cuda+Opencv学习7
7.1
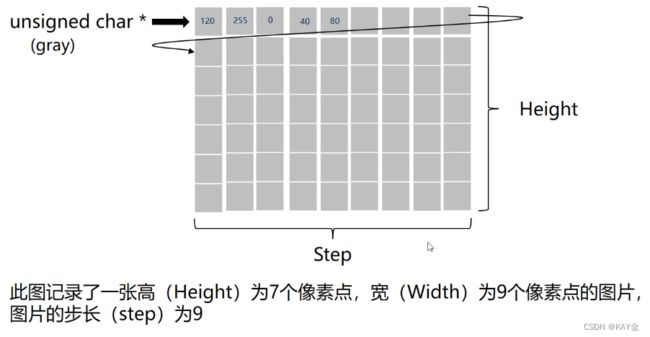
图片以unsigned char*指针存储图片的信息。
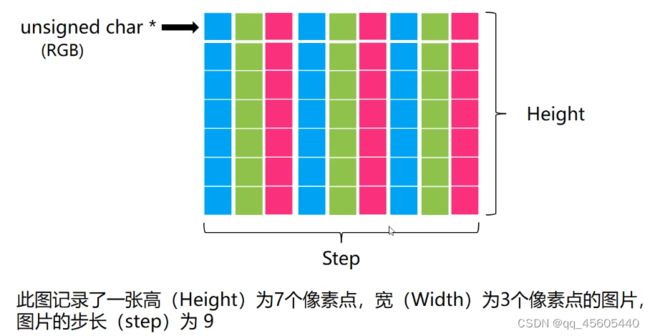 opencv中按照BGR存储
opencv中按照BGR存储
有一部分计算机在储存图片时,一行的信息会以4byte的整数倍为终结,然后记录下一行信息,这时候如果一行的像素点不是4的倍数,就会补到4的倍数。

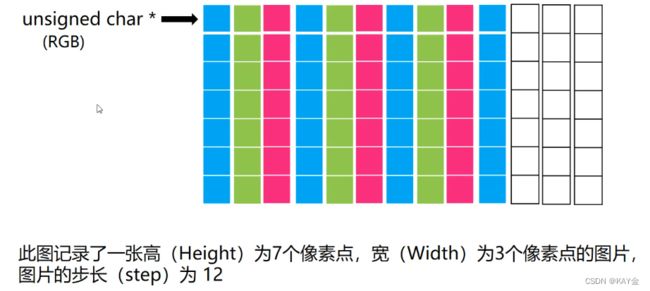
在Opencv中有几个常用的图片属性:

7.2 BGR图转灰度图
有对应公式:Gray = 0.114*blue+0.587*green+0.299*red;
0.299+0.144+0.587 =1,所以灰度图的像素值不会超过255。
若用opencv直接实现图片的灰度化直接用函数:cvtColor(原图,新图,COLOR_BGR2GRAY);
若用GPU去实现,则需要编写GPU端的函数。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
#define TILE 16
__global__ void bgr2grey_kernel(unsigned char* Src, unsigned char* Dst, int Width, int Height, int stride_src, int stride_dst) {
// 彩色图转灰度图
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int channels = stride_src / Width;
if (x < Width && y < Height) {
if (channels == 1) Dst[y * stride_dst + x] = Src[y * stride_src + x];
if (channels == 3) Dst[y * stride_dst + x] = Src[y * stride_src + 3 * x + 0] * 0.114 + Src[y * stride_src + 3 * x + 1] * 0.587 + Src[y * stride_src + 3 * x + 2] * 0.299;
}
}
int main() {
Mat frame = imread("F:\\图片\\QQ图片20221201202602.jpg");
cout << frame.cols << ends << frame.rows << ends << static_cast(frame.step) << endl;
// 图片灰度化
Mat grey, grey_gpu(frame.rows, frame.cols, CV_8UC1);
cvtColor(frame, grey, COLOR_BGR2GRAY);
unsigned char* Src, * Dst;
cudaMalloc((void**)&Src, static_cast(frame.step) * frame.rows * sizeof(unsigned char));
cudaMalloc((void**)&Dst, static_cast(grey_gpu.step) * grey_gpu.rows * sizeof(unsigned char));
dim3 blockdim(TILE, TILE);
//16*16的线程块
dim3 griddim((grey_gpu.cols + TILE - 1) / TILE, (grey_gpu.rows + TILE - 1) / TILE);
//除法可能会导致向下取整,所以将grey_gpu.cols/TILE改为grey_gpu.cols + TILE - 1) / TILE
cudaMemcpy(Src, frame.data, static_cast(frame.step) * frame.rows * sizeof(unsigned char), cudaMemcpyHostToDevice);
bgr2grey_kernel << > > (Src, Dst, frame.cols, frame.rows, static_cast(frame.step), static_cast(grey_gpu.step));
cudaMemcpy(grey_gpu.data, Dst, static_cast(grey_gpu.step) * grey_gpu.rows * sizeof(unsigned char), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
cudaFree(Src);
cudaFree(Dst);
imshow("ori", frame);
imshow("grey", grey);
imshow("grey_gpu", grey_gpu);
waitKey(0);
return 0;
} 7.3 图片的拉伸
使用双线性插值,实现图片的大小拉伸。
原理:
1.先把resize的点映射到原图的对应点;

2.由于是resize,所以映射到的点坐标很有可能带有小数,即它在原点的对应点的坐标,会被4个点所包围,如下图的点P(4个Q为原图包围P点的4个点)。
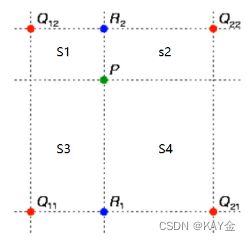
3.计算P分割出的4个矩形的面积;
4、对每个Q取它对面的矩形的面积作为权重(原因:离P越近的点,它应该获得的权重越大,而
它与P组成的矩形的面积会越小,反而它对角的矩形会越大,所以取对角的矩形面积作为权重)
最后公式为:设S = s1 + s2 + s3 + s4。P= Q12*(s4/S) + Q22*(s3/S)+ Q12*(s2/S)+ Q21*(s1/S)。
若用opencv直接实现图片的灰度化直接用函数:resize(原图,新图,Size s);//Size s(width,height);
若用GPU去实现,则需要编写GPU端的函数。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
#define TILE 16
__global__ void bgr2rgb_kernel(unsigned char* Src, unsigned char* Dst, int Width, int Height, int stride_src, int stride_dst) {
// bgr图转rgb图
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int channels = stride_src / Width;
if (x < Width && y < Height) {
if (channels == 1) Dst[y * stride_dst + x] = Src[y * stride_src + x];
if (channels == 3)
{
Dst[y * stride_src + 3 * x + 0] = Src[y * stride_src + 3 * x + 2];
Dst[y * stride_src + 3 * x + 2]= Src[y * stride_src + 3 * x +0];
}
}
}
__global__ void resize_kernel(unsigned char* Src, unsigned char* Dst, int SrcW, int SrcH, int SrcS, int DstW, int DstH, int DstS) {
// 图片拉伸
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int z = blockIdx.z;//通道几
//原图对应的点
float srcx = (float)x * (SrcW - 1) / (DstW - 1);
float srcy = (float)y * (SrcH - 1) / (DstH - 1);
int src_channels = SrcS / SrcW;
int dst_channels = DstS / DstW;
if (src_channels == dst_channels) {
if (x < DstW && y < DstH && z < dst_channels) {
float l_ratio = srcx - (int)srcx;
float r_ratio = 1 - l_ratio;
float t_ratio = srcy - (int)srcy;
float b_ratio = 1 - t_ratio;
Dst[y * DstS + dst_channels * x + z] = r_ratio * b_ratio * Src[(int)srcy * SrcS + src_channels * (int)srcx + z]
+ l_ratio * b_ratio * Src[(int)srcy * SrcS + src_channels * ((int)srcx + 1) + z]
+ r_ratio * t_ratio * Src[((int)srcy + 1) * SrcS + src_channels * (int)srcx + z]
+ l_ratio * t_ratio * Src[((int)srcy + 1) * SrcS + src_channels * ((int)srcx + 1) + z];
}
}
}
int main() {
Mat frame = imread("F:\\图片\\QQ图片20221201202602.jpg");
cout << frame.cols << ends << frame.rows << ends << static_cast(frame.step) << endl;
int Width = 5000, Height = 3000;//拉伸后的图片尺寸
Mat resize_gpu(Height, Width, CV_8UC3);
unsigned char* Src, * Dst;
cudaMalloc((void**)&Src, static_cast(frame.step) * frame.rows * sizeof(unsigned char));
cudaMalloc((void**)&Dst, static_cast(resize_gpu.step) * resize_gpu.rows * sizeof(unsigned char));
dim3 blockdim(TILE, TILE);
dim3 griddim((resize_gpu.cols + TILE - 1) / TILE, (resize_gpu.rows + TILE - 1) / TILE, frame.channels());
cudaMemcpy(Src, frame.data, static_cast(frame.step) * frame.rows * sizeof(unsigned char), cudaMemcpyHostToDevice);
resize_kernel << > > (Src, Dst, frame.cols, frame.rows, static_cast(frame.step), resize_gpu.cols, resize_gpu.rows, static_cast(resize_gpu.step));
cudaMemcpy(resize_gpu.data, Dst, static_cast(resize_gpu.step) * resize_gpu.rows * sizeof(unsigned char), cudaMemcpyDeviceToHost);
cudaFree(Src);
cudaFree(Dst);
imshow("ori", frame);
imshow("resize_gpu", resize_gpu);
waitKey(0);
return 0;
} 7.4 图片的直方图均衡
亮度直方图能够增加对比度。步骤:
1.统计图片各个通道的灰度直方图
⒉.利用公式:设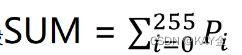 (Pi是灰度值为i的点的个数)求出总点数
(Pi是灰度值为i的点的个数)求出总点数
3.进行直方图变换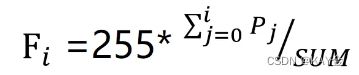
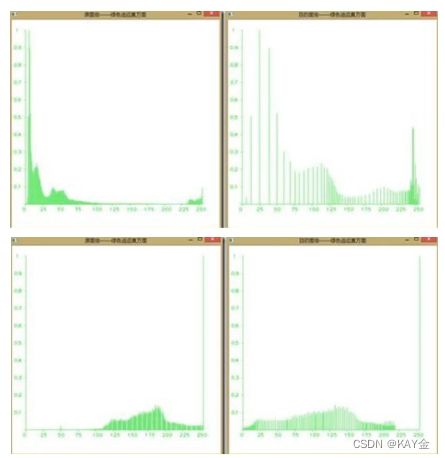
若用opencv直接实现图片的灰度化直接用函数:
vector
split(原图,bgr_channels);
for(ing i=0;i<原图.channels();i++) equalizeHist(bgr_channels[i],bgr_channels[i]);
merge(bgr_channels,新图);
若用GPU去实现,则需要编写GPU端的函数。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
#define TILE 16
__global__ void hist_cal_kernel(unsigned char* Src, int* hist, int Width, int Height, int Stride) {
// 各通道直方图统计
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int z = blockIdx.z;
extern __shared__ int hist_S[];//动态共享内存
int channels = Stride / Width;
int tid = threadIdx.y * blockDim.x + threadIdx.x;
hist_S[tid] = 0;
__syncthreads();
if (x < Width && y < Height && z < channels) {
int value = Src[y * Stride + channels * x + z];
atomicAdd(&hist_S[value], 1);
}
__syncthreads();
atomicAdd(&hist[z * 256 + tid], hist_S[tid]);
}
__global__ void hist_trans_kernel(int* hist, int channels) {
// 直方图变换
int tid = threadIdx.y * blockDim.x + threadIdx.x;
int x = blockIdx.x;
__shared__ int hist_S[256];
hist_S[tid] = hist[x * 256 + tid];
__syncthreads();
for (int s = 128; s > 0; s >>= 1) {
if (tid < s) {
hist_S[tid] += hist_S[tid + s];
}
__syncthreads();
}
int total = hist_S[0];
if (tid == 0) {
int sum = 0;
for (int i = 0; i < 256; i++) {
sum += hist[x * 256 + i];
hist[x * 256 + i] = (int)((float)255 * sum / total);
}
}
}
__global__ void pic_trans_kernel(unsigned char* Src, unsigned char* Dst, int* hist, int Width, int Height, int Stride) {
// 直方图均衡处理
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int z = blockIdx.z;
int channels = Stride / Width;
if (x < Width && y < Height && z < channels) {
int value = Src[y * Stride + channels * x + z];
int F_value = hist[z * 256 + value];
Dst[y * Stride + channels * x + z] = F_value;
}
}
int main() {
Mat frame = imread("F:\\图片\\QQ图片20221201202602.jpg");
Mat frame_hist, frame_gpu(frame.rows, frame.cols, CV_8UC3);
unsigned char* Src, * Dst;
int * hist;
cudaMalloc((void**)&Src, static_cast(frame.step) * frame.rows * sizeof(unsigned char));
cudaMalloc((void**)&Dst, static_cast(frame_gpu.step) * frame_gpu.rows * sizeof(unsigned char));
cudaMalloc((void**)&hist, frame.channels()*256*sizeof(int));
dim3 blockdim(TILE, TILE);
dim3 griddim((frame_gpu.cols + TILE - 1) / TILE, (frame_gpu.rows + TILE - 1) / TILE, frame_gpu.channels());
cudaMemcpy(Src, frame.data, static_cast(frame.step) * frame.rows * sizeof(unsigned char), cudaMemcpyHostToDevice);
hist_cal_kernel << > > (Src, hist, frame.cols, frame.rows, static_cast(frame.step));
hist_trans_kernel << > > (hist, frame.channels());
pic_trans_kernel << < griddim, blockdim >> > (Src, Dst, hist, frame.cols, frame.rows, static_cast(frame.step));
cudaMemcpy(frame_gpu.data, Dst, static_cast(frame_gpu.step) * frame_gpu.rows * sizeof(unsigned char), cudaMemcpyDeviceToHost);
cudaFree(Src);
cudaFree(Dst);
cudaFree(hist);
imshow("ori", frame);
//imshow("CPU", dst);
imshow("frame_gpu", frame_gpu);
waitKey(0);
return 0;
}