将名为“普通高等学校本科专业目录.pdf”的pdf文件转换成csv文件
文章目录
- 任务描述
- 2023年普通高等学校本科专业目录pdf链接
- 代码
- 代码解析
- 运行截图
任务描述
将名为“普通高等学校本科专业目录.pdf”的pdf文件转换成csv文件。这个pdf每页是个表格,表格有7列。
下面是pdf的第一页和第二页:
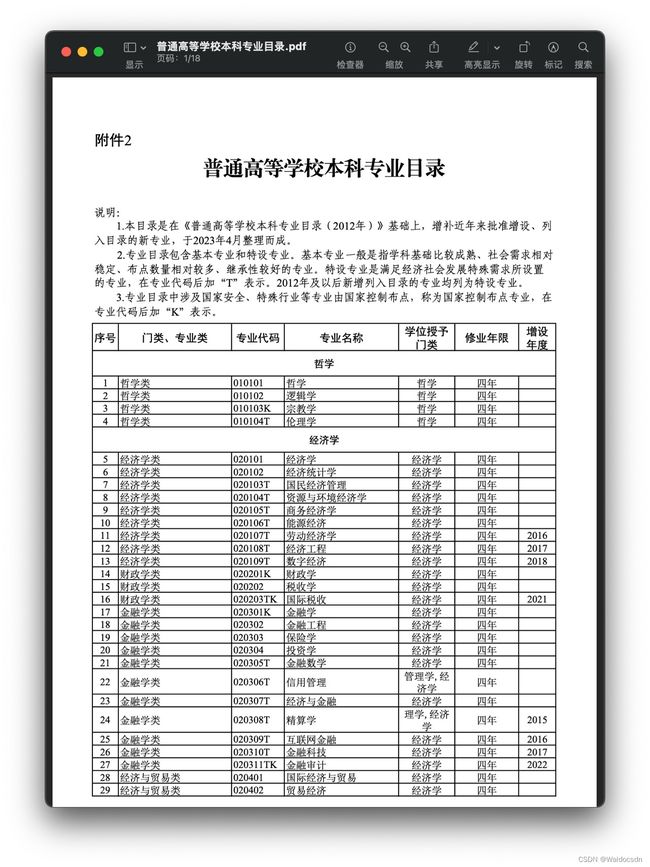
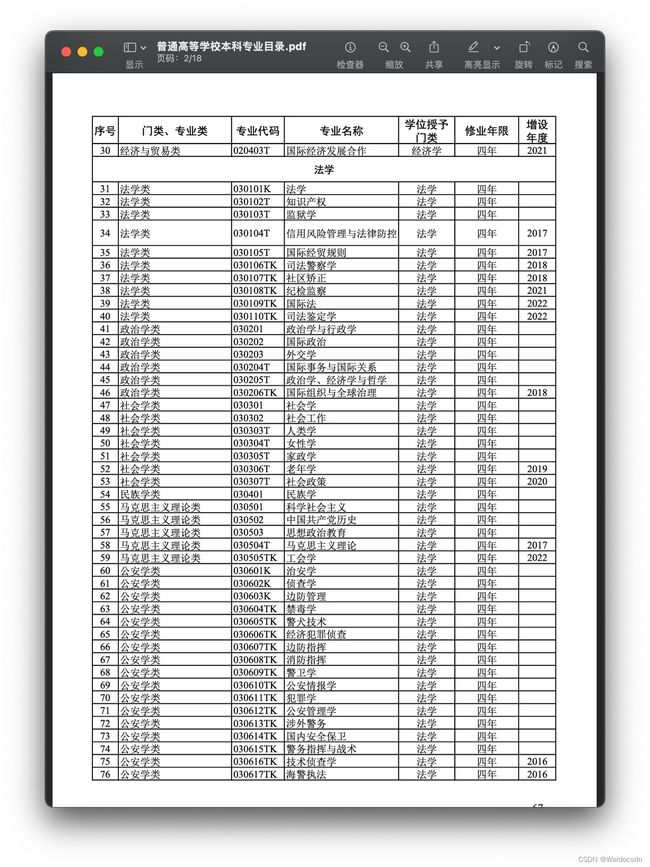
2023年普通高等学校本科专业目录pdf链接
链接: https://pan.baidu.com/s/14acDd_L7AtXgKyq_LAV5Rg?pwd=hmne 提取码: hmne
代码
可以使用 Python 的几个库来做到这一点。以下是一个示例代码,该代码使用了pdfplumber来读取PDF文件,并使用pandas来保存数据到csv文件。
注意:此代码假设pdf文件中的表格能够通过线条明确辨识,并且此方法可能不会对所有pdf文件有效,因为pdf的构造和内容可能会对解析产生影响。
import pdfplumber
import pandas as pd
def convert_pdf_to_csv(pdf_file):
# 打开pdf文件
with pdfplumber.open(pdf_file) as pdf:
# 初始化一个空的DataFrame用于存储所有页的数据
df_all = pd.DataFrame()
# 遍历每一页
for page in pdf.pages:
# 提取表格数据
tables = page.extract_tables()
for table in tables:
# 将表格数据转化为DataFrame
df = pd.DataFrame(table[1:], columns=table[0])
df_all = pd.concat([df_all, df])
# 保存为csv文件
df_all.to_csv(pdf_file.replace('.pdf', '.csv'), index=False)
# 使用函数
convert_pdf_to_csv("普通高等学校本科专业目录.pdf")
以上代码将遍历PDF中的每一页,并从每页中提取表格数据。这些数据将被合并并保存到一个CSV文件中。最后的CSV文件名将与输入的PDF文件名相同,只是扩展名变为了".csv"。
代码解析
这段代码是在Python环境下运行的首先,它需要导入两个库:pdfplumber和pandas。
-
import pdfplumber:pdfplumber是一个Python库,用于提取PDF中的文本、表格和元数据。 -
import pandas as pd:pandas是一个Python数据分析库,这里主要用它来创建和操作DataFrame(一个二维标签化的数据结构),并将DataFrame保存为csv文件。
然后,定义了一个名为convert_pdf_to_csv的函数,该函数接受一个参数pdf_file,代表要转换的PDF文件名。
-
with pdfplumber.open(pdf_file) as pdf: 使用pdfplumber的open函数打开PDF文件。with语句用于包裹文件操作的上下文,确保文件在操作完毕后被正确关闭。 -
df_all = pd.DataFrame(): 初始化一个空的DataFrame,用于存储从每一页PDF中提取出来的表格数据。 -
for page in pdf.pages: 遍历PDF的每一页。 -
tables = page.extract_tables(): 使用pdfplumber的extract_tables函数从每一页中提取表格数据,这会返回一个列表,每个元素代表一页中的一个表格,表格本身也是一个列表,其中包含行数据。 -
for table in tables: 对于每个提取出来的表格。 -
df = pd.DataFrame(table[1:], columns=table[0]): 将表格数据转换为DataFrame。这里假设表格的第一行是列名,所以我们用table[0]作为列名,剩余的table[1:]作为数据。 -
df_all = pd.concat([df_all, df]): 将当前页的DataFrame(df)与总的DataFrame(df_all)合并。 -
df_all.to_csv(pdf_file.replace('.pdf', '.csv'), index=False): 将最后的DataFrame保存为csv文件。文件名通过将原PDF文件名的’.pdf’部分替换为’.csv’得到。参数index=False表示在保存csv时不包括索引。
最后一行是调用这个函数,将指定的PDF文件转换为CSV文件。
运行截图
