C语言文件操作
文章目录
- C语言文件操作
-
- 1.为什么使用文件
- 2.什么是文件
-
- 程序文件
- 数据文件
- 文件名
- 3.文件的打开与关闭
-
- 3.1.文件指针
- 3.2.文件的打开与关闭
- 3.2.1文件的打开
-
- 3.2.1.1文件名
- 3.2.1.2文件的打开方式
- 3.2.1.3关于fopen的补充
- 3.2.2文件的关闭
- 3.2.3完整打开关闭文件实现
- 4.文件的顺序读写
-
- 4.1.文件读写函数
- 4.2.文件输入输出函数解析
-
- 4.2.1.fputc
- 4.2.2.fgetc
- 4.2.3.fputs
- 4.2.4.fgets
- 4.2.5.fprintf
- 4.2.6.fscanf
-
- 关于输入输出流的补充说明
- 4.2.7.fwrite
- 4.2.8.fread
-
- 对比一组函数
- 5.文件的随机读写
-
- 5.1.fseek
- 5.2.ftell
- 5.3.rewind
- 6.文本文件和二进制文件
- 7.文件读取结束的判定
-
- 7.1.如何判断文件是否读取结束
- 7.2 feof函数
- 8.文件缓冲区
C语言文件操作
1.为什么使用文件
在平时我们写的代码会定义变量,数组和自定义类型等用作在程序执行时的数据存储,这样做确实可以让我们存储数据,但是一旦程序结束,程序执行时申请用来存储数据的内存空间就还给了操作系统,我们就不能在下一次程序执行时拿到我们上一次程序执行时输入的数据,但如果我们想让数据无论在何时我们想读取都可以读到,那么我们就要用到文件,因为文件是存储在硬盘里,除非硬盘损坏造成数据丢失,数据会永久保存在硬盘里,做到了数据的永久化。
2.什么是文件
关于什么是文件,其实文件很常见,例如我随便打开一个文件夹,里面的都是文件。
例如我这个文件夹,通过观察类型那一栏,我们能发现里面,有各种各样类型的文件。这些放在磁盘上的都叫文件,
关于程序设计中,我么一般只谈两种文件:程序文件、数据文件(通过文件的功能划分。)
程序文件
包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境 后缀为.exe)。
程序文件既是在程序创建、程序执行过程中和程序结束后生成的所有文件。
数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件, 或者输出内容的文件。
数据文件既是放在硬盘上存储我么所需数据的文件,关于本章讨论的文件都是数据文件,因为数据文件帮助我们实现数据的永久存储,
保证我们能在每次程序执行时都能读取我们之前所存储的数据。
之前我们对数据的操作也就是输入和输出都是对终端操作的,也就是从终端的键盘输入数据,打印数据在屏幕上。
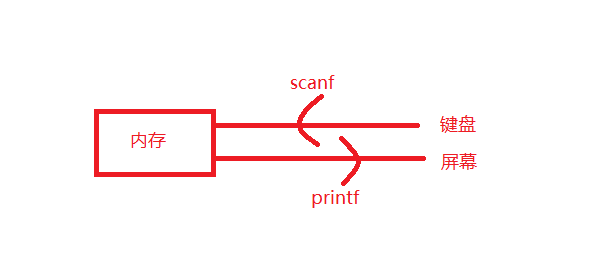
而通过数据文件我们对于数据的输入输出就变了,我们可以把数据从内存到磁盘上存储的文件。

文件名
每个文件需要通过某种标识唯一确定,就像人的身份证号码一样,每个人都是独一无二的,通过一个身份证号码可以唯一确定一个人,
文件标识的作用就如同身份证号码一样,可以唯一确定一个文件。
而一个完整的文件名包含3个部分:文件路径 + 文件名主干 + 文件后缀名。
例如:C:\Users\123\Desktop\c++项目文件夹\code-warehouse\10_9\test.c
- 文件路径:C:\Users\123\Desktop\c++项目文件夹\code-warehouse\10_9\
- 文件名主干:test
- 文件名后缀: .c
- 文件中不能包含这些字符:/?"<>|,
为了方便,我们通常把文件标识叫做文件名
3.文件的打开与关闭
3.1.文件指针
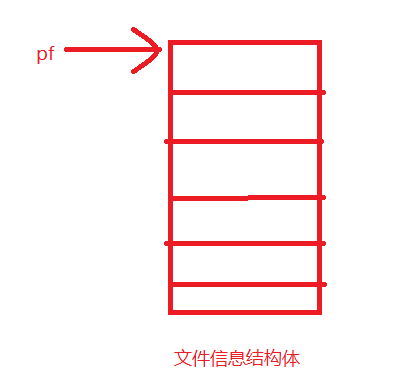
关于文件的打开,首先我们必须知道一个概念就是文件指针。
每一个被使用的文件在被使用时,系统都会为其开辟一部分内存空间,用来存储该文件的文件信息(包括文件名,文件的状态和文件的位置等)。这些文件信息被保存在系统自定义的结构体类型中,类型名为FILE,FILE*也被称为文件指针。
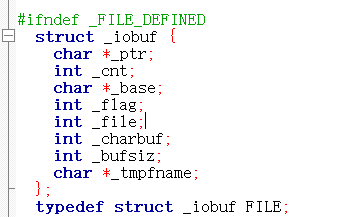
上图为code blocks编译器中对文件存储信息结构体的类型定义,每一个编译器对文件信息结构体类型的定义可能有所不同,但都大同小异,程序通过文件信息,可以准确的操作想操作的文件,因此我们要通过文件信息操作文件,文件指针能够指向存储文件信息的结构体数据,我们可以通过文件指针得到文件信息,进而操作文件。
关于文件指针指向的信息具体内容和拿到信息后如何操作,编译器会自动处理,不必关心,我们只需要知道通过文件指针,可以方便的操作文件。
FILE* pf
就像如此我们定义一个存储文件存储信息结构体的指针,拿到文件信息,进而操作我们想操作的文件。
3.2.文件的打开与关闭
关于文件的操作,类似于一个水瓶,我们要往瓶子里倒水,首先我们要打开瓶子,然后我们往瓶子里倒入水,在装完水之后我们要关上瓶子,防止瓶子里的水洒出来,文件的操作就类似于此,在我们向文件存储数据时,首先我们要打开文件,然后进行文件的读取和写入,在完成文件数据的写入和读取之后,我们要关闭文件,防止文件数据的泄露。
3.2.1文件的打开

关于我们的文件打开,我们会用到库函数(在
3.2.1.1文件名
文件名分为两类:
1.相对路径:相对路径所指的相对是指相对程序所在的工程文件夹,输入相对路径文件名,打开的是程序所在工程文件夹里的文件。
如图,程序创建好后,程序文件所在的文件夹就是程序所在的工程文件夹,如果我在fopen函数中输入data.txt 打开的就是此文件夹下的data.txt 文件。
FILE* pf = fopen("data.txt", "w");
2.绝对路径:绝对路径和相对路径的区别在于绝对路径是该文件完整的文件名,他是你指定硬盘、指定文件夹内的数据文件,
比如我要打开以下数据文件:

我要在fopen函数中输入完整的文件名
FILE* pf = fopen("C:\\测试文件夹\\data.txt", "w");
要注意用两个\因为第一个\代表转义。
3.2.1.2文件的打开方式
值得注意的是文件的打开方式使用双引号括起来的字符串。
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| “r”(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| “w”(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a”(追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
| “rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| “wb”(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
| “ab”(追加) | 向一个二进制文件尾添加数据 | 出错 |
| “r+”(读写) | 为了读和写,打开一个文本文件 | 出错 |
| “w+”(读写) | 为了读和写,建立一个新的文件 | 建立一个新的文件 |
| “a+”(读写) | 打开一个文件,在文件尾添加数据 | 建立一个新的文件 |
| “rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
| “wb+”(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| “ab+”(读写) | 打开一个二进制文件,在文件尾添加数据 | 建立一个新的文件 |
以上所指的输入数据含义为:从文件读取数据输入内存中。
输出数据含义为:把内存中的数据输出到文件中。
3.2.1.3关于fopen的补充
关于文件打开函数fopen函数还需知道的是fopen的返回值为FILE*类型,也就是存储文件信息的结构体的指针。
打开文件失败会返回一个空指针。
3.2.2文件的关闭

观察文件关闭函数的声明,我们发现fclose也就是文件关闭函数只有一个参数,那就是FILE*类型的指针,也就是存储所操作的文件信息的结构体的指针,因此fclose的调用相对简单。
fclose(pf);
pf = NULL;
值得注意的是fclose类似于动态内存开辟中的free函数,需要手动将指针置为空,防止指针为一个野指针。
3.2.3完整打开关闭文件实现
以下为完整的打开和关闭文件实现。
#include 4.文件的顺序读写
4.1.文件读写函数
关于文件的读写和在键盘上读在屏幕上写一样有很多内置的库函数。
| 功能 | 函数名 | 适用于 |
|---|---|---|
| 字符输入函数 | fgetc | 所有输入流 |
| 字符输出函数 | fputc | 所有输出流 |
| 文本行输入函数 | fgets | 所有输入流 |
| 文本行输出函数 | fputs | 所有输出流 |
| 格式化输入函数 | fscanf | 所有输入流 |
| 格式化输出函数 | fprintf | 所有输出流 |
| 二进制输入 | fread | 文件 |
| 二进制输出 | fwrite | 文件 |
以往我们用scanf函数在键盘里读(输入),用printf函数在屏幕上写(输出),实际上都是通过内存暂存数据的,文件的操作也一样。

读和写,也就是输入和输出都会通过内存暂存数据,输入和输出都是指从将数据输入到内存中或者输出到内存中。
4.2.文件输入输出函数解析
4.2.1.fputc

首先是fputc函数,通过观察fputc函数的声明我们可知,调用fputc函数需要两个参数,第一个是要输出到文件的字符,第二个参数就存储文件信息的结构体的指针。
//实例代码
#include 结果展示:

值得注意的是,由于本代码实现时用的时"w"方式打开,也就是只写方式,因此每次运行程序进行向文件输出的操作时,会清空上一次存储的数据重新输出,这一点要和以追加形式打开文件的操作分开来。
4.2.2.fgetc
然后是fgetc函数。

通过观察fetc函数的函数声明可知,调用fetc函数只需要输入存储文件信息的结构体的指针,但注意只能读取一个字符。
//代码演示
#include 结果展示:

如果读取成功返回读取的字符的ASCII码值,如果读取失败会返回EOF也就是-1。

我么可以利用这一点运用循环读取数据。
//代码演示
#include 结果展示:
4.2.3.fputs
通过观察上面的表格我们知道fputs是文本行输出函数,也就是对于一行字符串的输入函数。

首先我们还是观察fputs函数的函数声明,我们能知道fputs函数的调用需要两个参数,第一个参数是一个字符指针,即存放想要输出到文件里的字符或字符串的地址,第二个参数依旧是存储文件信息的结构体的指针。
//代码实现
#include 结果演示:
4.2.4.fgets
和fputs函数相对应的就是fgets函数,也就是文本行输入函数,也就是输入一行字符的函数。

首先,我么观察fgets函数的函数声明,我们知道fets函数的调用需要两个参数,第一个参数是一个字符指针,用来存储从文件中读取的数据,第二个参数是一个整形数,用来表示读取这一行的字符个数,但要注意的是如果我们第二参数输入的是n,实际读到的字符数是n-1个,第三个参数是存储文件信息的结构体的指针。
//代码实现
#include 结果演示:
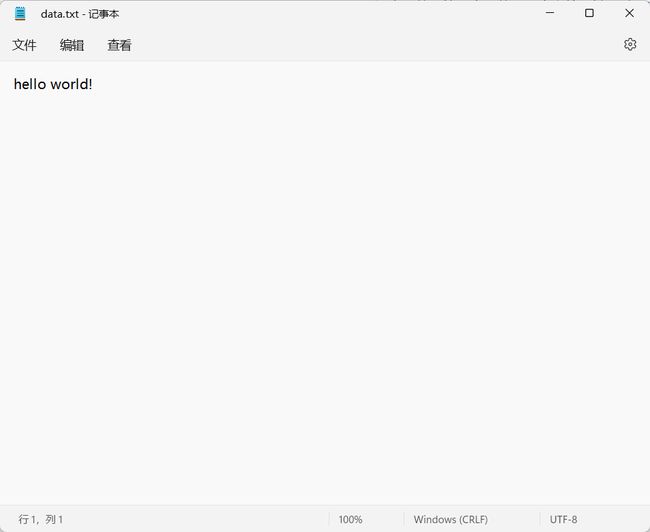

通过监视窗口观察,可以看出在fgets函数第二个参数输入4,实际只读到3个字符,第4个字符是fgets函数补上的’\0’。
//代码实现2
#include 结果演示:

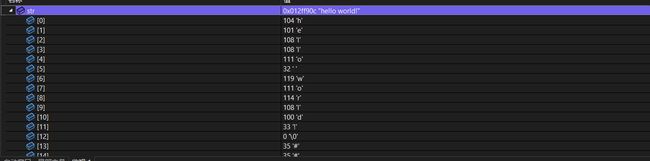
观察监视窗口,看str字符串存储的数据变化我么可知,如果在fets函数中输入大于文件一行内含有的字符串数,fets会把文件内一行所有的字符存在str字符串中并补上一个’\0’。
//代码实现3
#include 结果演示:
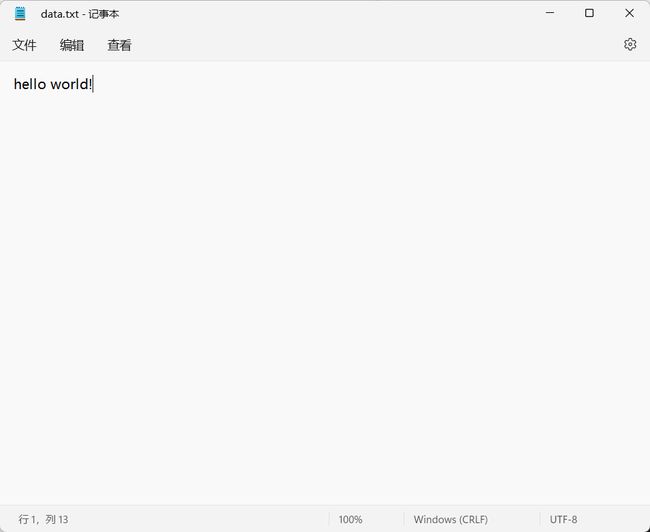
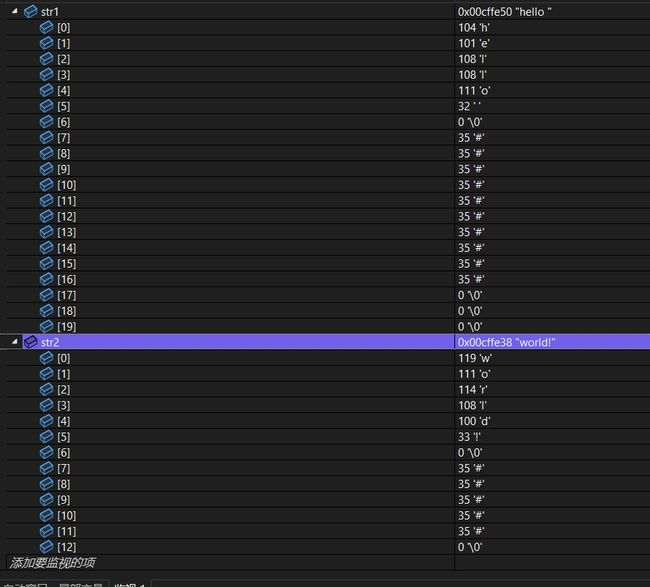
通过监视窗口观察str1字符串和str2字符串,我么发现如果第一次使用fgets函数读取一行未读完,第二次调用还会继续上次没读完的位置开始读取。
如果读取成功返回存放读取到的数据的地址,如果读取失败返回NULL。
4.2.5.fprintf
观察上面的表格我们发现fprintf函数是格式化输出函数,什么是格式化输出?关于这个问题,我么可以拿和fprintf函数很相似的函数printf对比观察


我们观察printf和fprintf的函数声明我们发现printf和fprintf函数参数只是差了一个存放文件信息的结构体的指针参数,因此我们可以想到
fprintf和printf的使用上只是多了一个调用文件的操作。
//代码实现
#include 结果演示:

4.2.6.fscanf
通过分析fprintf函数,我们可以想到fscanf大概率也是scanf类似的,因此我们观察scnaf和fscanf的函数声明。
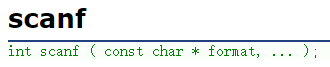

果然,fscanf和scanf函数的参数也只是差了一个存储文件信息的结构体的指针,因此我们对fscanf的使用可以仿照scanf函数。
//代码实现
#include 结果演示:

读取成功返回读取的格式化数据的个数,读取失败返回小于格式化数据的个数的值。
关于输入输出流的补充说明
我们观察上面表格时,我们会发现最后一栏的适用于写着所有输入(输出)流,实际上我们观察前面任意的文件读写函数的函数声明

比如fsacnf第一个参数为FILE* 类型,变量名为stream,这样起名是因为FILE*类型也被称作文件流,关于这个流的问题我们还需要再观察fscanf函数和scanf函数。


我们之前就发现两个函数之间只差了一个文件流的参数,难道scanf函数的调用不需要使用像文件流这样的参数吗?
实则不然,当一个c语言程序运行的时候会默认打开三个流:
stdin :标准输入流—键盘
stdout:标准输出流—屏幕
strerr:标准错误流—屏幕
实际以上三个流都是FILE类型的,用文件流的方式操作把数据和键盘、屏幕两个外部设备联系起来。
scanf正是在调用时使用了标准输入流,才能够从键盘这个外部设备向内存输入数据的。
printf也是调用了标准输出流,才能够从内存向屏幕这个外部设备输出数据的。
因此如果fscanf第一个参数是标准输入流,他的作用会和scanf函数一样。
同理,fprintf第一个参数是标准输出流,他的作用回合printf函数一样。
包括表格内使用所有输入(输出)流的函数也是同理。
//代码实例
#include 结果演示:
4.2.7.fwrite
观察上面的表格,我们发现fwrite函数是进行二进制输出函数,因此他向文件中输出的数据是二进制形式的。

观察函数声明,我们发现fwrite函数的调用需要四个参数,第一个参数是要输出的数据类型的指针,第二个参数是要输出的数据类型的大小,第三个参数是要输出的数据的个数,第四个参数是存储文件信息的结构体的指针。
//代码实现
#include 结果演示:
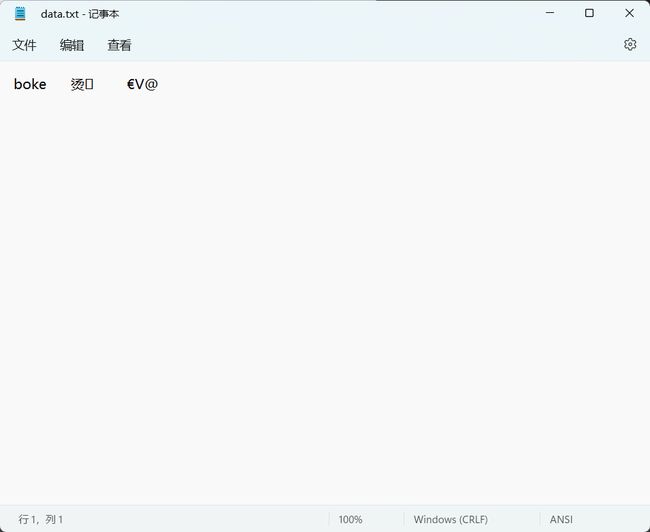
值得注意的是,由二进制形式写入的数据通过文本文档观察可能是看不懂的乱码。
4.2.8.fread
和fwrite函数一样fread函数是以二进制的形式读取数据。

观察fread函数的函数声明,fread函数的调用需要四个参数,第一个参数是从文件中读取的数据在内存中存储的变量的指针,
第二个参数是读取的数据的大小,第三个参数是读取的数据的个数,第四个参数是存储文件信息的结构体的指针。
//代码实现
struct S
{
char name[10];
int age;
double score;
};
int main()
{
FILE* pf = fopen("data.txt", "rb");
if (NULL == pf)
{
perror("fopen");
return 1;
}
struct S s = { 0 };
fread(&s, sizeof(struct S), 1, pf);
printf("%s %d %.2f", s.name, s.age, s.score);
fclose(pf);
pf = NULL;
return 0;
}
结果演示:

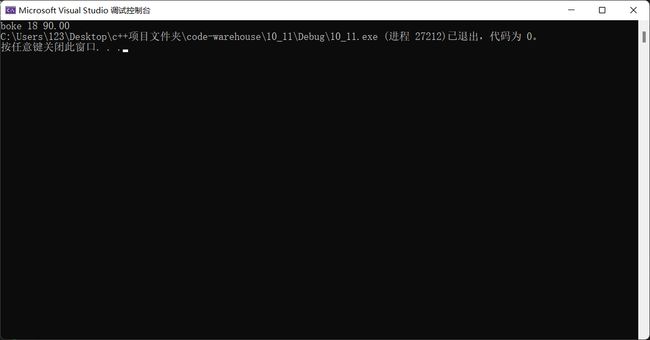
虽然二进制形式存储的数据在文本文档中是乱码,但按照二进制形式读取时不会出现任何问题。
读取成功返回要求读取的元素个数,读取失败返回小于要求读取元素个数的值。
对比一组函数
scanf/fscanf/sscanf
printf/fprintf/sprintf
scanf:按照一定的格式从键盘输入数据
printf:按照一定的格式输出数据到屏幕
//适用于标准输入(输出)流
fscanf:按照一定格式从输入流(文件流/stdin)输入数据
fprintf:按照一定的格式从输出流(文件流/stdout)输出数据
//适用于所有输入(输出)流的格式化输入/输出
sscanf:从字符串按照一定的格式读取出格式化数据
sprintf:把格式化的数据按照一定格式转化为字符串


//代码实现
#include 结果演示:
//代码实现
#include 结果演示:

5.文件的随机读写
用文件顺序读写函数进行输入输出数据都是根据之前读取或写入后指向文件偏移位置的指针指向的位置往后以此读取或写入(每读取一个字符文件指针向后移动一位),为了实现随机读写我们可以使用以下函数。
5.1.fseek

观察fseek的函数声明我们可以知道,fseek函数的调用需要三个参数,第一个参数是文件流,第二个参数是是相对后一个参数的偏移量,
第三个参数有三个数值可供使用。
SEEK_SET:文件起始位置
SEEK_CUR:文件当前位置、
SEEK_END:文件末尾位置
//代码实现1
#include 结果演示:


//代码实现2
#include 结果演示:
//代码实现3
#include 结果演示:

5.2.ftell

ftell函数的作用是返回一个值,这个值的含义是从文件开头,指向文件偏移位置的指针偏移了多少。
//代码实现
#include 结果演示:


5.3.rewind

rewind函数的作用是使指向文件偏移位置的指针回到文件开始的位置。
//代码实现
#include 结果演示:
6.文本文件和二进制文件
当我们向文件输出数据的时候,有时候会出现文件用文本形式打开显示的看不懂的乱码的情况,有时候是能看懂的文本形式。
实际上根据数据的组织形式,数据文件被成为文本文件和二进制文件。
数据在内存中以二进制的形式存储,如果不加任何转换的输出到外存,就是二进制文件。
实际上绝大多数文件包括程序文件等都是以二进制形式存储的。
如果数据要求在外存上以ASCII码形式存储,则需要在存储前进行转换。以ASCII码形式存储的文件就是文本文件。
让我们通过一个实例感受二进制文件和文本文件存储方式的区别。
当我们要在文件中存储数据10000:
文本文件实现:

//代码实现
#include 结果演示:

二进制文件实现:
二进制形式存储10000就是和把10000存到内存里一样的方式,也就是把10000的补码存到文件里。

//代码实现
#include 结果演示:

由于二进制存储是不加任何转换的,所以我们在文本文档查看到的是乱码。
7.文件读取结束的判定
7.1.如何判断文件是否读取结束
无论我们以何种方式读取数据,最终都可能读取结束,我们可以通过读取文件函数的返回值来判断文件是否读取结束。
fgetc
如果读取正常,会返回读取到的字符的ASCII值
如果读取失败,返回EOFfgets
如果读取正常,返回的是存放读取到的数据的地址
如果读取失败,返回的NULLfscanf
如果读取正常,返回的是格式串中指定的数据的个数
如果读取失败,返回的是小于格式串中指定的数据的个数fread
如果读取正常返回要求fread读取的数据个数
如果读取失败返回小于要求fread读取的数据个数的值
7.2 feof函数
注意feof函数不是用判断文件是否读取结束,
而是判断文件读取结束的时候,是因为读取失败结束,还是因为读到文件尾结束。
如果是因为读到文件尾结束返回真,如果是因为读取失败结束返回假。
正确使用:
文本文件形式:
#include 二进制文件形式:
#include 8.文件缓冲区
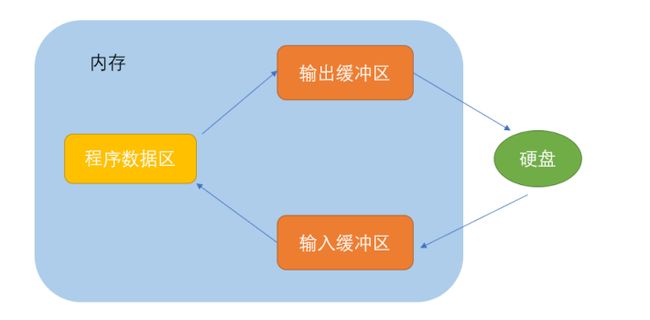
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序 中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装 满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓 冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根 据C编译系统决定的。
简单来说就是为了避免用户读取一个字符就调用操作系统向文件写入数据,造成效率很低,系统设置一个文件缓冲区,当你装满文件缓冲区时才能将数据一次性写入文件,当然缓冲区也不是只能在装满时输入,当你强制刷新缓冲区或关闭文件时,数据也会被写入文件。
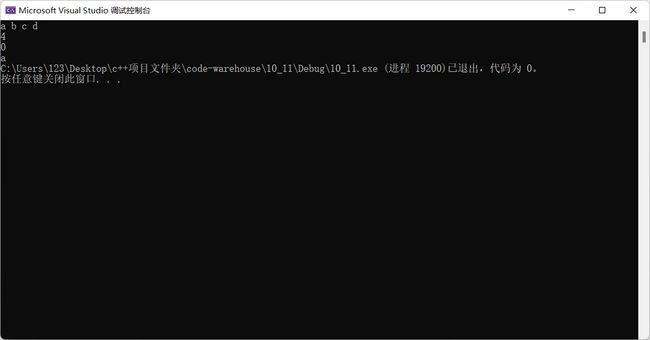
我么可以通过一个例子切实感受缓冲区的存在:
#include 结果演示:
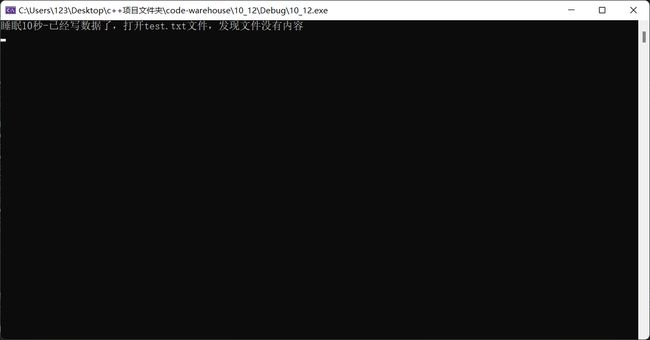




这里可以得出一个结论: 因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文 件。 如果不做,可能导致读写文件的问题。
写作不易,如有问题欢迎指正,感谢阅读。