Week2云计算从0到1学习-已脱敏
第一次接触云计算,小白打卡。熟悉公司的shell脚本,深入学习。不懂的东西就去百度。请倒叙查看文档内容,即最新的学习内容写在最上方。其他周笔记见主页其他博客,搜索关键字【云计算】
week2学习
实际操作:
1. 搭建环境的服务器
ip username passwd
已有完整的测试环境
ip2 username2 passwd2
2. 创建与搭建好的ip2服务器一样的环境
mkdir -p /xx/xx/xx/xx/storage
拷贝远程服务器文件到本机
# scp -r username@hostname://xx/storage/* /xx/storage
3. 需要把image(镜像)提前加载到对应的node上,在创建盘和pod前加载
cd /xx/storage
docker load -i centos_v3.tar.gz

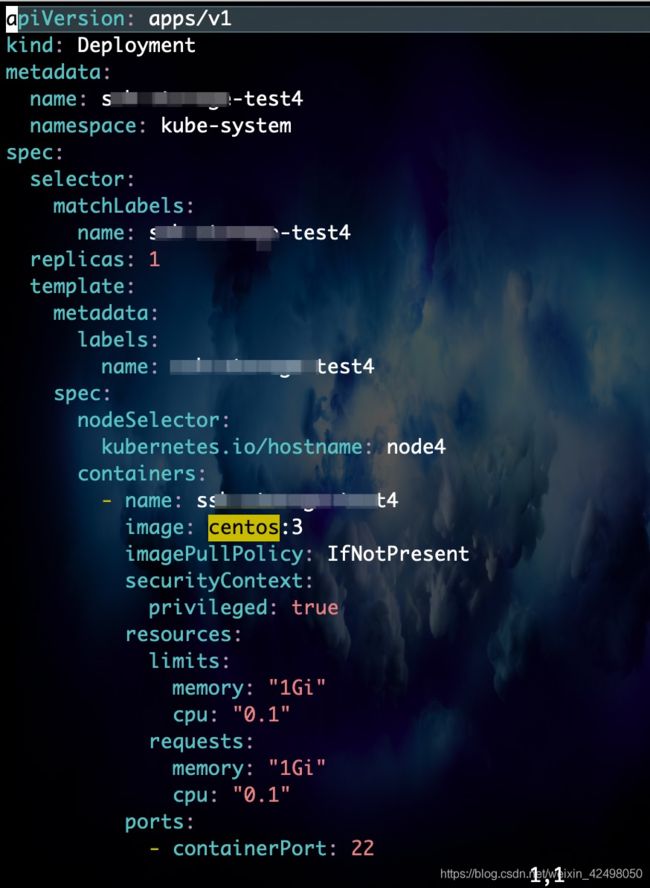
4. 拷贝盘 deployment4.yml
修改盘deployment4.yml
vim下修改文件命名 name要一致
:%s/test1/test44/g
:%s/pvc-log/pvc-log44/g
5. 拷贝pod pvc-test4.yml
修改拷贝pod pvc-test4.yml
命名与盘deployment4.yml的name一致
:%s/pvc-log1/pvc-log44
# kubectl get nodes 查看节点状态

列出Pod以及运行Pod节点信息 -A全部 all
# kubectl get pod -A -o wide|grep test

6. 创建盘
kubectl create -f pvc-test4.yml
成功后显示
persistentvolumeclaim/pvc-log44 created
如遇如图的提示pvc-log4 already exists 则需要修改配置文件的4为44
kubectl get pvc -A|grep pvc-log44 查看状态
kube-system pvc-log44 Bound pvc-脱敏 20Gi RWX managed-nfs-storage 8m30s
如遇pvc的状态为pending状态,则需要删除pvc再重新创建 kubectl delete -f xxx.yml

如遇 创建盘的时候,error: the path "\u00a0pvc-testxx.yml" does not exist。则需要
cd /var 或者到yml在的目录赋权限
chmod -R 755 *
修改权限后重新创建盘即可

延伸
查询所有名字空间的 pods
kubectl get pods --all-namespace
kubectl get pods -A # 缩写
查看pvc详情
[root@node1 ~]# kubectl describe pv pvc-5dcb2a52-7dd5-480e-85a2-c3582a009be6
7. 创建pod: kubectl create -f deployment4.yml
deployment.apps/ssh-storage-test44 created
service/ssh-storage-test44 created
kubectl get pod -A -o wide|grep test4 查看pod有没有创建成功

正常的话应为Running状态
kube-system ssh-storage-test44-xx-nqqdn 1/1 Running 0 58s
如果失败则需要排查 如此次遇到的是ImagePullBackOff状态
kube-system ssh-storage-test4-xx-xx 0/1 ImagePullBackOff 0 166m ip node4

原因:登录服务器默认的在node1上,配置文件配置的pvc node在node4上,需要ssh node4登录到node4。再把node1的镜像拷贝到node4服务器
解决:需要登录到报错pod绑定的node机器上加载镜像
哪个node报错就拷贝到哪个node下加载镜像(后来发现登录新创建的盘 pod默认的/tmp下是有镜像centos_v3.tar.gz的,这种情况不需要远程拷贝)
# scp centos_v3.tar.gz username@hostname:/tmp
拷贝完成再登录到node4 ssh node4
在node4 加载镜像 docker load -i centos_v3.tar.gz 左图
加载完成,删除原始错误状态的pod
kubectl delete pod ssh-storage-test4-587ff5896f-7hxn9 -n kube-system

如遇pod状态为Evicted
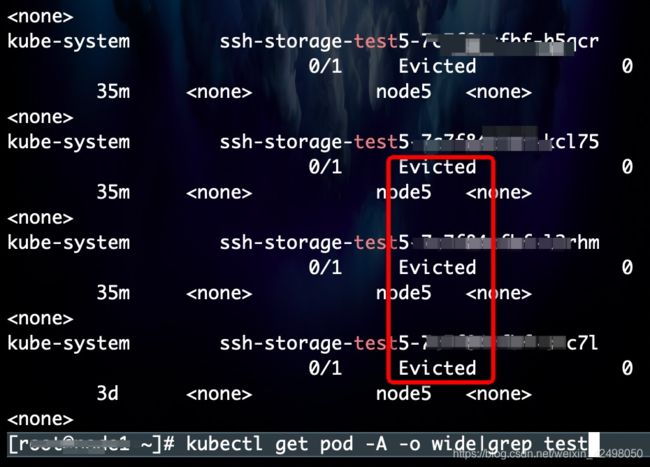
发现有很多 Evicted 状态的pod
问题原因:这是由于node节点的磁盘或内存资源不够后将现有的pod进行了驱赶
批量删除所有Evicted状态的pod即可
# kubectl -n kube-system get pods | grep Evicted |awk '{print$1}'|xargs kubectl -n kube-system delete pods
PS: kubectl -n kube-system get pods #指定pod所在的命名空间
执行完成后,成功删除全部Evicted状态的Pods

删除完Evicted状态的pod5数据后 需要登录与pod5绑定的node5机器重新加载镜像
又遇到了新的问题:以上操作后,pod5会临时的变成Running状态,但是过一会又出来一堆Evicted的pod5。目测应该是需要登录到node5而非pod5加载镜像
实际操作中遇到的pod状态积累:Running Pending-ContainerCreating ErrImagePull Evicted
正常状态如下
pvc为bound状态(绑定状态) pod为running状态(运行状态)
# kubectl get pvc -A |grep log4 查看pvc
kube-system pvc-log4 Bound pvc-xx 20Gi RWX managed-nfs-storage 174m
# kubectl get pod -A |grep test 查看pod
kube-system ssh-storage-test4-xx-xx 1/1 Running 0 9m26s

查看pvc : kubectl get pvc -A |grep
查看pod : kubectl get pod -A|grep
8. 可以创建完pod查看下状态 正常为Running 其实7最后面写了,再补充下吧
# kubectl get pod -A |grep ssh-storage
非running的需要查一下为什么没有run起来
pod为上面kubectl get pod -A |grep ssh-storage-test44出来的pod名称,为deployment4.yml配置的name(ssh-storage-test44)
# kubectl describe pod ssh-storage-test4-xx -n kube-system

扩展
kubectl describe命令详解
输出指定的一个/多个资源的详细信息。
摘要
输出指定的一个/多个资源的详细信息。
此命令组合调用多条API,输出指定的一个或者一组资源的详细描述。
$ kubectl describe TYPE NAME_PREFIX
首先检查是否有精确匹配TYPE和NAME_PREFIX的资源,如果没有,将会输出所有名称以NAME_PREFIX开头的资源详细信息。
支持的资源包括但不限于(大小写不限):pods (po)、services (svc)、 replicationcontrollers (rc)、nodes (no)、events (ev)、componentstatuses (cs)、 limitranges (limits)、persistentvolumes (pv)、persistentvolumeclaims (pvc)、 resourcequotas (quota)和secrets。
kubectl describe (-f FILENAME | TYPE [NAME_PREFIX | -l label] | TYPE/NAME)
9. 查看pod的ip
# kubectl get pod -A -o wide|grep test44
kube-system ssh-storage-test44-xx-nqqdn 1/1 Running 0 79m ipxx.xx.xx.xx node5
第二列为pod的地址
登录pod(2种方式)
在node1上通过上面的方式获取所有pod列表,用kubectl命令行登录 或者ssh root@pod的ip 再加密码登录,root可不写
# kubectl exec -it ssh-storage-test44-xx-xx -n kube-system bash
# kubectl exec -it ssh-storage-test4-xx-xx bash -n kube-system
登录到pod后安装iperf3, 如果没有,用yum install iperf3安装测试网络。
由于node4不能连接外网需要手动scp拷贝过去
pod不支持rz命令,需要登录node后scp远程拷贝到pod。node上支持rz等命令
遇到的问题:

从A机器拷贝iperf3到B机器(腾讯云)的node4不行,connection timed out lose connection。
登录B机器的node1(ssh node1),从A机器远程拷贝到B机器的node1,再从B的node1拷贝到B的node4
原因:pod是自己的网络 pod是和所在机器的宿主机网络是通的。从其他机器直接要连这个pod是有限制的。两层网络,A和B是宿主机,他们是有个网络,A上和B上各有自己的K8s网络。
[username@hostnameA tmp]# scp iperf3 username@ipB:/tmp/
iperf3 100% 11KB 34.0MB/s 00:00
[username@hostnameB tmp]# scp iperf3 node4:/tmp/
iperf3 100% 11KB 23.7MB/s 00:00
但是拷贝完发现不能用,解决办法 去https://iperf.fr/iperf-download.php#fedora
下载 Fedora 64 bits / Red Hat 64 bits / CentOS 64 bits (AMD64) by ssahani. (sha256)
- iPerf 3.1.3 - RPM package (8 jun 2016 - 76.8 KiB)
rz上传到B服务器node1的/tmp下
再用rpm命令安装
[username@hostname tmp]# rpm -i iperf3-3.1.3-1.fc24.x86_64.rpm

参考博客
https://blog.csdn.net/nathanniubee/article/details/86704055
10. 以上成功后,再创建pvc5 pod5
今天搭建了另一套环境,遇到的问题及分析
1. 拷贝文件
cp deployment4.yml deployment5.yml
cp pvc-test4.yml pvc-test5.yml
vim deployment5.yml
vim pvc-test5.yml
2. 加载镜像
cd ..
docker load -i centos_v3.tar.gz
3. 创建盘 检查盘状态
cd beijing/
kubectl create -f pvc-test5.yml
kubectl get pvc -A|grep log5
4. 创建pod 检查pod状态
kubectl create -f deployment5.yml
kubectl get pod -A -o wide|grep test5
5. 创建完成发现了个错误,就是pod5里的deployment5.yml的node没改还是node4 应该改为node5

# kubectl get pod -A -o wide|grep test5
kube-system ssh-storage-test5-xx-m5kh2 1/1 Running 0 13m ipxx.xx.xx.xx node4
# vim deployment5.yml
修改deployment5.yml,删除pod,重新创建
# kubectl delete pod ssh-storage-test5-xx-m5kh2 -n kube-system
pod "ssh-storage-test5-xx-m5kh2" deleted
遇到的问题:
如上使用 kubectl delete pod xx(podid) -n kube-system 删除后,k8s会马上自动创建一个新的podid,新建的podid后缀会变,绑定的显示还是node4
需要使用 kubectl get deployment -n kube-system 发现test5处于ready available 状态
kubectl delete deployment ssh-storage-test5-xx -n kube-system 删除原来创建的与node4绑定的podid
kubectl get pod -A -o wide |grep test 删除podid后查看配置中的podid状态 显示0/1 之前为1/1
此时再使用kubectl delete pod xx(podid) -n kube-system 去删除之前的podid
kubectl get pod -A -o wide |grep test 此时没有与node4绑定的podid了。用修改后的deployment5.yml重新创建即可
正确删除pod参考博客https://blog.csdn.net/qq_41210783/article/details/104428868
1、先删除pod
2、再删除对应的deployment
否则只是删除pod是不管用的,还会看到pod,因为deployment.yaml文件中定义了副本数量
实例如下:
删除pod
[root@test2 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
jenkins2-8698b5449c-grbdm 1/1 Running 0 8s
[root@test2 ~]# kubectl delete pod jenkins2-8698b5449c-grbdm -n jenkins
pod "jenkins2-8698b5449c-grbdm" deleted
查看pod仍然存储
[root@test2 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
jenkins2-8698b5449c-dbqqb 1/1 Running 0 8s
[root@test2 ~]#
删除deployment
[root@test2 ~]# kubectl get deployment -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
jenkins2 1 1 1 1 17h
[root@test2 ~]# kubectl delete deployment jenkins2 -n kube-system
再次查看pod消失
deployment.extensions "jenkins2" deleted
[root@test2 ~]# kubectl get deployment -n kube-system
No resources found.
[root@test2 ~]#
[root@test2 ~]# kubectl get pod -n kube-system
No resources found.
我的实际操作
获取pod列表 kubectl get pod -A -o wide|grep ssh-storage-test
删除pod kubectl delete pod podid -n kube-system
获取所有的deployment kubectl get deployment -n kube-system
删除对应的deployment kubectl delete deployment ssh-storage-testX -n kube-system
再去查看pod列表 kubectl get pod -A -o wide|grep ssh-storage-test
但是创建完成又发现新的问题(如果命令不生效则需要在后面指定命名空间-n kube-system)

分析报错
kubectl describe pod ssh-storage-test5-xx-xx -n kube-system 日志中类似的错误如下:kubectl describe pod 配置的deployment 中的pod名
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m57s default-scheduler Successfully assigned kube-system/ssh-storage-test5-xx-xx to node5
Normal Pulling 7m48s (x4 over 9m56s) kubelet, node5 Pulling image "centos:3"
Warning Failed 7m44s (x4 over 9m33s) kubelet, node5 Failed to pull image "centos:3": rpc error: code = Unknown desc = Error response from daemon: manifest for centos:3 not found
Warning Failed 7m44s (x4 over 9m33s) kubelet, node5 Error: ErrImagePull
Warning Failed 7m32s (x6 over 9m33s) kubelet, node5 Error: ImagePullBackOff
Normal BackOff 4m52s (x17 over 9m33s) kubelet, node5 Back-off pulling image "centos:3"
如果失败则需要排查 如此次遇到的是ImagePullBackOff 状态
发现报错为上面在node4遇到的错误
原因以及解决:登录服务器默认的在node1上 配置文件配置的pvc node在node5上,需要ssh node4把node1的镜像拷贝到node5服务器,再在node5重启,再到node1查看pod5状态
[username@node5 tmp]# docker load -i centos_v3.tar.gz
2653d992f4ef: Loading layer 216.5MB/216.5MB
445b195a0a1e: Loading layer 370.6MB/370.6MB
729bda915a8c: Loading layer 130.4MB/130.4MB
811b342ff5b5: Loading layer 39.32MB/39.32MB
Loaded image: centos:3
如果从服务器默认的node到其中任一node在scp的时候,不需要username@ip 只需要nodeN
[username@node1 storage]# scp centos_v3.tar.gz node5:/tmp

扩展知识
deployment的作用:
- 创建指定数量的pod
- 检查pod健康状态和数量
6. 同样操作完成后分别登录到node4 node5(ssh nodeN),利用iperf3测试node4 node5之间传输的网速
分别登录到pod4 pod5(kubectl exec -it ssh-storage-test4-xx-xx bash -n kube-system),利用iperf3测试pod4 pod5之间传输的网速
拓展
错误的容器镜像/非法的仓库权限解决方案:
kubectl get pods 状态为ErrImagePull && ImagePullBackOff (一直在restarting)
当我们创建一个名字为myapp的deployment的时候,它指向的是一个不存在的docker镜像:
最常见的有两个问题:
(a)指定了错误的容器镜像
(b)使用私有镜像却不提供仓库认证信息
ssh
Kubernetes ---- 存储卷(PV、PVC)
在创建需要持久化数据的Pod之前,要先创建一个PVC,这个PVC要在系统上找一个符合规则的PV,进行申请并占用,他们是一一对应关系的,一旦一个PV被某个PVC占用了,那么状态会变为Bound,不能被别的PVC绑定了,如果PVC找不到匹配规则的PV的话,那么状态就会变为pending状态,直到与符合规则的PV关联上;一个pvc创建后,相当于是一个存储卷,可以被多个Pod访问,可以自己制定规则(accessMode)
Kubernetes之kubectl命令行工具简介、安装配置及常用命令
kubectl作为kubernetes的命令行工具,主要的职责就是对集群中的资源的对象进行操作,这些操作包括对资源对象的创建、删除和查看等。下表中显示了kubectl支持的所有操作,以及这些操作的语法和描述信息
kubectl是Kubernetes集群的命令行工具,通过kubectl能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。运行kubectl命令的语法如下所
$ kubectl [command] [TYPE] [NAME] [flags]comand:指定要对资源执行的操作,例如create、get、describe和delete
comand:指定要对资源执行的操作,例如create、get、describe和delete
TYPE:指定资源类型,资源类型是大小学敏感的,开发者能够以单数、复数和缩略的形式。例如:
$ kubectl get pod pod1
$ kubectl get pods pod1
$ kubectl get po pod1
NAME:指定资源的名称,名称也大小写敏感的。如果省略名称,则会显示所有的资源,例如:
$ kubectl get pods
flags:指定可选的参数。例如,可以使用-s或者–server参数指定Kubernetes API server的地址和端口。
另外,可以通过kubectl help命令获取更多的信息。
Basic Commands (Beginner):
create Create a resource from a file or from stdin.
expose 使用 replication controller, service, deployment 或者 pod 并暴露它作为一个 新的
Kubernetes Service
run 在集群中运行一个指定的镜像
set 为 objects 设置一个指定的特征
Basic Commands (Intermediate):
explain 查看资源的文档
get 显示一个或更多 resources
edit 在服务器上编辑一个资源
delete Delete resources by filenames, stdin, resources and names, or by resources and label selector
Deploy Commands:
rollout Manage the rollout of a resource
scale 为 Deployment, ReplicaSet, Replication Controller 或者 Job 设置一个新的副本数量
autoscale 自动调整一个 Deployment, ReplicaSet, 或者 ReplicationController 的副本数量
Cluster Management Commands:
certificate 修改 certificate 资源.
cluster-info 显示集群信息
top Display Resource (CPU/Memory/Storage) usage.
cordon 标记 node 为 unschedulable
uncordon 标记 node 为 schedulable
drain Drain node in preparation for maintenance
taint 更新一个或者多个 node 上的 taints
Troubleshooting and Debugging Commands:
describe 显示一个指定 resource 或者 group 的 resources 详情
logs 输出容器在 pod 中的日志
attach Attach 到一个运行中的 container
exec 在一个 container 中执行一个命令
port-forward Forward one or more local ports to a pod
proxy 运行一个 proxy 到 Kubernetes API server
cp 复制 files 和 directories 到 containers 和从容器中复制 files 和 directories.
auth Inspect authorization
Advanced Commands:
apply 通过文件名或标准输入流(stdin)对资源进行配置
patch 使用 strategic merge patch 更新一个资源的 field(s)
replace 通过 filename 或者 stdin替换一个资源
wait Experimental: Wait for one condition on one or many resources
convert 在不同的 API versions 转换配置文件
Settings Commands:
label 更新在这个资源上的 labels
annotate 更新一个资源的注解
completion Output shell completion code for the specified shell (bash or zsh)
Other Commands:
alpha Commands for features in alpha
api-resources Print the supported API resources on the server
api-versions Print the supported API versions on the server, in the form of "group/version"
config 修改 kubeconfig 文件
plugin Runs a command-line plugin
version 输出 client 和 server 的版本信息
执行kubectl命令,获取nodes的信息:
$ kubectl get nodes
kubectl输出选项
kubectl默认的输出格式为纯文本格式,可以通过-o或者–output字段指定命令的输出格式。
$ kubectl [command] [TYPE] [NAME] -o=
kubectl 创建对象
$ kubectl create -f ./my-manifest.yaml #创建资源
$ kubectl create -f ./my1.yaml -f ./my2.yaml #使用多个文件创建资源
$ kubectl create -f ./dir #使用目录下的所有清单文件(yaml)来创建资源
$ kubectl create -f https://git.io/vPieo #使用url创建资源
$ kubectl run nginx --image=nginx #启动一个nginx实例
$ kubectl explain pods #获取pod和svc的文档
kubectl 显示和查找资源
以下命令查找资源时可能查不到的原因是需要指定namespace,通过 -n
指定即可,或者all $ kubectl get pods --all-namespaces #列出所有namespace中的pod,也可以是services、deployment等
$ kubectl get pods -o wide #列出pod并显示详细信息
$ kubectl get deployment my-dep #列出指定daployment
$ kubectl get pods --include-uninitialized #列出该namespace中的所有pod,包括未初始化的
使用详细输出来描述命令
$ kubectl describe nodes
#查看node节点信息 $ kubectl describe pods
#查看pod详细信息 $ kubectl get services --sort-by=.metadata.name --all-namespaces #l列出所有service并按名称排序
根据重启次数排序列出pod
$ kubectl get pods --sort-by='.status.containerStatuses[0].restartCount' --all-namespaces
获取所有具有app=cassandra的pod中的version标签
$ kubectl get pods --selector=app=cassandra rc -o jsonpath='{.items[*].metadata.labels.version}'
获取所有节点的ExternalIP
$ kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternlIP")].address}'
kubectl编辑资源
$ kubectl -n codeus edit svc/c #编辑codeus命名空间下名称为c的service
kubectl Scale 资源
扩展pod下容器数量
$ kubectl scale --replicas=3 rs/foo #扩展名称为foo的资源到3个,是否使用rs取决于yaml中的编写
例如yaml中kind: Deployment ,则应通过下面方法扩展
$ kubectl scale --replicas=3 deployment/foo
或者直接通过创建资源的yaml文件扩展
$ kubectl scale --replicas=3 -f foo.yaml
根据判断条件扩展
例如条件是:如果mysql的数量是2,则扩展到3
$ kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
同时扩展多个资源
$ kubectl scale --replicas=5 rc/foo rc/bar rc/baz
kubectl 删除资源
$ kubectl delete deployment
#删除指定deployment,此方法还可以删除service等 $ kubectl delete -f xxx.yaml #通过创建此pod的yaml文件删除pod
kubectl 与运行中的pod交互
$ kubectl -n
logs my-podname #查看pod日志, -f 持续查看 $ kubectl port-forward my-podname 5000:6000 #转发pod中的6000端口到本地的5000端口
$ kubectl exec my-podname -- ls / #在已存在的容器中执行命令
参考资料
1.《kubectl Usage Conventions》地址:https://kubernetes.io/docs/reference/kubectl/conventions/
2.《kubectl Commands》地址:https://kubernetes.io/docs/reference/kubectl/kubectl-cmds/
3.《Overview of kubectl》地址:https://kubernetes.io/docs/reference/kubectl/overview/
命令iperf3命令使用
iperf3是一个网络速度测试工具,支持IPv4与IPv6,支持TCP、UDP、SCTP传输协议,可在Windows、Mac OS X、Linux、FreeBSD等各种平台使用,是一个简单又实用的小工具。yum install iperf3 或者brew install iperf3即可安装。
Iperf3 是一个网络性能测试工具。Iperf可以测试最大TCP和UDP带宽性能,具有多种参数和UDP特性,可以根据需要调整,可以报告带宽、延迟抖动和数据包丢失.对于每个测试,它都会报告带宽,丢包和其他参数,可在Windows、Mac OS X、Linux、FreeBSD等各种平台使用,是一个简单又实用的小工具
[root@bogon ~]# rpm -ivh iperf3-3.1.3-1.fc24.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:iperf3-3.1.3-1.fc24 ################################# [100%]
#查看
[root@bogon ~]# which iperf3
/usr/bin/iperf3
[root@bogon ~]#
启动:
/usr/bin/iperf3
[root@bogon ~]# iperf3 -s
-----------------------------------------------------------
Server listening on 5201
-----------------------------------------------------------
实际应用
杀死本机Mac的进程
ps -ef|grep iperf3|awk '{print $2}'|grep -v grep|xargs sudo kill -9

server端输入 iperf3 -s 启动监听端口
客户端输入 iperf3 -c 127.0.0.1 -t 10

测试服务器上的操作
# scp -r username@hostname:/path/iperf3-3.0.11-1.fc22.x86_64.rpm ./
# iperf3 -s -p 25001
Iperf的主要功能如下:
TCP
-
测量网络带宽
-
报告MSS/MTU值的大小和观测值
-
支持TCP窗口值通过套接字缓冲
-
当P线程或Win32线程可用时,支持多线程。客户端与服务端支持同时多重连接
UDP
-
客户端可以创建指定带宽的UDP流
-
测量丢包
-
测量延迟
-
支持多播
-
当P线程可用时,支持多线程。客户端与服务端支持同时多重连接(不支持Windows)
其他
-
在适当的地方,选项中可以使用K(kilo-)和M(mega-)。例如131072字节可以用128K代替。
-
可以指定运行的总时间,甚至可以设置传输的数据总量。
-
在报告中,为数据选用最合适的单位。
-
服务器支持多重连接,而不是等待一个单线程测试。
-
在指定时间间隔重复显示网络带宽,波动和丢包情况。
-
服务器端可作为后台程序运行。
-
服务器端可作为Windows 服务运行。
-
使用典型数据流来测试链接层压缩对于可用带宽的影响。
-
支持传送指定文件,可以定性和定量测试
延伸知识
TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。 TCP的缺点: 慢,效率低,占用系统资源高,易被攻击
UDP的优点: 快,比TCP稍安全 UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些
TCP UDP
TCP与UDP基本区别
1.基于连接与无连接
2.TCP要求系统资源较多,UDP较少;
3.UDP程序结构较简单
4.流模式(TCP)与数据报模式(UDP);
5.TCP保证数据正确性,UDP可能丢包
6.TCP保证数据顺序,UDP不保证
tcp协议和udp协议的差别
TCP UDP
是否连接 面向连接 面向非连接
传输可靠性 可靠 不可靠
应用场合 少量数据 传输大量数据
速度 慢 快
Kubernetes 存储系统 Storage 介绍
容器中的存储都是临时的,因此Pod重启的时候,内部的数据会发生丢失。实际应用中,我们有些应用是无状态,有些应用则需要保持状态数据,确保Pod重启之后能够读取到之前的状态数据,有些应用则作为集群提供服务。这三种服务归纳为无状态服务、有状态服务以及有状态的集群服务,其中后面两个存在数据保存与共享的需求,因此就要采用容器外的存储方案
Kubernetes中存储中有四个重要的概念:Volume、PersistentVolume PV、PersistentVolumeClaim PVC、StorageClass。掌握了这四个概念,就掌握了Kubernetes中存储系统的核心。我用一张图来说明这四者之间的关系。

- Volumes是最基础的存储抽象,其支持多种类型,包括本地存储、NFS、FC以及众多的云存储,我们也可以编写自己的存储插件来支持特定的存储系统。Volume可以被Pod直接使用,也可以被PV使用。普通的Volume和Pod之间是一种静态的绑定关系,在定义Pod的同时,通过
volume属性来定义存储的类型,通过volumeMount来定义容器内的挂载点。 - PersistentVolume。与普通的Volume不同,PV是Kubernetes中的一个资源对象,创建一个PV相当于创建了一个存储资源对象,这个资源的使用要通过PVC来请求。
- PersistentVolumeClaim。PVC是用户对存储资源PV的请求,根据PVC中指定的条件Kubernetes动态的寻找系统中的PV资源并进行绑定。目前PVC与PV匹配可以通过
StorageClassName、matchLabels或者matchExpressions三种方式。 - StorageClass。
benchmark
一、Benchmark简介
benchmark最早是一款软件,专业测试显卡性能的,也就是3DMARK的前身。后来很多软件和游戏里的测试工具都叫benchmark了,benchmark就改名叫3DMARK了
Benchmark在计算机领域应用最成功的就是性能测试,主要测试负载的执行时间、传输速度、吞吐量、资源占用率等
参考博客 大数据领域的Benchmark介绍
二、Benchmark的组成
Benchmark的核心由3部分组成:数据集、 工作负载、度量指标
度量指标:性能高估的两大利器就是Benchmark和Profile工具
1、数据集
数据类型分为结构化数据、半结构化数据和非结构化数据。由于大数据环境下的数据类型复杂,负载多样,所以大数据Benchmark需要生成3种类型的数据和对应负载。
1)结构化数据:传统的关系数据模型,可用二维表结构表示。典型场景有电商交易、财务系统、医疗HIS数据库、政务信息化系统等等;
2)半结构化数据:类似XML、HTML之类,自描述,数据结构和内容混杂在一起。典型应用场景有邮件系统、Web搜索引擎存储、教学资源库、档案系统等等,可以考虑使用Hbase等典型的KeyValue存储;
3)非结构化数据:各种文档、图片、视频和音频等。典型的应用有视频网站、图片相册、交通视频监控等等。
2、工作负载
互联网领域数据庞大,用户量大,成为大数据问题产生的天然土壤。对工作负载理解和设计可以从以下几个维度来看
1)密集计算类型:CPU密集型计算、IO密集型计算、网络密集型计算;
2)计算范式:SQL、批处理、流计算、图计算、机器学习;
3)计算延迟:在线计算、离线计算、实时计算;
4)应用领域:搜索引擎、社交网络、电子商务、地理位置、媒体、游戏。
3、度量指标
性能高估的两大利器就是Benchmark和Profile工具。Benchmark用压力测试挖掘整个系统的性能状况,而Profile工具最大限度地呈现系统的运行时状态和性能指标,方便用户诊断性能问题和进行调优。
1)工具的使用
a)在架构层面:perf、nmon等工具和命令;
b)在JVM层面:btrace、Jconsole、JVisualVM、JMap、JStack等工具和命令;
c)在Spark层面:web ui、console log,也可以修改Spark源码打印日志进行性能监控。
2)度量指标
a)从架构角度度量:浮点型操作密度、整数型操作密度、指令中断、cache命中率、TLB命中;
b)从Spark系统执行时间和吞吐的角度度量:Job作业执行时间、Job吞吐量、Stage执行时间、Stage吞吐量、Task执行时间、Task吞吐量;
c)从Spark系统资源利用率的角度度量:CPU在指定时间段的利用率、内存在指定时间段的利用率、磁盘在指定时间段的利用率、网络带宽在指定时间段的利用率;
d)从扩展性的角度度量:数据量扩展、集群节点数据扩展(scale out)、单机性能扩展(scale up)。
ETCD
是一个分布式的,一致的 key-value 存储,主要用途是共享配置和服务发现。Etcd 已经在很多分布式系统中得到广泛的使用
为什么需要 Etcd ?
所有的分布式系统,都面临的一个问题是多个节点之间的数据共享问题,这个和团队协作的道理是一样的,成员可以分头干活,但总是需要共享一些必须的信息,比如谁是 leader, 都有哪些成员,依赖任务之间的顺序协调等。所以分布式系统要么自己实现一个可靠的共享存储来同步信息(比如 Elasticsearch ),要么依赖一个可靠的共享存储服务,而 Etcd 就是这样一个服务。
Etcd 提供什么能力?
Etcd 主要提供以下能力,已经熟悉 Etcd 的读者可以略过本段。
- 提供存储以及获取数据的接口,它通过协议保证 Etcd 集群中的多个节点数据的强一致性。用于存储元信息以及共享配置。
- 提供监听机制,客户端可以监听某个key或者某些key的变更(v2和v3的机制不同,参看后面文章)。用于监听和推送变更。
- 提供key的过期以及续约机制,客户端通过定时刷新来实现续约(v2和v3的实现机制也不一样)。用于集群监控以及服务注册发现。
- 提供原子的CAS(Compare-and-Swap)和 CAD(Compare-and-Delete)支持(v2通过接口参数实现,v3通过批量事务实现)。用于分布式锁以及leader选举。
Etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于google开源的一个golang的btree实现的,另外一部分是后端存储。按照它的设计,backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,Etcd 的事务是基于boltdb的事务实现的。Etcd 在boltdb中存储的key是reversion,value是 Etcd 自己的key-value组合,也就是说 Etcd 会在boltdb中把每个版本都保存下,从而实现了多版本机制
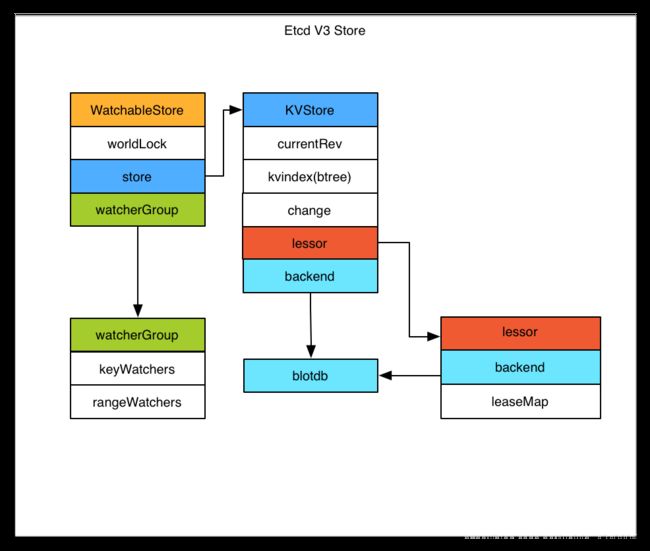
Etcd 的周边工具
- Confd
- Metad
- Etcd 集群一键搭建脚本
了解etcd性能
影响性能的两大因素:
延迟延迟是完成操作所花费的时间
吞吐量一段时间内完成的所有操作
etcd自带基准测试在目录tool/benchmark,可以通过go install安装后在go环境bin目录下
# write to leader
benchmark --endpoints=${HOST_1} --target-leader --conns=1 --clients=1 \
put --key-size=8 --sequential-keys --total=10000 --val-size=256
benchmark --endpoints=${HOST_1} --target-leader --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
# write to all members
benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --conns=100 --clients=1000 \
range YOUR_KEY --consistency=s --total=100000
- target-leader目标服务器:仅领袖
- conns 连接数
- clients客户端数量
- endpoints指定服务端
- key-size键的大小(以字节为单位)
- val-size值大小(以字节为单位)
- total 键的总数
- consistency 一致性(l表示线性化,s表示串行化)
10000 / 10000 Booooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo! 100.00% 34s
Summary:
Total: 34.5578 secs.
Slowest: 0.3055 secs.
Fastest: 0.0000 secs.
Average: 0.0034 secs.
Stddev: 0.0036 secs.
Requests/sec: 289.3703
Response time histogram:
0.0000 [245] |∎
0.0305 [9753] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
0.0611 [1] |
0.0916 [0] |
0.1222 [0] |
0.1527 [0] |
0.1833 [0] |
0.2138 [0] |
0.2444 [0] |
0.2749 [0] |
0.3055 [1] |
Latency distribution:
10% in 0.0029 secs.
25% in 0.0030 secs.
50% in 0.0030 secs.
75% in 0.0039 secs.
90% in 0.0040 secs.
95% in 0.0040 secs.
99% in 0.0140 secs.
99.9% in 0.0190 secs.
吞吐量(TPS)、QPS、并发数、响应时间(RT)概念
https://blog.csdn.net/qq_15437667/article/details/81210542
估算QPS峰值
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
故该机器支持139QPS即可。
Serializable接口
什么是Serializable接口
一个对象序列化的接口,一个类只有实现了Serializable接口,它的对象才能被序列化。
什么是序列化?
序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
为什么要序列化对象
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化什么情况下需要序列化?
当我们需要把对象的状态信息通过网络进行传输,或者需要将对象的状态信息持久化,以便将来使用时都需要把对象进行序列化
那为什么还要继承Serializable。那是存储对象在存储介质中,以便在下次使用的时候,可以很快捷的重建一个副本。