【kafka】-入门篇
一、选型
1.1 产品选型

1.2 厂商选择
- Apache Kafka,也称社区版 Kafka。优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;缺陷在于仅提供基础核心组件,缺失一些高级的特性。
- Confluent Kafka,Confluent 公司提供的 Kafka。优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证;缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。
- CDH/HDP Kafka,大数据云公司提供的 Kafka,内嵌 Apache Kafka。优势在于操作简单,节省运维成本;缺陷在于把控度低,演进速度较慢。
1.3 版本迭代
1.0-2.0
3.x 移处ZK
1.4 kafka监控管理平台
- 滴滴开源Logi-KafkaManager
- Kafka Eagle
- kafka manager
二、基础使用
(一) 概念
消费者组
理想情况下,Consumer实例的数==该 Group 订阅Topic的分区总数。
假设一个 Consumer Group 订阅了 3 个主题,
分别是 A、B、C,它们的分区数依次是 1、2、3(总共是 6 个分区)。
为该 Group 设置 6 个 Consumer 实例是比较理想的情形,因为它能最大限度地实现高伸缩性。
如果设置 8 个实例,那么有 2 个实例(8 – 6 = 2)将不被分配分区,永远处于空闲状态。
位移
消费者在消费的过程中需要记录自己消费了多少数据(位移)
重平衡 Rebalance
比如某个 Group 下有 20 个 Consumer 实例,它订阅了一个具有 100 个分区的 Topic。
正常情况下,Kafka 平均会为每个 Consumer 分配 5 个分区。
这个分配的过程就叫 Rebalance。
- 组成员数发生变更。比如有新的 Consumer 实例加入组或者离开组,抑或是有 Consumer 实例崩溃被“踢出”组。
- 订阅主题数发生变更。Consumer Group 可以使用正则表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile(“t.*c”)) 就表明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主题。在 Consumer Group 的运行过程中,你新创建了一个满足这样条件的主题,那么该 Group 就会发生 Rebalance。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
避免 Rebalance 的发生
在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成。这是 Rebalance 为人诟病的一个方面。
主题(位移主题)
位移主题的 Key 中应该保存 3 部分内容:
(二)分区策略
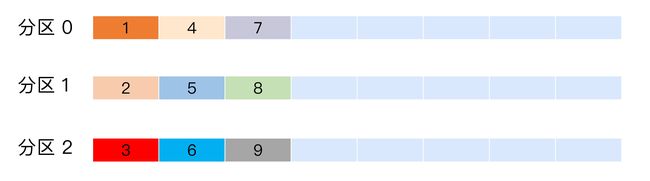
轮询策略
随机策略
也称 Randomness 策略。

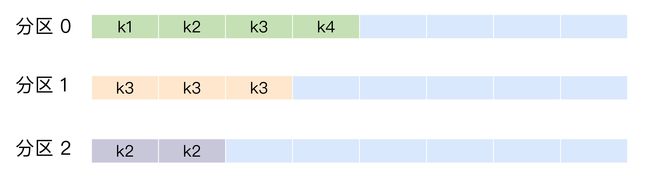
按消息键保序策略
为每条消息定义消息键,简称为 Key。
保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的
基于地理位置的分区策略
但这种策略一般只针对那些大规模的Kafka集
群,特别是跨城市、跨国家甚至是跨大洲的集群。
Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
(三)生产者压缩算法
producer端进行消息压缩,broker端保持消息压缩,consumer端解压缩,
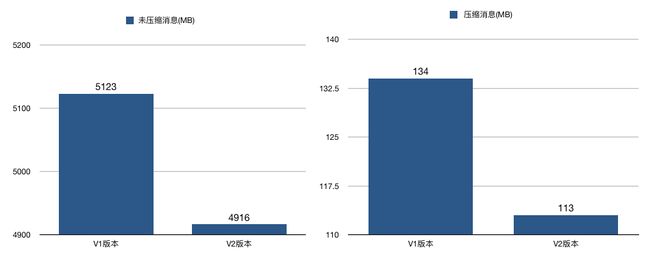
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。
生产者
程序中配置 compression.type 参数即表示启用指定类型的压缩算法
spring.kafka.producer.compression-type=gzip
Producer 启动后生产的每个消息都是 GZIP 压缩过的,从而降低了Producer到Broker的网络传输,从而也降低了Broker的数据存储压力。
broker端
producer.properties
compression.type=none
其实大部分情况下 Broker 从 Producer 端接收到消息后 原封不动保存。
有两种例外情况就可能让 Broker 重新压缩消息。
- Broker端指定了和Producer端不同的压缩算法
- Broker端发⽣了消息格式转换
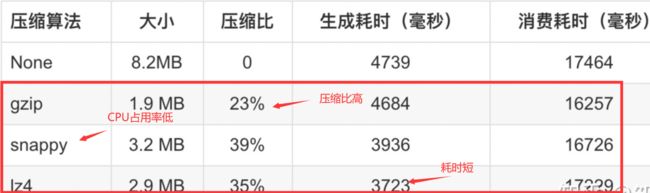
压缩格式
- LZ4
- Snappy
- zstd
- GZIP
比较
- 吞吐量:LZ4 > Snappy > zstd / GZIP
- 压缩⽐:zstd > LZ4 > GZIP > Snappy
(四)消息丢失问题
无消息丢失如何实现
生产者
Kafka 只对“已提交”的消息(committed message)做有限度的持久化保证。
(1)已成功提交
当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,
它们会告诉生产者程序这条消息已成功提交。
(2)有限度的持久化
假如消息保存在 N 个 Kafka Broker 上,前提条件: N 个 Broker 中至少有 1 个存活。
只要这个条件成立,Kafka 就能保证你的这条消息永远不会丢失。
Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。
消费者
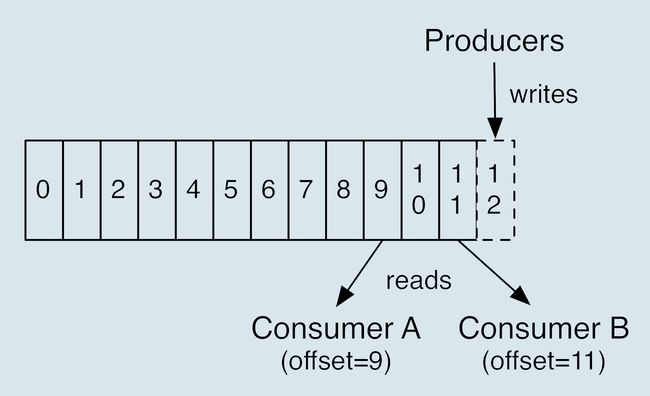
当前的书签页是第 90 页,我先将书签放到第 100 页上,之后开始读书。
当阅读到第 95 页时,我临时有事中止了阅读。
那么问题来了,当我下次直接跳到书签页阅读时,我就丢失了第 96~99 页的内容。
解决办法:
(1)单线程消费
维持 【先消费消息,再更新位移】的顺序
(2)多线程消费
如果是多线程异步处理消费消息,Consumer 程序不要开启自动提交位移,而是要应用程序手动提交位移。
但是,这种处理方式可能带来的问题是【消息的重复处理】,同一页被读了很多遍。
(五)拦截器
(六)交付可靠性
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once)-默认:消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
(七)索引
索引的抽象父类 AbstractIndex。
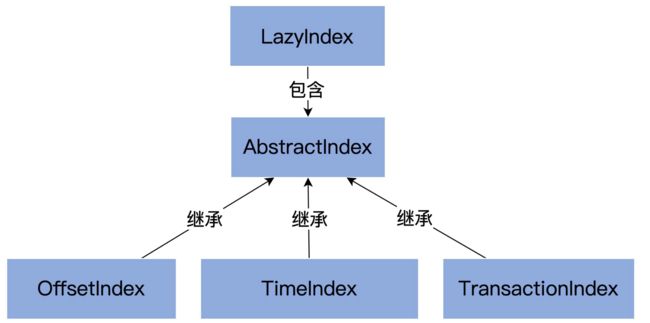
-
索引文件(file)。每个索引对象在磁盘上都对应了一个索引文件。你可能注意到了,这个字段是 var 型,说明它是可以被修改的。难道索引对象还能动态更换底层的索引文件吗?是的。自 1.1.0 版本之后,Kafka 允许迁移底层的日志路径,所以,索引文件自然要是可以更换的。
-
起始位移值(baseOffset)。索引对象对应日志段对象的起始位移值。举个例子,如果你查看 Kafka 日志路径的话,就会发现,日志文件和索引文件都是成组出现的。比如说,如果日志文件是 00000000000000000123.log,正常情况下,一定还有一组索引文件 00000000000000000123.index、00000000000000000123.timeindex 等。这里的“123”就是这组文件的起始位移值,也就是 baseOffset 值。
-
索引文件最大字节数(maxIndexSize)。它控制索引文件的最大长度。Kafka 源码传入该参数的值是 Broker 端参数 segment.index.bytes 的值,即 10MB。这就是在默认情况下,所有 Kafka 索引文件大小都是 10MB 的原因。
-
索引文件打开方式(writable)。“True”以“读写”方式打开,“False”以“只读”打开。
常规索引
不同索引类型保存不同的
- 位移索引 8 个字节
- <消息的相对位移,日志段文件中该消息第一个字节的物理文件位置>
- 时间戳位移 12 个字节
- < 时间戳,相对位移值 >
位移索引 OffsetIndex
.index 文件
时间戳索引
.timeindex 文件
已中止事务索引
三、原理初探
(一)副本机制
- follower副本是不对外提供服务的。
- 从master副本异步拉取消息,并写入到自己的提交日志中
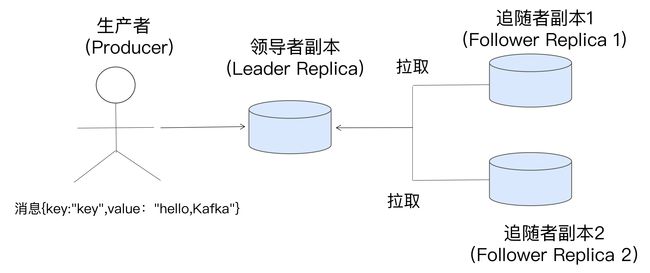
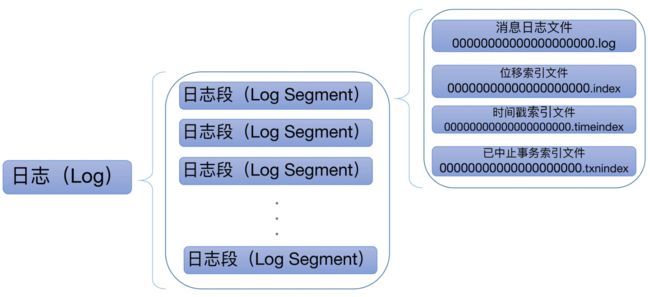
(二)日志系统
Kafka 日志对象由多个日志段对象组成,而每个日志段对象会在磁盘上创建一组文件,包括
- 消息日志文件(.log)
- 位移索引文件(.index)
- 时间戳索引文件(.timeindex)
- 已中止(Aborted)事务的索引文件(.txnindex)。
(三)压缩算法
(四)Hash算法
主流 Hash 散列算法介绍和使用
murmurHash算法
哈希算法简单来说就是将一个元素映射成另一个元素,可以简单分类两类,
- 加密哈希:MD5,SHA256等
- 非加密哈希:如MurMurHash,CRC32,DJB等
- 漫谈非加密哈希算法
MurMurHash的随机分布特征表现更良好,Redis,Memcached,Cassandra,HBase,Lucene中都使用到了这种hash算法。
选举机制
(1) ZK的ZAB协议
(2)Kraft模式
Raft比ZK的ZAB协议更加易懂,也更加高效,partition的主选举将变得更快捷,controller的调度速度将上一个档次。
Kafka高可用 — KRaft集群搭建
kafka3.1集群搭建(kraft模式)
五、参考文章
kafka核心技术实战