ShardingJDBC分库分表实战与核心原理-01
一、ShardingSphere产品介绍

ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞生,最初就叫ShardingJDBC。2016年的时候,由其中一个主要的开发人员张亮,带入到京东数科,组件团队继续开发。在国内历经了当当网、电信翼支付、京东数 科等多家大型互联网企业的考验,在2017年开始开源。并逐渐由原本只关注于关系 型数据库增强工具的ShardingJDBC升级成为一整套以数据分片为基础的数据生态 圈,更名为ShardingSphere。到2020年4月,已经成为了Apache软件基金会的顶 级项目。
ShardingJDBC
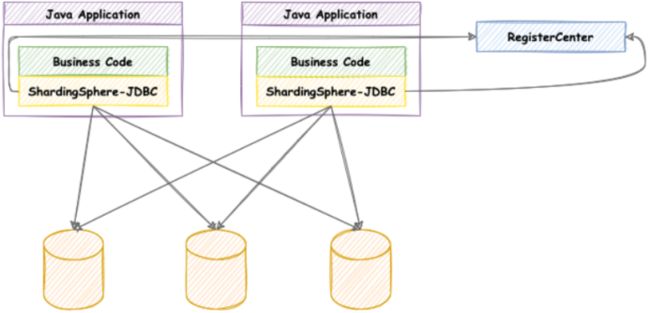
shardingJDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使⽤客户端直连数据库,以jar包形式提供服务,⽆需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
ShardingProxy
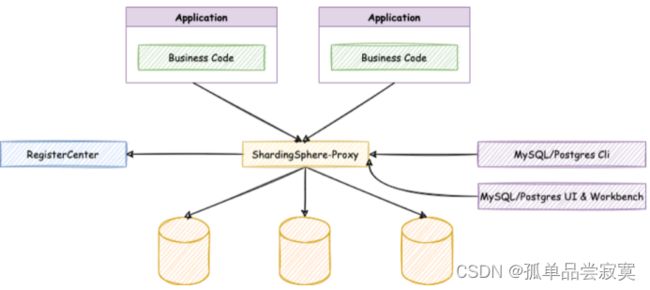
ShardingProxy定位为透明化的数据库代理端,提供封装了数据库⼆进制协议的服 务端版本,⽤于完成对异构语⾔的⽀持。⽬前提供 MySQL 和 PostgreSQL 版本, 它可以使⽤任何兼容 MySQL/PostgreSQL 协议的访问客⼾端。
那这两种方式有什么区别呢?

很显然,ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC
驱动包,所有分库分表逻辑均由业务方自己控制,所以他的功能相对灵活,支持的 数据库也非常多,但是对业务侵入大,需要业务方自己定制所有的分库分表逻辑。 而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个 普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在, 但是这也意味着功能会比较固定,能够支持的数据库也比较少。这两者各有优劣。
二、ShardingSphere生态定位
对于ShardingSphere,大家用得多的一般是他的4.x版本,这也是目前最具影响 力的一个系列版本。但是,ShardingSphere在2021年底,发布了5.x版本的第一个 发布版,这也标志着ShardingSphere的产品定位进入了一个新的阶段。
官网上也重 点标识了一下ShardingSphere的发展路线:
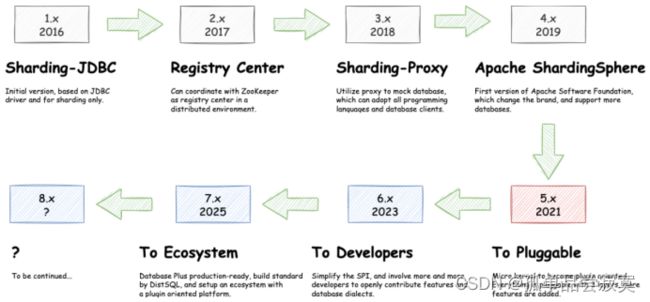
其实从4.x版本升级到5.x版本,ShardingSphere做了很多功能增强,但是其核心 功能并没有太大的变化。更大的区别其实是体现在产品定位上,在4.x版本中, ShardingSphere是定位为一个数据库中间件,而到了5.x版本,ShardingSphere给 自己的定位成了DatabasePlus,旨在构建多模数据库上层的标准和生态,从而更接 近于Sphere(生态)的定位。

其中核心的理念就是图中的连接、增量、可拔插。一方面未来会支持更多的数据 库,甚至不光是MySQL、PostGreSQL这些关系型数据库,还包括了像RocksDB, Redis这一类非关系型的数据库。又一方面会拓展ShardingSphere的数据库功能属 性,让用户可以完全基于ShardingSphere来构建上层应用,而其他的数据库只是作 为ShardingSphere的可选功能支持。另一方面形成 微内核+三层可拔插扩展 的模 型(图中的L1,L2,L3三层内核模型),让开发者可以在ShardingSphere的内核基础 上,做更灵活的功能拓展,可以像搭积木一样定制属于自己的独特系统
三、ShardingJDBC实战
1、表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。
绑定表
指分片规则一致的主表和子表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。 例如:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在配置绑定表关系,并且使用 order_id 进行关联后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。 因此,绑定表间的分区键需要完全相同。
广播表
指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
2、分片
分片键
用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
自定义分片算法
提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
- 标准分片算法
用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
- 复合分片算法
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
- Hint 分片算法
用于处理使用 Hint 行分片的场景
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
3、SpringBoot集成Sharding JDBC
pom.xml
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
org.springframework.boot
spring-boot-starter
2.4.5
org.springframework.boot
spring-boot-starter-test
2.4.1
org.springframework.boot
spring-boot-starter-jdbc
2.4.1
mysql
mysql-connector-java
5.1.44
com.baomidou
mybatis-plus-boot-starter
3.3.2
org.projectlombok
lombok
1.18.18
com.alibaba
druid
1.1.20
junit
junit
4.12
test
水平分表的方式在同一个库中创建多个相同结构的个表
- 创建数据库yax
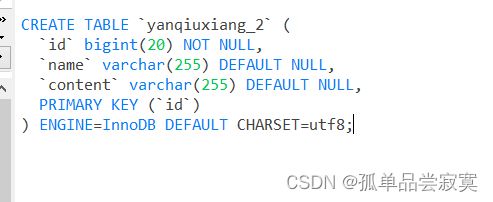
- 在数据库创建2个相同的表yanqiuxiang_1和yanqiuxiang_2
- 数据操作规则:如果操作的数据id是偶数着操作yanqiuxiang_1表,如果是奇数操作yanqiuxiang_2表


项目架构
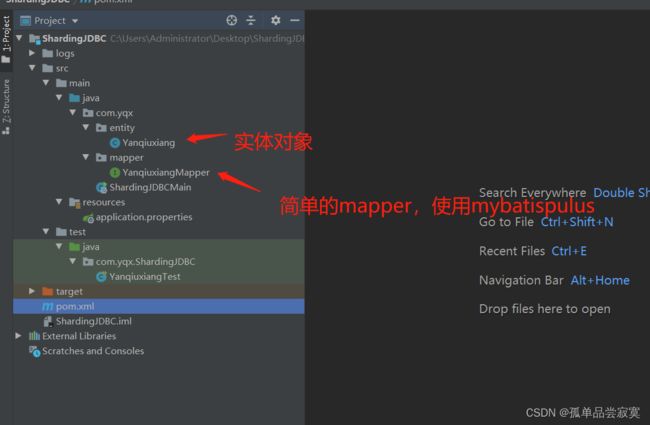
实体对象
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("yanqiuxiang")
public class Yanqiuxiang {
private Long id;
private String name;
private String content;
}
mapper
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.yqx.entity.Yanqiuxiang;
public interface YanqiuxiangMapper extends BaseMapper {
}
application.properties
#垂直分表策略
# 配置真实数据源
spring.shardingsphere.datasource.names=m1
# 配置第 1 个数据源
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/yqx?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分两个表:m1.yanqiuxiang_1,m1.yanqiuxiang_2
spring.shardingsphere.sharding.tables.yanqiuxiang.actual-data-nodes=m1.yanqiuxiang_$->{1..2}
# 指定表的主键生成策略
spring.shardingsphere.sharding.tables.yanqiuxiang.key-generator.column=id
spring.shardingsphere.sharding.tables.yanqiuxiang.key-generator.type=SNOWFLAKE
#指定分片策略 约定id值为偶数添加到yanqiuxiang_1表。如果是奇数添加到yanqiuxiang_2表。
# 选定计算的字段
spring.shardingsphere.sharding.tables.yanqiuxiang.table-strategy.inline.sharding-column= id
# 根据计算的字段算出对应的表名。
spring.shardingsphere.sharding.tables.yanqiuxiang.table-strategy.inline.algorithm-expression=yanqiuxiang_$->{id%2+1}
# 打开sql日志输出。
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true首先定义一个数据源m1,并对m1进行实际的JDBC参数配置
spring.shardingsphere.sharding.tables.yanqiuxiang开头的一系列属性即定义了一个名为yanqiuxiang的逻辑表。
actual-data-nodes属性即定义yanqiuxiang逻辑表的实际数据分布情况,他分布在m1.yanqiuxiang_1和m1.yanqiuxiang_2两个表。
key-generator属性配置了他的主键列以及主键生成策略。
ShardingJDBC默认提供了UUID和SNOWFLAKE两种分布式主键生成策略。
table-strategy属性即配置他的分库分表策略。分片键为id属性。分片算法为yanqiuxiang_$->{id%2+1},表示按照id模2+1的结果,然后加上前面的yanqiuxiang__ 部分作为前缀就是他的实际表结果。注意,这个表达式计算出来的结果需要能够与实际数据分布中的一种情况对应上,否则就会报错。
sql.show属性表示要在日志中打印实际SQLTest
import com.yqx.entity.Yanqiuxiang;
import com.yqx.mapper.YanqiuxiangMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@RunWith(SpringRunner.class)
@SpringBootTest
public class YanqiuxiangTest {
@Resource
private YanqiuxiangMapper yanqiuxiangMapper;
//插入数据会进行分片
@Test
public void addcourse() {
for (int i = 0; i < 10; i++) {
Yanqiuxiang c = new Yanqiuxiang();
c.setName("yan");
c.setContent("1");
yanqiuxiangMapper.insert(c);
//insert into course values ....
}
}
}
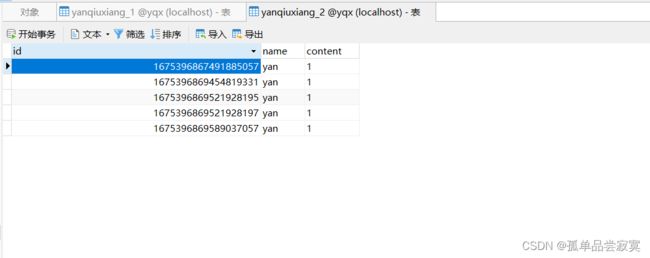
上面操作的是单个数据库进行分表
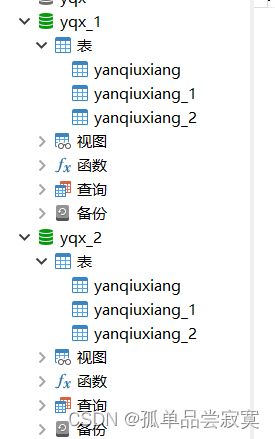
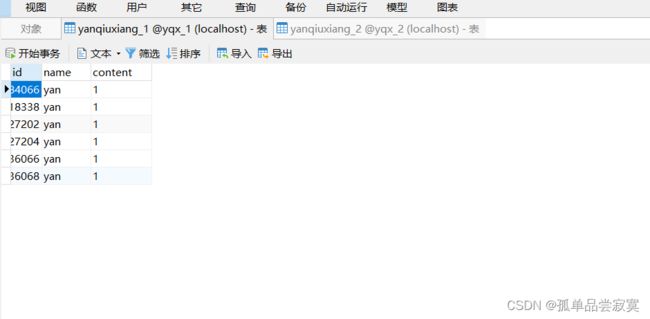
下面操作多个库多个表
#配置数据源
spring.shardingsphere.datasource.names=ds1,ds2
#配置第一个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/yqx_1?serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
#配置第二个数据源
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://127.0.0.1:3306/yqx_2?serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=123456
#配置yanqiuxiang表所在的数据节点
spring.shardingsphere.sharding.tables.yanqiuxiang.actual-data-nodes=ds$->{1..2}.yanqiuxiang_$->{1..2}
#database-strategy 库分片策略
spring.shardingsphere.sharding.tables.yanqiuxiang.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.yanqiuxiang.database-strategy.inline.algorithm-expression=ds$->{id%2+1}
#table-strategy 表分片策略
# 选定计算的字段
spring.shardingsphere.sharding.tables.yanqiuxiang.table-strategy.inline.sharding-column= id
# 根据计算的字段算出对应的表名。
spring.shardingsphere.sharding.tables.yanqiuxiang.table-strategy.inline.algorithm-expression=yanqiuxiang_$->{id%2+1}
spring.shardingsphere.sharding.tables.yanqiuxiang.key-generator.column=id
spring.shardingsphere.sharding.tables.yanqiuxiang.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.yanqiuxiang.key-generator.props.worker.id=1
spring.shardingsphere.props.sql.show=trueSharding-JDBC认为对于分片策略存有两种维度:
- 数据源分片策略(DatabaseShardingStrategy):数据被分配的目标数据源
- spring.shardingsphere.sharding.tables.course.database-strategy
- 表分片策略(TableShardingStrategy):数据被分配的目标表
- spring.shardingsphere.sharding.tables.course.table-strategy
两种分片策略API完全相同,但是表分片策略是依赖于数据源分片策略的(即:先分库然后才有分表)

四、ShardingSphere五种分片策略
1、NoneShardingStrategy
不分片。这种严格来说不算是一种分片策略了。只是ShardingSphere也提供了这么一个配置。
2、InlineShardingStrategy
最常用的分片方式
配置参数:
inline.shardingColumn 分片键;
inline.algorithmExpression 分片表达式
实现方式: 按照分片表达式来进行分片。
#分片策略(test是我们的逻辑表,这里对应实际表test_1和test_2)
spring.shardingsphere.sharding.tables.test.table-strategy.inline.sharding-column=tid
spring.shardingsphere.sharding.tables.test.table-strategy.inline.algorithm-expression=test_$->{tid%2+1}
#分库策略
spring.shardingsphere.sharding.tables.test.database-strategy.inline.sharding-column=tid
spring.shardingsphere.sharding.tables.test.database-strategy.inline.algorithm-expression=s$->{tid%2+1}
*注:只支持分片主键的精确路由,不支持范围查询、模糊查询、联表查询。
3、StandardShardingStrategy
只支持单分片键的标准分片策略。
配置参数:
standard.sharding-column 分片键;
standard.precise-algorithm-class-name 精确分片算法类名;
standard.range-algorithm-class-name 范围分片算法类名;
#分片策略
spring.shardingsphere.sharding.tables.test.table-strategy.standard.sharding-column=tid
spring.shardingsphere.sharding.tables.test.table-strategy.standard.precise-algorithm-class-name=com.shardingDemo.algorithem.MyPreciseTableShardingAlgorithm
spring.shardingsphere.sharding.tables.test.table-strategy.standard.range-algorithm-class-name=com.shardingDemo.algorithem.MyRangeTableShardingAlgorithm
#分库策略
spring.shardingsphere.sharding.tables.test.database-strategy.standard.sharding-column=tid
spring.shardingsphere.sharding.tables.test.database-strategy.standard.precise-algorithm-class-name=com.shardingDemo.algorithem.MyPreciseDSShardingAlgorithm
spring.shardingsphere.sharding.tables.test.database-strategy.standard.range-algorithm-class-name=com.shardingDemo.algorithem.MyRangeDSShardingAlgorithm
*注:需要定制实现精确路由和范围路由的逻辑类,也就是自己编码路由逻辑。
实现方式:
shardingColumn 指定分片键。
preciseAlgorithmClassName 指向一个实现了io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm接口的java类名,提供按照 = 或者 IN 逻辑的精确分片
精确分片算法
/**
* @author :yanqiuxiang
* @date :Created in 2023/7/03
* @description: 自定义扩展的精确分片算法
**/
public class MyPreciseDSShardingAlgorithm implements PreciseShardingAlgorithm {
/**
* @param availableTargetNames 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息
* @param shardingValue 包含 逻辑表名、分片列和分片列的值。
* @return 返回目标结果
*/
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
//实现按照 = 或 IN 进行精确分片。
//例如 select * from course where cid = 1 or cid in (1,3,5)
// select * from course where userid- 'xxx';
//实现course_$->{cid%2+1} 分表策略
BigInteger shardingValueB = BigInteger.valueOf(shardingValue.getValue());
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "m"+resB ;
if(availableTargetNames.contains(key)){
return key;
}
throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config");
}
} 范围分片算法类名
/**
* @author :yanqiuxiang
* @date :Created in 2023/7/3
* @description: 自定义扩展的范围分片算法。实现对select * from course where cid between 2000 and 3000; 这类语句的数据源分片
**/
public class MyRangeDSShardingAlgorithm implements RangeShardingAlgorithm {
/**
*
* @param availableTargetNames
* @param shardingValue 包含逻辑表名、分片列和分片列的条件范围。
* @return 返回目标结果。可以是多个。
*/
@Override
public Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
//实现按照 Between 进行范围分片。
//例如 select * from course where cid between 2000 and 3000;
Long lowerEndpoint = shardingValue.getValueRange().lowerEndpoint();//2000
Long upperEndpoint = shardingValue.getValueRange().upperEndpoint();//3000
//对于我们这个奇偶分离的场景,大部分范围查询都是要两张表都查。
return availableTargetNames;
}
}
4、ComplexShardingStrategy
支持多分片键的复杂分片策略。
配置参数:
complex.sharding-columns 分片键(多个);
complex.algorithm-class-name 分片算法实现类;
实现了org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm接口的java类名。提供按照多个分片列进行综合分片的算法。
#分片策略(这里用了两个表的主键tid和uid)
spring.shardingsphere.sharding.tables.test.table-strategy.complex.sharding-columns= tid, uid
spring.shardingsphere.sharding.tables.test.table-strategy.complex.algorithm-class-name=com.shardingDemo.algorithem.MyComplexTableShardingAlgorithm
#分库策略(这里用了两个表的主键tid和uid)
spring.shardingsphere.sharding.tables.test.database-strategy.complex.sharding-columns=tid, uid
spring.shardingsphere.sharding.tables.test.database-strategy.complex.algorithm-class-name=com.shardingDemo.algorithem.MyComplexDSShardingAlgorithm
*注:需要定制实现多表关联路由逻辑类。/**
* @author :yanqiuxiang
* @date :Created in 2023/7/3
* @description: 实现根据多个分片列进行综合分片的算法
**/
public class MyComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm {
/**
*
* @param availableTargetNames 目标数据源 或者 表 的值。
* @param shardingValue logicTableName逻辑表名 columnNameAndShardingValuesMap 分片列的精确值集合。 columnNameAndRangeValuesMap 分片列的范围值集合
* @return
*/
@Override
public Collection doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
//实现按照 Between 进行范围分片。
//例如 select * from course where cid in (1,3,5) and userid Between 200 and 300;
Collection cidCol = shardingValue.getColumnNameAndShardingValuesMap().get("cid");
Range uageRange = shardingValue.getColumnNameAndRangeValuesMap().get("user_id");
List result = new ArrayList<>();
Long lowerEndpoint = uageRange.lowerEndpoint();//200
Long upperEndpoint = uageRange.upperEndpoint();//300
//实现自定义分片逻辑 例如可以自己实现 course_$->{cid%2+1 + (30-20)+1} 这样的复杂分片逻辑
for(Long cid : cidCol){
BigInteger cidI = BigInteger.valueOf(cid);
BigInteger target = (cidI.mod(BigInteger.valueOf(2L))).add(new BigInteger("1"));
result.add("course_"+target);
}
return result;
}
}
5、HintShardingStrategy
不需要分片键的强制分片策略。这个分片策略,简单来理解就是说,他的分片键不再跟SQL语句相关联,而是用程序另行指定。对于一些复杂的情况,
例如:
select count(*) from (select userid from t_user where userid in (1,3,5,7,9))
这样的SQL语句,就没法通过SQL语句来指定一个分片键。这个时候就可以通过程序,给他另行执行一个分片键,例如在按userid奇偶分片的策略下,可以指定1作为分片键,然后自行指定他的分片策略。
配置参数:
hint.algorithm-class-name 分片算法实现类;
实现方式:
algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口的java类名。
在这个算法类中,同样是需要分片键的。而分片键的指定是通过HintManager.addDatabaseShardingValue方法(分库)和HintManager.addTableShardingValue(分表)来指定。使用时要注意,这个分片键是线程隔离的,只在当前线程有效,所以通常建议使用之后立即关闭,或者用try资源方式打开。
/**
* @author :yanqiuxiang
* @date :Created in 20230/7/3
* @description: 自定义扩展hint分片算法。Hint分片的分片键从SQL语句中抽离出来,由程序自行指定。
* 通过HintManager来指定。注意这个HintManager设置的分片键都是线程安全的。
**/
public class MyHintTableShardingAlgorithm implements HintShardingAlgorithm {
/**
*
* @param availableTargetNames 可选 数据源 和 表 的名称
* @param shardingValue
* @return
*/
@Override
public Collection doSharding(Collection availableTargetNames, HintShardingValue shardingValue) {
// 对SQL的零侵入分片方案。shardingValue是通过HintManager.
// 比如我们要实现将 select * from t_user where user_id in {1,2,3,4,5,.....}; 按照in的第一个值,全部路由到course_1表中。
// 注意他使用时有非常多的限制。
String key = "course_"+shardingValue.getValues().toArray()[0];
if(availableTargetNames.contains(key)){
return Arrays.asList(key);
}
// return Arrays.asList("course_1");
throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config");
}
} 广播表
spring.shardingsphere.sharding.broadcast-tables=t_dict
spring.shardingsphere.sharding.tables.t_dict.key-generator.column=dict_id
spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
绑定表
spring.shardingsphere.sharding.binding-tables[0]=test,t_dict
五、ShardingSphere的SQL使用限制
支持的SQL
|
SQL
|
必要条件 |
|
SELECT * FROM tbl_name
|
|
|
SELECT * FROM tbl_name WHERE (col1 = ? or col2 = ?) and col3 = ?
|
|
|
SELECT * FROM tbl_name WHERE col1 = ? ORDER BY col2 DESC LIMIT ?
|
|
|
SELECT COUNT(*), SUM(col1), MIN(col1),MAX(col1),
AVG(col1) FROM tbl_name WHERE col1 = ?
|
|
|
SELECT COUNT(col1) FROM tbl_name WHERE col2 = ?
GROUP BY col1 ORDER BY col3 DESC LIMIT ?, ?
|
|
|
INSERT INTO tbl_name (col1, col2,…) VALUES (?, ?, ….)
|
|
|
INSERT INTO tbl_name VALUES (?, ?,….)
|
|
|
INSERT INTO tbl_name (col1, col2, …) VALUES (?, ?, ….), (?, ?, ….)
|
|
|
INSERT INTO tbl_name (col1, col2, …)
SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
|
INSERT表和SELECT表
必须为相同表或绑定表
|
|
REPLACE INTO tbl_name (col1, col2, …) SELECT col1,
col2, … FROM tbl_name WHERE col3 = ?
|
REPLACE表和SELECT
表必须为相同表或绑定
表
|
|
UPDATE tbl_name SET col1 = ? WHERE col2 = ?
DELETE FROM tbl_name WHERE col1 = ?
CREATE TABLE tbl_name (col1 int, …)
ALTER TABLE tbl_name ADD col1 varchar(10)
DROP TABLE tbl_name
TRUNCATE TABLE tbl_name
CREATE INDEX idx_name ON tbl_name
DROP INDEX idx_name ON tbl_name
DROP INDEX idx_name
SELECT DISTINCT * FROM tbl_name WHERE col1 = ?
SELECT COUNT(DISTINCT col1) FROM tbl_name
SELECT subquery_alias.col1 FROM (select
tbl_name.col1 from tbl_name where tbl_name.col2=?)
subquery_alias
|
不支持的SQL
|
SQL
|
不支持原因
|
|
INSERT INTO tbl_name (col1, col2, …)
VALUES(1+2, ?, …)
|
VALUES语句不支持运算表达式
|
|
INSERT INTO tbl_name (col1, col2, …)
SELECT * FROM tbl_name WHERE col3
= ?
|
SELECT子句暂不支持使用*号简写及内
置的分布式主键生成器
|
|
REPLACE INTO tbl_name (col1, col2, …)
SELECT * FROM tbl_name WHERE col3
= ?
|
SELECT子句暂不支持使用*号简写及内
置的分布式主键生成器
|
|
SELECT * FROM tbl_name1 UNION
SELECT * FROM tbl_name2
|
UNION
|
|
SELECT * FROM tbl_name1 UNION ALL
SELECT * FROM tbl_name2
|
UNION ALL
|
|
SELECT SUM(DISTINCT col1),
SUM(col1) FROM tbl_name
|
详见DISTINCT支持情况详细说明
|
|
SELECT * FROM tbl_name WHERE to_date(create_time, ‘yyyy-mm-dd’)
= ?
|
会导致全路由
|
|
(SELECT * FROM tbl_name)
|
暂不支持加括号的查询 |
|
SELECT MAX(tbl_name.col1) FROM
tbl_name
|
查询列是函数表达式时,查询列前不能使 用表名;若查询表存在别名,则可使用表的 别名
|
SELECT DISTINCT * FROM tbl_name WHERE col1 = ?
SELECT DISTINCT col1 FROM tbl_name
SELECT DISTINCT col1, col2, col3 FROM tbl_name
SELECT DISTINCT col1 FROM tbl_name ORDER BY col1
SELECT DISTINCT col1 FROM tbl_name ORDER BY col2
SELECT DISTINCT(col1) FROM tbl_name
SELECT AVG(DISTINCT col1) FROM tbl_name
SELECT SUM(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1
SELECT COUNT(DISTINCT col1 + col2) FROM tbl_name
SELECT COUNT(DISTINCT col1), SUM(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1), col1 FROM tbl_name GROUP BY col1
SELECT col1, COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1|
SQL
|
不支持原因
|
|
SELECT SUM(DISTINCT tbl_name.col1),SUM(tbl_name.col1)
FROM tbl_name
|
查询列是函数表达式时,查询列前不能使用 表名;若查询表存在别名,则可使用表的别名
|