FcaNet: Frequency Channel Attention Networks论文总结和代码详解
论文:https://arxiv.org/abs/2012.11879
中文版:FcaNet: Frequency Channel Attention Networks
源码:https://github.com/cfzd/FcaNet或https://gitee.com/yasuo_hao/FcaNet
目录
一、论文背景和出发点
二、创新点
三、离散余弦变换(DCT)和通道注意力
四、Multi-Spectral Channel Attention的具体实现
五、频率分量的选择标准
六、Multi-Spectral Channel Attention代码实现
七、实验
八、总结
一、论文背景和出发点
问题:许多工作都集中在如何设计高效的通道注意机制上,而忽略了一个基本问题,即由于大量的信息丢失,通道注意机制使用标量来表示通道会很困难。(传统的GAP操作,即“平均”操作会极大的抑制特征的多样性,而且会造成大量信息的丢失。)
出发点:在这项工作中,我们从不同的角度出发,将信道表示问题视为使用频率分析的压缩过程。基于频率分析,我们从数学上证明了传统的全局平均池是频域特征分解的一个特例。(为使用离散余弦变换压缩信道提供了可能性。)
有了这些证明,我们自然地推广了信道注意机制在频域中的压缩,并提出了我们的多谱信道注意方法,称为FcaNet。(传统的GAP操作压缩通道的效果不好,因此作者提出使用离散余弦变换(DCT)来压缩信道。)
简单地来说,作者将通道注意力视为一个压缩问题,传统的方式使用全局平均化池会造成大量信息丢失,所以作者建议在信道注意力机制中使用离散余弦变换(DCT)来压缩通道。
二、创新点
1. 证明了传统GAP(全局平均化池)是DCT(离散余弦变换)的特例。
2. 提出了三种频率分量选择标准以及建议的多光谱信道注意力框架,以实现FcaNet。
3. 大量实验表明,该方法在ImageNet和COCO数据集上都取得了最先进的结果,计算成本与SENet相同。在ImageNet数据集上的结果,如下图所示:

三、离散余弦变换(DCT)和通道注意力
1. 离散余弦变换DCT
作用:
(1)2维DCT的基函数

(2)2维DCT
DCT变换就是将原图像和DCT基函数进行内积运算。
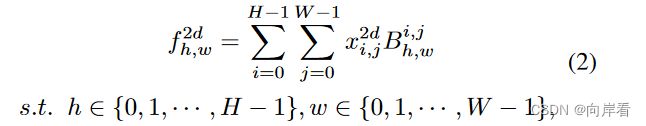
其中![]() 是
是![]() 的2D DCT频谱,
的2D DCT频谱,![]() 是输入图像,
是输入图像, 是
是![]() 的高度,
的高度, 是
是![]() 的宽度,
的宽度,![]() 是2维DCT的基函数,
是2维DCT的基函数, ∈ { 0, 1, · · · , H−1 },
∈ { 0, 1, · · · , H−1 }, ∈ { 0, 1, · · · , W−1 }。
∈ { 0, 1, · · · , W−1 }。
(3)逆2维DCT
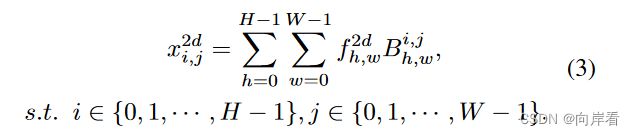
2. 通道注意力
传统方式的阐述,以SE模块为例。
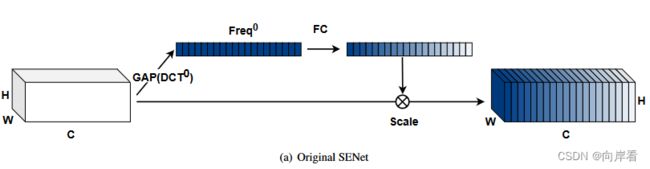
(1)注意力向量

其中,![]() 是注意力向量,sigmoid是sigmoid函数,
是注意力向量,sigmoid是sigmoid函数,![]() 代表映射函数,如全连接层或一维卷积,
代表映射函数,如全连接层或一维卷积,![]() 是一种压缩方法(SE模块中使用全局平均池化GAP)。详情可参考:SENet的Squeeze操作和Excitation操作。
是一种压缩方法(SE模块中使用全局平均池化GAP)。详情可参考:SENet的Squeeze操作和Excitation操作。
(2)缩放
在获得所有通道的注意力向量后,输入X的每个通道按相应的注意力值进行缩放:
![]()
其中,X̃是注意力机制的输出,![]() 是注意力向量的第i个元素,
是注意力向量的第i个元素,![]() 是输入图像的第i个通道。详情可参考:SENet的Scale操作。
是输入图像的第i个通道。详情可参考:SENet的Scale操作。
3. 证明:GAP是2D-DCT的特例
将2维DCT公式中的h和w都置为0,得到:
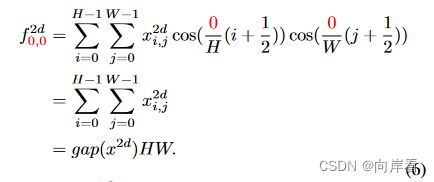
![]() 表示最低频率分量与gap函数成正比,由上式可见,gap函数是2维DCT的一种特例。
表示最低频率分量与gap函数成正比,由上式可见,gap函数是2维DCT的一种特例。
结论:在信道注意机制中使用GAP意味着只保留最低频率的信息。
推广:除了低频信息以外,其他频率的所有分量也表示信道的有用信息不应被遗弃,所以作者提出在注意力机制中将GAP推广到2D DCT,并用2D DCT的多个频率分量压缩更多信息。
四、Multi-Spectral Channel Attention的具体实现
多光谱通道注意力模块,如下图所示:

1. 分割
沿通道维度方向将输入 分成
分成![]() 。
。
其中,![]() ,通道数C被分为了n份。
,通道数C被分为了n份。
2. 压缩
对于每个 ,分配相应的2D-DCT频率分量用作每个的压缩,得到的
,分配相应的2D-DCT频率分量用作每个的压缩,得到的![]() 构成通道注意力的各个分量。
构成通道注意力的各个分量。
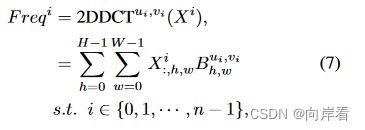
其中,![]() 是对应于
是对应于![]() 的频率分量2维指数,
的频率分量2维指数,![]() 是压缩后的C'维向量。
是压缩后的C'维向量。
3. 拼接
对每个![]() 进行拼接操作,得到多光谱向量。
进行拼接操作,得到多光谱向量。
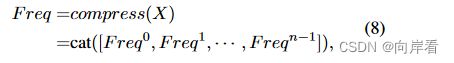
其中,![]() 是获得的多光谱向量。
是获得的多光谱向量。
4. 多光谱通道注意力
为了获取通道注意力,多光谱向量还要经过全连接层和sigmoid处理。整个多光谱通道注意力框架可以表示为:
![]()
获取到通道注意力之后的步骤与SEnet基本一致。
五、频率分量的选择标准
如何为每个选择频率分量指数![]() 是一个重要问题,作者提出了三个选择标准。
是一个重要问题,作者提出了三个选择标准。
1. FcaNet LF(低频)
只选择低频分量。
2. FcaNet TS(两步选择)
第一步:分别评估通道注意力中每个频率分量的结果。
第二步:根据评估结果,我们选择了性能最高的Top-k频率分量。
3. FcaNet NAS(神经结构搜索)
使用神经结构搜索来搜索信道的最佳频率分量。
对于每个,将一组连续变量![]() 配给搜索组件。该的频率分量可以表示为:
配给搜索组件。该的频率分量可以表示为:

其中O是包含所有2D DCT频率分量索引的集合。训练后,的频率分量等于![]() 中的最大值。
中的最大值。
六、Multi-Spectral Channel Attention代码实现

步骤:
1. 先选择标准频率分量,主要是获取频率分量对应的h、w,源码中使用mapper_x,mapper_y表示。
def get_freq_indices(method):
assert method in ['top1','top2','top4','top8','top16','top32',
'bot1','bot2','bot4','bot8','bot16','bot32',
'low1','low2','low4','low8','low16','low32']
num_freq = int(method[3:])
if 'top' in method:
all_top_indices_x = [0,0,6,0,0,1,1,4,5,1,3,0,0,0,3,2,4,6,3,5,5,2,6,5,5,3,3,4,2,2,6,1]
all_top_indices_y = [0,1,0,5,2,0,2,0,0,6,0,4,6,3,5,2,6,3,3,3,5,1,1,2,4,2,1,1,3,0,5,3]
mapper_x = all_top_indices_x[:num_freq]
mapper_y = all_top_indices_y[:num_freq]
elif 'low' in method:
all_low_indices_x = [0,0,1,1,0,2,2,1,2,0,3,4,0,1,3,0,1,2,3,4,5,0,1,2,3,4,5,6,1,2,3,4]
all_low_indices_y = [0,1,0,1,2,0,1,2,2,3,0,0,4,3,1,5,4,3,2,1,0,6,5,4,3,2,1,0,6,5,4,3]
mapper_x = all_low_indices_x[:num_freq]
mapper_y = all_low_indices_y[:num_freq]
elif 'bot' in method:
all_bot_indices_x = [6,1,3,3,2,4,1,2,4,4,5,1,4,6,2,5,6,1,6,2,2,4,3,3,5,5,6,2,5,5,3,6]
all_bot_indices_y = [6,4,4,6,6,3,1,4,4,5,6,5,2,2,5,1,4,3,5,0,3,1,1,2,4,2,1,1,5,3,3,3]
mapper_x = all_bot_indices_x[:num_freq]
mapper_y = all_bot_indices_y[:num_freq]
else:
raise NotImplementedError
return mapper_x, mapper_y
2. 参考数学公式,构建dct波滤器。
源码如下:
def build_filter(self, pos, freq, POS):
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS)
if freq == 0:
return result
else:
return result * math.sqrt(2)
def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y, channel):
dct_filter = torch.zeros(channel, tile_size_x, tile_size_y)
c_part = channel // len(mapper_x)
for i, (u_x, v_y) in enumerate(zip(mapper_x, mapper_y)):
for t_x in range(tile_size_x):
for t_y in range(tile_size_y):
# 构建DCT滤波器,对应数学公式
dct_filter[i * c_part: (i+1)*c_part, t_x, t_y] = self.build_filter(t_x, u_x, tile_size_x) * self.build_filter(t_y, v_y, tile_size_y)
return dct_filter
3. dct波滤器与输入图像进行点乘,注意这里的dct波滤器是一组波滤器,与输入图像进行点乘,实际上是每一个与其对应的dct波滤器进行点乘,再经过torch.sum(x, dim=[2,3])消去的H、W,完成![]() 的压缩过程,即可得到的2D DCT频谱,即多光谱向量。
的压缩过程,即可得到的2D DCT频谱,即多光谱向量。
源码如下:
class MultiSpectralDCTLayer(nn.Module):
"""
Generate dct filters
"""
def __init__(self, height, width, mapper_x, mapper_y, channel):
super(MultiSpectralDCTLayer, self).__init__()
assert len(mapper_x) == len(mapper_y)
assert channel % len(mapper_x) == 0
self.num_freq = len(mapper_x)
# fixed DCT init
# 返回一组DCT滤波器
self.register_buffer('weight', self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# fixed random init
# self.register_buffer('weight', torch.rand(channel, height, width))
# learnable DCT init
# self.register_parameter('weight', self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# learnable random init
# self.register_parameter('weight', torch.rand(channel, height, width))
# num_freq, h, w
def forward(self, x):
assert len(x.shape) == 4, 'x must been 4 dimensions, but got ' + str(len(x.shape))
# n, c, h, w = x.shape
# DCT变换
# x与DCT滤波器内积
x = x * self.weight
# 消去x的2,3维
result = torch.sum(x, dim=[2,3])
return result
4. 的多光谱向量,再经过全连接层 + relu激活 + 全连接层 + sigmoid激活,最终可得到一个通道注意力向量。通道注意力向量与原图像x相乘,进行重新加权。
![]()
源码如下:
class MultiSpectralAttentionLayer(torch.nn.Module):
def __init__(self, channel, dct_h, dct_w, reduction = 16, freq_sel_method = 'top16'):
super(MultiSpectralAttentionLayer, self).__init__()
self.reduction = reduction
self.dct_h = dct_h
self.dct_w = dct_w
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
self.num_split = len(mapper_x)
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y]
# make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
# 返回x的多光谱向量
self.dct_layer = MultiSpectralDCTLayer(dct_h, dct_w, mapper_x, mapper_y, channel)
# 全连接层 + relu激活 + 全连接层 + sigmoid激活,返回一个通道注意力向量
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
n,c,h,w = x.shape
x_pooled = x
if h != self.dct_h or w != self.dct_w:
x_pooled = torch.nn.functional.adaptive_avg_pool2d(x, (self.dct_h, self.dct_w))
# If you have concerns about one-line-change, don't worry. :)
# In the ImageNet models, this line will never be triggered.
# This is for compatibility in instance segmentation and object detection.
y = self.dct_layer(x_pooled)
y = self.fc(y).view(n, c, 1, 1)
# 通道注意力向量与原图像x相乘
return x * y.expand_as(x)
这篇博文有部分代码的详细注解:FcaNet从频域角度重新思考CV注意力机制
七、实验
数据集:ImageNet,COCO数据集。
网络:ResNet-34、ResNet-50、ResNet-101和ResNet-152。
1. 在ImageNet上不同注意力方法的比较
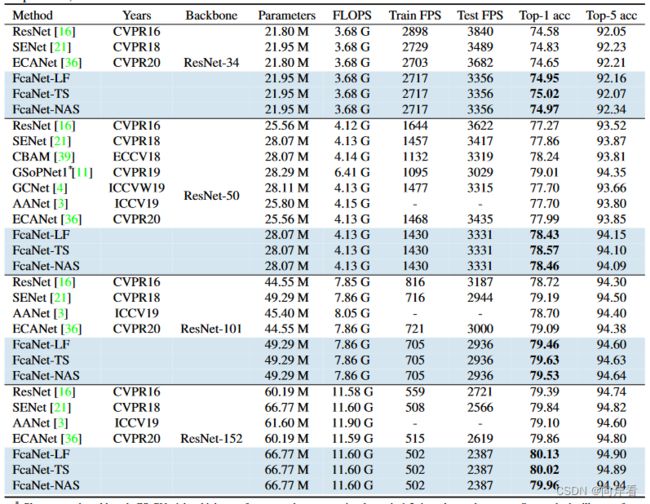
在相同的计算成本下,FcaNet优于对比的不同注意力方法。
2. 在CoCo上不同注意力方法的比较
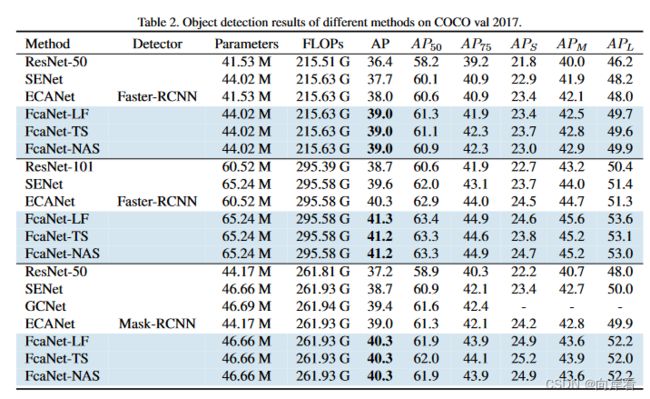
在不同的数据集上,FcaNet依然优于对比的不同注意力方法。
八、总结
在本文中,研究了通道注意力的一个基本问题,即如何表示通道,并将此问题视为一个压缩过程。证明了GAP是DCT的一个特例,并提出了具有多谱注意力模块的FcaNet,它在频域上推广了现有的信道注意力机制。同时,在多谱框架中探索了频率分量的不同组合,并提出了频率分量选择的三个标准。在相同数量的参数和计算成本的情况下,本文提出的方法可以始终优于SENet。与其他通道注意力方法相比,我们在图像分类、对象检测和实例分割方面也取得了最先进的性能。此外,FcaNet简单而有效。本文提出的方法可以在现有信道注意力方法的基础上,只需更改几行代码即可实现。