BI-SQL丨截取字符串

截取字符串
我们在做BI可视化之前,通常需要已经清洗干净的数据才能进行可视化分析。
随着电商的发展,有很多数据都是从网上渠道抓取过来的,这就导致原始数据有很多对于分析来说的无效数据,那么在SQL中这部分数据该如何进行处理呢?
函数介绍
SUBSTRING语法:
SUBSTRING ( 表达式 , 开始位置 , 长度 )
返回结果为:返回字符、binary、text 或 image 表达式的一部分。
CHARINDEX语法:
CHARINDEX ( 目标字符串 , 被查找字符串 [ , 开始查找位置 ] )
若省略第三参数,则默认从第一位开始查找。
返回结果:字符串开始出现的位置。
PATINDEX语法:
PATINDEX ( '%字符串%' , 表达式)
第一参数可以使用通配符,第二参数通常为被查找的字符串。
返回结果:字符串开始出现的位置。
注:
CHARINDEX函数与PATINDEX函数从结果上来看,二者的作用类似,不过前者是完全匹配,后者支持模糊查询。
使用实例
案例数据:

在白茶本机的数据库中存在名为“CaseData”的数据库。
存在名为“案例数据”的表。从上图中我们可以看出,数据量比较少,而且在[商品名称]这一列中存在很多的无用字符。
例子1:
提取手机的所有信息,并将[商品名称]中无用的字符串去掉。
代码1:
SELECT SUBSTRING([商品名称],CHARINDEX('手机',[商品名称]),2) AS Product,*
FROM [案例数据]
WHERE [商品名称] LIKE N'%手机%'
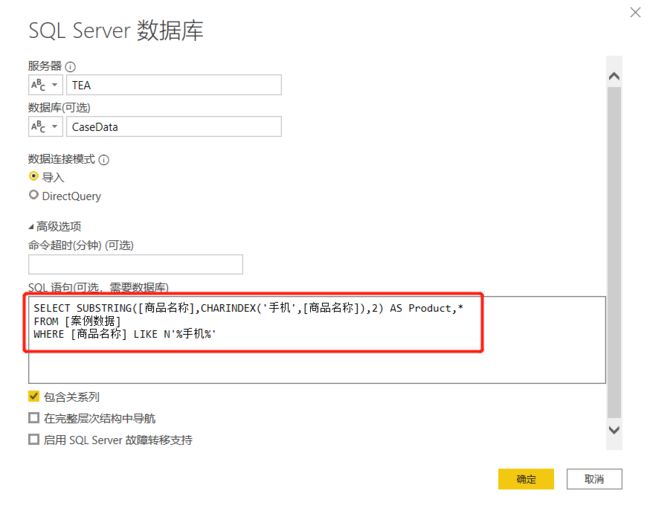
结果如下:

解释:
这段代码中,我们首先通过CHARINDEX函数定位到手机出现的字符串位置,再通过SUBSTRING函数进行字符串截取。
代码2:
SELECT SUBSTRING([商品名称],PATINDEX('%手机%',[商品名称]),2) AS Product,*
FROM [案例数据]
WHERE [商品名称] LIKE N'%手机%'
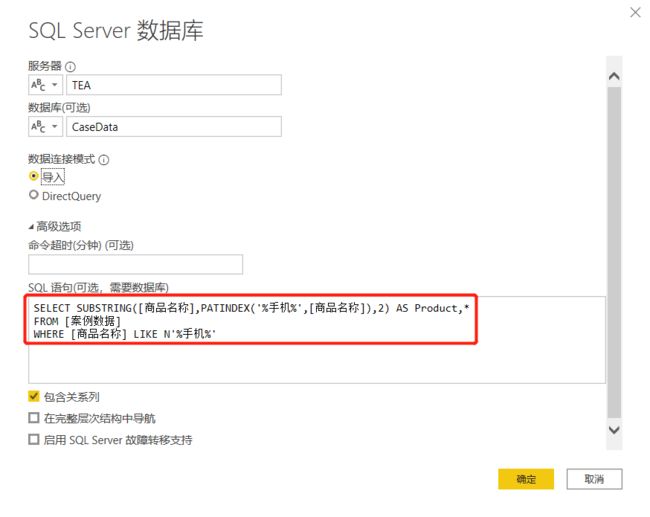
结果如下:
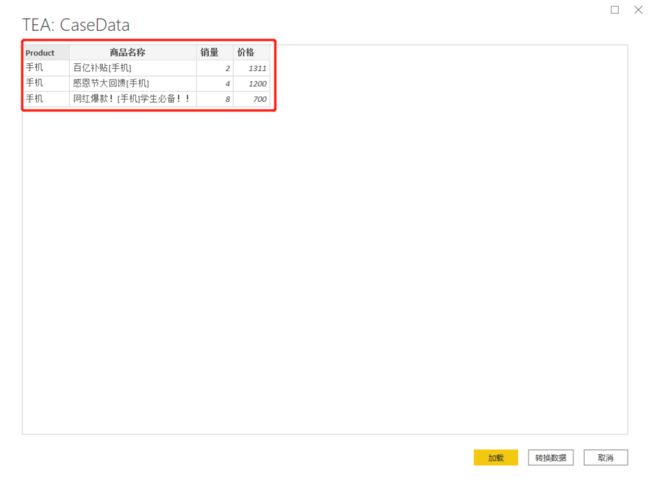
例子2:
提取[商品名称]中所有商品,并将[商品名称]中无用的字符串去掉。
代码:
SELECT SUBSTRING([商品名称],
CHARINDEX('[',[商品名称])+1,CHARINDEX(']',[商品名称])-CHARINDEX('[',[商品名称])-1
)AS Product,*
FROM [案例数据]
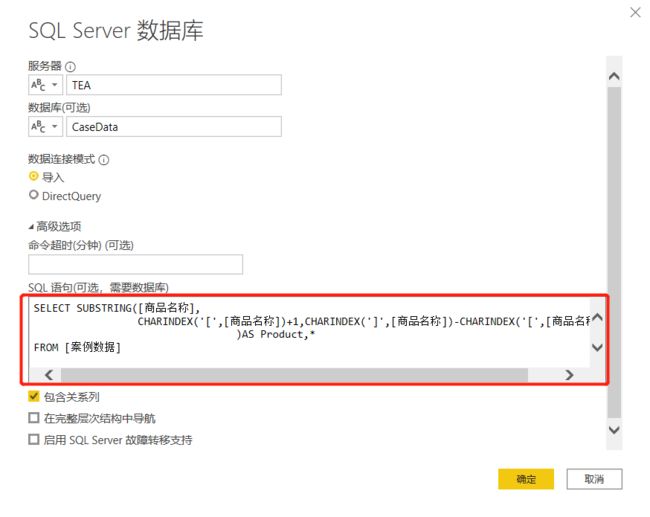
结果如下:

解释:
这段代码中,我们先判断的是“[”符号首次出现的位置,来定位所有商品名称的首字符位置,再通过判断“]”的位置来确认商品名称的末字符位置,二者相减即为需要截取的字符串长度。
![]()

这里是白茶,一个PowerBI的初学者。
