解密:GPT-4框架与训练过程,数据集组成,并行性的策略,专家权衡,推理权衡等细节内容
大家好,我是微学AI,今天给大家解密一下GPT-4框架与训练过程,数据集组成,并行性的策略,专家权衡,推理权衡等细节内容。2023年3月14日,OpenAI发布GPT-4,然而GPT-4的框架没有公开,OpenAI之所以不公开GPT-4的架构,并不是因为存在对人类的潜在威胁,而是因为他们所建立的模型是可以被复制的。事实上,我们预计Google、Meta、Anthropic、Inflection、Character、腾讯、阿里、百度等公司在短期内都会拥有与GPT-4同样甚至更强大的模型。当然,OpenAI具有令人惊叹的工程能力,他们所构建的东西也是令人难以置信的,但是他们所采用的解决方案并非神奇。这是一个实用的方案,其中包含许多复杂的权衡。OpenAI最大优势在于他们拥有最多的真实世界使用情况、领先的工程人才,并且可以通过未来的模型继续领先其他公司。
GPT-4现状
我们从多个信息源收集到了关于GPT-4的大量信息,今天我们想要分享一些。这包括模型架构、训练基础设施、推理基础设施、参数数量、训练数据集组成、标记数量、层次数量、并行策略、多模态视觉适应性、不同工程权衡背后的思考过程、已实施的独特技术,以及他们如何缓解与庞大模型推理相关的一些最大瓶颈。
GPT-4最有趣的方面在于理解他们为什么做出了某些架构决策。此外,我们还将概述GPT-4在A100上进行训练和推理的成本,并介绍与下一代模型架构使用H100相比的规模。
首先,让我们来看一下问题陈述。从GPT-3到GPT-4,OpenAI希望将规模扩大100倍,但问题的关键在于成本。稠密的Transformer模型无法进一步扩展。稠密的Transformer是OpenAI GPT-3、Google PaLM、Meta LLAMA、TII Falcon、MosaicML MPT等模型所使用的模型架构。我们可以轻松地列举出50家使用相同架构进行LLM训练的公司。这是一个好的架构,但在扩展性方面存在缺陷。
GPT-4框架
GPT-4的规模是GPT-3的10倍以上。据我们了解,它有大约1.8万亿个参数,分布在120个层,而GPT-3只有大约1750亿个参数。
OpenAI通过使用混合专家(MoE)模型,成功地将成本控制在合理范围内。
此外,OpenAI的模型中有16位专家,每位专家的多层感知机(MLP)参数约为1110亿个。每次前向传递(forward pass)有两位专家进行路由。
尽管文献中谈到了选择将每个tokens路由到哪个专家的高级路由算法,但据说OpenAI当前的GPT-4模型相对简单。
此外,注意力机制中大约有550亿个共享参数。
每次前向推导(生成一个标记)时,仅使用大约2800亿个参数和560 TFLOPS。这与完全密集模型每个前向传递所需的大约1.8万亿个参数和3700 TFLOPs形成鲜明对比。
数据集组成
OpenAI在大约13万亿个tokens上对GPT-4进行了训练。考虑到CommonCrawl的RefinedWeb中包含大约5万亿个高质量tokens,这是有道理的。作为参考,Deepmind的Chinchilla模型和Google的PaLM模型分别使用了大约1.4万亿个和0.78万亿个tokens进行训练。甚至据称PaLM 2也是基于大约5万亿个tokens进行训练的。
这个数据集并不包含13万亿个独特的tokens。相反,由于缺乏高质量的tokens,该数据集包含多个时期。文本数据经历了2个时期,而代码数据则经历了4个时期。有趣的是,这远远少于Chinchilla的最佳状态,这表明需要以两倍的tokens数量对模型进行训练。这表明在网络上很难找到易获取的tokens。存在着比之前提到的高质量文本tokens多1000倍的数量,甚至还有更多的音频和视觉tokens,但是获取它们并不像简单的网页抓取那么容易。
还有来自ScaleAI以及内部的数百万行指导微调数据。不幸的是,我们找不到关于他们的强化学习高分辨率函数(RLHF)数据的详细信息。
预训练阶段的上下文长度(seqlen)为8,000。 GPT-4的32,000个seqlen版本是在预训练后对8,000个seqlen进行微调得到的。
批处理大小逐渐在集群上的若干天内逐渐增加,但最后,OpenAI使用了批处理大小为60百万!当然,由于并非每个专家都看到所有tokens,这实际上是每个专家仅处理了7.5百万个tokens。
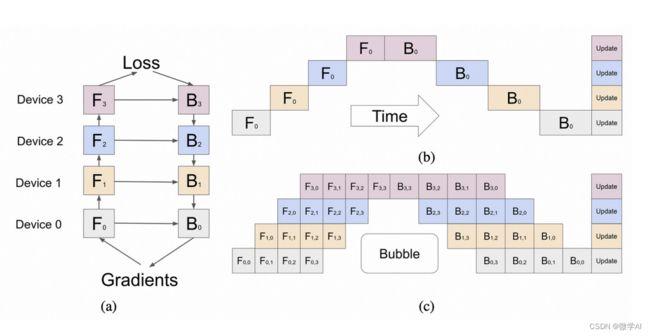
并行性的策略
在跨所有A100 GPU进行并行化的策略非常重要。他们利用了8路张量并行性,因为这是NVLink的限制。除此之外,他们还使用了15路管道并行。从理论上讲,在考虑到数据通信和计算时间之比时,这样的管道数量太多了,但如果他们受到内存容量限制,那么这样做是有道理的。
每个GPU纯粹通过管道+张量并行化时,仅参数的FP16占用约30GB的内存。一旦加上KV缓存和开销,如果OpenAI的大部分GPU是40GB的A100,那么从理论上讲这是有道理的。他们可能使用了ZeRo阶段1。他们可能还使用了块级FSDP或者混合共享数据并行化。
至于为什么他们没有使用完整模型的FSDP,可能是因为更高的通信开销。虽然OpenAI的大多数节点之间具有高速网络连接,但并不是所有节点之间的带宽都很高。我们相信至少有一些集群之间的连接带宽比其他集群低得多。
训练费用
OpenAI训练GPT-4所使用的浮点操作数(FLOPS)约为2.15x10^25,使用了大约25,000块A100 GPU,在90至100天的时间内运行,利用率在32%至36%之间。其中,非常低的利用率部分是由于大量的失败导致需要重启检查点。上述提到的中断非常昂贵。
另一个原因是在这么多GPU之间进行全局归约操作是非常昂贵的,尤其是如果我们怀疑集群实际上是一组具有较弱网络连接的小集群,每个集群内部的非阻塞带宽为800G/1.6T,但这些集群之间的连接只有200G/400G。
如果在云端的A100 GPU每小时成本约为1美元,仅考虑这次训练的成本将达到约6300万美元。这还不包括所有的试验、失败的训练运行和其他诸如数据收集、强化学习超参数优化、人员等费用。考虑到这些因素,实际成本要高得多。此外,这还假设你有某个机构购买芯片、网络设备和数据中心,承担资本支出,并将其租给你使用。
目前,使用大约8,192块H100 GPU可以在约55天内完成预训练,成本为2150万美元,每小时成本为2美元。需要注意的是,我们相信到今年年底将有9家公司拥有更多的H100 GPU。虽然不是所有公司都会将它们全部用于单个训练运行,但那些这样做的公司将能够训练出更大规模的模型。Meta公司到今年年底将拥有超过100,000块H100 GPU,但其中很大一部分将分布在他们的数据中心进行推理。他们最大的单个集群仍将拥有超过25,000块H100 GPU。到今年年底,许多公司将拥有足够的计算资源来训练一个与GPT-4规模相当的模型。
专家权衡机制
MoE是一种在推理过程中减少参数数量的好方法,同时仍然增加参数数量,这对于每个训练标记来编码更多信息是必要的,因为获取足够高质量的标记非常困难。如果OpenAI真的试图达到最佳性能,他们实际上需要训练两倍数量的标记。
话虽如此,OpenAI做出了多种权衡。例如,在推理过程中,与MoE的处理非常困难,因为模型的每个部分并不在每个标记生成时都被使用。这意味着某些部分可能处于休眠状态,而其他部分正在使用。对于服务用户来说,这会严重影响利用率。
研究人员表明,使用64到128个专家比使用16个专家可以获得更好的损失结果,但那只是纯粹的研究。选择较少的专家有多种原因。OpenAI选择使用16个专家的原因之一是更多的专家在许多任务上很难进行泛化。更多的专家也更难实现收敛。在如此大规模的训练过程中,OpenAI选择在专家数量上更为保守。
此外,使用较少的专家还有助于他们的推理基础设施。在转向专家混合推理架构时,存在各种困难的权衡。让我们先从普通语言模型(LLM)的推理中的基本权衡开始,然后再讨论OpenAI面临的挑战和他们所做的选择。
推理的权衡
在开始之前,我们想提一下,我们与所有的LLM(Large Language Model)公司交流过后得出的结论是,Nvidia的FasterTransformer推理库相当糟糕,而TensorRT更是更差劲。由于无法根据Nvidia的模板进行修改,人们只能从头开始创建自己的解决方案。如果Nvidia团队正在阅读这篇文章,你们需要尽快改进LLM推理功能,否则标准工具将变成一个开放的工具,可以更轻松地添加第三方硬件支持。大规模模型的潮流即将到来。如果在推理中没有软件优势,并且仍然需要手动编写核心代码,那么AMD的MI300和其他硬件市场将会更大。
在LLM推理中,有三个主要的权衡要考虑,即批处理大小(并发用户数量)和使用的芯片数量。
1.延迟 - 模型必须在合理的延迟内响应。在聊天应用程序中,人们不希望等待几秒钟才能开始获取输出。预填充(输入标记)和解码(输出标记)需要不同的时间来处理。
2.吞吐量 - 模型必须每秒输出一定数量的标记。对于人类使用,大约需要每秒30个标记。对于其他用途,较低和较高的吞吐量也是可以接受的。
3.利用率 - 运行模型的硬件必须实现高利用率,否则将成本过高。虽然可以通过更高的延迟和较低的吞吐量将更多的用户请求分组在一起,从而实现更高的利用率,但这会增加一定的困难。
LLM推理主要涉及平衡两个关键点,即内存带宽和计算能力。简单来说,每个参数都需要被读取,并且与之相关联的是2个浮点运算。因此,大多数芯片(如H100 SXM)在批处理大小为1时,内存带宽(3TB/s)与FP8的计算能力(2,000 TFLOP/s)之比完全不平衡。如果只有一个用户进行服务,即批处理大小为1,那么推理时间主要由传输每个标记生成所需的参数所占用的内存带宽决定,而计算时间几乎可以忽略不计。
为了将大型语言模型高效地扩展到许多用户,批处理大小必须超过1。多个用户可以分摊参数读取成本。例如,在批处理大小为256或512时,每个读入的字节内存对应512个或1024个浮点运算。这种比例更接近H100的内存带宽与FLOPS之间的关系。这有助于实现更高的利用率,但代价是延迟增加。
许多人认为,LLM推理的主要瓶颈是内存容量,因为模型的大小决定了可以放入多少个芯片中,但这是不正确的。尽管大型模型需要多个芯片进行推理,并且较高的内存容量意味着它们能够适应更少的芯片,但实际上使用比所需容量更多的芯片更好,这样可以降低延迟,提高吞吐量,并使用更大的批处理大小以实现越来越高的利用率。

GPT-4推理权衡和基础设施
使用GPT-4的混合专家(MoE)模型架构会引入一系列新的困难,这使得以上所有问题都变得困难起来。每个标记生成的前向传递可以被路由到不同的专家组。这给在吞吐量、延迟和批处理大小之间取得平衡带来了麻烦。
OpenAI的GPT-4有16个专家,每次前向传递分配其中2个。这意味着如果批处理大小为8,则每个专家的参数读取只能是批处理大小1。更糟糕的是,某个专家可能具有批处理大小为8,而其他专家可能是4、1或0。每次生成标记时,路由算法将使前向传递以不同的方向进行,导致标记与标记之间的延迟和专家批处理大小变化显著。
推理基础设施是OpenAI选择较少数量的专家的主要原因之一。如果他们选择更多的专家,内存带宽将更加瓶颈推理过程。OpenAI的推理集群通常达到4k+的批处理大小,这意味着即使在专家之间进行了最佳负载平衡,专家的批处理大小也只有大约500左右。这需要非常大规模的使用才能实现。
据我们了解,OpenAI在一个由128个GPU组成的集群上进行推理。他们在多个数据中心和地理位置上都有多个这样的集群。推理过程采用8路张量并行和16路管道并行。每个由8个GPU组成的节点只有大约130亿个参数,即FP16精度下不到30GB,FP8/int8精度下不到15GB。这使得推理可以在40GB A100的GPU上运行,只要所有批次之间的KV缓存大小不会变得太大。
包含各种专家的各个层不能在不同节点之间分开,因为这样会使网络流量变得不规则,并且在每个标记生成之间重新计算KV缓存的代价太大。对于任何未来的MoE模型扩展和条件路由,最大的困难是如何在KV缓存周围进行路由。
模型的层数为120层,因此将其分配给15个不同的节点是很简单的,但由于第一个节点需要进行数据加载和嵌入,所以在推理集群的首节点上放置较少的层是有意义的。此外,关于有些人提出的猜测解码的传闻,我们稍后会讨论,但我们不确定是否相信这些传闻。这也解释了为什么首节点需要包含较少的层。
GPT-4推理成本
尽管GPT-4的前馈参数仅为175B参数的Davinchi模型的1.6倍,但其成本却是Davinchi模型的3倍。这主要是因为GPT-4需要更大规模的集群,并且利用率较低。
我们认为,对于128个A100 GPU来推理GPT-4的8k序列长度,每1,000个标记的成本为0.0049美分;而对于128个H100 GPU来推理GPT-4的8k序列长度,每1,000个标记的成本为0.0021美分。值得注意的是,我们假设高利用率,并保持批处理大小较大。
然而,OpenAI有时明显存在利用率非常低的情况,这可能是我们的一个错误假设。我们假设OpenAI在低峰时段会关闭集群,并利用那些节点从检查点中恢复训练,用于较小的测试模型,试验各种新技术。这有助于降低推理成本。如果OpenAI不这样做,他们的利用率将更低,我们的成本估计将翻倍以上。
多头查询注意力
MQA是其他人正在做的事情,但我们想指出OpenAI也在采用这种方法。简而言之,只需要一个头部,并且KV缓存的内存容量可以大大减少。即便如此,32k序列长度的GPT-4绝对无法在40GB的A100 GPU上运行,而8k序列长度在最大批处理大小上也有限制。如果没有这个限制,8k序列长度将在最大批处理大小上受到显著限制,甚至达到经济不划算的程度。
连续批处理
OpenAI实施了可变批量大小和连续批处理。这样做可以允许一定水平的最大延迟,并且优化推理成本。如果您对连续批处理的概念不熟悉,可以阅读AnyScale的此页面,它值得一读。
推测性解码
OpenAI在GPT-4推理中使用了推测解码(speculative decoding)。我们不确定是否完全相信这个说法。从tokens到tokens的延迟波动以及在简单检索任务和复杂任务之间的差异似乎表明这是可能的,但是有太多的变量无法确定。为了防止误解,我们将在此处使用《加速LLM推理的分阶段推测解码》中的部分文本,并进行一些修改和添加一些色彩。
使用LLMs通常分为两个阶段。首先是预填充(prefill)阶段,将提示语通过模型运行以生成KV缓存和第一个输出Logits(可能的tokens输出概率分布)。这通常很快,因为整个提示可以并行处理。
第二阶段是解码阶段。从输出的Logits中选择一个tokens,并将其馈送回模型,生成下一个tokens的Logits。重复此过程直到生成所需数量的tokens。由于解码必须按顺序进行,每次都需要将权重流传输到计算单元,以生成单个tokens,因此当以小批量方式运行时,此第二阶段的算术强度(即计算的FLOP / 内存带宽的字节)极低。因此,解码通常是自回归生成中最耗费资源的部分。
这就是为什么在OpenAI的API调用中,输入tokens比输出tokens便宜得多的原因。
推测解码的基本思想是使用一个较小且更快的草稿模型来提前解码多个tokens,然后将其作为单个批次馈送给正式模型(oracle model)。如果草稿模型的预测是正确的(即较大模型也同意),那么可以通过单个批次解码多个tokens,从而节省了相当多的内存带宽和时间。
然而,如果较大模型拒绝草稿模型预测的tokens,则剩余的批次将被丢弃,算法自然而然地回退到标准的逐tokens解码方式。推测解码还可以与拒绝采样方案结合使用,以从原始分布中进行采样。请注意,这仅在带宽是瓶颈的小批量环境中有用。
推测解码以计算代价换取带宽。为什么推测解码成为一个有吸引力的性能优化目标有两个关键原因。首先,它不会降低模型的质量。其次,它提供的性能改进通常与其他方法无关,因为其性能来自于将顺序执行转换为并行执行。
目前的推测方法为批次预测一个单一序列。然而,这对于大批量大小或低草稿模型对齐性来说并不具备良好的可扩展性。直观来说,两个模型在长连续tokens序列上达成一致的概率是指数级低的,这意味着随着算术强度的增加,推测解码的收益会迅速变小。
我们认为如果OpenAI使用推测解码,它们可能仅将其应用于约4个tokens的序列。另外有人还猜测Bard使用了推测解码,因为谷歌在将整个序列发送给用户之前会等待,但我们不认为这种猜测是真实的。
视觉多模态
目前还没有将多模态LLM的研究商业化的例子。它使用了一个独立的视觉编码器和文本编码器,但二者之间存在交叉注意力。据说它的架构与Flamingo类似,并在GPT-4的基础上增加了更多参数,总参数量达到了1.8T。在仅有文本的预训练之后,它还进行了约2万亿次微调。
关于视觉模型,OpenAI本来希望从头开始训练,但由于技术尚不成熟,所以选择了从文本开始以降低风险。下一个模型,即GPT-5,据说将完全从头开始训练,具备生成图像的能力,并且还能处理音频。
这种视觉能力的一个主要应用是用于自主代理,能够阅读网页并转录其中的图像和视频内容。他们训练的数据中包括联合数据(渲染的LaTeX/文本)、网页截图、YouTube视频帧采样,并运行Whisper技术获取转录内容。
在所有针对LLMs的过度优化中,一个有趣的事实是视觉模型的输入输出成本与文本模型不同。正如我们在“亚马逊云危机”一文中所描述的,文本模型的数据加载成本极低。而视觉模型的IO成本则高出大约150倍,每个标记的数据量为600字节,而不是文本模型的4字节。现在人们正在对图像压缩进行大量研究。
这对于那些为未来2-3年优化硬件以适应LLMs使用情况和比例的硬件供应商来说非常重要。他们可能会发现自己处于一个几乎每个模型都具备强大视觉和音频能力的世界中。他们的架构可能无法很好地适应这种情况。总之,LLMs的架构肯定会进一步发展,超越目前简化的以文本为基础的密集模型和MoE模型。