Redis实现延迟队列的原理
略谈Redis实现延迟队列原理
- 1、初始化
-
- 1.1 生成阻塞队列
- 1.2 生成延迟队列
- 1.3 任务的执行
-
- 1.3.1 QueueTransferTask的pushTaskAsync
- 1.3.2 延迟队列任务的执行
- 2、插入数据
- 3、拉取数据
- 4、BLPOP原理
这里对Redisson的延迟队列的底层实现逻辑进行了简单的探讨,Redisson实现延迟队列主要使用了一个阻塞队列(使用了redis的list结构)和一个延迟队列(一个list结构、一个score为到期时间的zset结构,一个分布订阅的通道)。
本博客的内容包括初始化时各redis结构的初始化,定时任务的执行过程,数据如何插入,以及数据如何阻塞读取。

1、初始化
private static final String ACQUIRE_LOCK_RETRY_DQ = "test_queue";
// 阻塞队列
private static RBlockingDeque<String> blockingDeque;
// 延迟队列
private static RDelayedQueue<String> delayedQueue;
@Autowired
public void setRedissonClient(@Qualifier("defaultRedissonClient") RedissonClient redissonClient) {
blockingDeque = redissonClient.getBlockingDeque(ACQUIRE_LOCK_RETRY_DQ);
delayedQueue = redissonClient.getDelayedQueue(blockingDeque);
}
以上是初始化代码,来看一下初始化都做了什么事。
1.1 生成阻塞队列
生成阻塞队列的语句是
blockingDeque = redissonClient.getBlockingDeque(ACQUIRE_LOCK_RETRY_DQ);
getBlockingDeque方法是生成RedissonBlockingDeque,其源码如下:
public <V> RBlockingDeque<V> getBlockingDeque(String name) {
return new RedissonBlockingDeque<V>(connectionManager.getCommandExecutor(), name, this);
}
一层层往里追溯:
public RedissonObject(Codec codec, CommandAsyncExecutor commandExecutor, String name) {
this.codec = codec;
this.name = name;
this.commandExecutor = commandExecutor;
}
是实例化了一个RedissonObject对象,RedissonBlockingDeque继承RedissonBlockingDeque,RedissonBlockingDeque继承RedissonDeque,RedissonDeque继承RedissonQueue,RedissonQueue继承RedissonList,
RedissonList继承RedissonExpirable,RedissonExpirable继承RedissonObject。
不需要关注这么长的继承关系,只需要搞清楚实例化的时候干了什么就可以了,在实例化RedissonBlockingDeque的过程中,实际上就是对codec、name和commandExecutor进行赋值,codec是编码方式,commandExecutor是redis命令执行器,这里我们不需要关注,我们重点关注name的赋值,也就是说在这一步,实例化了一个 name = test_queue的阻塞队列对象。
1.2 生成延迟队列
生成延迟队列的语句是
delayedQueue = redissonClient.getDelayedQueue(blockingDeque);
这里是用了1.1中生成的阻塞队列blockingDeque作为参数生成延迟队列,其源码如下:
public <V> RDelayedQueue<V> getDelayedQueue(RQueue<V> destinationQueue) {
if (destinationQueue == null) {
throw new NullPointerException();
}
return new RedissonDelayedQueue<V>(queueTransferService, destinationQueue.getCodec(), connectionManager.getCommandExecutor(), destinationQueue.getName());
}
不难看出是生成了一个RedissonDelayedQueue对象,先看一下RedissonDelayedQueue的构造方法入参
| 参数 | 说明 |
|---|---|
| queueTransferService | protected final QueueTransferService queueTransferService = new QueueTransferService(); 这是在redisson客户端生成的队列任务调度的对象,其包含schedule方法,是后面用来启动延迟队列运行任务的 |
| codec | 编码方式,取自阻塞队列的codec,及两个队列的编码方式要一致 |
| commandExecutor | 这是从连接管理对象获取到redis命令执行器,这里不需要关注 |
| name | 这是名称,用来作为延迟队列名称的一部分 |
下面是RedissonDelayedQueue的构造方法,是需要重点分析的地方
protected RedissonDelayedQueue(QueueTransferService queueTransferService, Codec codec, final CommandAsyncExecutor commandExecutor, String name) {
// 这是父类的实例化方法,同1.1的阻塞队列,
//最后是RedissonObject的实例化方法,及对codec、name和commandExecutor进行赋值。
super(codec, commandExecutor, name);
// 通道名称,用于延迟队列的发布订阅
channelName = prefixName("redisson_delay_queue_channel", getName());
// 延迟队列名称,list结构,能够记录数据加入延迟队列的顺序
queueName = prefixName("redisson_delay_queue", getName());
// 以过期时间为score的zset延迟队列名称,按过期时间从小到大的排列
timeoutSetName = prefixName("redisson_delay_queue_timeout", getName());
// 生成QueueTransferTask对象,并重载pushTaskAsync和getTopic方法
// 用于queueTransferService执行schedule方法
// 详解见1.3
QueueTransferTask task = new QueueTransferTask(commandExecutor.getConnectionManager()) {
@Override
protected RFuture<Long> pushTaskAsync() {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_LONG,
"local expiredValues = redis.call('zrangebyscore', KEYS[2], 0, ARGV[1], 'limit', 0, ARGV[2]); "
+ "if #expiredValues > 0 then "
+ "for i, v in ipairs(expiredValues) do "
+ "local randomId, value = struct.unpack('dLc0', v);"
+ "redis.call('rpush', KEYS[1], value);"
+ "redis.call('lrem', KEYS[3], 1, v);"
+ "end; "
+ "redis.call('zrem', KEYS[2], unpack(expiredValues));"
+ "end; "
// get startTime from scheduler queue head task
+ "local v = redis.call('zrange', KEYS[2], 0, 0, 'WITHSCORES'); "
+ "if v[1] ~= nil then "
+ "return v[2]; "
+ "end "
+ "return nil;",
Arrays.<Object>asList(getName(), timeoutSetName, queueName),
System.currentTimeMillis(), 100);
}
// 获取延迟队列的发布订阅topic对象,关注channelName参数即可
@Override
protected RTopic getTopic() {
return new RedissonTopic(LongCodec.INSTANCE, commandExecutor, channelName);
}
};
// 执行延迟队列的任务
queueTransferService.schedule(queueName, task);
// 赋值
this.queueTransferService = queueTransferService;
}
1.3 任务的执行
1.3.1 QueueTransferTask的pushTaskAsync
evalWriteAsync方法属于redis执行器的执行lua脚本的方法,这里不进行原理详解。首先明确KEY[N]:evalWriteAsync入参keys列表的第N个,从1开始,ARGV[N]是指evalWriteAsync入参params的第N个,从1开始,是只下面分析lua脚本:
@Override
protected RFuture<Long> pushTaskAsync() {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_LONG,
// 获取score为[0, 当前时间戳]的timeoutSetName中的前100个数据
"local expiredValues = redis.call('zrangebyscore', KEYS[2], 0, ARGV[1], 'limit', 0, ARGV[2]); "
// 若取到值
+ "if #expiredValues > 0 then "
// 对取到的数据进行遍历
+ "for i, v in ipairs(expiredValues) do "
// 对数据进行解码
+ "local randomId, value = struct.unpack('dLc0', v);"
// 将数据放入name = test_queue的阻塞队列中
// 这里KEYS[1]的getName()就说获取name属性
// 从rpush命令可以得知,阻塞队列是list结构
+ "redis.call('rpush', KEYS[1], value);"
// 从名称为queueName的list删除第一个为v的数据
+ "redis.call('lrem', KEYS[3], 1, v);"
+ "end; "
// 从名称为timeoutSetName的zset删除取出的所有数据
+ "redis.call('zrem', KEYS[2], unpack(expiredValues));"
+ "end; "
// get startTime from scheduler queue head task
// 获取timeoutSetName的第一个元素,用于获取下一个到期的元素的时间
+ "local v = redis.call('zrange', KEYS[2], 0, 0, 'WITHSCORES'); "
+ "if v[1] ~= nil then "
// 返回下一个需要进行处理数据的时间
+ "return v[2]; "
+ "end "
+ "return nil;",
Arrays.<Object>asList(getName(), timeoutSetName, queueName),
System.currentTimeMillis(), 100);
}
从上面的lua脚本来看,pushTaskAsync的执行流程为:

总结来说就是将延迟队列中的数据取出,放到阻塞队列中
1.3.2 延迟队列任务的执行
对应的语句是:queueTransferService.schedule(queueName, task),其schedule方法的源码如下:
public synchronized void schedule(String name, QueueTransferTask task) {
// 将名为name(延迟队列的name属性)的延迟队列的QueueTransferTask 对象放入到ConcurrentHashMap中
QueueTransferTask oldTask = tasks.putIfAbsent(name, task);
if (oldTask == null) {
// 若不存在重复的任务,则开启该任务
task.start();
} else {
// 该任务已存在,则对任务计数器+1
oldTask.incUsage();
}
}
下面看schudule中最主要的方法start:
public void start() {
// 获取延迟队列的RTopic对象,getTopic已在初始化时进行的重载,可回顾1.2节
RTopic schedulerTopic = getTopic();
// 订阅的监听器,当有新的客户端订阅延迟队列的topic时执行pushTask方法
statusListenerId = schedulerTopic.addListener(new BaseStatusListener() {
@Override
public void onSubscribe(String channel) {
pushTask();
}
});
// 发布的监听器,当有消息发布时执行scheduleTask方法
messageListenerId = schedulerTopic.addListener(Long.class, new MessageListener<Long>() {
@Override
public void onMessage(CharSequence channel, Long startTime) {
// startTime即为发布消息的消息体
scheduleTask(startTime);
}
});
}
pushTask是对redis延迟队列进行操作的方法,scheduleTask是控制时间轮来调用pushTask的,同时pushTask和scheduleTask的方法也是相互调用的,下面先来看一下pushTask方法:
private void pushTask() {
// 执行pushTaskAsync,这个方法已被重载,可回顾1.3.1节
// 简单来说就就是将延迟队列的数据取出,放入阻塞队列
RFuture<Long> startTimeFuture = pushTaskAsync();
startTimeFuture.onComplete((res, e) -> {
if (e != null) {
// 未从pushTaskAsync获取到下条数据的到期时间
// 也意味着延迟队列中没有数据了
if (e instanceof RedissonShutdownException) {
return;
}
log.error(e.getMessage(), e);
// 调用scheduleTask,入参是当前时间+5s
scheduleTask(System.currentTimeMillis() + 5 * 1000L);
return;
}
if (res != null) {
// 从pushTaskAsync获取到了下条数据的到期时间
// scheduleTask为延迟队列下条数据的到期时间
// 可能大于当前时间也可能小于当前时间
scheduleTask(res);
}
});
}
在来看一下scheduleTask方法:
private final AtomicReference<TimeoutTask> lastTimeout = new AtomicReference<TimeoutTask>();
private void scheduleTask(final Long startTime) {
// 获取上一个TimeoutTask
TimeoutTask oldTimeout = lastTimeout.get();
if (startTime == null) {
return;
}
if (oldTimeout != null) {
// 若存在旧的时间任务,则停掉旧的时间轮任务
oldTimeout.getTask().cancel();
}
long delay = startTime - System.currentTimeMillis();
if (delay > 10) {
// 开始时间距离当前时间大于10ms
// 生成新的Timeout,延迟时间为delay,这里用的是HashedWheelTimeout,具体原理感兴趣的可以继续深究
// 这里只需要理解他是一个时间精度不高的任务调度器即可
Timeout timeout = connectionManager.newTimeout(new TimerTask() {
// 重载时间轮的run方法,让其到时间可执行该方法
@Override
public void run(Timeout timeout) throws Exception {
// 调用pushTask,上面已经提到
pushTask();
// 该时间轮任务已处理完,对lastTime进行处理
TimeoutTask currentTimeout = lastTimeout.get();
if (currentTimeout.getTask() == timeout) {
// 若lastTimeout仍记录当前任务则清除
lastTimeout.compareAndSet(currentTimeout, null);
}
}
}, delay, TimeUnit.MILLISECONDS);
if (!lastTimeout.compareAndSet(oldTimeout, new TimeoutTask(startTime, timeout))) {
// 将新生成的时间轮任务放到lastTime
// lastTime替换失败,说明有其他的时间轮任务也在处理,则需要将该线程新建的时间轮任务停掉
timeout.cancel();
}
} else {
// // 开始时间距离当前时间小于等于10ms,直接执行pushTask
pushTask();
}
}
总结来说,对于延迟队列的任务调度:
(1)当有新的客户端进行订阅时,立即调用pushTask拉取延迟队列的数据放入到阻塞队列,之后以调用scheduleTask进行拉取(调用pushTask)
(2)对于当有新的消息发布时,会调用scheduleTask根据发布消息的消息体(startTime)判断进行时间轮询的处理还是立即调用pushTask
通过pushTask和scheduleTask的相互调用,就能保证总有一个任务在处理或者等待处理延迟列中的数据(这里的处理是指拉取延迟队列的数据放入到阻塞队列)
以上就是redis延迟队列的初始化过程
2、插入数据
先看下插入数据的代码:
public void addMsg(String msg, long delay, TimeUnit timeUnit) {
delayedQueue.offer(msg, delay, timeUnit);
}
这里使用了RDelayedQueues的offer方法,由RedissonDelayedQueue实现,进入其源码:
@Override
public void offer(V e, long delay, TimeUnit timeUnit) {
get(offerAsync(e, delay, timeUnit));
}
get方法是对Future进行操作,这里只需要关注offerAsync方法即可:
@Override
public RFuture<Void> offerAsync(V e, long delay, TimeUnit timeUnit) {
if (delay < 0) {
throw new IllegalArgumentException("Delay can't be negative");
}
// 将延迟时间转换为时间戳
long delayInMs = timeUnit.toMillis(delay);
long timeout = System.currentTimeMillis() + delayInMs;
// 生成随机Id
long randomId = ThreadLocalRandom.current().nextLong();
//执行向延迟队列插入数据的Lua脚本
return commandExecutor.evalWriteAsync(getName(), codec, RedisCommands.EVAL_VOID,
// 将数据进行编码
"local value = struct.pack('dLc0', tonumber(ARGV[2]), string.len(ARGV[3]), ARGV[3]);" ‘’
// 将数据放到延迟队列的zset结构中
+ "redis.call('zadd', KEYS[2], ARGV[1], value);"
// 将数据放到延迟队列的list结构中
+ "redis.call('rpush', KEYS[3], value);"
// if new object added to queue head when publish its startTime
// to all scheduler workers
// 从延迟队列的zset中获取第一个数据,也就是最先到期的那个数据
+ "local v = redis.call('zrange', KEYS[2], 0, 0); "
+ "if v[1] == value then "
// 如果新插入的数据和第一个到期的数据相等,则将当前插入数据的过期时间发布出去
// 这么做的原因是新插入数据的到期时间小于当前时间能够触发消息监听器立即进行处理,减少时间差
+ "redis.call('publish', KEYS[4], ARGV[1]); "
+ "end;",
Arrays.<Object>asList(getName(), timeoutSetName, queueName, channelName),
timeout, randomId, encode(e));
}
以上,redis延迟队列的插入分为四步:
(1)数据编码
(2)将数据插入延迟队列的zset
(3)将数据插入数据的list
(4)判断是否需要发布消息,如需要则进行发布
3、拉取数据
拉取数据的代码如下:
public String getMsgSync() {
String msg;
try {
msg = blockingDeque.take();
LOGGER.info("get msg from queue: {}", msg);
return msg;
} catch (InterruptedException e) {
LOGGER.error("get msg from queue error.", e);
Thread.currentThread().interrupt();
}
return null;
}
这里使用了BlockingDeque的take方法,由RedissonBlockingDeque实现,其最终和redis交互的源码如下:
@Override
public RFuture<V> takeAsync() {
return commandExecutor.writeAsync(getName(), codec, RedisCommands.BLPOP_VALUE, getName(), 0);
}
RedisCommand<Object> BLPOP_VALUE = new RedisCommand<Object>("BLPOP", new ListObjectDecoder<Object>(1));
这里比较简单就是使用了redis的BLPOP命令从阻塞队列中进行读取
我们只需要在起一个线程循环调用getMsgSync方法就可以拉取延迟队列的数据进行业务逻辑处理了:
singleThreadExecutor.execute(() -> {
while (true) {
String msg= getMsgSync();
if (StringUtils.isNotEmpty(msg)) {
// do something...
}
}
});
以上就是Redisson实现延迟队列的原理,简单来说,将数据插入到延迟队列时,会存入到延迟队列的list和zset结构中,通过任务调度的方式将延迟队列中到期的数据取出,然后放入到阻塞队列中,客户端通过BLPOP的命令阻塞的拉取阻塞队列的数据,若拉取到数据就可以进行业务逻辑的处理。
4、BLPOP原理
(1)判断队列中有无数据,有则返回数据,否则进入(2);
(2)将无数据的队列放入到blocking_keys中,结构是hash,key是队列的所取数据队列的键值,value是被阻塞的客户端列表,阻塞客户端;
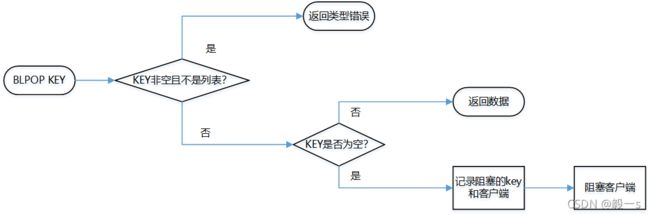
(3)当向队列中插入数据时,若该队列存在blocking_keys,将该队列key放到ready_keys中;

(4)每次redis命令执行完,都会遍历ready_keys,并从blocking_keys取出客户端进行响应。
![]()