MongoDB
MongoDB概述
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB服务端可运行在Linux、Windows平台,支持32位和64位应用,默认端口为27017。
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
MongoDB主要特点
文档
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
多个键及其关联的值有序地放在一起就构成了文档。
MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。

{“greeting”:“hello,world”}这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。
例如:{“greeting”:“hello,world”,“foo”: 3} 文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。{“foo”: 3 ,“greeting”:“hello,world”}
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
集合
集合就是一组文档,类似于关系数据库中的表。
集合是无模式的,集合中的文档可以是各式各样的。例如,{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。
但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。
例如,对于一个博客系统,可能包括blog.user和blog.article两个子集合,这样划分只是让组织结构更好一些,blog集合和blog.user、blog.article没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB推荐的方法。
数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。
一个MongoDB实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。
MongoDB中存在以下系统数据库。
- Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
- Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。
- Config 数据库:当MongoDB 使用分片模式时,config数据库在内部使用,用于保存分片的信息。
数据模型
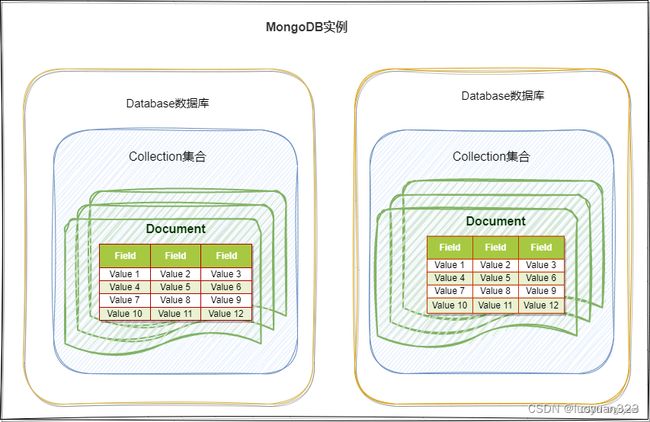
- 一个MongoDB实例可以包含一组数据库,一个DataBase可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。
- 一个Document包含一组field(字段),每一个字段都是一个key/value pair
key: 必须为字符串类型
value:可以包含如下类型
- 基本类型,例如,string,int,float,timestamp,binary 等类型
- 一个document
- 数组类型
MongoDb作为nosql数据库,它具有以下特性:
- 面向集合文档存储,适合存储json形式的数据;
- 格式自由,数据格式不固定,数据结构发生变更的同时不会影响程序运行;
- 面向对象的sql查询语句,基本涵盖关系型数据库的所有查询语句;
- 有索引的支持,查询效率更快;
- 支持复制和自动故障转移;
- 可以使用分片集群提升查询性能
针对以上的特性,我们可以在以下场景中采用mongdb数据库: - 应用不需要事务(这一条是最重要的,如果应用的事务的依赖很强,是不能选择该数据库的
- 数据模型无法确定,经常发生变更;
- 应用的qps达到2000以上;
- 应用存储的数据很大,达到TB级别以上;
- 应用需要大量的地理位置查询或者文本查询。因此mongodb使用与游戏,社交,物流,物联网,视频直播这些场景。
MongoDB基本操作及增删改查
数据库
登陆数据库
mongo
use admin
db.auth(用户名,密码)
查看数据库
show databases;
选择数据库
use 数据库名
如果切换到一个没有的数据库,例如use test1,那么会隐式创建这个数据库。(后期当该数据库有数据时,系统自动创建)
查看集合
show collections
创建集合
db.createCollection('集合名')
删除集合
db.集合名.drop()
删除数据库
通过use语法选择数据
通过db.dropDataBase()删除数据库
增删改查
增加
db.集合名.insert(JSON数据)
db.c1.insert({uname:"webopenfather",age:18})
如果集合存在,那么直接插入数据。如果集合不存在,那么会隐式创建。
- 数据库和集合不存在都隐式创建
- 对象的键统一不加引号(方便看),但是查看集合数据时系统会自动加
- mongodb会给每条数据增加一个全球唯一的_id键

_id键的组成

自己增加_id,只需要给插入的JSON数据增加_id键即可覆盖(但实战强烈不推荐)
db.c1.insert({_id:1, uname:“webopenfather”, age:18})
快速插入10条数据
由于mongodb底层使用JS引擎实现的,所以支持部分js语法。因此:可以写for循环
for (var i=1; i<=10; i++) { db.c1.insert({uanme: "a"+i, age: i}) }
查询文档
db.集合名.find(条件,查询的列)
| 条件 | 写法 |
|---|---|
| 查询所有数据 | {}或者不写 |
| 查询age=6的数据 | {age:6} |
| 查询age=6,性别=男 | {age:6,sex:‘男’} |
| 查询的列(可选参数) | 写法 |
|---|---|
| 查询全部列(字段) | 不写 |
| 只显示name列(字段) | {name:1} |
| 除了name’列(字段)都线束 | {name:0} |
只看年龄列,或者年龄以外的列

其他语法
db.集合名.find({
键:{运算符:值}
})
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
查询所有数据
db.c1.find()
查询age大于5的数据
db.c1.find({age:{$gt:5}})
查询年龄是5岁、8岁、10岁的数据
db.c2.find({age:{$in:[5,8,10]}})
修改文档
db.集合名.update(条件,新数据[是否新增,是否修改多条,])
-
修改数据需要使用修改器,如果不使用,那么会将新数据替换原来的数据。1db.集合名.update(条件,{修改器:{键:值}}[是否新增,是否修改多条,])
修改器作用inc递增rename重命名列set修改列值unset删除列 -
是否新增
指条件匹配不到数据则插入(true是插入,false否不插入默认)
db.c1.update({uname:“zs30”},{$set:{age:30}},true) -
是否修改多条
指将匹配成功的数据都修改(true是,false否默认)
db.c3.update({uname:"zs2"},{$set:{age:30}},false,true)
将{uname:“zs”}改为{uname:“zs2”}
db.c1.update({uname:"zs1"},{$set:{uname:"zs2"}})
给{uname:“zs2”}的年龄加2岁或减2岁
db.c1.update({uname:"zs2"},{$inc:{age:2}})
删除文档
db.c1.remove({uname:"zs3"})
MongoDB存储数据类型
MongoDB中每条记录称作一个文档,这个文档和我们平时用的JSON有点像,但也不完全一样。JSON是一种轻量级的数据交换格式。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,JSON易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,但是JSON也有它的局限性,比如它只有null、布尔、数字、字符串、数组和对象这几种数据类型,没有日期类型,只有一种数字类型,无法区分浮点数和整数,也没法表示正则表达式或者函数。由于这些局限性,BSON闪亮登场啦,BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型,MongoDB使用BSON做为文档数据存储和网络传输格式。
数字
shell默认使用64位浮点型数值,如下:
db.sang_collec.insert({x:3.1415926})
db.sang_collec.insert({x:3})
对于整型值,我们可以使用NumberInt或者NumberLong表示,如下:
db.sang_collec.insert({x:NumberInt(10)})
db.sang_collec.insert({x:NumberLong(12)})
字符串
db.sang_collec.insert({x:"hello MongoDB!"})
正则表达式
正则表达式主要用在查询里边,查询时我们可以使用正则表达式,语法和JavaScript中正则表达式的语法相同,比如查询所有key为x,value以hello开始的文档且不区分大小写:
db.sang_collec.find({x:/^(hello)(.[a-zA-Z0-9])+/i})
数组
db.sang_collec.insert({x:[1,2,3,4,new Date()]})
数组中的数据类型可以是多种多样的。
日期
MongoDB支持Date类型的数据,可以直接new一个Date对象,如下:
db.sang_collec.insert({x:new Date()})
内嵌文档
db.sang_collect.insert({name:"三国演义",author:{name:"罗贯中",age:99}});
MongoDB 中的索引
索引创建
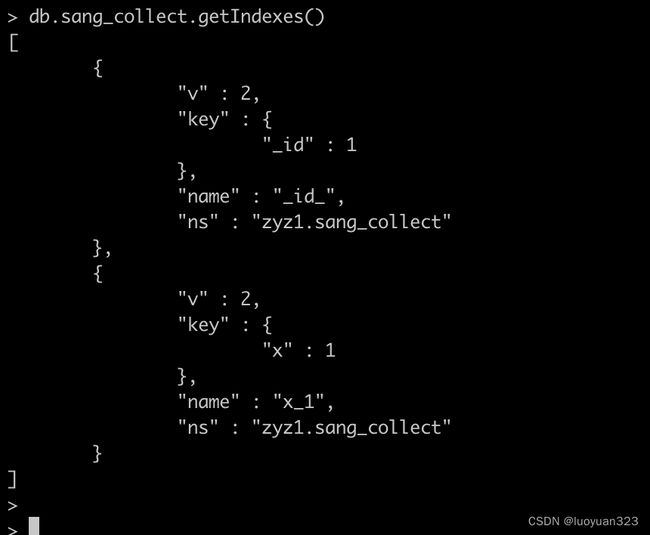
默认情况下,集合中的_id字段就是索引,我们可以通过getIndexes()方法来查看一个集合中的索引:
db.sang_collect.getIndexes()
db.sang_collect.ensureIndex({x:1})
1表示升序,-1表示降序。当我们给x字段建立索引之后,再根据x字段去查询,速度就非常快
我们看到每个索引都有一个名字,默认的索引名字为字段名_排序值,当然我们也可以在创建索引时自定义索引名字,如下:
db.sang_collect.ensureIndex({x:1},{name:"myfirstindex"})
当然索引在创建的过程中还有许多其他可选参数,如下:
db.sang_collect.ensureIndex({x:1},{name:"myfirstindex",dropDups:true,background:true,unique:true,sparse:true,v:1,weights:99999})
name表示索引的名称
dropDups表示创建唯一性索引时如果出现重复,则将重复的删除,只保留第一个
background是否在后台创建索引,在后台创建索引不影响数据库当前的操作,默认为false
unique是否创建唯一索引,默认false
sparse对文档中不存在的字段是否不起用索引,默认false
v表示索引的版本号,默认为2
weights表示索引的权重
删除索引
db.sang_collect.dropIndex("xIndex")
MongoDB之副本集配置
MongoDB主从复制
主从复制是MongoDB最早使用的复制方式, 该复制方式易于配置,并且可以支持任意数量的从节点服务器,与使用单节点模式相比有如下优点:
在从服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
可配置读写分离,主节点负责写操作,从节点负责读操作,将读写压力分开,提高系统的稳定性。
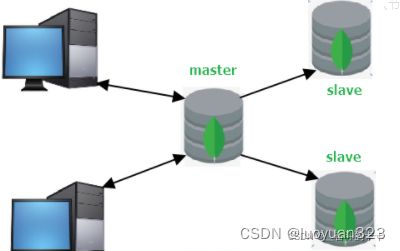
MongoDB的主从复制至少需要两个服务器或者节点。其中一个是主节点,负责处理客户端请求,其它的都是从节点,负责同步主节点的数据。
主节点记录在其上执行的所有写操作,从节点定期轮询主节点获取这些操作,然后再对自己的数据副本执行这些操作。由于和主节点执行了相同的操作,从节点就能保持与主节点的数据同步。
主节点的操作记录称为oplog(operation log),它被存储在MongoDB 的 local数据库中。oplog 中的每个文档都代表主节点上执行的一个操作。需要重点强调的是oplog只记录改变数据库状态的操作。比如,查询操作就不会被存储在oplog中。这是因为oplog只是作为从节点与主节点保持数据同步的机制。
然而,主从复制并非生产环境下推荐的复制方式,主要原因如下两点:
- 灾备都是完全人工的 如果主节点发生故障失败,管理员必须关闭一个从服务器,然后作为主节点重新启动它。然后应用程序必须重新配置连接新的主节点。
- 数据恢复困难 因为oplog只在主节点存在,故障失败需要在新的服务器上创建新的oplog,这意味着任意存在的节点需要重新从新的主节点同步oplog。
因此,在新版本的MongoDB中已经不再支持使用主从复制这种复制方式了,取而代之的是使用副本集复制方式。
MongoDB副本集
MongoDB副本集(Replica Set)其实就是具有自动故障恢复功能的主从集群,和主从复制最大的区别就是在副本集中没有固定的“主节点;整个副本集会选出一个节点作为“主节点”,当其挂掉后,再在剩下的从节点中选举一个节点成为新的“主节点”,在副本集中总有一个主节点(primary)和一个或多个备份节点(secondary)。
官方推荐的副本集最小配置需要有三个节点:一个主节点接收和处理所有的写操作,两个备份节点通过复制主节点的操作来对主节点的数据进行同步备份。
