Pandas学习(二)—— Pandas基础
2.1.1、文件读取
根据待读取文件格式不同有不同的pandas方法,如pd.read_excel, pd.read_csv, pd.read_txt,
且每一种方法可指定的参数都巨多 就拿csv的来举例(是不是贼恐怖~)

但是有一些参数是这几种格式的方法所共有的,教程里也提及了,如header, index_col, usecol等。
因为我自己处理的数据通常是excel格式,所以我就讲讲pd.read_excel吧。
-
我们要输入的第一个参数是文件的路径,这个路径要带上文件名(包括扩展名如xlsx);可以是绝对路径(从盘符开始),也可以是相对路径。什么是相对路径呢,如果这个excel文件恰好跟当前py文件处在同一个目录下,那么我们直接输入excel的文件名就好了

我刚刚新建了一个temp.xlsx的excel文件,那么我想读取它,直接
df1 = pd.read_excel('temp.xlsx')
然后我把它移动到py文件所在文件夹(torch_test)的子文件夹temp_file里了,那么我应该
df1 = pd.read_excel('temp_file/temp.xlsx')
那么如果py文件要读取的excel在其所在文件夹之外呢?我又不想用绝对路径,咋办呢?
熟悉cmd命令的小伙伴肯定知道,想要去当前文件夹的父文件夹只要cd ..就可了
python中也是一样的,现在我要读取的excel文件在这个位置:

而py文件的绝对路径是:D:\Pycharm\torch_test
所以我现在只需要向上移动一个文件夹到codes就好办了!
df1 = pd.read_excel('../codes/python_2020CUMCM/副本附件1:123家有信贷记录企业的相关数据.xlsx',
sheet_name='Sheet2',usecols='H:L',header=15)
注意一定要带上xlsx这个扩展名,否则python会说No such file…
这边还有几个参数。
-
第二个是sheet_name很好理解,因为一个excel工作簿会有不同的工作表,我现在想读取的数据是这样的
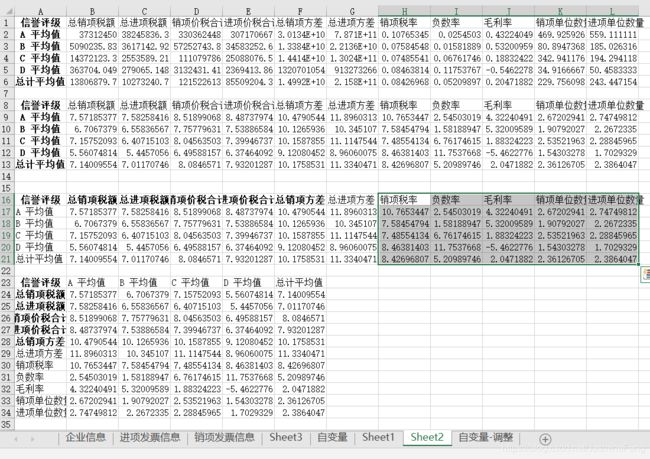
它在Sheet2这个工作表里头,所以指定
sheet_name='Sheet2', -
use_cols指定要读取哪些列,我要读取的是H到L,所以指定
use_cols='H:L';如果我只想读取H和L这两列(不连续),那么指定use_cols='H,L'
P.S. python中左开右闭(不包括右端点)区间很常见,比方说list(range(1,10))生成的列表是不包括10的,对一个列表list_1切片索引list_1[0:10]也是索引不到第10个数的,但是pandas里常常会出现两个端点同时取到的情况,以上就是一例,H和L都被取了。 -
header指定我们要从哪一行开始读取,这边也是个易踩坑的地方,容易看到excel里面header应该是16行,但是pandas中是从第0行开始算的,所以。。。excel中每行减去1是pandas中的每行。这边
header=15就很显然了吧~
print读出来的结果:
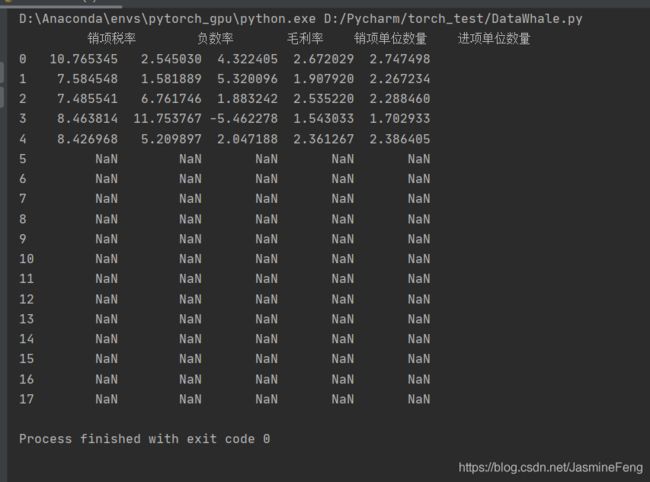
我们看到这边出现超多的NaN,欸,为啥呢?
我们再来仔细观察一下工作表:

工作表的最后一行是34行(pandas33),而我框出来的区域都没有填充值,所以是未定数NaN啊。原来pandas并没这么智能,不知道我们其实只想从第16行(pandas15)往下读5行就可以了。所以这个时候nrows就要闪亮登场了!
- nrows用来指定我要读取多少行数据(标题行不算),这边
nrows=5
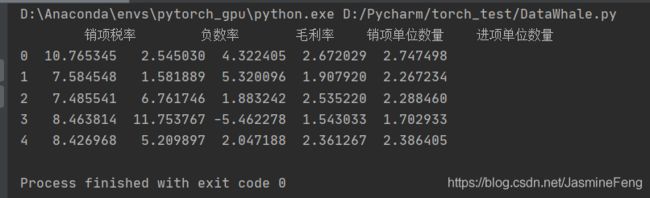
所以这就是我最终想要看到的啦,嘿嘿~
没想到一个文件读取能写这么多。。。明天继续写吧,嗐!
2.1.2、数据写入
在excel中追加数据较为困难,容易覆盖原数据。
有两个不太聪明但勉强能用的方法:
- 在原WorkBook中新建一个WorkSheet,把数据存到新sheet中,而不能直接在原sheet中追加,这时设置
pd.ExcelWriter(file_name, mode='a') - 取出要追加的sheet的数据,转成DataFrame格式,用pandas将其与新数据进行拼接,然后将拼接的数据存进sheet,就不用怕覆盖了
数据写入时通常指定index=False,因为DataFrame对象是带有index属性的
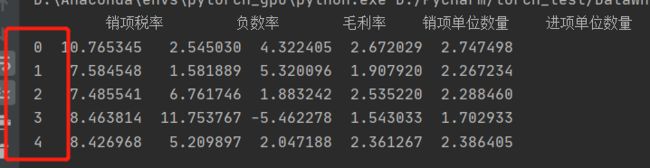
如果我们不指定index=False的话(缺省值为True),写入excel时,也会出现这个index:
df1.to_excel('temp.xlsx')

大多数情况下这个A列是多余的,这就是to_excel方法中index关键字的作用。
对于转换成LaTeX语言,除了教程中提供的方法(需另外install包),我一般是用插件的我也忘了当时是在哪下载这个插件的了,反正一搜一大把~
2.2.1、Series对象
Series是一维的values, 在实例化的时候,我们通常要指定data和index,其余的一般不怎么用:
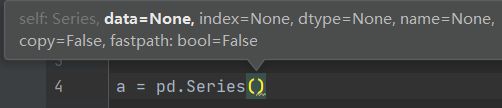
下面举两个实例化的例子。a没有指定index,b指定了index为大写拉丁字母的前四个,请注意index必须是序列,如list/tuple,但绝对不能是字符串,所以这边要用list把‘ABCD’变成['A','B','C','D']再给index!
from string import ascii_uppercase
a = pd.Series(['a','b','c','d'])
b = pd.Series([10,20,30,40], index=list(ascii_uppercase[:4]))
print(a)
print(b)
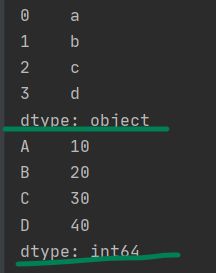
如果data是字符串的话,那么Series对象dtype就默认是object,这个教程里也说了。
2.2.2、DataFrame对象
DataFrame由一列列的Series对象构成,因此可以认为前者是后者的“容器”。
创建DataFrame的方法有很多,比较常用的有:
- data为ndarray,index & columns为序列(缺省值为从0开始的整数)
df1 = pd.DataFrame(np.arange(12).reshape(3,4))
print(df1)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
- data为嵌套有序列(本文中序列均不包括字符串)的字典
dict1 = {'name':['Mike','Lily'],'age':(12,13)}
df1 = pd.DataFrame(dict1)
print(df1)
# name age
# 0 Mike 12
# 1 Lily 13
- data为嵌套有字典的序列
list1 = [{'name':'Mike'},{'name':'Lily','age':13}]
df2 = pd.DataFrame(list1,index=('stu1','stu2'))
print(df2)
# name age
# stu1 Mike NaN
# stu2 Lily 13
这里因为我没填入Mike童鞋的年龄,所以pandas给了他NaN
DataFrame的常用属性有values(取值),columns(列索引),index(行索引),shape(形状)。
---------------------------------------------------------------------------------------------------------------------
P.S. 有一点我不是很懂,就是为啥columns用的复数,但是index用的是单数咧?强迫症患者表示有点难受!
---------------------------------------------------------------------------------------------------------------------
用.T可以把DataFrame(打这个好麻烦,后面直接用DF代替)对象转置,这个跟ndarray差不多~
2.3.1、汇总函数
- 当一个表数据量很多致使
print全部的时候不方便观察时,我们可以用*pd.head(n=5), pd.tail(n=5)*来分别查看首尾n行,了解大致长什么样子~ - np.info(), np.describe() 也是概览全局的方法,其中前者可以告知我们数据条目、非空值信息,后者可以告知我们常用统计量(计数、均值、最值、标准差、四分位数),这对于数据预处理是很有帮助的!
2.3.2、特征统计函数
这些函数在统计时都是逐列统计的,按照我上一篇博客的观点的话,这个指针是在第0维从上往下移动的,所以axis=0(缺省值),当然如果你转置,那最好还是指定axis=1。
- DataFrame.idxmax可用来找到某列最大值的位置
2.3.3、唯一值函数
我现在创建一个新的DF对象,方便后面解释。
dict1 = {'name':['Mike','Lily','Jasmine','Hobo','Eddie'],
'Age':[21,8,21,8,10],'Sex':['M','F','M','Unknown','M']}
df = pd.DataFrame(dict1,index=['stu'+str(i) for i in range(1,6)])
print(df)
# name Age Sex
# stu1 Mike 21 M
# stu2 Lily 8 F
# stu3 Jasmine 21 M
# stu4 Hobo 8 Unknown
# stu5 Eddie 10 M
DF[col_name].unique()可以剔去当列的重复值,注意DF是没有unique方法的,只有Series才有!
age = df['Age'].unique()
sex = df['Sex'].unique()
print(age)
print(sex)
print(df.unique())
# [21 8 10]
# ['M' 'F' 'Unknown']
# AttributeError: 'DataFrame' object has no attribute 'unique'
P.S. 除了用unique方法,还可以借助集合元素的唯一性来剔除重复值,如果与len()函数结合的话,就可以获取唯一值出现的频数(nunique方法)。
HAVE A TRY :print(len(set(df['Age'])))
- value_counts()比之于unique和nunique更为强大,因其将二者合二为一,且有更多参数可以指定
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)

以上是来自官方文档对参数的解释。
- normalize指定是否归一化,如
True则返回频率; - sort指定是否排序,排序准则是频率;
- ascending指定是否升序排列;
- bins对数值型的column指定是否要划分区间,可以参考matplotlib.pyplot中的hist;
- dropna指定是否丢弃缺失值。
- DF.drop_duplicates可以删除重复行。
df1_unique_age = df.drop_duplicates(['Age']) # 年龄不可重复
print(df1_unique_age)
# name Age Sex
# stu1 Mike 21 M
# stu2 Lily 8 F
# stu5 Eddie 10 M
df1_unique_age_sex = df.drop_duplicates(['Age','Sex']) # 年龄、性别不可同时重复
print(df1_unique_age_sex)
# name Age Sex
# stu1 Mike 21 M
# stu2 Lily 8 F
# stu4 Hobo 8 Unknown
# stu5 Eddie 10 M
- DF.duplicated用于找出重复值而不是删除(通过返回bool值)
HAVE A TRY:
print(df[~df.duplicated(['Age','Sex'])] == df.drop_duplicates(['Age','Sex']))
2.3.4、替换函数
- 映射替换
现在我想把性别男、女、未知替换成0、1、-1,我可以用DF.replace方法
df1 = df.replace({'M':0,'F':1,'Unknown':-1})
df2 =df.replace(['M','F','Unknown'],[0,1,-1])
print(df1)
print(df2)
传入字典or列表效果等价,均打印:
# name Age Sex
# stu1 Mike 21 0
# stu2 Lily 8 1
# stu3 Jasmine 21 0
# stu4 Hobo 8 -1
# stu5 Eddie 10 0
通过指定method='ffill'或method='bfill'的f和b从其功能看可能分别是front与back,即用前/后的未被替换值填充待被替换值,但这个能有啥实际作用我一时还没想到。。。
-
逻辑替换
如果numpy中的where理解到位的话,pandas中的where就容易多了,只不过,DF.where or Series.where不能对满足条件的值操作,而numpy可以,pandas中是用mask对满足条件的值进行操作的,但是我可能会记混,所以我的话更倾向于在mask中把条件反转一下而减少使用where,毕竟if-then相比于if not-then这种逻辑思维不需要绕什么弯子。对于NaN这种没法比大小的灰色地带可以用Series.isnull(), Series.notnull()。 -
数值替换
这个类别下的abs, clip, round等更像是数学上的函数,非要说替换的话,勉勉强强~
clip相当于一个限流器,但是我们如果要让超出范围的值变成自定义的值的话,还是要参考where或mask方法。
2.3.5、排序函数
排序有按值排序和按索引排序。
- 按值排序
现在我把这个DF扩充两列(班级、分数、等第),并把性别和班级作为索引。
dict1 = {'name':['Mike','Lily','Jasmine','Hobo','Eddie'],
'Age':[21,8,21,8,10],'Sex':['M','F','M','Unknown','M'],
'Class':[2,1,2,3,3],
'Score':[90,89,100,99,96],'Grade':['A','B','S','A','A']}
df = pd.DataFrame(dict1,index=['stu'+str(i) for i in range(1,6)])
df1 = df.set_index(['Sex','Class'])
print(df)
# name Age Sex Class Score Grade
# stu1 Mike 21 M 2 90 A
# stu2 Lily 8 F 1 89 B
# stu3 Jasmine 21 M 2 100 S
# stu4 Hobo 8 Unknown 3 99 A
# stu5 Eddie 10 M 3 96 A
print(df1) # 原先的stuN(N=1,2,3,4,5)索引变成了Sex和Class
# name Age Score Grade
# Sex Class
# M 2 Mike 21 90 A
# F 1 Lily 8 89 B
# M 2 Jasmine 21 100 S
# Unknown 3 Hobo 8 99 A
# M 3 Eddie 10 96 A
以Score为标准进行降序排列,用by 指定标准,ascending是否升序。
注意到因为Eddie和Mike都是Male, 所以Mike没有再显示性别。
print(df1.sort_values(by='Score',ascending=False))
# name Age Score Grade
# Sex Class
# M 2 Jasmine 21 100 S
# Unknown 3 Hobo 8 99 A
# M 3 Eddie 10 96 A
# 2 Mike 21 90 A
# F 1 Lily 8 89 B
排序可以指定多重标准,标准的优先级与列表元素顺序一致。如果先按年龄排序、再按成绩排序,则
print(df1.sort_values(by=['Age','Score'],ascending=False))
# name Age Score Grade
# Sex Class
# M 2 Jasmine 21 100 S
# 2 Mike 21 90 A
# 3 Eddie 10 96 A
# Unknown 3 Hobo 8 99 A
# F 1 Lily 8 89 B
- 按索引排序
这时就需要用到sort_index方法了。与sort_values中的by关键字功能相同的是sort_index中的level关键字。当然也可以不指定level,那么就按照所有index排序。现在我想用班级1、2、3的顺序来sort
print(df1.sort_index(level='Class'))
# name Age Score Grade
# Sex Class
# F 1 Lily 8 89 B
# M 2 Mike 21 90 A
# 2 Jasmine 21 100 S
# 3 Eddie 10 96 A
# Unknown 3 Hobo 8 99 A
2.3.6、apply方法
apply方法跟map函数有点像,也是传入一个函数来对DataFrame(list)进行某种映射,尤其是匿名函数lambda表达式可以让代码变得尤为简洁。

反正我从来没用过这个方法,今天第一次知道,以后也不知道能不能用得上
2.4.1、滑窗对象
对一个Series使用rolling方法可得到滑窗对象,关键字window可指定窗口大小。
roller = df['Score'].rolling(window=3)
roller_sum = roller.sum()
print(roller_sum)
# stu1 NaN
# stu2 NaN
# stu3 279.0
# stu4 288.0
# stu5 295.0
# Name: Score, dtype: float64
print(roller_sum.__class__)
# 我们看到前roller_sum前两个是NaN,这是因为默认情况下初始状态窗口最下(右)端是第一个元素。假定我们的窗口是左右滑动的(左右or上下只要转置DF就可以互换了)。
-------------------(画图中)
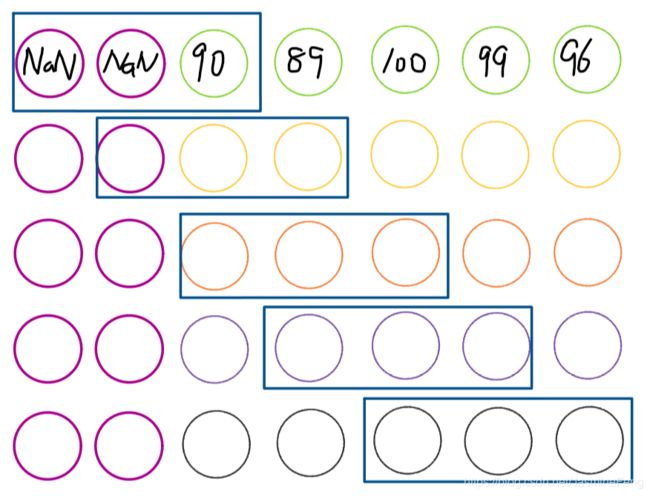
rolling时其实是这样子的,我们假想在元素的最左端还有 w i n d o w s − 1 = 2 windows-1=2 windows−1=2个窗口,这边,由于是假想的窗口,所以用NaN填充之,那么带有NaN算出来的任何统计量当然是NaN,sum也是NaN(什么,你想用nansum,不好意思,rolling对象没这属性~)
如果我们不想让他输出NaN,可以指定min_periods关键字。
roller = df['Score'].rolling(window=3,min_periods=1)
print(roller.sum())
# stu1 90.0
# stu2 179.0
# stu3 279.0
# stu4 288.0
# stu5 295.0
# Name: Score, dtype: float64
我们指定了滑窗的最小长度是1,此时工作过程是这样的:
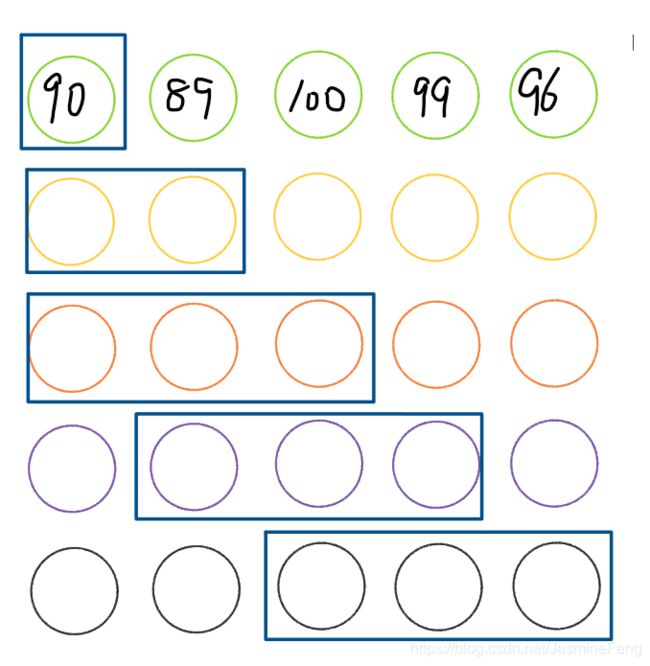
真好~再也不用担心NaN啦!
下面这些方法称为“类滑窗函数”,因为他们在操作的时候很像滑窗移动,也完全可以用rolling来实现:
shift(periods=1)方法,取前periods个数diff(periods=1)方法,返回值为 x t − x t − p e r i o d s x_t-x_{t-periods} xt−xt−periods,而numpy中的diff(n=1)返回的是 ∇ n x t \nabla^nx_t ∇nxt,即 n n n阶差分pct_change(periods=1)方法,与向前第n 个元素相比计算增长率
P.S. 若 n < 0 n\lt0 n<0,则表示向后操作

这个练一练我想到的是逆序求和再逆序(不过我并没想到怎么用shift,掌握得还不够熟练!)
s = pd.Series([1,2,3])
s_inverse = s[::-1] # 3,2,1
roller_sum = s_inverse.rolling(2).sum() # NaN, 5, 3
print(roller_sum[::-1]) # 3, 5, NaN
print(s[::-1].rolling(2).sum()[::-1]) # 写成一行
后来队里的小伙伴提醒我可以这么写:
print((s[::-1]+s[::-1].shift(1))[::-1]) # 3, 5, NaN
恍然大悟~运行效率嘛。。我试了一下,迭代1w次rolling需要3.075s,shift需要3.043s;当把Series的 1 , 2 , 3 ⋯ 1,2,3\cdots 1,2,3⋯换成 1 , 2 , 3 , ⋯ , 1 0 4 1,2,3,\cdots,10^4 1,2,3,⋯,104,再迭代1w次,rolling需要5.753s,shift需要3.316s!
究其原因,可能是因为要滑动的次数与序列长度成正比,时间复杂度 O ( n ) O(n) O(n),shift再相加一次性完成,时间复杂度 O ( 1 ) O(1) O(1)?我不太确定哈,欢迎大佬指正!
2.4.2、扩张窗口
我一看教程的解释就想到了cumsum cumprod与练一练简直不谋而合呢!
这是工作过程:
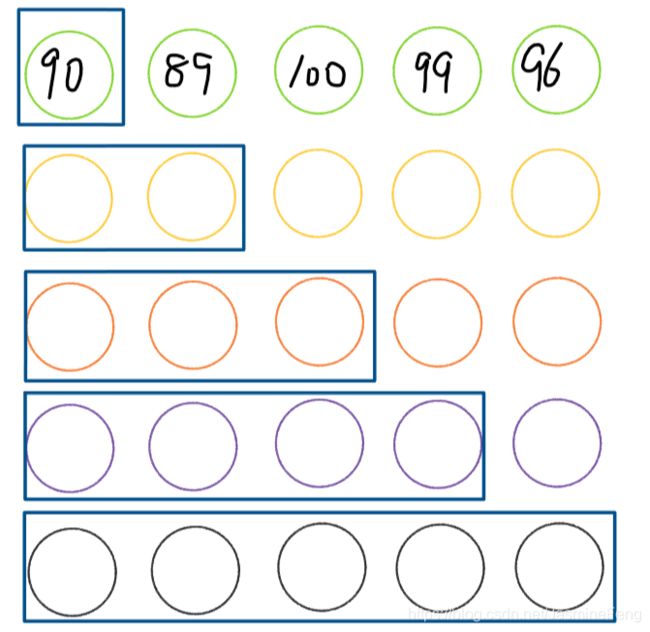
print(df['Score'].expanding().mean())
# stu1 90.0
# stu2 89.5
# stu3 93.0
# stu4 94.5
# stu5 94.8
# Name: Score, dtype: float64
用expanding分别实现cumsum, cumprod, cummax:
s = pd.Series([1,2,3,4])
print(s.expanding().sum())
print(s.expanding().apply(lambda x:x.prod())) # 前面刚说apply不知道有啥用途,这里就上场了
print(s.expanding().max())
练习
2.5.1、口袋妖怪数据集
坚持没看一眼参考答案,做了将近两个小时
![]()
思路是找出不相等的索引,发现返回空索引,证明完全相等。
答案是算均值(布尔值转换成整型),可能普适性上没有返回索引好。
df = pd.read_csv('E:/DataWhale组队学习/data/pokemon.csv')
# 验证Total
total_vali = df.loc[:,'HP':'Speed'].sum(axis=1)
idx_unequal = df[total_vali!=df.loc[:,'Total']].index
print(idx_unequal) # Int64Index([], dtype='int64')

通过分组聚合查看每种有多少数量,通过获取groupby索引得到出现的组合。
对Type 1, Type 2做笛卡尔积得到所有可能的组合,用求差集的方法获得未出现的组合。
import itertools
# 对于#重复的只保留第一条记录
df1 = df.drop_duplicates(['#'],keep='first')
# 求第一属性的种类数量
num_type1 = df1['Type 1'].value_counts()
# print(num_type1)
type1_123 = num_type1.index[:3]
# print(type1_123) # Index(['Water', 'Normal', 'Grass'], dtype='object')
# 求第一属性和第二属性的组合种类
num_type_compose = df1.groupby(by=['Type 1','Type 2']).count()['Name']
appear_types = list(num_type_compose.index)
print(len(appear_types)) # 125
# 求未出现的组合
type1, type2 = df1['Type 1'].unique().tolist(), df1['Type 2'].unique().tolist()
all_types = list(itertools.product(type1, type2))
print(len(all_types)) # 342
potential_types = set(all_types).difference(set(appear_types))
print(len(potential_types)) # 217
但是!看了答案我发现类别数目不太一样,进行漫长的debug后我发现这么做是有大问题的,首先groupby不会算上NaN(见下图),但其实应该是被包括在内的。不算的话125个,算的话143个。
(经实验我用fillna把NaN改成字符串’nan’再做groupby就是143)
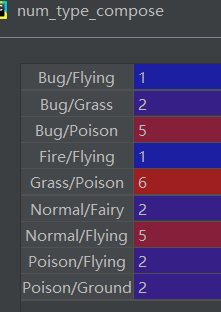
其次!Type 1竟然的值竟然也在Type 2里!比如Poison童鞋就是“双开”的典型案例,做了笛卡尔积会出现('Poison','Poison')的情况,或者是前后两个Type交换但其实只算一类,所以就会多出很多!
后来队里的小伙伴提醒我这两个类就是一样的,只不过第二类可以缺失。。。难怪L_full的i和j都是从Type 1 取的。
啊啊啊这真是我没想到的,小聪明,小聪明啊!

答案的思路是用字符串的join方法把两个类别拼接在一起,如果两个类别相同或者第二类是NaN的话,就用Type 1往里填充。最后也是用差集来做的。

我没想到(a)问就有坑!如果逐个替换的话就会报错,因为当我已经把大于120换成high,那么再替换小于50的时候就要拿high与50比了,而整形与字符串型不能比大小的。然后我想了两个解决方案。
方案一:先把大于120和小于50的替换成整形,设完mid后再把两个整形用replace替换成字符型。
s1 = df['Attack'].copy()
print((s1<0).sum())
s1.mask(s1>120,-1,inplace=True)
s1.mask((s1<50)&(s1>0),-2,inplace=True)
s1.mask((s1>=50)&(s1<=120),'mid',inplace=True)
s1.replace([-1,-2],['high','low'],inplace=True)
方案二:先记录符合条件的索引,最后用字符串赋值。
s2 = df['Attack'].copy()
idx_high = s2[s2>120].index
idx_low = s2[s2<50].index
idx_mid = s2[(50<=s2)&(s2<=120)].index # 不能用50<=s2<=120作为condition
s2[idx_high], s2[idx_low], s2[idx_mid] = 'high', 'low', 'mid'
看到答案我也是惊了,竟然连用mask,可能就一直是整形和整形比了?这就不报错了。我说你不讲wude!
(b)问replace方法我不会,虽然我心里知道一定要传入一个dict,但就是没想起来字典推导式,哭了

apply方法倒是简单
s_type1 = df['Type 1'].copy()
# replace方法不会!
s_type1_upper1 = s_type1.apply(lambda x: x.upper())
求离差我没用apply,是一步步写的,而且。。。看了答案才发现应该算绝对值
# 求离差并排序
data = df.loc[:,'HP':'Speed'].values
m = np.median(data,axis=1,keepdims=True)
deviation = (data - m).abs().max(axis=1)
df2 = df.copy()
df2.loc[:,'Deviation'] = deviation
df2.sort_values(by='Deviation',inplace=True,ascending=False)
print(df2.head())
----------------------------------------------
怎么这么多,已经11068字了呢
----------------------------------------------
2.5.2、指数加权窗口
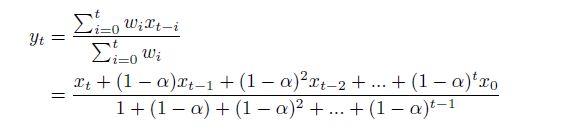
这个公式进一步可以写作:
y t = ∑ i = 0 t ( 1 − α ) i x t − i ∑ i = 0 t ( 1 − α ) i y_t= \frac{\sum_{i=0}^t (1-\alpha)^i x_{t-i}}{\sum_{i=0}^t (1-\alpha)^i} yt=∑i=0t(1−α)i∑i=0t(1−α)ixt−i
如此代码就显然了:
out = s.expanding().apply(lambda x: ((1 - alpha) ** np.arange(len(x)) * x[::-1]).sum()
/ ((1 - alpha) ** np.arange(len(x))).sum())

这一问虽然也可以像上一问使用类似的公式,但由于窗口长度固定,故分母是固定的,我们可以先算出分母,这样就不用在每一次滑动都进行一次分母的求和了。
alpha = 0.2
window = 3
denominator = ((1-alpha)**np.arange(window)).sum()
result = s.rolling(window=window).apply(lambda x:((1-alpha)**np.arange(window)*x[::-1]).sum()/denominator)
print(s)
print(result[:4])
# 0 NaN
# 1 NaN
# 2 -1.409836
# 3 -1.737705
# dtype: float64