机器学习技术(三)——机器学习实践案例总体流程
机器学习实践案例总体流程
文章目录
- 机器学习实践案例总体流程
-
- 一、引言
- 二、案例
-
- 1、决策树对鸢尾花分类
-
- 1.数据来源
- 2.数据导入及描述
- 3.数据划分与特征处理
- 4.建模预测
- 2、各类回归波士顿房价预测
-
- 1.案例数据
- 2.导入所需的包和数据集
- 3.载入数据集,查看数据属性,可视化
- 3、分割数据集,并对数据集进行预处理
- 4、利用各类回归模型,对数据集进行建模
- 5、利用网格搜索对超参数进行调节

一、引言
前面学习了一些基础知识,但还没有步入机器学习算法。通过两个案例,来掌握机器学习模型的训练与评估、机器学习模型搭建的总体流程以及特征处理、决策树模型、交叉检验、网格搜索等常用数据挖掘方法的知识。
二、案例
1、决策树对鸢尾花分类
1.数据来源
本道题目使用数据集为“iris.data”。这份数据集包含3种不同类型的鸢尾花 (Setosa, Versicolour, and Virginica) 的数据,数据形状为150x5, 五列字段分别为sepal_length(萼片长度)、sepal_width(萼片宽度)、petal_length(花瓣长度)、petal_width(花瓣宽度)、类别。
2.数据导入及描述
导入数组处理numpy、数据分析pandas模块、可视化模块matplotlib。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
导入数据集文件 “iris.data”,命名为iris_data,将5列数据列名设置为’sepal_length_cm’, ‘sepal_width_cm’, ‘petal_length_cm’, ‘petal_width_cm’, ‘class’。
iris_data = pd.read_csv('./iris.data')
iris_data.columns = ['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm', 'class']
查看(除表头外)前 5 行数据,查看数据描述信息。
iris_data.head()
iris_data.describe()
输出:
| sepal_length_cm | sepal_width_cm | petal_length_cm | petal_width_cm | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
3.数据划分与特征处理
将数据集切分为4列特征和类别,导入sklearn库中的train_test_split方法将数据集的75%作为训练集和25%作为测试集。
from sklearn.model_selection import train_test_split
all_inputs = iris_data[['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm']].values
all_classes = iris_data['class'].values
(training_inputs,testing_inputs,training_classes,testing_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wCJdleQM-1688539473388)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230703151156315.png)]
4.建模预测
导入sklearn中的DecisionTreeClassifier,构建决策树模型进行分类模型训练,并在测试集上进行评分。
from sklearn.tree import DecisionTreeClassifier
decision_tree_classifier = DecisionTreeClassifier()
decision_tree_classifier.fit(training_inputs, training_classes)
decision_tree_classifier.score(testing_inputs, testing_classes)
输出:
0.9736842105263158
导入sklearn中的cross_val_score,构建决策树模型,进行10次交叉验证,并输出评分。
from sklearn.model_selection import cross_val_score
decision_tree_classifier = DecisionTreeClassifier()
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print (cv_scores)
输出:
[1. 0.93333333 1. 0.93333333 0.93333333 0.86666667
0.93333333 1. 1. 1. ]
构建决策树模型,设置max_depth=1,进行10次交叉验证,并输出评分。
decision_tree_classifier = DecisionTreeClassifier(max_depth=1)
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print (cv_scores)
输出:
[0.66666667 0.66666667 0.66666667 0.66666667 0.66666667 0.66666667
0.66666667 0.66666667 0.66666667 0.66666667]
导入sklearn中的GridSearchCV和StratifiedKFold,构建决策树模型,对决策树模型参数进行网格搜索,设置parameter_grid = {'max_depth': [1, 2, 3, 4, 5],'max_features': [1, 2, 3, 4]},进行10次交叉验证,输出最优模型评分和最佳参数。
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
decision_tree_classifier = DecisionTreeClassifier()
parameter_grid = {'max_depth': [1, 2, 3, 4, 5],
'max_features': [1, 2, 3, 4]}
cross_validation = StratifiedKFold(n_splits=10)
grid_search = GridSearchCV(decision_tree_classifier, param_grid=parameter_grid, cv=cross_validation)
grid_search.fit(all_inputs, all_classes)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
输出:
Best score: 0.96
Best parameters: {'max_depth': 3, 'max_features': 4}

2、各类回归波士顿房价预测
由于本案例使用的数据集样本量较小,且数据来自于scikit-learn自带的开源波士顿房价数据。波士顿房价预测项目是一个简单的回归模型,通过此案例可以学会一些关于机器学习库sklearn的基本用法和一些基本的数据处理方法。
1.案例数据
该案例主要内容是进行波士顿数据集,共有13个特征,总共506条数据,每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。具体如下:
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft.的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
target:自住房的平均房价,以千美元计。
2.导入所需的包和数据集
保证下方引入的内容已经被安装。
如pip install xgboost 等
# 防止不必要的警告
import warnings
warnings.filterwarnings("ignore")
# 引入数据科学基础包
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import scipy.stats as st
import seaborn as sns
# 引入机器学习,预处理,模型选择,评估指标
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import r2_score
# 引入本次所使用的波士顿数据集
from sklearn.datasets import load_boston
# 引入算法
from sklearn.linear_model import RidgeCV, LassoCV, LinearRegression, ElasticNet
#对比SVC,是svm的回归形式
from sklearn.svm import SVR
# 集成算法
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
3.载入数据集,查看数据属性,可视化
- 载入波士顿房价数据集,获取特征和标签,查看相关属性
# 载入波士顿房价数据集
boston = load_boston()
# x是特征,y是标签
x = boston.data
y = boston.target
# 查看相关属性
print('特征的列名')
print(boston.feature_names)
print("样本数据量:%d, 特征个数:%d" % x.shape)
print("target样本数据量:%d" % y.shape[0])
输出:
特征的列名
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
样本数据量:506, 特征个数:13
target样本数据量:506
- 数据转化为dataframe形式
x = pd.DataFrame(boston.data, columns=boston.feature_names)
x.head()
输出:
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
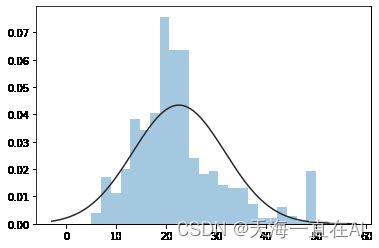
- 对标签的分布进行可视化
sns.distplot(tuple(y), kde=False, fit=st.norm)
3、分割数据集,并对数据集进行预处理
将数据分割为训练集和测试,将数据集进行标准化处理
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=28)
# 标准化数据集
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
x_train[0:100]
输出:
array([[-0.35703125, -0.49503678, -0.15692398, ..., -0.01188637,
0.42050162, -0.29153411],
[-0.39135992, -0.49503678, -0.02431196, ..., 0.35398749,
0.37314392, -0.97290358],
[ 0.5001037 , -0.49503678, 1.03804143, ..., 0.81132983,
0.4391143 , 1.18523567],
...,
[-0.34697089, -0.49503678, -0.15692398, ..., -0.01188637,
0.4391143 , -1.11086682],
[-0.39762221, 2.80452783, -0.87827504, ..., 0.35398749,
0.4391143 , -1.28120919],
[-0.38331362, 0.41234349, -0.74566303, ..., 0.30825326,
0.19472652, -0.40978832]])
4、利用各类回归模型,对数据集进行建模
- 输入模型名字
# 模型的名字
names = ['LinerRegression',
'Ridge',
'Lasso',
'Random Forrest',
'GBDT',
'Support Vector Regression',
'ElasticNet',
'XgBoost']
- 创建模型列表
# 定义模型
# cv在这里是交叉验证的思想
models = [LinearRegression(),
RidgeCV(alphas=(0.001,0.1,1),cv=3),
LassoCV(alphas=(0.001,0.1,1),cv=5),
RandomForestRegressor(n_estimators=10),
GradientBoostingRegressor(n_estimators=30),
SVR(),
ElasticNet(alpha=0.001,max_iter=10000),
XGBRegressor()]
- 输出所有回归模型的R2评分
# 先定义R2评分的函数
def R2(model,x_train, x_test, y_train, y_test):
model_fitted = model.fit(x_train,y_train)
y_pred = model_fitted.predict(x_test)
score = r2_score(y_test, y_pred)
return score
- 遍历所有模型进行评分
# 遍历所有模型进行评分
for name,model in zip(names,models):
score = R2(model,x_train, x_test, y_train, y_test)
print("{}: {:.6f}, {:.4f}".format(name,score.mean(),score.std()))
输出:
LinerRegression: 0.564115, 0.0000
Ridge: 0.563673, 0.0000
Lasso: 0.564049, 0.0000
Random Forrest: 0.735384, 0.0000
GBDT: 0.730172, 0.0000
Support Vector Regression: 0.517260, 0.0000
ElasticNet: 0.563992, 0.0000
XgBoost: 0.759977, 0.0000
5、利用网格搜索对超参数进行调节
- 使用网格搜索,以及交叉验证
# 模型构建
'''
'kernel': 核函数
'C': SVR的正则化因子,
'gamma': 'rbf', 'poly' and 'sigmoid'核函数的系数,影响模型性能
'''
parameters = {
'kernel': ['linear', 'rbf'],
'C': [0.1, 0.5,0.9,1,5],
'gamma': [0.001,0.01,0.1,1]
}
# 使用网格搜索,以及交叉验证
model = GridSearchCV(SVR(), param_grid=parameters, cv=3)
model.fit(x_train, y_train)
输出:
GridSearchCV(cv=3, estimator=SVR(),
param_grid={'C': [0.1, 0.5, 0.9, 1, 5],
'gamma': [0.001, 0.01, 0.1, 1],
'kernel': ['linear', 'rbf']})
- 获取最优参数
# 获取最优参数
print ("最优参数列表:", model.best_params_)
print ("最优模型:", model.best_estimator_)
print ("最优R2值:", model.best_score_)
输出:
最优参数列表: {'C': 5, 'gamma': 0.1, 'kernel': 'rbf'}
最优模型: SVR(C=5, gamma=0.1)
最优R2值: 0.7965173649188232
- 可视化
ln_x_test = range(len(x_test))
y_predict = model.predict(x_test)
# 设置画布
plt.figure(figsize=(16,8), facecolor='w')
# 用红实线画图
plt.plot(ln_x_test, y_test, 'r-', lw=2, label=u'真实值')
# 用绿实线画图
plt.plot(ln_x_test, y_predict, 'g-', lw = 3, label=u'SVR算法估计值,$R^2$=%.3f' % (model.best_score_))
# 图形显示
plt.legend(loc = 'upper left')
plt.grid(True)
plt.title(u"波士顿房屋价格预测(SVM)")
plt.xlim(0, 101)
plt.show()
结果
如汉字不能正常显示,请设置为英文或将字体文件放到指定路径中,在使用时调用字体文件。
如不能解决请参考:https://blog.csdn.net/hfy1237/article/details/128218567