数据库基础学习笔记
Oracle数据库
转载请注明出处,请尊重别人的劳动成果,谢谢。数据库的操作大同小异,oracle,mysql,sqlserver等的操作区别不大,但也存在个别的区别!
1.数据的存储
内存 贵 小 容易丢失
FILE 大 便宜 不容丢失
慢 维护不方便 数据损坏 线程
DBMS(database manager system) ----- DB(database)
2.主流的数据库管理系统
Oracle 甲骨文 oracle9i oracle10g oracle11g
db2 IBM db2
sqlserver 微软 sqlserver2003
开源的 mysql sun --- 甲骨文
3.RDBMS
关系型数据库 管理系统
基于二维表的数据库
由行 和 列组成的 表格 叫二维表
表头 table header
行 row
列 column
字段名 field
字段值 field value
表 table
4.访问 oracle
telnet IP
访问本地主机的 Oracle 使用 sqlplus
sqlplus system/123456
SQL>
5.在SQL> 可以写的语句有如下五类 (SQL(struct query language)语句的分类)
select语句 DQL(data query language) 数据查询语句
DML (data manipulation language) 数据操作语句
insert delete update
DDL (data define language) 数据定义语句
create table(创建表) drop table(删除表) alter table(修改表)
TCL (transaction control language) 事务控制语句
commit 提交 rollback 回退 savepoint 保存点
DCL (data control language) 数据控制语句 (DBA 数据库管理员)
grant 授权 revoke 回收授权
6.修改语言环境 和 初始化数据基本数据
1.配置一个环境变量
NLS_LANG AMERICAN_AMERICA.UTF8
2.初始化运行环境
SQL>@文件路径/***.sql
SQL>desc s_emp;
ID 员工编号
LAST_NAME 姓
FIRST_NAME 名
USERID 用户编号
START_DATE 入职日期
COMMENTS 备注
MANAGER_ID 直接领导的员工编号
TITLE 职位
DEPT_ID 部门编号
SALARY 月薪
COMMISSION_PCT 提成
SQL>desc s_dept 部门表 SQL> desc s_region 地区表
ID 部门编号 ID 地区编号
NAME 部门名 NAME 地区名
REGION_ID 地区编号
7.desc 表名;
字段的名字
NULL? 字段是不是可以为 空 如果是可以为空则没有 NOT NULL 否则必须有值
字段的类型:
number 数字类型(整数 浮点 long)
number(11,2) 总长度是11 小数点后占 2 位
varchar2(n) 代表字符串类型 n 长度
date 日期类型 这里包含了 年 月 日 时 分 秒 信息
8.select语句中的 from 子句
8.1 如何从表中查询一个字段对应的内容
select 字段名 from 表名;
从 s_emp 表中查询 salary 字段对应的内容
select salary from s_emp;
从 s_dept 表中查询 name 字段对应的内容
select name from s_dept;
8.2 如何从表中查询多个字段对应的内容
多个字段 使用 英文逗号 隔开
从s_emp 表中查询 id first_name salary 对应的值
select id,first_name,salary from s_emp;
col first_name for a20; (了解)
把叫 first_name 的这一列 一行最多显示 20个字符
8.3 如何从一个表中 查询所有字段对应的内容
select id,name,region_id from s_dept;
一个字段 一个字段的 写 是可以完成的
但 * 可以代表 所有的字段名
select * from s_dept;
8.4 sql语句中 数学运算
+ - * / (除法没有取整)
select salary,salary+1000 from s_emp;
显示 s_emp 表中的 每个员工的月薪 和 年薪
select salary,salary*13 from s_emp;
计算每个员工 每天的平均工资 (一个月按照 21 个工作日计算)
select salary,salary/21 from s_emp;
8.5 sql 语句别名问题
字段或者表达式 都可以出现另外一个名字 我们称之为别名
select salary sal,salary/21 day avgsal from s_emp;
别名自动变大写
一个字段或者表达式 别名只能有一个
解决上面的这两个问题 我们可以使用 双引号
原样显示
把别名看成一个整体
select salary "sal",salary/21 "day Avgsal" from s_emp;
8.6 sql中字符串
在数据库中 使用 单引号表达
' ' 'a' 'hello world'
sql中字符串的值 要区分大小写 而sql语句不区分大小写
8.7 字符串的拼接
|| oracle中叫 字符串连接符
select first_name || last_name from s_emp;
在first_name 和 last_name 之间 拼接一个 $ 字符串
select first_name || '$' || last_name from s_emp;
特殊情况 是 要拼接一个 单引号 需要使用两个单引号 代表一个单引号(转义)
select first_name || '''' || last_name from s_emp;
8.8 NULL 处理
NULL 值和 任何值做运算 结果都是NULL
nvl(par1,par2) 这个函数当par1的值为NULL时 则返回 par2的值,否则就返回par1的值
现在重新计算一下年薪 年薪的计算方式是 月薪*12 再加上 月薪*12*(提成/100)
select salary*12,commission_pct,salary*12+salary*12*(commission_pct/100)
from s_emp;
select salary*12,commission_pct,
nvl(salary*12+salary*12*(commission_pct/100),0)
from s_emp;
NULL 值要尽早处理
select salary*12,commission_pct,
salary*12+salary*12*(nvl(commission_pct,100)/100)
from s_emp;
8.9 数据排重
重复的数据 只保留一次
distinct 排重关键字
select salary from s_emp;
select distinct salary from s_emp;
多字段的排重
当你需要 多个字段 联合起来 值相同时 过滤掉 则使用多字段排重
select distinct id,salary from s_emp;
select distinct title,salary from s_emp;
select title,salary from s_emp;
9.where 子句
9.1 什么是where
where子句 又叫条件子句 是用来限制表中的行数据返回的 满足where条件的数据
被选中 不满足where条件的数据被过滤掉。
9.2 举例
两个极限条件
select 字段名 from 表名 where 1=1; 恒等条件 永真条件
select 字段名 from 表名 where 1 != 1 恒假条件 永假条件
select id from s_emp where 1=1;
select id from s_emp where 1!=1; // no rows selected
9.3 number 类型条件的表达
找出id 等于 1 的 员工 显示 id first_name salary
select id,first_name,salary from s_emp where id=1;
找出 salary 等于 1450 的员工 显示 id first_name salary
select id,first_name,salary from s_emp where salary=1450;
9.4 字符串类型 条件的表达
查询 first_name 叫 Carmen 的 员工 显示 id first_name salary
select id,first_name,salary from s_emp where first_name='carmen';
字符串的表达 需要使用单引号
字符串的值 大小敏感
SELECT id,first_name,salary FROM S_EMP where first_name='Carmen';
9.5 常见的比较运算符
= != > < >= <=
9.5.1 sql 中的4个运算符
9.5.1.1 where 字段 in(值1,值2,值3)
只要这个字段的值 出现在后面的列表中就选中
查询s_emp 表中 dept_id 在 31 或者 在 32 或者 在50 部门的员工 显示 first_name
dept_id
select first_name,dept_id from s_emp where dept_id in (31,32,50);
9.5.1.2 where 字段 between a and b
表达这个字段的值 在 [a,b] 之中
查询 s_emp 表中 salary 在 1300 到 1500 之间 的员工 包括1300 和 1500
显示 id first_name salary
select id,first_name,salary from s_emp where salary between 1300 and 1500;
9.5.1.3 NULL 值判断运算符 where 字段 is null
其它的运算符 对NULL 值判断无效
select id,first_name from s_emp where manager_id = 1;
select id,first_name from s_emp where manager_id != 1;
select id,first_name from s_emp where manager_id is null;
9.5.1.4 模糊查询 where 字段 like '模糊查询统配串';
找出所有的姓李的人 李元霸 李元吉 李靖 李双江
找出所有的带 龙的昵称 史泰龙 成龙 小龙虾 小龙女
模糊查询统配串 中有两个通配符
_ 代表一个任意字符
% 代表 0-n个任意字符
查询 s_emp 表中 所有带 a 的 first_name
select first_name from s_emp where first_name like '%a%';
在上面查询的基础上 找出 倒数第二个字符是 a 的
select first_name from s_emp where first_name like '%a_';
介绍一张表 叫 user_tables 这张表中记录了所有表的信息 S_EMP S_DEPT 都在这张表中
找出所有的 以 S_ 开头的表名
_ 既要表达 下滑线 又要表达一个任意字符 需要转义成 _ 的含义
select table_name from user_tables where table_name like 'S\_%' escape '\';
9.5.2 逻辑条件连接符
与 and
找出工资 在 (1300,1500)之间的员工
select id,salary from s_emp where salary > 1300 and salary < 1500;
或 or
找出部门编号 在 31 或者 32 或者 50 部门的员工 显示 id dept_id
select id,dept_id from s_emp where dept_id = 31 or dept_id = 32 or dept_id =50;
非 not
= != <>
> <=
< >=
in not in
between and not between and
like not like
is null is not null
除了 最后一个 其它注意 NULL 问题
找出提成 不是 NULL 的 员工 显示 id first_name commission_pct
select id,first_name,commission_pct from s_emp
where commission_pct is not null;
9.5.3 条件的优先级
-- 只对 31部门限制 不对 42 部门限制 salary
select dept_id,salary from s_emp
where salary>1000 and dept_id=31 or dept_id=42;
-- 提升后面条件的优先级 对两个部门的salary 都限制
select dept_id,salary from s_emp
where salary>1000 and (dept_id=31 or dept_id=42);
10.sql中的排序
10.1 语法
from 表 where 条件 order by 排序标准 排序方式关键字;
order by 永远出现语句最后
排序标准:工资 身高 体重 头发长短
排序的方式:升序(默认的顺序 自然顺序 字典顺序 asc 可以省略)
降序 desc
10.2 举例
按照工资排序 显示 id first_name salary
select id,first_name,salary from s_emp order by salary;
select id,first_name,salary from s_emp order by salary asc;
select id,first_name,salary from s_emp order by salary desc;
10.3 NULL 值 在排序中 如何处理的?
作为最大值处理
select id,first_name,manager_id from s_emp order by manager_id;
select id,first_name,manager_id from s_emp order by manager_id desc;
10.4 当第一排序字段的值相同时 可以启用第二排序字段进行排序
select id,first_name,manager_id from s_emp order by manager_id desc,id desc;
11.单行函数
11.1 函数的分类
单行函数: sql语句影响数据多少行 就 针对每一行 返回一个结果
sql语句影响多少行 就返回多少个结果
组函数: 无论sql 语句影响多少行 只返回一个结果
11.2 举例
select first_name,upper(first_name) uname from s_emp;
select first_name,upper(first_name) uname from s_emp where id=1;
select first_name,upper(first_name) uname from s_emp where id<1;
select first_name,upper(first_name) uname from s_emp where id>1;
组函数的例子 sqlplus 中要求数据一对一显示
select count(first_name) cname from s_emp where id=1;
select count(first_name) cname from s_emp where id<1;
select count(first_name) cname from s_emp where id>1;
max
select max(first_name) uname from s_emp where id>1;
11.3 为了学习单行函数方便 引入了一个 单行 单列的 表 叫 dual
select * from dual;
select lower('HELLO') from s_emp;
select lower('HELLO') FROM DUAL;
11.4 处理字符串的函数
upper 变大写
lower 变小写
length 求字符串长度
select length('hello') from dual;
concat(par1,par2) 连接两个字符串 并返回连接之后的
select concat('ab','cd') from dual;
'ab' || 'cd' || 'ef' 推荐使用 || 否则连接比较麻烦
nvl(par1,par2) 可以处理任何类型
要求par1 和 par2 的类型保持一致
substr(par1,par2,par3)
par1 要处理的字符串
par2 从什么位置开始截取 编号从1开始 也可以是负数 -1 代表最后一个字符
par3 截取的长度
select substr('hello',0,2) from dual;
select substr('hello',1,2) from dual;
select substr('hello',2,2) from dual;
select substr('hello',-2,2) from dual;
replace(par1,par2,par3) 了解一下
select replace('one world one dream','one','two') from dual;
11.5 处理数字的单行函数
round(par1,par2) 四舍五入
par1 要处理的数字
par2 精度 要保留多少位小数 默认保留0位 就是取整
select round(9.53) from dual;
select round(12.88) from dual;
select round(9.53,1) from dual;
select round(12.88,1) from dual;
select round(12.88,-1) from dual;
trunc (par1,par2) 截取
par1 要处理的数字
par2 精度 要保留多少位小数 默认保留0位 代表切掉指定位置
select trunc(9.53) from dual; 9
select trunc(12.88) from dual; 12
select trunc(9.53,1) from dual; 9.5
select trunc(12.88,1) from dual; 12.8
select trunc(12.88,-1) from dual; 10
11.6 格式化 显示函数
to_char(par1,par2)
par1 要格式化显示的数据 目前是数字类型的数据或者字段
par2 格式化字符串 可以省略 省略之后代表把任何类型变成字符串
FM 代表格式的开始 可以省略 format 的缩写
$ 美元符号
L 代表本地货币符号 ¥ RMB
9 小数点前 代表 0-9 的任意数字
小数点后 代表 1-9 的任意数字
0 小数点前 代表 强制显示前导零 12345.68 012,345.68
9999.95 009,999.95
小数点后 代表 0-9 的任意数字
, 分割符号
. 小数点
select to_char(12345.68,'FM$099,999.99') from dual;
select to_char(12345.68,'FM$099,999.00') from dual;
按照如下格式 FM$099,999.99 显示 s_emp 表中的 salary
select to_char(salary,'FM$099,999.99') from s_emp;
select to_char(salary,'FM$099,999.00') from s_emp;
// L 和 配置的语言环境变量有关
select to_char(salary,'FML099,999.00') from s_emp;
NLS_LANG 语言_地区.编码
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
11.7 函数的嵌套
把一个函数的返回值 作为另一个函数的参数
截取 s_emp 表中的first_name 后三个字符 并把这三个字符变大写
select first_name,upper(substr(first_name,-3,3)) from s_emp;
select first_name,upper(substr(first_name,length(first_name)-2,3)) from s_emp;
把S_EMP 表中 的 id first_name manager_id 显示出来 如果manager_id 是 NULL
显示成BOSS。
select id,first_name,nvl(to_char(manager_id),'BOSS') from s_emp;
12.多表查询
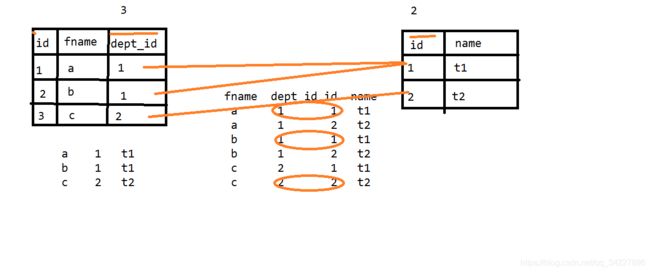 表连接
表连接
//内连接
12.1 为什么要有多表查询
因为我们需要的数据 来自于多张表
12.2 如何实现?
查询 每个员工的 first_name dept_id
select first_name ,dept_id from s_emp;
在上面查询的基础上 要显示部门的名字
select first_name ,dept_id,name from s_emp,s_dept;
笛卡尔乘积
把两张表 所有的可能都会被匹配出来
限制笛卡尔积中无用数据的生成 (使用连接条件)
如果两个表中有同名字段则使用 表名点 进行区分
select first_name ,dept_id,name from s_emp,s_dept
where dept_id = s_dept.id;
12.3 显示 s_dept 表中的 部门名 以及 对应的 s_region 的地区名
select s_dept.name,s_region.name
from s_dept,s_region
where region_id = s_region.id;
12.4 可以使用 表的别名 简化上面的 查询
select d.name,r.name
from s_dept d,s_region r
where region_id = r.id;
12.5 上面的查询 无论 是 员工表和部门表 还是 部门表和地区表
连接都是 等号 这个连接符来做的 比如
dept_id = s_dept.id
region_id = s_region.id
这种连接我们称之为 等值连接
12.6 非等值连接
不使用等号 作为连接符号 就叫非等值连接
salgrade 工资级别表
losal 这个级别对应的低工资
hisal 这个级别对应的高工资
grade 工资级别
写一个sql 查询每个员工的 salary 和 对应的 工资级别
select salary,grade
from s_emp,salgrade
where salary between losal and hisal;
select salary,grade
from s_emp,salgrade
where salary >= losal and salary <= hisal;
12.7 自连接
 自连接
自连接
12.7.1 什么时候用
一张表中 有两层 或者两层以上的业务含义的数据 要把其中的一层含义的数据找出来
就会使用自连接。
分析:
s_emp 表中 有普通员工 和 领导层的员工
领导 和 员工的 区别是 有没有人被他管
id manager_id
1 NULL
2 1
3 2
4 2
99 4
100 100
select id,manager_id from s_emp where id=manager_id;
当有一个人的manager_id 是你的 id 时 你就是领导
-- 25 - 8
select distinct m.id,m.first_name
from s_emp e,s_emp m where e.manager_id=m.id;
12.8.内连接: 符合连接条件的数据 被选中 不符合连接条件的数据被过滤掉。
等值连接
非等值连接
自连接
12.8.外连接
 外连接
外连接
12.8.1 特点
外连接的结果集 等于 内连接的结果集 加上 匹配不上的数据。
(一个也不能少)
12.8.2 如何实现?
(+) (+)字段所在的表的 对面 表的数据全部被选中
原来内连接中 被过滤的数据 是通过 NULL 记录进行的匹配
select distinct m.id,m.first_name
from s_emp e,s_emp m
where e.manager_id(+)= m.id and e.manager_id is null;
12.8.3 练习
显示 每个员工的first_name 和他对应的部门名
select first_name,name
from s_emp e,s_dept d
where e.dept_id = d.id;
由于公司发展的需要 需要对 id =10 的员工的 部门编号 设置成 NULL
update s_emp set dept_id = null where id = 10;
commit;
使用外连接技术 显示所有的员工的 first_name 和 对应的部门名 即使没有部门编号的员工也
要显示
select first_name,name
from s_emp e,s_dept d
where e.dept_id = d.id(+);
12.8.4 练习
显示每个部门的名字 和 对应的地区的名字
s_dept s_region
select d.name,r.name
from s_dept d,s_region r
where d.region_id = r.id;
公司的业务发展了 增加了新的部门
insert into s_dept values(100,'test100',NULL);
insert into s_dept values(101,'test101',NULL);
commit;
显示每个部门的名字 和 对应的地区的名字 没有地区编号的部门也要显示
select d.name,r.name
from s_dept d,s_region r
where d.region_id = r.id(+);
12.8.5显示每个员工的工资 和 对应的工资级别 s_emp salgrade
select salary,grade
from s_emp,salgrade
where salary between losal and hisal;
现在给 id <= 2 的人 涨工资 都涨成 12500
update s_emp set salary=12500 where id <=2;
commit;
显示每个员工的工资 和 对应的工资级别 超出统计范围的也要显示
select salary,grade
from s_emp,salgrade
where salary between losal(+) and hisal(+);
12.8.6 表连接
内连接:
等值连接 员工和部门 部门和地区
非等值连接 员工工资 和 工资级别
自连接 谁是领导
外连接:
等值连接 员工和部门 部门和地区
非等值连接 员工工资 和 工资级别
自连接 谁是普通员工
外连接的结果集 = 内连接的结果集 + 匹配不上的记录
(+) (+)字段所在的表 的 对面的表的数据全部被匹配出来
本质上 是靠 NULL 记录匹配出来的
13.SQL99中的内外连接
13.1 SQL99 中内连接
from a表 join b表 on 表的连接条件 where 过滤条件;
from a表 [inner] join b表 on 表的连接条件 where 过滤条件;
-- [] 代表里面的内容可以省略 写sql 千万别写上[]
显示每个部门的名字 和 对应的地区的名字 并且部门编号大于32 s_dept s_region
select d.name,r.name
from s_dept d,s_region r
where d.region_id = r.id and d.id > 32;
select d.name,r.name
from s_dept d join s_region r
on d.region_id = r.id where d.id > 32;
13.2 SQL99 的外连接
a表 left [outer] join b表 on 表的连接条件 where 过滤条件;
a表 right [outer] join b表 on 表的连接条件 where 过滤条件;
a表 full [outer] join b表 on 表的连接条件 where 过滤条件;
a表 left [outer] join b表 的意思就是 左边的表 发起连接,发起连接的意思
就是把表中所有的数据全部匹配出来。
数据同样是使用 NULL 记录进行匹配
显示所有的普通员工? 先写内连接找领导 改成 (+) 形式找到普通员工
最后改成left outer join
select distinct m.id,m.first_name
from s_emp e,s_emp m
where e.manager_id = m.id;
上面的sql 找出了 8 个领导 还剩下 25-8 = 17 普通员工
select distinct m.id,m.first_name
from s_emp e,s_emp m
where e.manager_id = m.id;
17 个普通员工
select distinct m.id,m.first_name
from s_emp e,s_emp m
where e.manager_id(+) = m.id and e.manager_id is null;
select distinct m.id,m.first_name
from s_emp m left outer join s_emp e
on e.manager_id = m.id where e.manager_id is null;
把上面的程序 改成 右外连接
select distinct m.id,m.first_name
from s_emp e right outer join s_emp m
on e.manager_id = m.id where e.manager_id is null;
全外连接: 它只是一个逻辑概念 全外连接的结果集 等于左外连接的结果集 加上 右外连接的结果集然后去除重复的记录。
oracle 中如何实现全外连接 它不是通过两端都加(+) 实现的, oracle 中是通过 合并结果集的方式
实现的。union 合并两个结果集 并排重, union all 合并两个结果集 不排重
select id from s_emp union select id from s_emp;
select id from s_emp union all select id from s_emp;
-----------------------------------------------------------------
综合练习:
显示每个员工的first_name 以及对应的部门名 还有 部门所在的地区名
dept_id 对应部门表的 id 部门表的region_id 对应地区表的 id
select e.first_name,d.name,r.name
from s_emp e,s_dept d,s_region r
where e.dept_id = d.id and d.region_id = r.id;
------------------------------------------------------------------------------------------------------
14.组函数
14.1 特点
对一组数据处理之后 只返回一个结果
无论sql影响多少行 只有一个结果
14.2 常见的组函数
count 统计数据的个数
max 统计一组数据的最大值
min 统计最小值
sum 统计和
avg 统计平均值
14.3 举例
select count(id),max(salary),min(salary) from s_emp;
统计s_emp 表中的 工资的和 以及 工资的平均值
select sum(salary),avg(salary) from s_emp;
14.4 特殊用法
select count(*) from s_emp;
select sum(distinct salary),avg(distinct salary) from s_emp;
14.5 NULL 值 组函数是如何处理的? 忽略
求提成的 平均值 提成的和 以及提成的最大值
select avg(commission_pct),sum(commission_pct),max(commission_pct)
from s_emp;
15.分组
 分组
分组
15.1 概念
按照一定的标准 把数据分成若干部分
15.2 语法
select 字段 from 表名 where 条件
group by 分组标准 having 组数据过滤条件 order by 排序标准;
15.3 练习
按照部门编号分组 统计每个部门的人数
select dept_id,count(id)
from s_emp group by dept_id;
where 条件 限制表中行数据返回的
having 条件 是对组数据进行过滤
按照部门编号分组 统计每个部门的人数 显示人数大于2 的组
select dept_id,count(id)
from s_emp group by dept_id having count(id) > 2;
15.4 练习
按照部门编号分组 统计 s_emp 表中的 平均工资 显示 平均大于 1200的部门
最终显示 部门编号 平均工资
select dept_id,avg(salary) from s_emp group by dept_id
having avg(salary) > 1200;
15.5 按照部门编号分组 统计每个部门的 人数 然后显示 部门的名字
select dept_id,count(s_emp.id),max(name)
from s_emp , s_dept
where dept_id = s_dept.id
group by dept_id;
select dept_id,count(s_emp.id),name
from s_emp , s_dept
where dept_id = s_dept.id
group by dept_id,name;
结论: 在分组语句中 select 后的字段 要么是分组标准 要么是经过合适的组函数处理过的
15.6 sql 语句中各个部分的执行顺序
select from where group by having order by
执行顺序: from where group by having select order by
select dept_id,avg(salary) asal from s_emp group by dept_id
having avg(salary) > 1200 order by asal;
16. 子查询
16.1 概念
把一个查询的结果 作为另一个查询的基础
16.2 举例
-- 查询所有的不重复的 领导对应的员工编号
select distinct manager_id from s_emp;
-- 查询所有的领导 8
select id,first_name from s_emp where id in ((select distinct manager_id from s_emp));
-- 查询所有的普通员工 25 - 8 注意NULL值
select id,first_name from s_emp where id not in
((select distinct manager_id from s_emp where manager_id is not null ));
16.3 查询工资大于 id=10 这个员工的对应的工资的员工
select id,salary from s_emp where salary > (select salary from s_emp where id=10);
16.4 子查询可以出现的位置
where 条件之后
having 条件之后
from之后
16.5 找出平均工资 比 42部门平均高的部门 显示部门编号 和 平均工资
先求出 42 部门的平均工资
select avg(salary) from s_emp where dept_id=42;
按照部门编号 分组 求每个部门的平均工资 然后过滤
select dept_id,avg(salary) from s_emp
group by dept_id
having avg(salary) >(select avg(salary) from s_emp where dept_id=42);
16.6 from 之后
任何合法select语句 都是一张内存表
select first_name name,salary from s_emp;
select name,salary from (select first_name name,salary from s_emp)
where salary > 1000;
17.DDL(data define language 数据定义语句)
17.1 create table 创建表
create table 表名(
字段名 类型,
字段名 类型,
字段名 类型
);
类型:
number 数字类型 (其它数据有自己的类型写法)
varchar(n) 字符串类型 变长字符串
char(n) 定长字符串
date 日期类型
练习:
建立一张订单表 myorder100 字段如下
id number oid char(30)
oname varchar(30) odate date
omoney number
create table myorder100(
id number,
oid char(30),
oname varchar(30),
odate date,
omoney number
);
17.2 删除表
drop table 表名;
drop table myorder100;
create table myorder100(
id number,
oid char(30),
oname varchar(30),
odate date,
omoney number
);
17.3 修改表 (了解 4)
删除表的字段
alter table 表名 drop column 字段名;
alter table myorder100 drop column omoney;
增加表的字段
alter table 表名 add 字段名 字段类型;
alter table myorder100 add omoney number;
18.DML (data manipulation language 数据操作语言)
18.1 insert 增加数据(插入数据)
-- 全字段插入
insert into 表名 values(值1,值2,值3);
insert into s_dept values(123,'test123',1);
commit;
如果有些字段值 不想写值 可以使用 NULL 但要求这些字段没有 not null 限制
insert into s_dept values(124,'test124',NULL);
commit;
insert into s_dept values(125,NULL,NULL); 这个地方报错 是因为第二个字段有非空限制
-- 选择部分字段插入 必须包含所有的非空字段
insert into 表名(字段名1,字段名3) values(值1,值3);
没有选择的字段值 默认是 NULL值
insert into myorder100(id,omoney) values(1,1);
commit;
insert into myorder100(id,odate) values(1,sysdate);
commit;
18.2 删除数据
delete from 表名 where 条件;
commit;
delete from myorder100 where id=1;
commit;
18.3 修改数据
update 表名 set 字段名=值1 where 条件;
update 表名 set 字段名=值1,字段名2=值2 where 条件;
commit;
练习:
把 s_emp 表中 id=10 first_name 改成 zhangsan 并且把 salary 改成 9999
update s_emp set first_name='zhangsan',salary=9999 where id = 10;
commit;
19.TCL(transaction control language) 事务控制语句
19.1 事务的概念
需要把多条sql操作 看成一个整体,这些语句要求一起成功 或者 一起失败。
银行转账:
update account_zs set money=money-49999 where id='62551181181110';
update account_zs set money=money+49999 where id='62551181181199';
19.2 事务的 特性
原子性 : 事务中的语句 要求一起成功 或者 一起失败
一致性: 语句的操作 保持一致
隔离性: 一个事务进行DML 操作 没有提交之前对另外事务而言数据的变化 不可见
这里我们称之为 隔离性。
持久性: 要一直保持
19.3 如何结束一个事务
commit; 确认 提交 把数据写入磁盘
rollback; 回退 撤销之前的DML操作
19.4 保存点 savepoint (了解)
可以做到 部分成功 部分失败
insert into myorder100(id,odate) values(1,sysdate);
savepoint a;
insert into myorder100(id,odate) values(2,sysdate);
savepoint b;
insert into myorder100(id,odate) values(3,sysdate);
rollback to b;
commit;
20.日期类型
20.1 默认的机制
oracle 中无论插入数据 还是显示数据 默认的日期格式 是 DD-MON-YY
20.2 改变默认的显示
to_char(par1,par2)
par1 可以是日期类型的数据
par2 变成日期格式字符串
yyyy 四位年
MM 二位月
dd 二位天
hh 12小时制
hh24 24小时制
mi 分钟
ss 秒
day 星期几
month 月的全写
mon 月的缩写
am 上午显示 am 下午 pm
select id,odate,to_char(odate,'yyyy-mm-dd hh24:mi:ss day') from myorder100;
20.3 按照入职日期排序 显示 每个员工的 id first_name start_date
select id,first_name,start_date
from s_emp order by start_date;
select id,first_name,to_char(start_date,'yyyy-mm-dd hh24:mi:ss day') rdate
from s_emp order by start_date;
20.4 如何插入日期?
sysdate 插入当前系统日期
2008-08-08
insert into myorder100(id,odate) values(3,'08-AUG-2008');
commit;
只能插入 年 月 日 默认的时分秒 全是 零
select id,odate,to_char(odate,'yyyy-mm-dd hh24:mi:ss day') from myorder100;
to_date(par1,par2)
par1 日期字符串
par2 根据日期指定的日期格式 日期格式和to_char 中一样
2317-05-22 06:10:08
insert into myorder100(id,odate) values(4,to_date('2317-05-22 06:10:08',
'yyyy-mm-dd hh24:mi:ss'));
commit;
20.5 日期调整
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
-- 默认 按照天为单位加
select to_char(sysdate+1,'yyyy-mm-dd hh24:mi:ss') from dual;
调整 一个小时
select to_char(sysdate+1/24,'yyyy-mm-dd hh24:mi:ss') from dual;
调整 一分钟
select to_char(sysdate+1/(24*60),'yyyy-mm-dd hh24:mi:ss') from dual;
调整 十 分钟
select to_char(sysdate+10/(24*60),'yyyy-mm-dd hh24:mi:ss') from dual;
调整 一个月 add_months
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(add_months(sysdate,1),'yyyy-mm-dd hh24:mi:ss') from dual;
想获取 本月对应的订单
trunc(par1,par2)
par1 是一个日期
par2 截取的单位 默认是天
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(trunc(sysdate),
'yyyy-mm-dd hh24:mi:ss') from dual;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(trunc(sysdate,'mm'),
'yyyy-mm-dd hh24:mi:ss') from dual;
20.6 查询 1991 年 1 月 到 6 月底 入职的员工有哪些
select id,first_name,to_char(start_date,'yyyy-mm-dd hh24:mi:ss') hdate
from s_emp order by hdate;
select id,first_name,to_char(start_date,'yyyy-mm-dd hh24:mi:ss') hdate from s_emp
where start_date >= to_date('1991-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')
and start_date < to_date('1991-07-01 00:00:00','yyyy-mm-dd hh24:mi:ss') ;
select id,first_name,to_char(start_date,'yyyy-mm-dd hh24:mi:ss') hdate from s_emp
where start_date >= to_date('1991-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')
and start_date < add_months(trunc(to_date('1991-01-10 00:00:00','yyyy-mm-dd hh24:mi:ss'),'mm') ,6);
20.7 给你一个时间 求出这个时间对应的月的开始 和 月的结束
sysdate
trunc(sysdate,'mm') 5月1日 零点零分零秒
add_months(trunc(sysdate,'mm'),1) 6月1日 零点零分零秒
21.约束 constraint
21.1 约束
约束 是在数据库层面 对数据进行验证,满足约束 才能进入数据库,不满足约束条件
则被拦截在数据库之外。
21.2 数据库中约束的种类
主键约束:如果对数据库表的一个字段 加了主键约束 则这个字段不能为NULL值,并且字段的值
不能重复。并且一张表只能有一个主键。 primary key pk
唯一性约束:如果对表 中某个字段加了唯一性限制 则 这个字段的值不能重复。 unique uk
非空约束: 字段的值不能是NULL值。 not null nn
检查约束:加了检查约束的字段 字段的值必须符合检查条件 否则报错。 check ck
外键约束: 讲完了上面四个约束再说
21.3 约束的实现方式
列级约束: 在定义表的某一列时,直接在这一列的后面加约束限制 叫列级约束。
表级约束: 在定义完表的所有列之后 再选择某些列加约束限制 叫表级约束。
21.4主键的列级约束实现
drop table student;
create table student(
id number primary key,
name varchar2(30)
);
insert into student values(1,'messi');
ORA-00001: unique constraint (SYSTEM.SYS_C007582) violated
如果不给系统的约束起名字,则数据库管理系统 会自动为约束命名一个不重复的系统约束名.
这个约束不方便我们以后的调试 和 维护。
21.5 给约束起名字
字段名 类型 constraint 约束名 约束关键字
约束名的构成是:表名_字段名_约束关键字简写
drop table student;
create table student(
id number constraint student_id_pk primary key,
name varchar2(30)
);
insert into student values(1,'messi');
21.6建立一张表格 叫 student201709
id number 主键
fname varchar2(30) 唯一
sname varchar2(30) 非空
要求给这三个约束起名字 命名规范是 表名_字段名_约束简写
create table student201709(
id number constraint student201709_id_pk primary key,
fname varchar2(30) constraint student201709_fname_uk unique,
sname varchar2(30) constraint student201709_sname_nn not null
);
21.7 check 约束
在上面的 基础加一个字段 叫salary 要求工资大于3500
drop table student201709;
create table student201709(
id number constraint student201709_id_pk primary key,
fname varchar2(30) constraint student201709_fname_uk unique,
sname varchar2(30) constraint student201709_sname_nn not null,
salary number constraint student201709_salary_ck check(salary>3500)
);
insert into student201709 values(1,'ea','eb',3500);
21.8 主键的表级约束
drop table student201709;
create table student201709(
id number ,
fname varchar2(30),
sname varchar2(30),
salary number, constraint student201709_id_pk primary key(id)
);
表级约束最大的优势 就是可以做联合约束
而 not null 没有联合非空的需求 导致 底层不支持联合非空 所以 not null 没有表级约束
create table student201709(
id number constraint student201709_id_pk primary key,
fname varchar2(30) constraint student201709_fname_uk unique,
sname varchar2(30) constraint student201709_sname_nn not null,
salary number constraint student201709_salary_ck check(salary>3500)
);
把上面的建表语句 改成 表级约束 除了 not null
21.9 建立一张订单表 jdorder 字段如下
id number 主键
oname varchar2(30) unique
omoney number
odate date
要求建表之前 先删除表
要求给约束 按照 表名_字段名_约束简写 起名字
要求插入数据 如下 1 jd00001 1000 sysdate
要求提交数据
再次插入一条数据 代表 订单补录
2 jd00002 800 '2017-05-21 18:06:09'
提交数据
最后把1 号订单的 钱数 改成 11000.95 提交数据
21.10.练习
drop table student201709;
create table student201709(
id number ,
fname varchar2(30),
sname varchar2(30),
salary number, constraint student201709_id_pk primary key(id)
);
表级约束最大的优势 就是可以做联合约束
而 not null 没有联合非空的需求 导致 底层不支持联合非空 所以 not null 没有表级约束
create table student201709(
id number constraint student201709_id_pk primary key,
fname varchar2(30) constraint student201709_fname_uk unique,
sname varchar2(30) constraint student201709_sname_nn not null,
salary number constraint student201709_salary_ck check(salary>3500)
);
把上面的建表语句 改成 表级约束 除了 not null
drop table student201709;
create table student201709(
id number ,
fname varchar2(30) ,
sname varchar2(30) constraint student201709_sname_nn not null,
salary number ,
constraint student201709_id_pk primary key(id),constraint student201709_fname_uk unique(fname),constraint student201709_salary_ck check(salary>3500)
);
22.外键约束
22.1 概念
外键约束 涉及到两张表 一张叫父表(主表) 一张叫子表(从表)
子表:定义了外键字段的表 叫 子表
外键字段的取值 受限于父表字段中的取,外键字段的值 要么取NULL值 要么取父表字段对应的值。
22.2 实现
(1.) 建表
先建父表 后建子表 除非你先不考虑主外键关系
create table parent09(
id number constraint parent09_id_pk primary key,
name varchar2(30)
);
create table child09(
id number constraint child09_id_pk primary key,
name varchar2(30),
fid number references parent09(id)
);
(2.) 插入数据
先插入父表数据 后插入子表数据 除非子表的外键字段取值为NULL
insert into child09 values(1,'c1',NULL);
commit;
insert into parent09 values(1,'p1');
insert into child09 values(2,'c2',1);
commit;
insert into parent09 values(2,'p2');
commit;
(3.) 删除数据
先删子表数据 后删父表数据 除非使用级联
delete from parent09 where id=1;
delete from parent09 where id=2;
(4.) 删除表
先删子表 后删父表 除非使用 cascade constraints
drop table parent09;
ORA-02449: unique/primary keys in table referenced by foreign keys
先断开主外键关系 然后删除表(可以不考虑删表的顺序)
drop table parent09 cascade constraints;
22.3 练习
建表之前 先删除表
建立一张 部门表 mydept 还有一张员工表 myemp
id numbe 主键 id number 主键
name varchar2(30) name varchar2(30)
salary number
dept_id number 外键
部门表中插入 两条数据 1 test1 2 test2
员工表中 插入 五条数据 1 ea 10000 1 2 eb 12000 1
3 ec 13000 1 4 ed 22000 2 5 ee 28000 2
提交数据
drop table mydept cascade constraints;
drop table myemp cascade constraints;
create table mydept(
id number constraint mydept_id_pk primary key,
name varchar2(30)
);
insert into mydept values(1,'test1');
insert into mydept values(2,'test2');
commit;
create table myemp(
id number constraint myemp_id_pk primary key,
name varchar2(30),
salary number,
dept_id number constraint myemp_dept_id_fk references mydept(id)
);
insert into myemp values(1,'ea',10000,1);
insert into myemp values(2,'eb',12000,1);
insert into myemp values(3,'ec',13000,1);
insert into myemp values(4,'ed',22000,2);
insert into myemp values(5,'ee',28000,2);
commit;
22.4 级联 (外键上设置 )
on delete cascade 级联删除 把关联子表数据自动删除
on delete set null 级联置空 把关联子表数据的外键设置成NULL
drop table mydept cascade constraints;
drop table myemp cascade constraints;
create table mydept(
id number constraint mydept_id_pk primary key,
name varchar2(30)
);
insert into mydept values(1,'test1');
insert into mydept values(2,'test2');
commit;
create table myemp(
id number constraint myemp_id_pk primary key,
name varchar2(30),
salary number,
dept_id number constraint myemp_dept_id_fk references mydept(id) on delete cascade
);
insert into myemp values(1,'ea',10000,1);
insert into myemp values(2,'eb',12000,1);
insert into myemp values(3,'ec',13000,1);
insert into myemp values(4,'ed',22000,2);
insert into myemp values(5,'ee',28000,2);
commit;
22.5 外键的表级约束
drop table myemp;
create table myemp(
id number constraint myemp_id_pk primary key,
name varchar2(30),
salary number,
dept_id number, constraint myemp_dept_id_fk foreign key(dept_id)
references mydept(id) on delete cascade
);
22.6 先建表 后加约束
drop table mydept cascade constraints;
create table mydept(
id number,
name varchar2(30)
);
alter table mydept add constraint mydept_id_pk primary key(id);
23.数据库中的其它对象
23.1 序列 sequence
23.1.1 作用
用来控制 表中的主键值的对象
23.1.2 语法
create sequence 序列名;
在需要主键值的地方 使用 序列名.nextval 来获取一个不重复的主键值
偶尔用到 序列名.currval
23.1.3 举例
drop table testseq cascade constraints;
create table testseq(
id number constraint testseq_id_pk primary key,
name varchar2(30)
);
create sequence testseq_id_seq;
insert into testseq values(testseq_id_seq.nextval,'test'||testseq_id_seq.currval);
23.2 索引 index
23.2.1 作用
是通过消耗大量的空间 和 时间 来达到加速查询的目的
3亿条 不使用索引 10分钟
索引 0.01s
3.2.2 语法
create index 索引名 on 表名(字段名);
注意主键 和 唯一性字段上 不能加索引 因为系统已经自动建立了索引
23.2.3 删除索引
drop index 索引名;
23.3 视图
23.3.1 什么是视图
视图本质上 就是一条sql 语句 相对于sql对应的数据 视图的本身的空间可以忽略
23.3.2 语法
create or replace view 视图名 as 查询语句;
create or replace view myview as select id,first_name name,salary
from s_emp;
23.3.3 作用
可以对同一份物理数据 作出不同的表现
可以用来控制权限
可以简化子查询
24. 分页
oracle 中 使用 rownum
mysql 中使用 limit m,n
select id,first_name,salary from s_emp;
select rownum,first_name,salary from s_emp;
rownum 在表中没有 但是可以使用 我们称之为 伪列
select rownum,first_name,salary from s_emp where rownum < 12;
一页显示 11 条 取第二页数据
select rownum,first_name,salary from s_emp where rownum < 23 and
rownum > 11;//错
select r,first_name,salary from (select rownum r,first_name,salary
from s_emp where rownum < 23) where r > 11;
按照工资排序 一页显示11 条数据 显示s_emp 表中的第二页数据 显示 rownum
first_name salary
select rownum,first_name,salary from s_emp order by salary;
先排序 后编号
select r,first_name,salary from (select rownum r,first_name,salary from (select first_name,salary from s_emp order by salary)where rownum < 23) where r>11;
最内层:负责排序
中间层:负责编号 和 起别名 以及部分过滤
最外层:使用别名进行过滤
按照工资排序 一页显示11 条数据 显示s_emp 表中的第三页数据 显示 rownum
first_name salary
select r,first_name,salary from (select rownum r,first_name,salary from (select first_name,salary from s_emp order by salary) where rownum < 3*11 +1)
where r > (3-1)*11;
select r,first_name,salary from (select rownum r,first_name,salary from (select first_name,salary from s_emp order by salary) where rownum < 2*11 +1)
where r > (2-1)*11;
25.什么是三范式 (补充)
第一范式:数据库中表的字段不可再分
第二范式:要求数据表中的数据 可以被唯一区分 一般表要有主键
第三范式:在满足第二范式的基础上 消除了传递依赖 传递依赖的意思 是所有的字段依赖
于主键 而不依赖于其它候选键字段。
26.表设计
eid ename eage did
1 ea 20 1
2 eb 21 1
3 ec 24 1
4 ed 22 2
5 ee 25 2
6 ef 36 3
did dname dloc
1 test1 loc1
2 test2 loc2
3 test3 loc3
27.表设计的练习 学生 和 课程
sid sname sage cid cname cscore
1 s1 20 1 java 120
1 s1 20 2 c++ 100
2 s2 20 1 java 120
学生课程关系表
id sid cid
1 1 1
2 1 2
3 1 3
4 2 1
5 2 3
课程表
cid cname cscore
1 java 120
2 c++ 100
3 UI 110
学生表
sid sname sage
1 s1 20
2 s2 22
PLSQL
28.简介
28.1 常见访问数据库的技术
jdbc 使用java 访问数据库的技术
PLSQL (procedure 过程化sql) 在数据库内部操作数据的技术
proc/c++ c 和 c++ 访问数据库的技术
ODBC 微软提供访问数据库的技术
OCI oracle 底层的连接接口
28.2.PLSQL 扩展了SQL
变量 和 类型
控制 结构
过程 和 函数
对象 和 方法
28.3.PLSQL程序结构
declare
/* 申明区
用来定义类型 或者 定义变量的 */
begin
/* 执行区
用来执行sql 语句 或者 PLSQL语句 */
exception
/* 异常处理区
一旦有异常发生 就自动进入这个区 处理 */
end;
28.4.PLSQL 的开发环境
命令行的 sqlplus
图形化开发工具 sqldeveloper
plsqldeveloper
28.5.第一个PLSQL程序
begin
dbms_output.put_line('hello plsql');
end;
/
需要设置服务端的输出为打开状态
set serveroutput on;
修改计算机的名字 重启机器
C:\oraclexe\app\oracle\product\11.2.0\server\network\ADMIN
28.6.标识符
用来给 变量 类型 函数 等命名的
不能超过 31 字符
不能是关键字
28.7.注释
-- 这叫单行注释
/* 这叫多行注释 */
28.8.变量
28.8.1 语法
declare
变量名 类型;
begin
类型:sql 中的类型 (number varchar2(n) char(n) date )
boolean binary_integer
复合:record类型 table类型 cursor类型 游标
参考类型: ref
大数据类型:BLOB CLOB (一般不用 数据库表中只存储这些数据的路径即可)
28.8.2 定义一个变量 用来存储整数 打印这个变量的值
declare
var_i number;
begin
dbms_output.put_line('var_i'||var_i);
end;
/
注意:一个变量 如果不赋值 则值为 NULL
28.8.3 变量的修饰
declare
var_i constant number:=5;
begin
-- var_i:=1001;
dbms_output.put_line('var_i='||var_i);
end;
/
注意:constant 修饰的变量 必须赋初值 赋值 使用 := 并且不能修改
还有一个修饰 叫 not null 修饰 要求变量必须赋值
declare
var_i number not null:=5;
begin
var_i:=1001;
dbms_output.put_line('var_i='||var_i);
end;
/
28.8.4 定义一个变量 要求非空修饰 这个变量的类型 要和 s_emp 表中的first_name 保持一致
给这个变量赋值 test 然后打印。
declare
var_name varchar2(25) not null :='test';
begin
dbms_output.put_line(var_name);
end;
/
28.8.5 可以通过 表名.字段名%type 来获取表中的字段对应的类型
declare
var_name s_emp.first_name%type not null :='test';
begin
dbms_output.put_line(var_name);
end;
/
28.8.6 record 类型 把多个类型 组织到一起的一个类型
declare
/* 定义一个record 类型 包装 s_emp 表中的 id first_name salary */
type emptype is record(
id s_emp.id%type,
name s_emp.first_name%type,
salary s_emp.salary%type
);
/* 使用 emptype 定义一个变量 */
var_emp emptype;
begin
var_emp.id := 100;
var_emp.name:='test';
var_emp.salary:=12345;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
end;
/
declare
/* 定义一个record 类型 包装 s_emp 表中的 id first_name salary */
type emptype is record(
id s_emp.id%type,
name s_emp.first_name%type,
salary s_emp.salary%type
);
/* 使用 emptype 定义一个变量 */
var_emp emptype;
begin
select id,first_name,salary into var_emp from s_emp where id=10;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
end;
/
28.8.7 定义一个record 类型 这个类型要包装 s_dept表中的所有的字段
然后使用record 类型 定义一个变量 使用 select语句 给这个变量 赋值 成 id =50
的数据 然后 打印这个变量对应的值。
declare
type depttype is record(
id s_dept.id%type,
name s_dept.name%type,
rid s_dept.region_id%type
);
var_dept depttype;
begin
select * into var_dept from s_dept where id=50;
dbms_output.put_line(var_dept.id||':'||var_dept.name);
end;
/
28.8.8 定义一个record 类型 这个类型要包装 s_emp表中的所有的字段
然后使用record 类型 定义一个变量 使用 select语句 给这个变量 赋值 成 id =5
的数据 然后 打印这个变量对应的值。
可以使用 表名%rowtype 直接获取表的一行对应的类型 实际上获取就是字段名 和 字段顺序 和
表保持一致的类型。
declare
var_emp s_emp%rowtype;
begin
select * into var_emp from s_emp where id = 5;
dbms_output.put_line(var_emp.id||':'||var_emp.first_name);
end;
/
28.8.9 table 类型 类似于java中的 map
语法: 定义一个table 类型
type table类型名 is table of 元素类型名 index by binary_integer;
如何定义变量:
变量名 table类型名;
如何访问:
变量名(key)
变量名(key):=值;
练习:
定义一个table类型 用来存储number类型的数据 然后table类型定义一个变量
分别把 9 5 2 7 0 存入这个变量中 然后 打印下标为 3 的对应的值。
declare
type numstype is table of number index by binary_integer;
var_nums numstype;
begin
var_nums(0):=9;
var_nums(1):=5;
var_nums(2):=2;
var_nums(3):=7;
var_nums(4):=0;
dbms_output.put_line(var_nums(3));
end;
/
下标连续时 遍历table类型的变量
declare
type numstype is table of number index by binary_integer;
var_nums numstype;
var_index binary_integer:=0;
begin
var_nums(0):=9;
var_nums(1):=5;
var_nums(2):=2;
var_nums(3):=7;
var_nums(4):=0;
dbms_output.put_line(var_nums(var_index));
var_index:=var_index+1;
dbms_output.put_line(var_nums(var_index));
var_index:=var_index+1;
dbms_output.put_line(var_nums(var_index));
var_index:=var_index+1;
dbms_output.put_line(var_nums(var_index));
var_index:=var_index+1;
dbms_output.put_line(var_nums(var_index));
end;
/
下标不连续时 遍历table类型的变量
迭代思想:
变量名.first() 获取第一个元素对应的下标 (元素对应的最小下标)
变量名.next(n) 根据一个元素的下标n 得到下一个元素对应的下标
变量名.last() 获取最后一个元素对应的下标
declare
type numstype is table of number index by binary_integer;
var_nums numstype;
var_index binary_integer:=0;
begin
var_nums(0):=9;
var_nums(1):=5;
var_nums(-12):=2;
var_nums(3):=7;
var_nums(4):=0;
var_index := var_nums.first();
dbms_output.put_line(var_nums(var_index));
var_index:= var_nums.next(var_index);
dbms_output.put_line(var_nums(var_index));
var_index:= var_nums.next(var_index);
dbms_output.put_line(var_nums(var_index));
var_index:= var_nums.next(var_index);
dbms_output.put_line(var_nums(var_index));
var_index:= var_nums.next(var_index);
dbms_output.put_line(var_nums(var_index));
end;
/
28.8.10 变量的作用域 和 可见性
declare
var_x number := 100;
begin
declare
var_y number := 99;
begin
end;
end;
局部可以访问全局 全局不能访问局部
当局部和全局冲突时 可以使用标签解决
<
declare
var_x number := 100;
begin
declare
var_x number := 99;
begin
dbms_output.put_line(var_x);
dbms_output.put_line(outerblock.var_x);
end;
end;
/
28.9.控制语句
28.9.1 分支语句
28.9.1.1 语法
java PLSQL
if(a>b){ if a > b then
} end if;
if(a>b){ if a > b then
}else{ else
} end if;
if(a>b) { if a > b then
}else if(a>c){ elsif a > c then
} end if;
if(a>b) { if a > b then
}else if(a>c){ elsif a > c then
}else if(a>d){ elsif a > d then
}else{ else
} end if;
28.9.1.2 练习
定义两个整数变量 赋值 并打印这两个变量的最大值
declare
var_x number;
var_y number;
begin
/* & 的意思代表从键盘录入数据 */
var_x := &var_x;
var_y := &var_y;
dbms_output.put_line(var_x||':'||var_y);
if var_x < var_y then
dbms_output.put_line(var_y);
else
dbms_output.put_line(var_x);
end if;
end;
/
28.9.1.3 NULL值的判断
declare
var_x number;
var_y number;
begin
if var_x > var_y then
dbms_output.put_line('var_x > var_y');
elsif var_x is null and var_y is null then
dbms_output.put_line('var_x is null and var_y is null');
elsif var_x < var_y then
dbms_output.put_line('var_x < var_y');
elsif var_x = var_y then
dbms_output.put_line('var_x = var_y');
else
dbms_output.put_line('why?why?why?');
end if;
end;
/
28.9.1.4 定义三个整数变量 从键盘录入值 然后打印这三个变量的最大值
declare
var_x number;
var_y number;
var_z number;
begin
var_x:=&var_x;
var_y:=&var_y;
var_z:=&var_z;
if var_x < var_y then
if var_y < var_z then
else
end if;
else
if var_x < var_z then
else
end if;
end if;
end;
declare
var_x number;
var_y number;
var_z number;
var_max number;
begin
var_x:=&var_x;
var_y:=&var_y;
var_z:=&var_z;
var_max := var_x;
if var_max < var_y then
var_max:=var_y;
end if;
if var_max < var_z then
var_max:=var_z;
end if;
dbms_output.put_line(var_max);
end;
/
28.10 循环语句
28.10.1 语法
简单循环
loop
/* 循环代码 */
end loop;
428.10.2 如何结束循环
exit when 退出循环的条件;
if 退出条件 then
exit;
end if;
28.10.3 练习
定义一个变量 把这个变量的值 从 1 输出 到 10
declare
var_i number:=1;
begin
loop
dbms_output.put_line(var_i);
exit when var_i=10;
var_i:=var_i+1;
end loop;
end;
/
declare
var_i number:=1;
begin
loop
dbms_output.put_line(var_i);
if var_i=10 then
exit;
end if;
var_i:=var_i+1;
end loop;
end;
/
28.10.4 while 循环
语法:
while 循环条件 loop
/* 循环代码 */
end loop;
练习:
使用while 循环 把一个变量的值 从1 输出 到 10
declare
var_i number:=1;
begin
while var_i < 11 loop
dbms_output.put_line(var_i);
var_i:=var_i+1;
end loop;
end;
/
使用while 循环 把一个变量的值 从10 输出 到 1
declare
var_i number:=10;
begin
while var_i > 0 loop
dbms_output.put_line(var_i);
var_i:=var_i-1;
end loop;
end;
/
28.10.5 for 循环 智能循环
语法: 目前可以把 a..b 理解成一个整数区间
for 变量 in a..b loop
/* 循环代码 */
end loop;
练习:把一个变量的值 从 1 输出 到 10
begin
for i in 1..10 loop
dbms_output.put_line(i);
-- i:=11;
end loop;
end;
/
for 循环中定义的变量 只能读 不能写
思考 如何从10 输出 到 1 ?
begin
for i in 1..10 loop
dbms_output.put_line(11-i);
end loop;
end;
/
begin
for i in reverse 1..10 loop
dbms_output.put_line(i);
end loop;
end;
/
28.10.6 多重循环的退出问题
declare
var_i number;
var_j number;
begin
var_i := 1;
while var_i < 4 loop
var_j:=1;
while var_j < 4 loop
dbms_output.put_line(var_j);
if var_j = 2 then
exit;
end if;
var_j:=var_j+1;
end loop;
var_i:=var_i+1;
end loop;
end;
/
思考 如何 满足上面条件的情况下 结束外层循环 现在结束的是内层循环
declare
var_i number;
var_j number;
begin
var_i := 1;
while var_i < 4 loop
var_j:=1;
while var_j < 4 loop
dbms_output.put_line(var_j);
if var_j = 2 then
var_i:=4;
exit;
end if;
var_j:=var_j+1;
end loop;
var_i:=var_i+1;
dbms_output.put_line('hehe');
end loop;
end;
/
declare
var_i number;
var_j number;
begin
var_i := 1;
<
while var_i < 4 loop
var_j:=1;
while var_j < 4 loop
dbms_output.put_line(var_j);
if var_j = 2 then
exit outerloop;
end if;
var_j:=var_j+1;
end loop;
var_i:=var_i+1;
dbms_output.put_line('hehe');
end loop;
end;
/
28.11. 控制语句 ----- goto 语句
28.11.1 语法
goto 标签名; <<标签名>>
28.11.2 使用goto 做个循环
declare
var_i number;
begin
var_i:=1;
<
if var_i < 10 then
dbms_output.put_line(var_i);
var_i:=var_i+1;
goto myloop;
end if;
end;
/
28.13.3 使用goto 退出多重循环
begin
<
for var_x in 1..3 loop
for var_y in 1..3 loop
dbms_output.put_line(var_y);
if var_y = 2 then
exit outerloop;
end if;
end loop;
end loop;
end;
/
begin
for var_x in 1..3 loop
for var_y in 1..3 loop
dbms_output.put_line(var_y);
if var_y = 2 then
goto outerloop;
end if;
end loop;
end loop;
<
/* 这句的意思是 空语句 */
NULL;
end;
/
-----------------------------------------------------------------------------------------------------
declare
type numstype is table of number index by binary_integer;
var_nums numstype;
var_index binary_integer:=0;
begin
var_nums(0):=9;
var_nums(1):=5;
var_nums(-12):=2;
var_nums(3):=7;
var_nums(4):=0;
-- var_nums.count();
var_index := var_nums.first();
loop
dbms_output.put_line(var_nums(var_index));
var_index:=var_nums.next(var_index);
if var_index = var_nums.last() then
dbms_output.put_line(var_nums(var_index));
exit;
end if;
end loop;
end;
/
----------------------------------------------------------------------------------------------
29.游标 cursor
29.1 概念
游标是存放多条数据的一个结果集(ResultSet)。
29.2 游标的使用步骤 (非滚动游标 ----- 只能顺序访问)
声明游标
declare
cursor 游标名 is select语句;
begin
打开游标
open 游标名;
提取数据 操作数据
fetch 游标名 into 变量;
关闭游标
close 游标名;
29.3 定义一个游标 用来存放s_emp 表中的 id first_name salary
然后提取游标的前两条数据 打印这两条数据 最后关闭游标
declare
cursor empcursor is select id,first_name name,salary from s_emp;
type emptype is record(
id s_emp.id%type,
name s_emp.first_name%type,
salary s_emp.salary%type
);
var_emp emptype;
begin
open empcursor;
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
close empcursor;
end;
/
使用 游标名%rowtype 来获取游标中的一行对应的类型
declare
cursor empcursor is select id,first_name name,salary from s_emp;
var_emp empcursor % rowtype;
begin
open empcursor;
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.name||':'||var_emp.salary);
close empcursor;
end;
/
29.4 写一个游标 用来存储 s_dpet 中的 id 和 name 以及 s_region 表中的 name
然后提取前两条数据 并打印 最后 关闭游标。
declare
cursor deptregioncursor is select d.name dname,r.name rname
from s_dept d,s_region r where d.region_id = r.id;
var_dr deptregioncursor % rowtype;
begin
open deptregioncursor;
fetch deptregioncursor into var_dr;
dbms_output.put_line(var_dr.dname ||':'||var_dr.rname);
fetch deptregioncursor into var_dr;
dbms_output.put_line(var_dr.dname ||':'||var_dr.rname);
close deptregioncursor;
end;
/
29.5.写一个游标 用来存放 s_emp 表中所有的 id first_name salary
并提取前两条数据 打印。
declare
cursor empcursor is select id,first_name,salary from s_emp;
var_emp empcursor % rowtype;
begin
open empcursor;
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
fetch empcursor into var_emp;
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
close empcursor;
end;
/
29.6.使用游标属性
游标名%FOUND 如果游标提取到了新数据 则返回TRUE 如果没有提取到新数据 则返回FALSE。
但这个属性使用有两个前提 第一游标必须处于打开状态 否则 出现非法游标的操作,第二游标必须
FETCH 否则 返回 NULL。
游标名%NOTFOUND 如果游标提取到了新数据 则返回FALSE 如果没有提取到新数据 则返回TRUE。 但这个属性使用有两个前提 第一游标必须处于打开状态 否则 出现非法游标的操作,第二游标必须 FETCH 否则 返回 NULL。
declare
cursor empcursor is select id,first_name,salary from s_emp;
var_emp empcursor % rowtype;
begin
open empcursor;
LOOP
fetch empcursor into var_emp;
/* 如果没有提取到 新数据 则结束循环 */
EXIT WHEN EMPCURSOR%NOTFOUND;
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
END LOOP;
close empcursor;
end;
/
把上面的程序 改成while 循环 结合FOUND 属性 遍历游标
declare
cursor empcursor is select id,first_name,salary from s_emp;
var_emp empcursor % rowtype;
begin
open empcursor;
fetch empcursor into var_emp;
WHILE EMPCURSOR%FOUND LOOP
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
fetch empcursor into var_emp;
END LOOP;
close empcursor;
end;
/
29.7.游标的其它属性
游标名 % ISOPEN 6 判断游标是否处于打开状态 打开就返回TRUE 否则返回FALSE.
注意打开的游标不能再打开 关闭的游标不能再关闭。否则报错。
游标名 % ROWCOUNT 1 游标指针偏移量
29.8.智能循环 遍历游标
智能循环 会自动定义变量 自动打开游标 自动提取数据 自动关闭游标
declare
cursor empcursor is select id,first_name,salary from s_emp;
begin
FOR VAR_EMP IN EMPCURSOR LOOP
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
END LOOP;
end;
/
29.9.带参游标
一个游标在定义时 可以设计参数,并且参数可以直接在游标对应的select语句中使用。
参数的类型 不能加长度修饰 但 可以使用%type。
打开游标时 传入对应的参数值。
declare
cursor empcursor(var_id number) is select id,first_name,salary from s_emp
where id>var_id;
var_emp empcursor % rowtype;
begin
open empcursor(20);
LOOP
fetch empcursor into var_emp;
/* 如果没有提取到 新数据 则结束循环 */
EXIT WHEN EMPCURSOR%NOTFOUND;
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
END LOOP;
close empcursor;
end;
/
declare
cursor empcursor(var_id number) is select id,first_name,salary from s_emp
where id>var_id;
begin
FOR VAR_EMP IN empcursor(20) LOOP
dbms_output.put_line(var_emp.id||':'||var_emp.first_name||':'||var_emp.salary);
END LOOP;
end;
/
29.10.参考游标 ref cursor
29.10.1 概念
参考游标的意思是 游标对应的sql语句 可以在程序执行的过程中发生改变 直到打开游标时
确定对应的sql语句。
只要把sql 语句变成字符串
29.10.2 使用步骤
定义一个参考游标类型
type 参考游标类型名 is ref cursor;
使用这个类型 定义一个游标变量
游标变量 参考游标类型名;
打开游标时 关联一个动态拼接好的字符串
open 游标变量 for sqlstr;
29.10.3 举例
declare
type myrefcursor is ref cursor;
refempcursor myrefcursor;
/* 为这个参考游标 定义一个动态字符串 */
sqlstr varchar2(200);
var_id number:=10;
type emptype is record(
id s_emp.id%type,
salary s_emp.salary % type,
dept_id s_emp.dept_id%type
);
var_emp emptype;
begin
sqlstr := 'select id,salary,dept_id from s_emp';
if var_id != 0 then
sqlstr := sqlstr ||' where id >' || var_id;
end if;
open refempcursor for sqlstr;
loop
fetch refempcursor into var_emp;
exit when refempcursor%notfound;
dbms_output.put_line(var_emp.id||':'||var_emp.salary||':'||var_emp.dept_id);
end loop;
close refempcursor;
end;
/
28.11.异常
28.11.1 PLSLQ中的异常
编译时 异常 --------语法错误
运行时异常
28.11.2 举例
declare
var_name s_emp.first_name%type;
begin
select first_name into var_name from s_emp where id=111;
dbms_output.put_line(var_name);
end;
/
others 代表 所有的异常
declare
var_name s_emp.first_name%type;
begin
select first_name into var_name from s_emp where id<111;
dbms_output.put_line(var_name);
exception
when no_data_found then
dbms_output.put_line('no emp found');
when too_many_rows then
dbms_output.put_line('too many emp found');
when others then
dbms_output.put_line('have exception');
end;
/
在plsql执行代码 中 判断语句可能会出那些异常 就在 Exception 中 进行相应
的when 捕获异常进行处理即可。
28.11.3 自定义异常的使用步骤
1.根据系统的需求 定义出相应的异常 异常是有层次结构的
2.抛出异常
根据相应的条件 抛出对应的异常
3.捕获异常
4.处理异常
能处理 就可以去处理一下
不能处理 就继续抛出
29.过程
29.1 过程的概念
把一组逻辑相关的 sql语句 和 plsql语句 组织到一起的一个逻辑结构 称之为过程。
29.2 语法
create or replace procedure 过程名(参数列表)
is
/* 申明区 */
begin
end;
/
29.3 举例
先写一个匿名块 定义两个整数变量 打印最大值
declare
var_x number:=10;
var_y number:=20;
begin
if var_x < var_y then
dbms_output.put_line(var_y);
else
dbms_output.put_line(var_x);
end if;
end;
/
create or replace procedure getmax(var_x number:=10,var_y number:=20)
is
begin
if var_x < var_y then
dbms_output.put_line(var_y);
else
dbms_output.put_line(var_x);
end if;
end;
/
29.4 如何调用存储过程?
call getmax(1,100);
call getmax(1);
call getmax(30);
exec getmax(1,100);
上面的调用方式 了解一下
开发中 用的比较多的是 使用 匿名块来调用存储过程 存储过程中调用存储过程
begin
getmax(123,99);
end;
/
29.5 查看存储过程
desc 存储过程名;
desc getmax;
PROCEDURE getmax
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
VAR_X NUMBER IN DEFAULT
VAR_Y NUMBER IN DEFAULT
第一部分 是参数的名字
第二部分 参数的类型
第三部分 参数的模式
第四部分 参数是否有缺省值
通过测试查询默认值 查询相关文档获取默认值
查询存储过程 源代码
select text from user_source where name='GETMAX';
29.6 写一个存储过程 有一个整数参数 代表一个数字
这个参数用来控制 打印 helloworld 的次数 比如 传入 3 则代表打印三次hello world
如果不传参数 则默认打印一次 hello world 。建立完存储过程之后 通过 desc 查询存储
过程 再通过 匿名块来调用存储过程。
create or replace procedure hellon(var_n number:=1)
is
begin
for i in 1..var_n loop
dbms_output.put_line('hello world');
end loop;
end;
/
begin
hellon(3);
end;
/
29.7 参数模式
in 默认的模式 代表只负责给存储过程 传入值
out 代表只负责给存储过程传出值
in out 即负责给存储过程传入值 又负责给存储过程传出值
只要有out 修饰的参数 必须是变量
static void addNumN(int x){
x=x+10000;
x
}
static void addString(StringBuffer s){
s.append("abc");
}
static void addString2(String s){
s=s+"abc";
}
public static void main(String[] args){
StringBuffer s = new StringBuffer("hello");
addString(s);
s
String s2= new String("hello");
addString2(s2);
s2
}
写一个存储过程 有三个整数参数 需要把前两个参数的和 存入第三个参数中 返回
create or replace procedure getSum(var_x in number,var_y number,
var_z out number)
is
begin
var_z := var_x + var_y;
end;
/
declare
var_z number:=1;
begin
getSum(1,99,var_z);
dbms_output.put_line(var_z);
end;
/
写一个存储过程 有两个整数参数 需要把前两个参数的和 存入第二个参数中 调用这个存储过程验证功能是否完成。
create or replace procedure getSum(var_x in number,var_y in out number)
is
begin
var_y := var_x + var_y;
end;
/
declare
var_y number:=1;
begin
/* 参数的位置赋值 */
getSum(99,var_y);
dbms_output.put_line(var_y);
end;
/
declare
var_y number:=1;
begin
/* 参数的名字赋值 改变赋值的顺序 参数的名字=>参数的值 */
getSum(var_y=>var_y,var_x=>99);
dbms_output.put_line(var_y);
end;
/
29.8 写一个存储过程 有两个整数参数 打印这两个参数的最大值 并且把两个参数的和
存入第二个参数中。调用存储过程 验证存储过程的功能。
create or replace procedure getMaxAndSum(var_x in number,
var_y in out number)
is
begin
if var_x < var_y then
dbms_output.put_line(var_y);
else
dbms_output.put_line(var_x);
end if;
var_y:=var_x+var_y;
end;
/
declare
var_y number:=1;
begin
getmaxandsum(88,var_y);
dbms_output.put_line(var_y);
end;
/
30.函数 function
30.1 函数和存储过程的不同
关键字不同 过程是 procedure 函数是 function
函数有返回值类型 和 返回值 需要返回值时用 return 返回 而过程没有
调用方式不同 过程可以直接调用可以看成PLSQL语句的一部分 而函数必须组成表达式才能调用
30.2 语法
create or replace function 函数名(参数列表) return 返回值类型
is
/* 申明区 */
begin
if 条件 then
return 值 ;
end if;
end;
/
30.3 写一个函数 设计两个整数参数 返回两个参数的最大值
create or replace function fungetmax(var_x number,var_y number) return number
is
begin
if var_x < var_y then
return var_y;
end if;
return var_x;
end;
/
select fungetmax(1,100) from dual;
begin
dbms_output.put_line(fungetmax(100,200));
if fungetmax(1,9527) > 100 then
dbms_output.put_line('hehe');
end if;
end;
/
30.4 写一个PLSQL函数 设计两个整数参数 返回这两个参数的最大值 并且把两个参数的和
存入第二个参数中。 调用函数 验证功能。
create or replace function fun_getmax_sum(var_x number,var_y in out number)
return number
is
begin
if var_x < var_y then
var_y:=var_x+var_y;
return var_y-var_x;
end if;
var_y:=var_x+var_y;
return var_x;
end;
/
create or replace function fun_getmax_sum(var_x number,var_y in out number)
return number
is
var_temp number;
begin
var_temp:=var_y;
var_y:=var_x+var_y;
if var_x < var_temp then
return var_temp;
end if;
return var_x;
end;
/
31.包package
31.1 概念
把相关的过程 函数 类型 等组织到一起的一个逻辑结构。
30.1.2 常见的系统包
dbms_output
dbms_output.put_line('hello');
dbms_random
select dbms_random.value(1,100) from dual;
select trunc(dbms_random.value(1,100)) from dual;
dbms_lob 读写大文本 和 大二进制的
dbms_job 定时任务包 它可以定时调用存储过程 #######
submit(job out binary_integer,what in varchar2,next_date date,interval varchar2)
job submit 提交定时器任务到数据库管理系统,数据库管理系统分配一个任务号 存入 job中。
what 要调用的存储过程
next_date 开始调用的时间
interval 调用的间隔 周期
run(job binary_integer) 把任务编号为job 定时任务运行起来
remove(job binary_integer) 删除编号为 job 的定时任务。
32 定时调用存储过程
32.1.建立一张
drop table testjob cascade constraints;
create table testjob(
id number constraint testjob_id_pk primary key,
name varchar2(30)
);
32. 2.drop sequence testjob_id_seq;
create sequence testjob_id_seq;
32.3. 注意存储过程 如果没有参数 则不能出现 ()
create or replace procedure insert_job
is
begin
insert into testjob values(testjob_id_seq.nextval,'test'||testjob_id_seq.currval);
commit;
end;
/
32.4.使用 dbms_job 包 一分钟 调用一次存储过程
declare
jobno binary_integer;
begin
dbms_job.submit(jobno,'insert_job();',sysdate,'sysdate+1/(24*60)');
dbms_output.put_line('jobno='||jobno);
dbms_job.run(jobno);
end;
/
select * from testjob;
32.5.删除定时任务
begin
dbms_job.remove(21);
end;
/
32.4 无论 是调用系统的包中的数据 还是自定义的包数据 记得在数据前
加 包名点 即可。
33.触发器trigger
33.1 概念
在进行 DML 操作时,这些操作可以被数据库管理系统 捕获到 进而进行相应的操作。
33.2 语法
create or replace trigger 触发器名 before|after DML操作(insert | delete|update)
on 表名 |for each row
declare
begin
end;
/
33.3 快速建立一张表
create table testemp09 as select id,first_name name ,salary from s_emp;
针对这张表 建立一个触发器
create or replace trigger testemp09_tri after update on testemp09
declare
begin
dbms_output.put_line('warning you update table testemp09');
end;
/
update testemp09 set salary= salary+100 where id=1;
update testemp09 set salary= salary+100 where id<1;
update testemp09 set salary= salary+100 where id>1;
无论sql影响多少行数据 触发器只触发一次 我们管这种触发器叫 语句级触发器。
如果希望 影响多少行 就触发多少次 可以使用行级触发器 这样可以精确的控制数据的变化。
create or replace trigger testemp09_tri after update on testemp09 for each row
declare
begin
dbms_output.put_line(:old.id||':'||:old.name||':'||:old.salary);
dbms_output.put_line('warning you update table testemp09');
dbms_output.put_line(:new.id||':'||:new.name||':'||:new.salary);
end;
/
update testemp09 set salary= salary+100 where id=1;
update testemp09 set salary= salary+100 where id<1;
update testemp09 set salary= salary+100 where id>1;
update :old :new
delete :old
insert :new
34.事务的四个隔离级别
conn.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
可以通过 Connection 点的方式 获取对应的常量
Connection.TRANSACTION_READ_UNCOMMITED 读未提交
Connection.TRANSACTION_READ_COMMITED 读提交
Connection.TRANSACTION_REPEATABLE_READ 可重复读
Connection.TRANSACTION_SERIALIZABLE 序列化
这四个隔离级别 是为了解决三个问题
脏读
一个事务 读取到了 另外一个事务没有提交的数据
不可重复读
一个事务在开始时 读取了一份数据 然后操作的过程中 这个事务影响的数据
被另外一个事务修改了并做了修改的提交,这个时候再次读取这份时 数据就
发生了改变。
幻读
一个事务在开始时 对表中的所有数据进行了统计 然后操作的过程中 表中的数据发生了
增 删 这样统计的数据就发生了改变。
35.连接池 (java)
35.1 为什么要有连接池
频繁的获取 和 关闭连接 是非常消耗资源的
连接池的连接的关闭 只是把连接放回了连接池
35.2 使用连接池来获取连接
BasicDataSource datasource = new BasicDataSource();
// 设置数据源的参数
datasource.setDriverClassName("oracle.jdbc.OracleDriver");
datasource.setUrl("jdbc:oracle:thin:@127.0.0.1:1521:xe");
datasource.setUsername("system");
datasource.setPassword("abc123");
// 最大空闲数
datasource.setMaxIdle(5);
// 最小空闲数
datasource.setMinIdle(1);
// 最大活动连接 最大连接数据
datasource.setMaxActive(15);
// 初始化数量
datasource.setInitialSize(2);
//创连接
Connection conn= ba.getConnection();