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
String token = request.getParameter("token");
if(token == null){
ctx.setSendZuulResponse(false);
ctx.setResponseStatusCode(401);
ctx.addZuulResponseHeader("content-type","text/html;charset=utf-8");
ctx.setResponseBody("非法访问");
}
return null;
}
}
代码里面都有注释,就不多解释了,搞定收工!
六、feign介绍
1、什么是feign
是不是在奇怪,spring cloud的五件套不是eureka、rabbitMQ、zuul、hystrix、Config吗,怎么又加了rabbit和feign了?嘿嘿,这就是理论和实战的区别了,feign其实就是整合了rabbit和hystrix,因为在实际开发中单独去使用实在是不太方便,所以就有人把它们整合了起来,feign应运而生。
rabbit和hystrix上面已经都讲过了,这里就不再重复了,用法都是类似的,这里讲一下feign熔断的工厂方法使用方式吧。
2、具体配置和代码
maven依赖:
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
2.2.6.RELEASE
com.buession.springcloud
buession-springcloud-common
2.0.2
org.springframework.cloud
spring-cloud-starter-feign
1.4.3.RELEASE
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
2.1.1.RELEASE
我们添加一个测试的接口,模拟正式开发时的环境:FeignServise02
package com.bug.springcloudfeign02.servise;
import com.bug.springcloudfeign02.fallback.FallbackFactory;
import com.bug.springcloudfeign02.fallback.FeignFallback;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "springcloud-service-01", /*fallback = FeignFallback.class*/ fallbackFactory = FallbackFactory.class)
public interface FeignServise02 {
@RequestMapping("/testService")
public String testService();
}然后就是具体的工厂类了:
package com.bug.springcloudfeign02.fallback;
import com.bug.springcloudfeign02.servise.FeignServise02;
import org.springframework.stereotype.Component;
@Component
public class FeignFallback implements FeignServise02 {
@Override
public String testService() {
System.out.println("feign熔断进入...");
return "feign熔断进入...";
}
}
controller类:
package com.bug.springcloudfeign02.controller;
import com.bug.springcloudfeign02.servise.FeignServise02;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class Feign02Controller {
@Resource
private FeignServise02 feignServise02;
@GetMapping("/testFeign02")
public String testFeign02(){
return feignServise02.testService();
}
}
搞定收工,就是这么的简单,它会自己监听,然后执行工厂类FeignFallback里的testService方法。
七、Config配置
1、什么是Config配置
通过上面的介绍,是不是发现所有的微服务里都要配置一个application.yml文件?几个微服务还好,如果十几个、几十个呢?是不是在修改配置的时候会非常的麻烦?而且有时候还会出现漏改,毕竟人不是机器嘛。config就是解决这个问题的,它把所有的配置统一起来,放到一个地方进行管理,所有的微服务就只需要去读自己的配置就可以了。
2、具体配置和代码
maven依赖:
org.springframework.cloud
spring-cloud-config-server
3.1.1
启动类增加注解:@EnableConfigServer
application.properties配置:
server.port=1001
spring.application.name=springcloud-config-01
spring.cloud.config.server.git.uri=git项目的地址https://******
spring.cloud.config.server.git.search-paths=项目下的子目录
spring.cloud.config.server.git.username=git用户名
spring.cloud.config.server.git.password=git密码需要注意要确定有这个项目,不然会报错的,子路径可以有可以没有,但是通常是有的,注意也不要写错了,不然会访问不到的。配置完后要怎样访问呢?
假设在这个项目里的子目录下,有三个配置文件
application.properties
application-dev.properties
application-test.properties我们访问的通配路径:服务的访问url / 配置文件名称 / 环境名称 / git分支名称,如http://localhost:1001/application/dev/master,返回的是一个json格式的数据,数据太长了我就不贴了,自己访问一下很容易看懂的。
这个是服务端,客户端我们要怎么直接在配置文件里访问呢?
在微服务里添加依赖:
org.springframework.cloud
spring-cloud-starter-config
3.1.1
bootstrap.properties(注意一定要是bootstrap,application级别不够是不行的):
spring.application.name=配置文件名称(application)
spring.cloud.config.profile=环境名称(dev)
spring.cloud.config.label=git分支名称(git分支名称)
spring.cloud.config.uri=服务的访问url(http://localhost:1001/)这样config就会自动把git上的配置文件加载下来,和我们原来在项目里配置的application.properties效果是一样的。
八、RabbitMQ消息中间件
1、什么是消息中间件
消息中间件是微服务里的重点,微服务之间的通信完全由消息中间件处理,是不可忽略的,所以这里会详细的讲解,文章会有点长。
所谓的中间件,就是在两个服务之间再加一层、加一个应用就是中间件,中间件是有很多的,如:消息中间件、数据库中间件等。“消息”指的是两个服务直接的通信、数据交互,所以就叫消息中间件,spring cloud默认集成的是rabbitMQ消息中间件。rabbitMQ和传统的http调用比较,有很多好处,①消息的可靠性,你中间断网了、服务崩了、数据处理失败了,它都能够再次恢复。②高并发的削峰能力,能够极大的减少服务器的压力。③应用的解耦,还有消息的订阅发布等。
2、RabbitMQ的安装
这里演示的是在Linux中通过docker安装,因为使用docker安装非常的简单方便,偷个懒,哈哈,没有安装docker的就百度一下吧,教程非常多,或者采用其他方式安装都是可以的。
① 进入Linux命令终端,执行命令:docker images,这个没实际用处,就检查一下。
② 执行命令:docker search rabbitmq,这个也没实际用处,是查询rabbitMQ镜像的。
③ 执行命令:docker pull rabbitmq,这个是安装镜像。
④ 执行命令:docker run -d --name myRabbitMQ -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -p 15672:15672 -p 5672:5672 rabbitmq,这行命令是最重要的,解释一下:
myRabbitMQ :是docker中的应用名称。
RABBITMQ_DEFAULT_USER:后面登录web页面时的用户名。
RABBITMQ_DEFAULT_PASS:后面登录web页面时的密码。
15672、5672:15672是web访问的端口,5672是应用访问的端口。OK 搞定!web端的访问路径是:你服务的ip + 端口号(15672)如:http://127.0.0.1:15672,注意要开放15672和5672两个端口。
在测试的时候还碰到了个奇怪的问题,rabbitMQ都启动成功了,但是web端就是死活访问不了,最后重启了docker容器和应用解决了,果然重启能解决百分之九十的bug,剩下的百分之十就是浏览器问题,程序员是永远不会承认自己的代码有bug的。
重启docker容器:systemctl restart docker
重启容器里的应用:docker start myRabbitMQ,myRabbitMQ是自己设定的应用名称最后看看web端的效果:
3、RabbitMQ的工作流程
先说一下MQ的流程,首先生产者(客户端)生产一条消息-->放入rabbitMQ消息中间件-->消费者(服务端)消费这条消息,所有的中间件基本都是这个流程。rabbitMQ自己内部也有一个流程,首先连接rabbitMQ建立通道-->然后再创建交换机-->创建队列,交换机和队列是两个很重要的概念,消息会先进入到交换机,然后再由交换机存入队列,消费者从队列里消费消息。rabbitMQ还有两个重要的知识点,正式开发中是一定要处理的,就是消息的准确入队和消息的可靠消费,下面会写怎么处理。
4、生产者的基本配置和代码
maven依赖:
org.springframework.boot
spring-boot-starter-amqp
2.7.3
application.properties配置
#rabbitMQ的服务IP地址
spring.rabbitmq.host=***.***.***.***
#端口号
spring.rabbitmq.port=5672
#用户名
spring.rabbitmq.username=***
#密码
spring.rabbitmq.password=*****
spring.rabbitmq.virtual-host=/创建一个config配置文件,对rabbitMQ的交换机和队列进行统一的管理:RabbitMQConfig
package com.bug.springcloudrabbitmq01.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* rabbitMQ的配置类,正式开发的话一定要分开写
* 不然后面业务增加,队列和交换机也增加,多了全在一个文件里就会很乱,可读性很差
*/
@Configuration
public class RabbitMQConfig {
//队列名称--自定义
public static final String DIRECT_QUEUE = "BUG_TEST_QUEUE";
//交换机名称--自定义
public static final String DIRECT_EXCHANGE = "BUG_TEST_EXCHANGE";
//交换机key名称,也就是路由名称--自定义
public static final String DIRECT_ROUTING_KEY = "BUG_KEY_TEST_QUEUE_EXCHANGE";
/**
* 创建队列
* @return Queue
*/
@Bean("directQueue")
public Queue directQueue() {
return new Queue(DIRECT_QUEUE, true);
}
/**
* 创建交换机,rabbitMQ的交换机是有很多种的
* DirectExchange 直连交换机
* DirectExchange 扇形交换机
* DirectExchange 主题交换机
* DirectExchange 头部交换机
* 不同的交换机可以适用不同的业务,其实就是一个树形的匹配问题,一对一、一对多等,一个消息想发送给一台还是要发送给多台,模糊匹配还是精确匹配等。
* 一篇文章很难把所有的都写到,所以这里就只用DirectExchange直连交换机进行测试了。
* 之前有说,我们的消息是先发送给交换机的,但是我们怎么去发送给指定交换机呢,DIRECT_ROUTING_KEY通过上面的这个名称进行匹配,简称路由key。
* @return Exchange
*/
@Bean("directExchange")
public DirectExchange directExchange() {
return new DirectExchange(DIRECT_EXCHANGE, true, false);
}
/**
* 匹配交换机和队列,可以理解为是把某一个交换机和某一个队列连接起来
* @param directQueue Queue
* @param directExchange Exchange
* @return Binding
*/
@Bean
public Binding bindingDirectExchange(Queue directQueue, DirectExchange directExchange) {
return BindingBuilder.bind(directQueue).to(directExchange).with(DIRECT_ROUTING_KEY);
}
}
代码里有详细的注释,这里就不多介绍了,这样我们的代码就基本写完了,可以尝试启动一下,看看是否有报错出现,rabbitMQ的依赖版本是有坑的,一定要注意和你自己的springboot版本匹配。
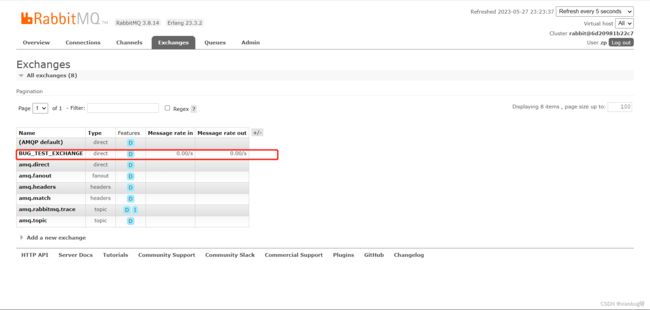
要注意,配置完后要是不使用,是不会在服务里面注册交换机和队列的,所以上面启动后,发现rabbitMQ客户端里没有交换机,这个是正常现象。
创建一个测试的controller类:TestRabbitMQController
package com.bug.springcloudrabbitmq01.controller;
import com.bug.springcloudrabbitmq01.config.RabbitMQConfig;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class TestRabbitMQController {
@Resource
private RabbitTemplate rabbitTemplate;
@GetMapping("/testRabbitMQ")
public void testRabbitMQ(){
//指定交换机,就是config配里的那个交换机名称
rabbitTemplate.setExchange(RabbitMQConfig.DIRECT_EXCHANGE);
//指定路由key
rabbitTemplate.setRoutingKey(RabbitMQConfig.DIRECT_ROUTING_KEY);
//发送消息
rabbitTemplate.convertAndSend("发送一条消息测试一下下啦!");
}
}
看看效果:
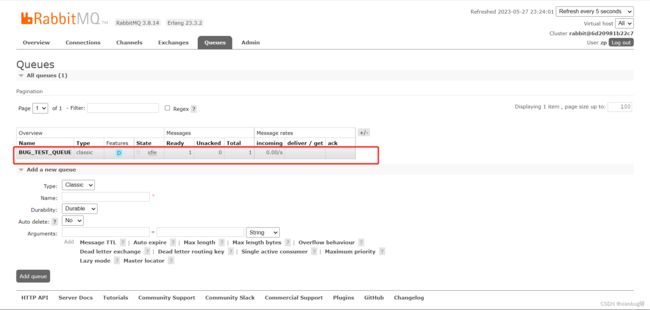
5、如何确保消息的可靠投递(可靠生产)
消息的可靠投递和可靠消费是rabbitMQ的重点,所有单独划分为一个小章节,和上面说过,消息的生产者和rabbitMQ不是在同一个服务器上,那么从一台服务器到另外一台服务器,之间肯定就要有通信,有通信就有可能出现各种意外情况,那要怎样确保消息一定进入rabbitMQ里面呢?
从消息生产者到最后的消息消费,中间其实是分了4部分的,生产者-->rabbitMQ的交换机-->rabbitMQ的队列-->消费者,所有可靠投递是有两部分的,① 确保消息进入rabbitMQ的交换机,② 确保消息从交换机进入队列。第二步是由rabbitMQ完成的,但是也会有返回结果。上代码!
properties.application增加一行配置:
#确认机制
spring.rabbitmq.publisher-confirm-type=correlatedcontroller代码:
package com.bug.springcloudrabbitmq01.controller;
import com.bug.springcloudrabbitmq01.config.RabbitMQConfig;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
@RestController
public class TestRabbitMQController {
@Resource
private RabbitTemplate rabbitTemplate;
@GetMapping("/testRabbitMQ")
public void testRabbitMQ(){
//指定交换机,就是config配里的那个交换机名称
rabbitTemplate.setExchange(RabbitMQConfig.DIRECT_EXCHANGE);
//指定路由key
rabbitTemplate.setRoutingKey(RabbitMQConfig.DIRECT_ROUTING_KEY);
//发送消息
rabbitTemplate.convertAndSend("发送一条消息测试一下下啦!");
}
/**
* PostConstruct 这个注解是在项目启动的时候执行的,是自动调用的
* 可靠生产的整个流程:
* 生产者-->rabbitMQ的交换机-->rabbitMQ的队列
* 而生产者也不是直接就发送消息到rabbitMQ的,最好的处理方式是:生产一条消息后,先把这条消息存入数据库表(也叫消息冗余表),
* 然后加上一些字段做标记(是否需要发送、是否发送成功、发送次数等),
* 发送失败的通过定时器去再次发送(如果有消息一直发送失败,那应该就是消息本身有问题了,要设置一个报警,当发送测试达到多少时,提醒工作人员人工处理),
* 这样就能确保,如果当时消息发送失败了,消息也不会丢失,并且能通过定时器再次发送,还能当成一种日志记录,
* 因为这里是测试,就不去完成这一步了,但是正式开发的话,是一定要这样处理的。
*/
@PostConstruct
public void regCallback(){
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String s) {
//消息就是在correlationData里,可以直接取的,如消息id:correlationData.getId();
//ack就是判断是否发送成功,true成功,false失败
if(!ack){
//发送失败
System.out.println("rabbitMQ消息发送失败啦,消息id是:" + correlationData.getId());
//也可以做一些其他处理,看具体业务需求,处理完就return;即可
}
if(ack){
//发送成功,发送成功一般是要修改数据库那张冗余表的状态的,看具体业务需求处理即可
System.out.println("rabbitMQ消息发送成功!");
}
}
});
}
}
效果:
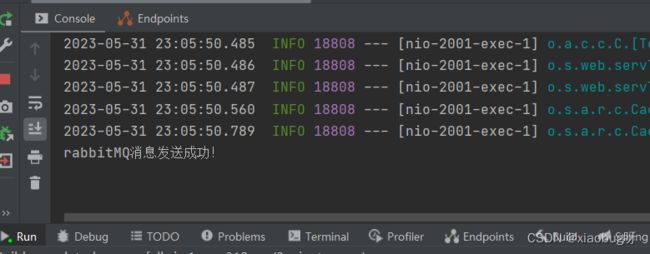
这样就OK了,其实就是用到了rabbitMQ的ConfirmCallback机制。
6、消费者消费消息(可靠消费)
消费端也有两个问题,① 怎样避免重复消费,两种方式可以处理(当然可能还会有其他的):第一种,使用redis的ex或者其他缓存机制,原理其实就是保存消息的id,然后再通过id去判断是否已经消费过了。第二种,使用乐观锁或者消费冗余表,处理之前先校验一下。推荐还是使用第一种方式,这里就不去演示redis的处理了。② 消费端处理消息时报错或者出现异常、宕机的情况,这个就要使用rabbitMQ的ack机制了,rabbitMQ默认是不开启ack的,就是不管你消费端有没有处理成功,我只有把消息给你就算完成任务了,然后移除掉那条消息。这种肯定是不太好的,所以要开启ack,ack的作用就是消费端拿到消息-->处理完成消息了-->最后再回调rabbitMQ,rabbitMQ这时再移除掉那条消息。这样是不是就不会丢失消息了!
我生产端和消费端写在了一个项目里,所以其他配置和上面的第4、第5是一样的,区别在于配置文件新加了个配置:
#开启ack手动应答manual,默认是自动应答
spring.rabbitmq.listener.direct.acknowledge-mode=manual新建一个消费端的类:
package com.bug.springcloudrabbitmq01.server;
import com.bug.springcloudrabbitmq01.config.RabbitMQConfig;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.io.IOException;
@Component
public class RabbitListenerACK {
@Resource
private RabbitTemplate rabbitTemplate;
/**
* queues队列的名称,监听的队列名称
*/
@RabbitListener(queues = RabbitMQConfig.DIRECT_QUEUE)
public void testACK(Message message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) throws IOException {
System.out.println("消费端进入。。。");
System.out.println("消息:" + message);
//处理完后最好在try cache里调用ack回执,这里演示就直接回调了,只有执行了下面这条代码,rabbitMQ里才会移除掉那条消息
channel.basicAck(tag, true);
}
}
效果:

7、死信队列
可靠生产和可靠消费写完了,是不是就感觉没其他问题了?no no no,万一rabbitMQ出现了问题呢?或者处理消息失败了呢?或者其他或者呢?让消息一直重试然后一直失败吗?如果一直这样的话,那不就成死循环了吗。所以,死信队列就出来了。死信队列:收容那些被拒绝的信息、时间超时的信息、消息队列的消息数量已经超过最大队列长度时又被插入的消息;
我们前面是声明了一个正常的交换机和一个正常的队列,然后把这个正常的交换机和队列关联起来,就组成了一个消息的正常业务通道。死信队列也是一样的,只不过需要把正常的队列和死信交换机关联起来。
死信队列的流程:
正常交换机 + 正常队列 --> 关联
死信交换机 + 死信队列 --> 关联
死信交换机 + 正常队列 --> 关联
只要完成上面3个部分就OK了,正常的消息还是在正常的队列里面取,而死信消息就得在死信队列里面取,取的方法都是一样的。如果有多个正常的业务队列需要用到死信,死信交换机是可以共用的,把正常的队列都关联上死信交换机,然后建立多个死信队列,然后通过不同的路由key来区分不同的死信消息就可以了。
上代码!其他的配置都是和上面一样的,不重复贴了,只有config文件需要增加死信队列而已。
package com.bug.springcloudrabbitmq01.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* rabbitMQ的配置类,正式开发的话一定要分开写
* 不然后面业务增加,队列和交换机也增加,多了全在一个文件里就会很乱,可读性很差
*/
@Configuration
public class RabbitMQConfig {
//队列名称--自定义
public static final String DIRECT_QUEUE = "BUG_TEST_QUEUE";
//交换机名称--自定义
public static final String DIRECT_EXCHANGE = "BUG_TEST_EXCHANGE";
//交换机key名称,也就是路由名称--自定义
public static final String DIRECT_ROUTING_KEY = "BUG_KEY_TEST_QUEUE_EXCHANGE";
//死信交换机名称--自定义
public static final String DLX_DIRECT_EXCHANGE = "BUG_TEST_DLX_EXCHANGE";
//死信队列名称--自定义
public static final String DLX_DIRECT_QUEUE = "BUG_TEST_DLX_QUEUE";
//死信的路由key
public static final String DLX_DIRECT_ROUTING_KEY = "BUG_KEY_TEST_DLX_QUEUE_EXCHANGE";
/**
* 创建队列
* @return Queue
*/
@Bean("directQueue")
public Queue directQueue() {
return new Queue(DIRECT_QUEUE, true);
}
/**
* 创建交换机,rabbitMQ的交换机是有很多种的
* DirectExchange 直连交换机
* DirectExchange 扇形交换机
* DirectExchange 主题交换机
* DirectExchange 头部交换机
* 不同的交换机可以适用不同的业务,其实就是一个树形的匹配问题,一对一、一对多等,一个消息想发送给一台还是要发送给多台,模糊匹配还是精确匹配等。
* 一篇文章很难把所有的都写到,所以这里就只用DirectExchange直连交换机进行测试了。
* 之前有说,我们的消息是先发送给交换机的,但是我们怎么去发送给指定交换机呢,DIRECT_ROUTING_KEY通过上面的这个名称进行匹配,简称路由key。
* @return Exchange
*/
@Bean("directExchange")
public DirectExchange directExchange() {
return new DirectExchange(DIRECT_EXCHANGE, true, false);
}
/**
* 匹配交换机和队列,可以理解为是把某一个交换机和某一个队列连接起来
* @param directQueue Queue
* @param directExchange Exchange
* @return Binding
*/
@Bean
public Binding bindingDirectExchange(Queue directQueue, DirectExchange directExchange) {
return BindingBuilder.bind(directQueue).to(directExchange).with(DIRECT_ROUTING_KEY);
}
/**
* 创建死信交换机
* @return dlxDirectExchange
*/
@Bean("dlxDirectExchange")
public DirectExchange dlxDirectExchange() {
return new DirectExchange(DLX_DIRECT_EXCHANGE, true, false);
}
/**
* 创建死信队列
* @return Queue
*/
@Bean("dlxDirectQueue")
public Queue dlxDirectQueue() {
return new Queue(DLX_DIRECT_QUEUE);
}
/**
* 死信队列关联死信交换机
* @param dlxDirectQueue dlxDirectQueue
* @param dlxDirectExchange dlxDirectExchange
* @return Binding
*/
@Bean
public Binding dlxBindingDirectExchange(Queue dlxDirectQueue, DirectExchange dlxDirectExchange) {
return BindingBuilder.bind(dlxDirectQueue).to(dlxDirectExchange).with(DLX_DIRECT_ROUTING_KEY);
}
/**
* 正常队列关联死信交换机
* @param directQueue directQueue
* @param dlxDirectExchange dlxDirectExchange
* @return Binding
*/
@Bean
public Binding dlxBindingDirectExchangeQueue(Queue directQueue, DirectExchange dlxDirectExchange) {
return BindingBuilder.bind(directQueue).to(dlxDirectExchange).with(DIRECT_ROUTING_KEY);
}
}
新加了死信交换机和死信队列后就没运行了,因为我这以前创建过,再创建的话需要把以前的删除掉才行,所以如果复制后有问题那可能需要自己处理了哈,反正原理是我上面说的那样。死信队列的目的就是收集正常处理失败了的消息、过期的消息、超过长度后接收的消息,然后再通过单独的逻辑(也可以理解为另一个消费者)去处理(根据你自己的业务逻辑去处理就可以了),接收消息的方式也是和普通的消费者是一样的。
总结
好了,springcloud微服务五件套就算是写完了,两万六千多字,累呀!其实还有很多地方都没有写到的,但是没得办法,东西太多了,不过只要能完全搞定上面这些东西,做普通的开发还是完全没问题的,进阶版后面有时间单独分开去写。
消息中间件是微服务里的重点,最后再理一下流程:
可靠生产:
数据库建立业务消息的附属表(冗余表)+ 定时器 + confirmCallback确认机制 + returnCallback退回模式;
可靠消费:
手动ack机制 + try cache + 死信队列 + 死信队列附属表,如果死信队列的逻辑也处理失败了,那最后再人工干预;
重复消费:
使用redis缓存加消息id去判断(因为id是唯一的),或者使用数据库乐观锁,当然两种都使用也是可以的,或者其它缓存技术,根据自己的业务去判断就可以了。