Kubernetes 入门基础
目录
一、Kubernetes 是什么?
1. 概述
2. 为什么用 k8s
3.k8s的特性
二、Kubernetes 基本组件
1.Pod(最小的资源单位)
2.Pod的两个分类
3.Pod 控制器
4. Label 标签
5.Label 选择器(Label selector)
6.资源清单
7.服务发现(Service同一个访问入口)
8.存储服务分类
9.调度器(Scheduler)
10.Namespaces
11.集群安全(RBAC通讯加密-ca整数加密手段)
12.HELM(K8S 中包的管理工具)
三、Kubernetes 集群架构
1.Master主控节点组件
2.work-node组件
3.用户访问流程
一、Kubernetes 是什么?
1. 概述
Kubernetes,简称 K8s,是用 8 代替名字中间的 8 个字符 “ubernete” 而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes 的目标是让部署容器化的应用简单并且高校,Kubernetes 提供了应用部署,规划,更新,维护的一种机制。
在 Kubernetes 中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
2. 为什么用 k8s
如果你是一名运维人员,可能经常因为一些重复、繁琐的工作感觉厌倦。比如:这个需要一套新的测试环境,那个需要一套新的测试环境,之前可能需要装系统、装依赖环境、开通权限等等。而如今,可以直接用镜像直接部署一套新的测试环境,甚至全程无需自己干预,开发人员通过 jenkins 或者自动化运维平台即可一键式创建,大大降低了运维成本。
一开始,公司业务故障,可能是因为基础环境不一致、依赖不一致、端口冲突等等问题,现在实现镜像部署,所有的依赖、基础都是一样的,大大减少了因为这类基础问题引发的故障。也有可能公司业务是由于服务器宕机、网络等问题,造成服务不可用,此类情况均需要运维人员及时去修复,而如今,可能在你收到告警信息的时候,k8s已经帮你恢复了。
在没有使用k8s时,业务应用的扩容和缩容,都需要人工去处理,从采购服务器、上架、到部署依赖环境,不仅需要大量的人力物力,而且非常容易在中间过程出现问题,又要花费大量的时间去查找问题。成功上架后,还需要在前端反代端添加或该服务器,而如今,可以利用k8s的弹性计算,一键式进行扩容和缩容,不仅大大提高了运维效率,而且还节省了不少的服务器资源,提高了资源利用率。
无论是对于开发人员、测试人员还是运维人员,k8s 的诞生,不仅减少了工作的复杂性,还减少了各种成本。上述带来的变革只是其中比较小的一部分,更多优点只有用了才能体会到。
3.k8s的特性
开源
轻量级:使用go语言编译型语言,语言级别支持进程管理,不需要人为控制,所以以go开发的资源消耗占用资源小
自我修复:对异常状态的容器进行重启或重建(先创建、再删除),目的是保证业务线不中断
弹性伸缩:使用命令、UI或者基于CPU使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性;且在业务低峰时回收资源,以最小成本运行服务
自动部署和回滚:K8S采用滚动更新策略更新应用(默认),一次更新一个Pod,而不是同时删除所有Pod,如果更新过程中出现问题,将回滚更改,确保升级不会影响业务
服务发现和负载均衡:K8S为多个pod(容器)提供一个统一访问入口(内部IP地址和一个DNS名称),并且负载均衡关联的所有容器,使得用户无需考虑容器IP问题
机密和配置管理:管理机密数据和应用程序配置,而不需要把敏感数据暴露在镜像里,提高敏感数据安全性。并可以将一些常用的配置存储在K8S中,方便应用程序使用
存储编排(静态、动态):挂载外部存储系统,无论是来自本地存储,公有云(如AWS),还是网络存储(如NFS、GlusterFS、Ceph)都作为集群资源的一部分使用,极大提高存储使用灵活性
批处理:提供一次性任务(job),定时任务(crontab);满足批量数据处理和分析的场景
二、Kubernetes 基本组件
1.Pod(最小的资源单位)
一个pod 会封装多个容器组成一个子节点的运行环境
最小部署单元一组容器的集合(基础容器+ 主应用容器+挂斗/副容器)
一个Pod中的容器共享网络命名空间(基础容器提供的pause)
Pod是短暂的 (叙述的是其生命周期)
pod内最少跑3个容器,分布是基础容器pause+运行容器+主应用
2.Pod的两个分类
自主式Pod:这种Pod本身是不能自我修复的。当Pod被创建后(不论是由你直接创建还是被其它controller),都会被K8s调度到集群的Node上。直到pod的进程终止、被删掉。因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在八个Node上。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。
控制器管理的Pod:K8s使用更高级的称为Controller的抽象层,来管理Pod实例。Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如。如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上,虽然可以直接使用Pod,但是在K8s中通常是使用Controller来管理Pod的。
3.Pod 控制器
Pod 控制器是Pod启动的一种模板,用来保证在 K8S 里启动的 Pod 应始终按照用户的预期运行(副本数、生命周期、健康状态检查等)。

1.ReplicaSet(rc) 确保预期的Pod副本数量;无法独立存在,需要以来已deployment挥着statefulset
2.Deployment 无状态应用部署
3.StatefulSet 有状态应用部署;指的就是mysql
4.DaemonSet 确保所有Node运行同一种Pod;无须借助于replicaset
5.Job 一次性任务
6.Cronjob 定时任务
7.HPA 弹性伸缩
4. Label 标签
是 K8S 特色的管理方式,便于分类管理资源对象。
Label 可以附加到各种资源对象上,例如Node、Pod、Service、RC等,用于关联对象、查询和帅选。
一个Label是一个key-value的键值对,其中key与value由用户自己制定。
一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象中,也可以在对象创建后动态添加或者删除。
可以通过给指定的资源对象捆绑一个或多个不同的Label,来实现多维度的资源分组管理功能。
与 Label 类似的,还有Annotation(注释)。
区别在于有效的标签值必须为63个字符或更少,并且必须为空或以字母数字字符([a-z0-9A-Z])开头和结尾,中间可以包含横杠(-)、下划线(_)、点(.)和字母或数字。注释值则没有字符长度限制。
5.Label 选择器(Label selector)
给某个资源对象定义一个Label,就相当于给它打了一个标签;随后可以通过标签选择器(Label selector)查询和筛选拥有某些Label的资源对象。
标签选择器目前有两种:基于等值关系(等于、不等于)和基于集合关系(属于、不属于、存在)。
6.资源清单
K8S中资源的概念:在kubernetes中,所有控制器,组件等都称为资源
资源清单格式(资源清单/配置文件):在k8s中,一般使用yaml格式的文件来创建符合我们预期期望的pod
容器探针—》liveness Probe 、 readnessProbe
Pod hook
重启策略Pod控制器:掌握各种控制器的特点以及使用定义方式。
服务发现:掌握svc (service)原理及其构建方式(service 的yml)
存储:掌握多种存储类型的特点并且能够在不同环境中选择合适的存储方案
调度器(Scheduler):掌握调度器原理(预选和优选)能够根据要求把Pod定义到想要的节点运行(selector)安全:集群的认证鉴权访问控制原理及其流程
7.服务发现(Service同一个访问入口)
通过service这个统一入口/定义的访问策略对外暴露服务K8S内部的Pod
通讯是以一组私有地址进行通讯的,所以默认情况下无法直接为客户端(服务、用户)提供访问
可以通过Service服务发现,把我们内部的pod资源暴露给客户端访问(以暴露一个ip:端口的方式),让客户端可以通过这个IP:端口的形式访问到K8S内部的多个pod(通常意义上是一个应用的副本集
8.存储服务分类
无状态服务:
任何一个请求都可以被任意一个实例处理,不存储状态数据,实例可以水平拓展,通过负载均衡将请求分发到各个节点,在一个封闭的系统中,只存在一个数据闭环,通常存在于单体架构的集群中
比如:LVS 服务不依赖自身的状态,实例的状态数据可以维护在内存中
有状态服务:
一个请求只能被某个节点(或者同等状态下的节点)处理存储状态数据,实例的拓展需要整个系统参与状态的迁移,在一个封闭的系统中,存在多个数据闭环,需要考虑这些闭环的数据一致性问题通常存在于分布式架构中
例如数据库(需要持久化)服务本身依赖或者存在局部的状态数据,这些数据需要自身持久化或者可以通过其他节点恢复
9.调度器(Scheduler)
K8S会自动完成把一个新的pod 调度到对应的节点(预选/优选算法)对于生产环境上,我们往往会需要将pod创建的过程(比如创建到的节点位置)进行管理
10.Namespaces
随着项目增多、人员增加、集群规模的扩大,需要一种能够逻辑上隔离K8S内各种“资源”的方法,这就是Namespace。
Namespace 是为了把一个K8S集群划分为若干个资源不可共享的虚拟集群组而诞生的。
不同Namespace内的“资源”名称可以相同,相同Namespace内的各种“资源”,“名称”不能相同。
合理的使用K8S的Namespace,可以使得集群管理员能够更好的对交付到K8S里的服务进行分类管理和浏览。
K8S里默认存在的Namespace有:default、kube-system、kube-public等。
查询K8S里特定“资源”要带上相应的Namespace。
11.集群安全(RBAC通讯加密-ca整数加密手段)
认证、鉴权、访问控制、原理及流程
从搭建集群,就需要用到加密,CA认证
管理和控制,必须先通过认证/授权,才能进行管理
跑的一些应用,nginx、squid -->需要一些访问控制策略
12.HELM(K8S 中包的管理工具)
类似linux里面yum
helm 安装 magodb
helm 模板、自定义
三、Kubernetes 集群架构
K8S也是一个典型的C/S架构,由master主控节点和node节点组成
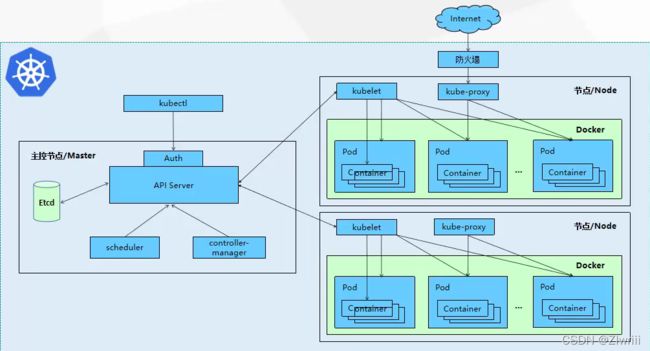
1.Master主控节点组件
(1)auth:认证
身份权限的认证;客户端通过堡垒机管理node,在k8s内只有master可以管理集群,这时就需要master对node进行授权,使用的是apiserver,授权node管理集群
(2)kube-APIserver:6443
调度、统筹k8s集群,各组件协调者,以RESTful API提供接口服务
所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给 Etcd存储,从而隔离其他组件与etcd直接交互
(3)kube-controller-manager(控制器管理中心-定义资源类型)
(4)处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager 就是负责管理这些控制器的。
(5)kube-scheduler:集群调度器
通过调度算法策略决定最终任务在哪个node节点上
根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
(6)etcd :分布式键值存储系统
特性是服务自动发现,去中心化,版本是V3+,v2只支持把数据保存在内存中。用于保存k8s集群几乎所有的信息数据,包括路由状态,比如Pod、Service等对象信息
2.work-node组件
(1)kubelet
kubelet是Master在Node节点上的Agent,管理代理的角色(kubelet)是bootstrap,kublet管理对应的node节点,及node节点与master之间的交互,kubectl会监控负责的node节点,周期性汇报给master(kubectl)
(2)kube-proxy(四层)
使用services定义了一组pod资源的访问策略,做反向代理,只要访问到services的id即可访问到pod
(3)docker或rocket
容器引擎,运行容器;kubelet借助于docker引擎创建容器
3.用户访问流程
(1)假设用户需创建 nginx资源(网站/调度)kubectl ——》auth ——》api-server基于yaml 文件的 kubectl create run / apply -f nginx.yaml(pod 一些属性,pod )
(2)请求发送至master 首先需要经过apiserver(资源控制请求的唯一入口)
(3)apiserver 接收到请求后首先会先记载在Etcd中
(4)Etcd的数据库根据controllers manager(控制器) 查看创建的资源状态(有无状态化)
(5)通过controllers 触发 scheduler (调度器)
(6)scheduler 通过验证算法,验证架构中的nodes节点,筛选出最适合创建该资源,接着分配给这个节点进行创建
(7)node节点中的kubelet 负责执行master给与的资源请求,根据不同指令,执行不同操作
(8)对外提供服务则由kube-proxy开设对应的规则(代理)
(9)container 容器开始运行(runtime 生命周期开始计算)
(10)外界用户进行访问时,需要经过kube-proxy -》service 访问到container (四层)
(11)如果container 因故障而被销毁了,master节点的controllers 会再次通过scheduler 资源调度通过kubelet再次创建容器,恢复基本条件限制(控制器,维护pod状态、保证期望值-副本数量)pod -->ip 进行更改–>service 定义统一入口(固定被访问的ip:端口)